在Beego中使用Flume和Kafka进行数据采集和分发
“纵有疾风来,人生不言弃”,这句话送给正在学习Golang的朋友们,也希望在阅读本文《在Beego中使用Flume和Kafka进行数据采集和分发》后,能够真的帮助到大家。我也会在后续的文章中,陆续更新Golang相关的技术文章,有好的建议欢迎大家在评论留言,非常感谢!
随着数据量的不断增长,数据采集和分发的重要性越来越凸显。在大数据领域中,Flume和Kafka是两个常用的流式数据采集与消息分发框架。在本篇文章中,我们将介绍如何在Beego框架中使用Flume和Kafka实现数据采集和分发。
一、Flume的安装和配置
Flume是一款开源的流式数据采集和传输系统。首先,我们需要安装Flume,并配置Flume的Agent。在本文中,我们将使用Flume的推荐方式进行配置,即使用YAML文件进行配置。
1.1 安装Flume
在命令行中输入以下命令进行Flume的安装:
sudo apt-get install flume-ng
安装完成后,可以在命令行中输入以下命令验证Flume是否成功安装:
flume-ng version
1.2 配置Flume的Agent
Flume的Agent是Flume的核心组件,用于采集和传输数据。在Beego框架中,我们使用Flume的Agent将数据收集并转发给Kafka集群。
我们需要在Flume的Agent中定义以下属性:
- Source:数据源,从哪里采集数据。
- Channel:数据通道,用于缓存采集到的数据。
- Sink:数据传输目的地,将数据发送到哪里。
使用YAML文件进行Flume的配置。示例配置文件如下所示:
#定义Agnet
agent:
#定义Flume的名字,用于标识Agent
name: beego_agent
#定义Agent的描述,可以自定义
description: My Flume agent
#定义Agent使用的配置文件
configuration:
#定义Source
sources:
source1:
#定义数据源类型,这里使用Exec Source,从命令行执行结果中采集数据
type: exec
#定义命令行执行的命令
command: tail -F /xxx/xxx.log
#定义Channel
channels:
channel1:
#定义数据通道类型,使用Memory Channel,即将所有数据缓存在内存中
type: memory
#定义Sink
sinks:
sink1:
#定义数据传输目的地类型,使用Kafka Sink,将数据发送到Kafka集群
type: org.apache.flume.sink.kafka.KafkaSink
#定义Kafka Sink的相关属性
kafka:
#定义Kafka集群的地址,可以是多个
bootstrap.servers: 192.168.0.1:9092,192.168.0.2:9092,192.168.0.3:9092
#定义每个批次发送数据的大小
producer.batch.size: 8192
#定义Kafka Topic
topic: beego_topic
#定义数据序列化方式
serializer.class: kafka.serializer.StringEncoder
#定义Channel与Sink之间的绑定关系
sinkgroups:
sinkgroup1:
sinks: sink1
channels: channel1
#定义Source与SinkGroup之间的绑定关系
configurations:
- channel:
channel1: {}
sources:
- source1
sinkgroups:
- sinkgroup1通过以上配置文件,我们将数据从命令行中采集,并将数据缓存在内存中。然后,我们使用Kafka Sink将数据发送到Kafka集群中的beego_topic Topic中。
二、Kafka的安装和配置
Kafka是一款分布式的流式数据处理系统,可以用于高吞吐率的数据传输,适用于实时数据处理场景。在Beego框架中,我们将使用Kafka作为数据采集和分发的目的地。
2.1 安装Kafka
在命令行中输入以下命令进行Kafka的安装:
sudo apt-get install kafka
安装完成后,可以在命令行中输入以下命令启动Kafka服务:
sudo systemctl start kafka.service
2.2 配置Kafka
在Kafka中,我们需要定义以下两个概念:
- Topic:Topic是Kafka消息的分类,消息通过Topic来进行分组。
- Partition:Partition是Kafka中存储消息的基本单位,一个Topic可以有多个Partition,每个Partition都是一个有序的消息队列。
我们需要在Kafka中创建一个名为beego_topic的Topic,并定义1个Partition。在命令行中输入以下命令:
sudo kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic beego_topic
通过以上命令,我们创建了一个名为beego_topic的Topic,并定义了一个Partition。在Beego框架中,我们将使用Kafka Topic作为数据传输的目的地。
三、在Beego中使用Flume和Kafka
在Beego中,我们可以使用Flume和Kafka进行数据的采集和分发。下面,我们将具体介绍如何在Beego中使用Flume和Kafka。
3.1 在Beego中嵌入Flume
