旋转位置编码与SwiGLU解析详解
对于一个科技周边开发者来说,牢固扎实的基础是十分重要的,golang学习网就来带大家一点点的掌握基础知识点。今天本篇文章带大家了解《大模型架构:旋转位置编码与SwiGLU解析》,主要介绍了,希望对大家的知识积累有所帮助,快点收藏起来吧,否则需要时就找不到了!
RoPE / SwiGLU
前言
✍ 上一篇我们把现代大模型的两件“基础设施”——GQA 注意力 和 RMSNorm + Pre-Norm 细讲了一遍,从多头注意力的演化一路讲到归一化的升级。这一篇,我们就顺势把剩下的两件标配武器补上:
RoPE(Rotary Positional Embedding):解决“长上下文 + 相对位置建模”的问题;SwiGLU 前馈网络:解决“FFN 表达力与训练稳定性”的问题。一、位置编码
1.1 绝对位置编码——三角函数编码
在最早的 Transformer 里,模型本身对“顺序”是没有感觉的,它只看到一串向量 : x_1, x_2, \dots, x_L \in \mathbb{R}^{d_{\text{model}}} 。他并不像RNN、LSTM一样具备循环机制,因此对于位置信息是不敏感。为了让模型知道“谁在前谁在后”,Transformer 直接给每个位置加了一个位置向量 PE_{pos}
\tilde{x}_{pos} = x_{pos} + PE_{pos}
Transformer 原始论文里的做法采用了三角函数位置编码:
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right),\quad PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right))
三角函数编码是绝对位置编码其中一种经典实现方式,用固定的 sin/cos 函数给每个绝对位置生成向量,方便模型外推到更长序列。
绝对 PE 的好处是实现很简单,但也有两点局限:
它更偏向“绝对位置”:第 10 个 token 和第 20 个 token 的位置向量完全不同;对于超长上下文,learned pos embedding 很难直接外推,sin-cos 虽然能算,但模型未必学会用。? 读到这里,读者可能会有点疑惑,为什么在前面说了 ① 三角函数编码方便模型外推到更长序列, 但是后面又说了② 对于超长上下文,learned pos embedding 很难直接外推,sin-cos 虽然能算,但模型未必学会用。
① 对 learned pos embedding 来说,当我们只训练了max_len = 2048,那 embedding table 里就只有 0~2047 这些 index;想用到 4096-long 序列时,根本没有 PE[3000] 这一行可用,得重新插值/扩表。但是,当我们采用了三角函数的位置编码时, 想算 pos=4096、pos=10000 都随时能算,从“函数定义”角度确实更“可外推”。② 明确表示了sin-cos 虽然能算,但模型未必学会用,对远超训练长度的位置(比如 8192)对应的正弦相位组合,模型可能根本没“学会如何解读”;因此这里根本不会自相矛盾,用一句土话讲就是“可以但没用的外推”。
代码实现import mathimport torchimport torch.nn as nnclass PositionalEncoding(nn.Module): """ 正弦 / 余弦绝对位置编码,接口风格跟 PyTorch Transformer 一致: 输入输出形状都是 [seq_len, batch_size, d_model] """ def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000): super().__init__() self.dropout = nn.Dropout(p=dropout) position = torch.arange(0, max_len, dtype=torch.float32).unsqueeze(1) # [max_len, 1] div_term = torch.exp( torch.arange(0, d_model, 2, dtype=torch.float32) * (-math.log(10000.0) / d_model) ) pe = torch.zeros(max_len, d_model, dtype=torch.float32) pe[:, 0::2] = torch.sin(position * div_term) # 偶数维 pe[:, 1::2] = torch.cos(position * div_term) # 奇数维 pe = pe.unsqueeze(1) # [max_len, 1, d_model] self.register_buffer("pe", pe) def forward(self, x: torch.Tensor) -> torch.Tensor: seq_len = x.size(0) x = x + self.pe[:seq_len] return self.dropout(x)1.2 相对位置编码——旋转编码
? RoPE(Rotary Positional Embedding)的核心思想可以一句话概括:
先看一个二维的小例子。假设我们有一个 2D 向量$(x_1, x_2)$,在平面上旋转一个角度 $\theta$:
\begin{pmatrix} x'_1 \\ x'_2 \end{pmatrix} = \begin{pmatrix} \cos \theta & -\sin \theta \\ \sin \theta & \cos \theta \end{pmatrix} \begin{pmatrix} x_1 \\ x_2 \end{pmatrix}
RoPE 就是把 Q/K 的每两个维度看作一个二维坐标系上的点,然后:
对于位置 pos ,计算一个角度 \theta_{pos} ;对每对维度做这个旋转。如果 Q 的原始向量为Q_{pos} ,RoPE 输出的就是“带位置信息”的 Q'_{pos} ,同理对 K 也做同样的旋转。
? 读者可能都知道旋转编码就是在Q K上进行旋转,但具体是怎么让模型知道了他们的相对位置信息呢?
