强化学习十二:GRPO、DAPO、DUPO、GSPO解析
大家好,今天本人给大家带来文章《强化学习十二:GRPO、DAPO、DUPO、GSPO详解》,文中内容主要涉及到,如果你对科技周边方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
在之前的强化学习系列中我们介绍了强化学习的基础知识,也在系列十和系列十一中介绍了强化学习RL在LLM中的应用。
最近我在介绍DeepResearch Agent的论文分享中讨论过从高质量数据合成,Agentic增量预训练(CPT),有监督微调(SFT)冷启动,到强化学习(RL)全流程的方法。但是介绍过程中重点在数据和论文方案思路框架上,RL算法部分都略过了。因为我发现每篇论文都在使用不同的RL方法,每个都详细介绍篇幅太长,不如将这些RL方法单独做一篇详细聊聊。
PPO在LLM的应用就不用再介绍了,系列十已经聊过,所以本文就介绍一些PPO的优化方案。
GRPO:Group Relative Policy Optimization
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
论文链接:https://arxiv.org/pdf/2402.03300
论文主要介绍的DeepSeekMath 7B的模型,在 MATH 和 GSM8K 等基准测试上超越了参数量更大的闭源模型。而提升的原因除了精心设计的数据工程,另一个重要原因就是引入PPO的优化算法GRPO(Group Relative Policy Optimization ),这种方法不仅提升了数学推理能力,也显著降低了训练过程中的显存占用。
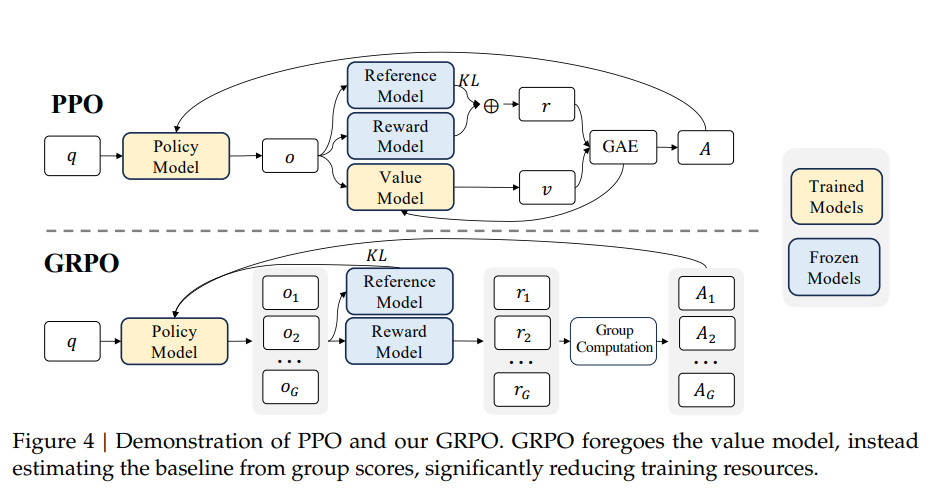
问题和背景
前文介绍过PPO框架中,我们需要有三个模型:
Actor策略模型:负责实际生成内容,是被优化的策略模型。
Reward Model奖励模型:负责给模型生成的完整输出打分,提供训练时的奖励信号。
Critic评论模型:负责估计当前生成状态的价值,用来计算优势,稳定训练过程。
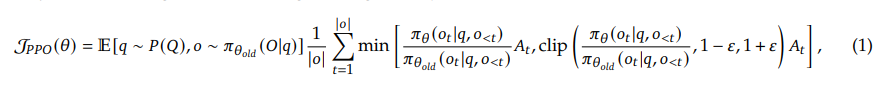
上面就是PPO的优化目标函数。
PPO 的问题在于:Actor 和 Critic 都是大型神经网络,二者需要同时更新,显存开销大;并且 Advantage 的计算依赖一个学习到的价值函数,训练容易不稳定。
论文方案
GRPO的解决方案就是直接去掉了Critic网络。GRPO的核心创新思路很简单:直接剔除Critic,启用群体相对优势。PPO中Critic存在主要就是为了计算优势函数,而什么是优势呢?就需要用Critic模型的值和奖励函数的值作比较得到,也就是它需要一个base基线。PPO用了模型,GRPO认为不就是要base么,我每次取一批数据,将平均值作为base不就好了。所以,它通过在一个批次(Group)的样本中对奖励进行归一化来计算优势函数。
计算公式: 优势函数 \hat{A}_{i,t} ,被计算为当前奖励与组内平均奖励之差,再除以该组奖励的标准差:
核心代码:
import torchimport torch.nn.functional as Fdef compute_sequence_likelihood(model, query, response): """ 计算序列似然度 π_θ(y | x) """ input_ids = torch.cat([query, response], dim=1) outputs = model(input_ids=input_ids) logits = outputs.logits # 获取 response 部分的 logits response_log_probs = F.log_softmax(logits, dim=-1)[:, query.size(1)-1:-1, :] token_log_probs = torch.gather( response_log_probs, dim=2, index=response.unsqueeze(-1) ).squeeze(-1) # 序列级别的对数似然度 return token_log_probs.sum(dim=1)def compute_importance_ratio(model, query, response, old_log_probs): """ 计算序列级别的重要性比率 s_i(θ) = π_θ(y_i | x) / π_θ_old(y_i | x) """ current_log_probs = compute_sequence_likelihood(model, query, response) return torch.exp(current_log_probs - old_log_probs)def compute_normalized_advantages(rewards): """ 计算归一化优势 Ã_i = (r_i - mean(r)) / std(r) """ mean_reward = rewards.mean(dim=-1, keepdim=True) std_reward = rewards.std(dim=-1, keepdim=True).clamp(min=1e-8) return (rewards - mean_reward) / std_rewarddef gspo_loss(model, queries, responses, old_log_probs, rewards, clip_range=0.2): """ GSPO 核心损失函数 J = E[min(s_i * A_i, clip(s_i, 1-ε, 1+ε) * A_i)] """ # 计算重要性比率 importance_ratios = [] for i, response in enumerate(responses): old_log_prob = old_log_probs[:, i] if old_log_probs.dim() > 1 else old_log_probs ratio = compute_importance_ratio(model, queries, response, old_log_prob) importance_ratios.append(ratio) importance_ratios = torch.stack(importance_ratios, dim=1) # [batch, group_size] # 计算归一化优势 advantages = compute_normalized_advantages(rewards) # [batch, group_size] # 序列级别裁剪 clipped_ratios = torch.clamp(importance_ratios, 1.0 - clip_range, 1.0 + clip_range) objective = torch.min( importance_ratios * advantages, clipped_ratios * advantages ) return -objective.mean()
总结
今天关于《强化学习十二:GRPO、DAPO、DUPO、GSPO解析》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于强化学习的内容请关注golang学习网公众号!
 Win10游戏卡顿怎么解决?优化技巧全解析
Win10游戏卡顿怎么解决?优化技巧全解析
- 上一篇
- Win10游戏卡顿怎么解决?优化技巧全解析