在Beego中,我们可以通过嵌入Flume的方式,将Flume和Beego应用无缝集成。在Beego中,我们可以使用gofluentd-go包,该包是一个Fluentd的客户端库,可以用于将日志数据发送到本地或远程Fluentd服务器。由于Fluentd的官方插件中已经包含了Flume的插件,因此我们可以使用gofluentd-go直接向Flume发送数据。
在Beego中使用gofluentd-go时,我们需要定义一个Fluentd的配置文件,在配置文件中指定Flume的地址和端口。如下所示:
input: type: forward port: 24224 output: type: forward host: localhost port: 5140 shared_key: secret_shared_key flume: enable: true host: 192.168.0.1 port: 5140
在配置文件中,我们将Flume的地址和端口指定为192.168.0.1:5140,并将Fluentd的input和output同时设为forward类型,将消息通过Fluentd的output发送到Flume中。
在Beego中,我们调用gofluentd-go的Send函数将数据发送到Flume中。示例代码如下所示:
import (
"github.com/fujiwara/fluent-agent-hydra/fluent"
"github.com/labstack/gommon/log"
)
const (
tag = "beego"
fluentdHost = "localhost"
fluentdPort = 24224
sharedSecret = "secret_shared_key"
)
var (
fluentLogger *fluent.Fluent
)
func InitFluent() error {
var err error
// 初始化FluentLogger
fluentLogger, err = fluent.New(fluent.Config{
FluentPort: fluentdPort,
FluentHost: fluentdHost,
SharedKey: sharedSecret,
TagPrefix: tag,
Async: false,
BufferLimit: 1000,
RetryWait: 500,
MaxRetry: 10,
})
if err != nil {
log.Errorf("Init Fluent failed:%v", err)
return err
}
log.Info("Init Fluent succeed.")
return nil
}
func SendData(data string) error {
// 发送数据到FluentD
err := fluentLogger.Post(tag, map[string]string{
"message": data,
})
if err != nil {
log.Errorf("Failed to send data to FluentD:%v", err)
return err
}
log.Infof("Success to send data to FluentD:%s", data)
return nil
}通过以上代码,我们可以将数据发送到Flume中,并将数据写入Kafka的beego_topic中。
3.2 在Beego中使用Kafka
在Beego中,我们可以使用sarama包将数据发送到Kafka中的beego_topic中。示例代码如下所示:
import (
"github.com/Shopify/sarama"
"github.com/labstack/gommon/log"
)
const (
kafkaHosts = "192.168.0.1:9092,192.168.0.2:9092,192.168.0.3:9092"
kafkaTopic = "beego_topic"
kafkaUsername = ""
kafkaPassword = ""
)
var (
producer sarama.SyncProducer
)
func InitKafka() error {
var err error
sarama.Logger = log.New(os.Stdout)
// 初始化Kafka Producer
config := sarama.NewConfig()
config.Producer.Retry.Max = 3
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
config.Net.SASL.Enable = false
config.Net.TLS.Enable = false
config.Net.TLS.Config = nil
config.Net.SASL.User = kafkaUsername
config.Net.SASL.Password = kafkaPassword
brokersList := []string{kafkaHosts}
log.Infof("Init Kafka:%v", brokersList)
producer, err = sarama.NewSyncProducer(brokersList, config)
if err != nil {
log.Errorf("Init Kafka failed:%v", err)
return err
}
log.Info("Init Kafka succeed.")