假设 query 在位置 m ,key 在位置 n ,RoPE 分别对它们做旋转:
Q'_m = R_{\theta_m} Q_m,\quad K'_n = R_{\theta_n} K_n , 其中 $R_{\theta}$ 是旋转矩阵。
则注意力里用到的点积是:
Q'_m \cdot K'_n = (R_{\theta_m} Q_m)^\top (R_{\theta_n} K_n) = Q_m^\top R_{\theta_m}^\top R_{\theta_n} K_n
因为旋转矩阵可加角度:
R_{\theta_m}^\top R_{\theta_n} = R_{\theta_n - \theta_m}
所以:
Q'_m \cdot K'_n = Q_m^\top R_{\theta_n - \theta_m} K_n
这就是 RoPE 在长上下文场景下比“纯绝对位置编码”更有优势的根本原因:模型更容易学到“离多远比较重要”,而不是死记“第 1234 个位置是什么样子”。
代码实现import torchdef rotate_half(x): # x: [..., 2 * d_half] x1, x2 = x.chunk(2, dim=-1) # 拆成两半 return torch.cat([-x2, x1], dim=-1) # (x1, x2) -> (-x2, x1)def apply_rope(x, cos, sin): """ x: [B, L, H, D] # Q 或 K cos: [L, 1, 1, D] sin: [L, 1, 1, D] """ # 广播到同一形状 while cos.dim()ROPE使用
Q = self.w_q(x) # [B, L, H*D]K = self.w_k(x)Q = Q.view(B, L, H, D)K = K.view(B, L, H, D)Q = apply_rope(Q, cos, sin) # 注入位置信息K = apply_rope(K, cos, sin)
?1. 介绍一下三角函数编码以及旋转编码,为什么现在常用旋转编码?(真实面经)
RoPE 用旋转把位置编码进 Q/K,使注意力只依赖“相对位置差”;编码函数本身是显式可计算的,任意位置都能算;相对位置 + 平滑旋转,让模型在没见过的更长上下文上,比传统绝对 PE 更容易“外推”。(重点!)二、激活函数
2.1 FFN 层
对于每个位置的隐藏向量 $x \in \mathbb{R}^{d_{\text{model}}}$,Transformer中的FFN 本质就是一个逐位置的两层 MLP:
\text{FFN}(x) = W_2 \cdot \sigma(W_1 x + b_1) + b_2
其中:
W_1 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}} ;W_2 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}} ;\sigma 是 ReLU 或 GELU 等非线性;通常 {\text{ff}} = 4 \cdot d_{\text{model}}自注意力解决“和谁交互”的问题,FFN 则在每个 token 自己的通道维度上,做一遍非线性变换,提升表达力。
2.2 GLU Serious
SwiGLU 属于 GLU(Gated Linear Unit)家族。GLU 的典型形式是: \text{GLU}(x) = (W^v x) \odot \sigma(W^g x)
也就是用两条线性变换:
一条生成 value(信息本体);一条生成 gate(门控因子);然后用 gate 去控制 value 的通过程度。
在 LLaMA 等模型中,用的是 SwiGLU 变体,大致可以写成:
\text{SwiGLU}(x) = \big(W^v x\big) \odot \text{SiLU}(W^g x)
其中 SiLU 激活为:
\text{SiLU}(z) = z \cdot \sigma(z)
代码手撕实现import torchimport torch.nn as nnimport torch.nn.functional as Fclass SwiGLUFFN(nn.Module): def __init__(self, d_model, d_ff=4096, dropout=0.1): super().__init__() # 一次性投影到 2 * d_ff,然后一分为二:gate + value self.w1 = nn.Linear(d_model, 2 * d_ff) self.w2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) def forward(self, x): """ x: [B, L, d_model] """ x_proj = self.w1(x) # [B, L, 2*d_ff] gate, value = x_proj.chunk(2, dim=-1) # 各 [B, L, d_ff] # SwiGLU:SiLU(gate) * value x = F.silu(gate) * value x = self.w2(self.dropout(x)) return x
? 2. 为什么大模型更喜欢用 SwiGLU?