- 下一篇
- CSS工具与动画库优化技巧
-

- 科技周边 · 人工智能 | 6小时前 | 豆包AI
- 豆包AI教你赏析诗词技巧
- 238浏览 收藏
-

- 科技周边 · 人工智能 | 6小时前 |
- WorkBuddyLDAP连接问题解决指南
- 263浏览 收藏
-

- 科技周边 · 人工智能 | 6小时前 | 夸克ai搜索
- 夸克AI比价怎么用?超实用教程分享
- 174浏览 收藏
-

- 科技周边 · 人工智能 | 6小时前 | CanvaAI Canva可画
- Canva多图拼贴教程:艺术排版技巧分享
- 166浏览 收藏
-

- 科技周边 · 人工智能 | 6小时前 | CodeGeeX
- CodeGeeX电脑版官方入口地址
- 333浏览 收藏
-

- 科技周边 · 人工智能 | 6小时前 |
- 腾讯元宝长篇人设是否连贯?
- 146浏览 收藏
-

- 科技周边 · 人工智能 | 6小时前 |
- WorkBuddyOpenSSL版本要求与加密问题解决
- 329浏览 收藏
-

- 科技周边 · 人工智能 | 7小时前 |
- Kimi多语言网页总结技巧分享
- 177浏览 收藏
-

- 科技周边 · 人工智能 | 7小时前 |
- WorkBuddyEULA协议重点解读
- 192浏览 收藏
-
- 科技周边 · 人工智能 | 7小时前 | 二狗PPT
- WPS转PPT太麻烦?二狗PPT在线转换省事
- 191浏览 收藏
-

- 科技周边 · 人工智能 | 7小时前 | CodeBuddy
- CodeBuddy生成Redis缓存代码方法解析
- 292浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 5871次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6308次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6113次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8082次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 6510次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