return nil
}
func SendDataToKafka(data string) error {
value := sarama.StringEncoder(data)
msg := &sarama.ProducerMessage{
Topic: kafkaTopic,
Value: value,
}
log.Infof("Send To Kafka:%v", data)
partition, offset, err := producer.SendMessage(msg)
if err != nil {
log.Errorf("Failed to send message to Kafka:%v", err)
return err
}
log.Infof("Sent message to partition %d at offset %d", partition, offset)
return nil
}通过以上代码,我们可以将数据发送到Kafka的beego_topic中,并将数据进行分发。
四、总结
在本文中,我们介绍了如何在Beego中使用Flume和Kafka实现数据采集和分发。首先,我们介绍了如何安装和配置Flume和Kafka。然后,我们讲解了如何将数据通过Flume发送到Kafka中,并在Beego中嵌入Flume。最后,我们演示了如何在Beego中使用sarama包将数据发送到Kafka中,并进行数据分发。
通过使用Flume和Kafka,我们可以在Beego中实现高效的数据采集和分发,为企业数据应用和开发提供了有力的支持。
今天带大家了解了的相关知识,希望对你有所帮助;关于Golang的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 荣耀90系列手机震撼发布:2亿像素大底影像引领潮流
荣耀90系列手机震撼发布:2亿像素大底影像引领潮流
- 上一篇
- 荣耀90系列手机震撼发布:2亿像素大底影像引领潮流

- 下一篇
- Win11 BitLocker驱动器加密如何使用
-
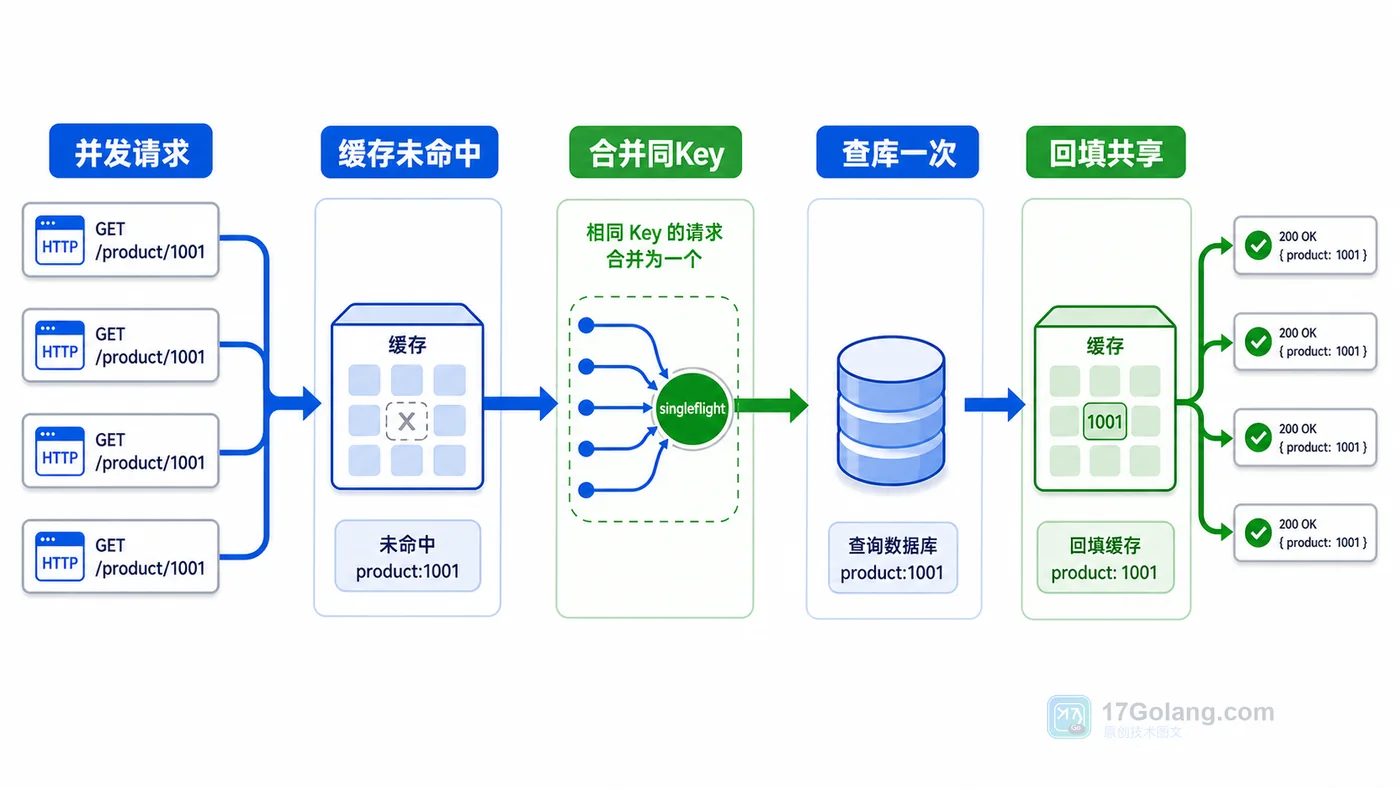
- Golang · Go教程 | 1天前 | singleflight · 并发控制 · Go教程 · 缓存治理 · 接口优化 · Go 并发请求 缓存击穿 singleflight 缓存回填
- Go singleflight 防缓存击穿实战:相同请求只查一次数据库
- 114浏览 收藏
-