标准 FFN 只是一条 MLP 路径,所有通道共享同一个激活函数。而 SwiGLU 用两个投影产生 gate 和 value,再用 SiLU(gate) 做门控,让不同通道的信息流可以被独立控制,在同样的参数规模下提升表达能力。实验上,在 LLaMA / PaLM 等模型中,SwiGLU 相比简单的 GELU/ReLU 有更好的收敛和下游表现。
三、Decoder Block 代码实现
本章将四件套组合起来,编写一个Decoder代码:
import mathimport torchimport torch.nn as nnclass RotaryEmbedding(nn.Module): """ RoPE 位置编码模块: - 只负责根据 head_dim + seq_len 生成 cos/sin - 不直接改 Q/K,在外面用 apply_rotary_pos_emb 处理 """ def __init__(self, head_dim: int, max_position_embeddings: int = 4096, base: float = 10000.0): super().__init__() assert head_dim % 2 == 0, "head_dim 必须是偶数,才能两两配对旋转" self.head_dim = head_dim self.max_position_embeddings = max_position_embeddings # inv_freq: [head_dim/2] # 对应论文里的 1 / base^{2i/d} inv_freq = 1.0 / (base ** (torch.arange(0, head_dim, 2, dtype=torch.float32) / head_dim)) self.register_buffer("inv_freq", inv_freq) # 不参与训练 # 预先算好最大长度的 cos/sin,后面按 seq_len 切片 self._build_cache(max_position_embeddings) def _build_cache(self, max_seq_len: int): # t: [max_seq_len] t = torch.arange(max_seq_len, dtype=torch.float32, device=self.inv_freq.device) # freqs: [max_seq_len, head_dim/2] freqs = torch.einsum("i,j->ij", t, self.inv_freq) # 扩成 [max_seq_len, head_dim] emb = torch.cat((freqs, freqs), dim=-1) self.register_buffer("cos_cached", emb.cos()[None, None, :, :]) # [1,1,L,D] self.register_buffer("sin_cached", emb.sin()[None, None, :, :]) # [1,1,L,D] def forward(self, seq_len: int, device=None): """ 返回: cos, sin: [1, 1, seq_len, head_dim] """ if seq_len > self.max_position_embeddings: # 超过预设长度就重建缓存(简单写法,够用) self.max_position_embeddings = seq_len self._build_cache(seq_len) cos = self.cos_cached[:, :, :seq_len, :] # [1,1,L,D] sin = self.sin_cached[:, :, :seq_len, :] # [1,1,L,D] if device is not None: cos = cos.to(device) sin = sin.to(device) return cos, sindef rotate_half(x: torch.Tensor) -> torch.Tensor: """ 将最后一维两两配对做 (x1, x2) -> (-x2, x1) x: [..., D] 且 D 为偶数 """ x1, x2 = x.chunk(2, dim=-1) return torch.cat([-x2, x1], dim=-1)def apply_rotary_pos_emb(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor) -> torch.Tensor: """ RoPE 旋转操作: x: [B, H, L, D] cos: [1, 1, L, D] sin: [1, 1, L, D] """ # 广播到 [B,H,L,D] return x * cos + rotate_half(x) * sinclass RoPEMultiHeadAttention(nn.Module): """ 带 RoPE 的多头注意力: - 输入 / 输出: [B, L, d_model] - 内部: 拆成 [B, H, L, Dh],对 Q/K 应用 RoPE """ def __init__(self, d_model, num_heads, dropout=0.0, max_position_embeddings: int = 4096): super().__init__() assert d_model % num_heads == 0 self.d_model = d_model self.num_heads = num_heads self.head_dim = d_model // num_heads self.w_q = nn.Linear(d_model, d_model) self.w_k = nn.Linear(d_model, d_model) self.w_v = nn.Linear(d_model, d_model) self.w_o = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout) # RoPE 模块,专门生成 cos/sin self.rotary_emb = RotaryEmbedding( head_dim=self.head_dim, max_position_embeddings=max_position_embeddings ) def forward(self, x, attn_mask=None): """ x: [B, L, d_model] attn_mask: [B, 1, L, L] 或 [B, L, L],为 0 的位置会被 mask 掉 """ B, L, _ = x.size() device = x.device # 1. 线性投影 Q = self.w_q(x) # [B, L, d_model] K = self.w_k(x) V = self.w_v(x) # 2. 拆成多头 [B, H, L, Dh] def split_heads(t): return t.view(B, L, self.num_heads, self.head_dim).transpose(1, 2) Q = split_heads(Q) # [B, H, L, Dh] K = split_heads(K) V = split_heads(V) # 3. 