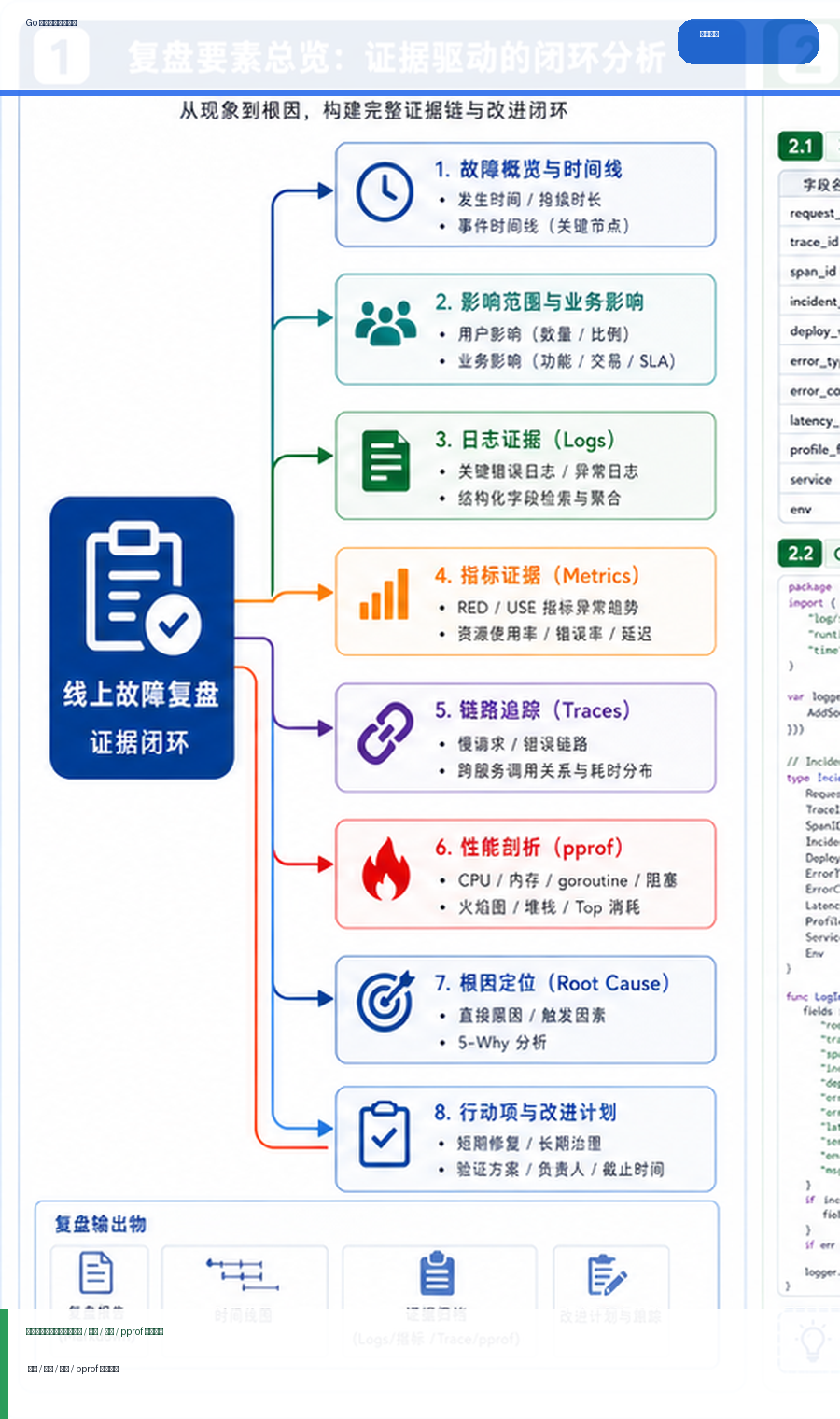
- Golang · Go教程 | 3天前 | golang
- Go 线上故障复盘模板:日志、指标、链路追踪与 pprof 证据闭环
- 710浏览 收藏
-
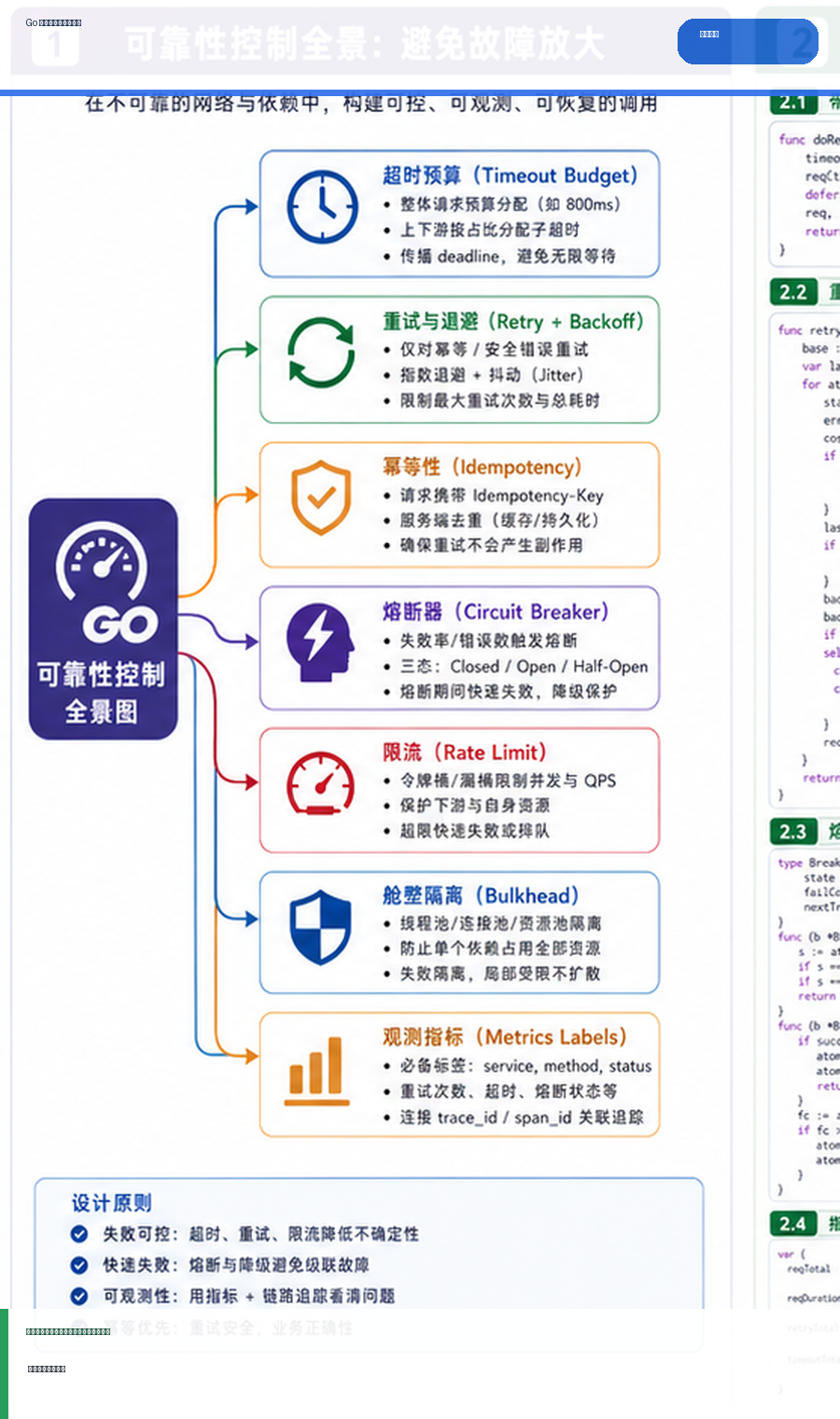
- Golang · Go教程 | 3天前 | golang
- Go 微服务超时、重试与熔断观测:避免故障放大的实践
- 687浏览 收藏
-
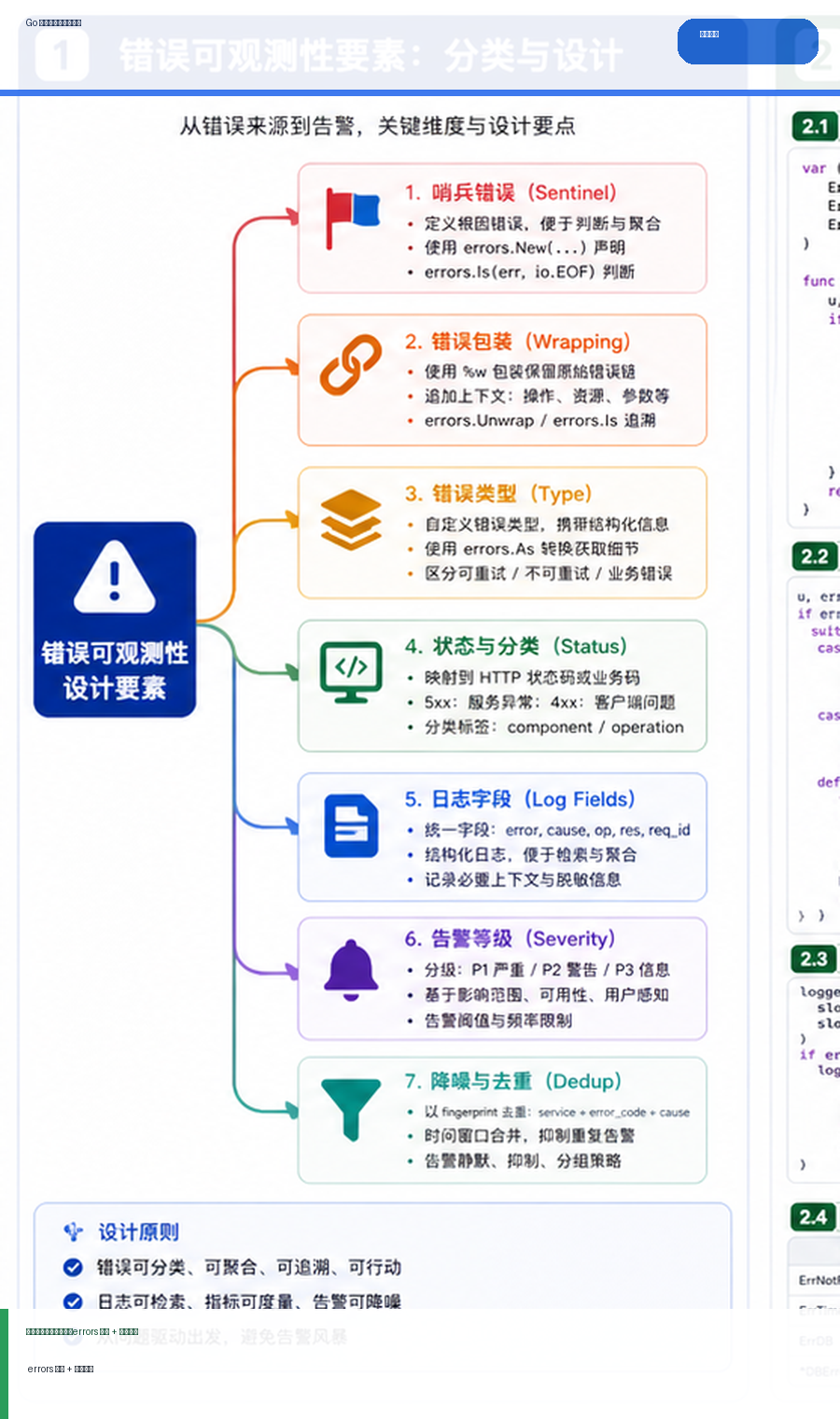
- Golang · Go教程 | 3天前 | golang
- Go 错误处理与告警设计:errors 包装、日志字段与告警降噪
- 664浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- MiMo Code
- MiMo Code 是小米大模型团队开源的新一代 AI 编程助手,面向开发者提供代码理解、生成与辅助开发能力,适合作为 AI 编程工具收藏和体验。
- 2次使用
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 26次使用
-

- MeloLab
- MeloLab 是一款 AI 音乐生成工具,可根据文本创意生成歌曲、人声、混音、分轨和背景音乐,适合创作者快速制作音乐素材。
- 24次使用
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8670次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9083次使用
-
- Java 性能优化上线清单:从定位、改造到灰度发布
- 2026-06-11 860浏览
-
- Spring Boot 压测验证:Gatling、JMeter 与性能回归门禁
- 2026-06-11 843浏览
-
- Java NMT 非堆内存排查:Direct Buffer、线程栈与 Metaspace 分析
- 2026-06-11 826浏览
-
- Spring Boot 容器内存优化:JVM 堆、非堆与 MaxRAMPercentage
- 2026-06-11 809浏览
-
- Tomcat 连接与线程参数调优:maxThreads、acceptCount 与 KeepAlive
- 2026-06-11 792浏览