生成 RoPE 的 cos/sin,并作用在 Q/K 上 cos, sin = self.rotary_emb(seq_len=L, device=device) # [1,1,L,Dh] Q = apply_rotary_pos_emb(Q, cos, sin) # [B,H,L,Dh] K = apply_rotary_pos_emb(K, cos, sin) # 4. 缩放点积注意力 scores = Q @ K.transpose(-2, -1) / (self.head_dim ** 0.5) # [B,H,L,L] if attn_mask is not None: # 根据你项目里 attn_mask 的形状调整,这里假设 0 的地方是 mask 掉 if attn_mask.dim() == 3: attn_mask = attn_mask.unsqueeze(1) # [B,1,L,L] scores = scores.masked_fill(attn_mask == 0, float('-inf')) attn = torch.softmax(scores, dim=-1) attn = self.dropout(attn) out = attn @ V # [B,H,L,Dh] # 5. 合并多头 out = out.transpose(1, 2).contiguous().view(B, L, self.d_model) out = self.w_o(out) # [B,L,d_model] return outclass SwiGLUFFN(nn.Module): def __init__(self, d_model, d_ff=4096, dropout=0.1): super().__init__() self.w1 = nn.Linear(d_model, 2 * d_ff) # gate + value self.w2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) def forward(self, x): x_proj = self.w1(x) # [B, L, 2*d_ff] gate, value = x_proj.chunk(2, dim=-1) # [B,L,d_ff] x2 x = torch.nn.functional.silu(gate) * value # SwiGLU x = self.w2(self.dropout(x)) return xclass RMSNorm(nn.Module): def __init__(self, d_model, eps=1e-8): super().__init__() self.weight = nn.Parameter(torch.ones(d_model)) self.eps = eps def forward(self, x): # x: [B,L,d_model] rms = x.pow(2).mean(dim=-1, keepdim=True).add(self.eps).sqrt() x_norm = x / rms return self.weight * x_normclass DecoderBlockWithRoPE(nn.Module): """ 现代 LLM 风格的 Decoder Block: - RoPE + MHA - RMSNorm + Pre-Norm - SwiGLU FFN """ def __init__(self, d_model, num_heads, d_ff=4096, dropout=0.1, max_position_embeddings: int = 4096): super().__init__() self.self_attn = RoPEMultiHeadAttention( d_model=d_model, num_heads=num_heads, dropout=dropout, max_position_embeddings=max_position_embeddings, ) self.ffn = SwiGLUFFN(d_model, d_ff, dropout) self.norm1 = RMSNorm(d_model) self.norm2 = RMSNorm(d_model) self.dropout = nn.Dropout(dropout) def forward(self, x, attn_mask=None): """ x: [B, L, d_model] """ # 1) Pre-Norm + RoPE Self-Attention h = self.norm1(x) attn_out = self.self_attn(h, attn_mask=attn_mask) x = x + self.dropout(attn_out) # 2) Pre-Norm + SwiGLU FFN h = self.norm2(x) ffn_out = self.ffn(h) x = x + self.dropout(ffn_out) return x四、总结
这一篇我们把另外两件标配武器补齐了:
RoPE:不再给输入加位置向量,而是在 Q/K 空间对每对维度做“旋转”,让注意力点积天然依赖相对位置差,更适合长上下文与外推;SwiGLU:给 FFN 加上一扇“门”,用 gate × value 的方式在通道维度上做细粒度控制,在相似参数量下比普通 GELU/ReLU FFN 更有表达力、训练更稳定。到这里,已经把“现代 LLM 架构四件套:GQA / RoPE / SwiGLU / RMSNorm + Pre-Norm”串成一个整体故事了。
本篇关于《旋转位置编码与SwiGLU解析详解》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
 豆包连接失败怎么解决
豆包连接失败怎么解决
- 上一篇
- 豆包连接失败怎么解决

- 下一篇
- 悟空浏览器最新版官网下载入口
-
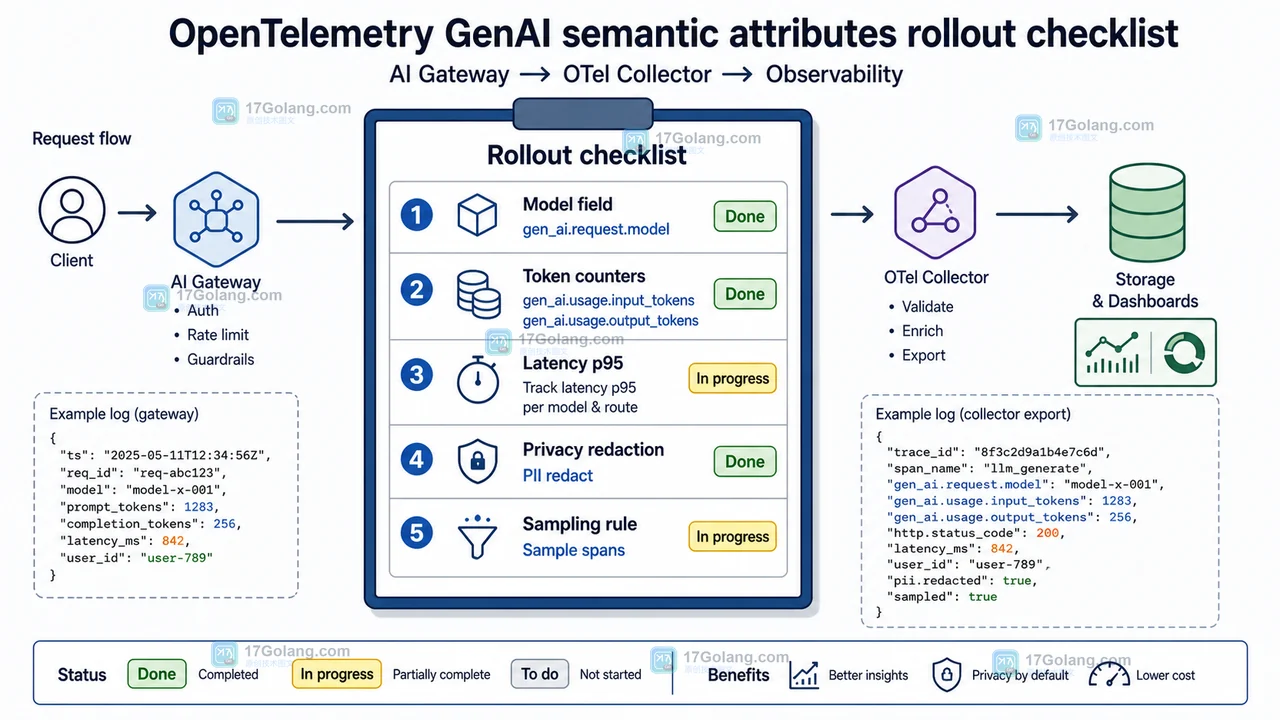
- 科技周边 · 人工智能 | 6天前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计
- AI 调用可观测架构:从散乱日志到 OpenTelemetry GenAI 字段统一
- 427浏览 收藏
-
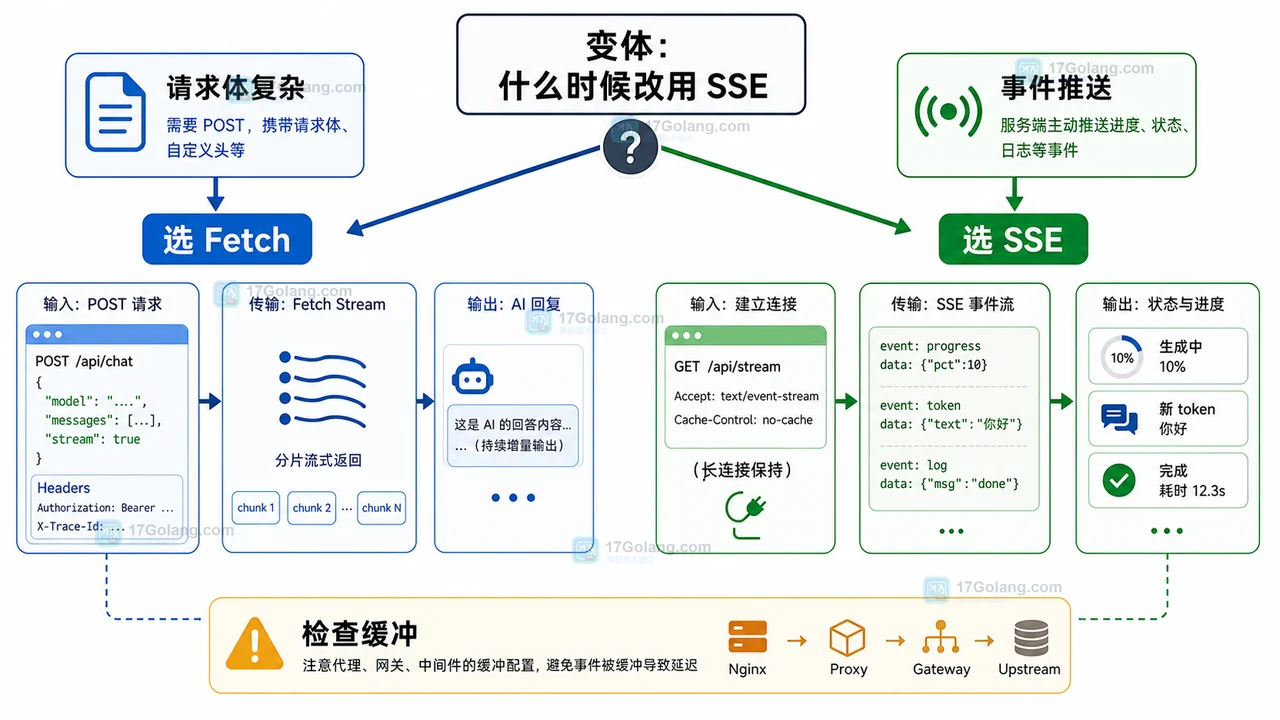
- 科技周边 · 人工智能 | 1星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream
- AI 聊天流式输出前端配方:用 Fetch Stream 实现逐字渲染和中断控制
- 448浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4372次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4052次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4037次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4222次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4190次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


