LangChain.js追踪OpenAIToken与费用教程
还在为LangChain.js追踪OpenAI Token与成本发愁?本文针对LangChain.js用户在使用OpenAI模型时,如何有效追踪Token使用量和成本的问题,提供了一套详细的解决方案。不同于Python版本,LangChain.js没有直接的`get_openai_callback()` API。本文将深入讲解如何通过配置LLM实例的`callbacks`属性,并巧妙运用`handleLLMEnd`回调函数,实时捕获并累计每次模型运行的Token消耗数据。通过本文提供的代码示例和注意事项,开发者可以轻松掌握Token追踪技巧,有效管理和优化LLM应用的成本,提升应用性能。本文重点介绍了模型版本选择、`llmOutput`的可用性、链式调用中的应用,以及成本计算方法,助您玩转LangChain.js,实现精细化运营。

本文旨在解决LangChain.js用户在追踪OpenAI模型Token使用量和成本时遇到的挑战。不同于Python版本提供的`get_openai_callback()`,LangChain.js框架中没有直接对应的API。我们将详细介绍如何通过配置LLM实例的`callbacks`属性,利用`handleLLMEnd`回调函数来实时捕获并累计每次模型运行的Token消耗数据,并提供代码示例及注意事项,帮助开发者有效管理和优化LLM应用成本。
在开发基于大型语言模型(LLM)的应用时,尤其是在使用OpenAI等服务时,精确追踪Token的使用量和相应的成本是至关重要的。这不仅有助于成本控制,还能为模型性能优化提供数据支持。LangChain作为一个强大的LLM应用开发框架,在Python版本中提供了便捷的get_openai_callback()机制来处理这一需求。然而,对于LangChain.js的开发者而言,寻找一个等效且有效的Token追踪方案却是一个常见的困扰。
LangChain.js中Token追踪的挑战
许多从LangChain Python迁移到LangChain.js的开发者会发现,Python版本中方便的get_openai_callback()函数在JavaScript框架中并不存在。尽管尝试通过一些非官方或由聊天机器人生成的代码(例如尝试调用chain.getOpenAICallback())来解决,但这些方法往往无效,因为相关函数在LangChain.js中并不存在。这使得开发者难以直接获取每次LLM调用后的Token消耗数据。
解决方案:利用handleLLMEnd回调函数
LangChain.js提供了一个灵活的回调系统,允许开发者在LLM生命周期的不同阶段注入自定义逻辑。解决Token追踪问题的关键在于利用handleLLMEnd回调函数,它会在每次LLM调用结束时被触发。通过将此回调函数配置到LLM实例中,我们可以在模型完成响应后,从回调参数中提取Token使用量信息。
核心实现步骤
- 导入必要的模块:首先,需要从langchain/chat_models/openai中导入ChatOpenAI类。
- 定义Token计数器:声明全局或模块作用域的变量,用于累积不同类型的Token(例如,totalCompletionTokens、totalPromptTokens、totalExecutionTokens)。
- 配置ChatOpenAI实例:在初始化ChatOpenAI实例时,通过callbacks属性传入一个包含自定义回调对象的数组。
- 实现handleLLMEnd回调:在回调对象中,定义handleLLMEnd方法。此方法接收output、runId等参数。output对象中包含了LLM调用的结果和重要的元数据,包括llmOutput?.tokenUsage,其中包含了completionTokens(完成Token)、promptTokens(提示Token)和totalTokens(总Token)。
- 累积Token数据:在handleLLMEnd函数内部,提取completionTokens、promptTokens和totalTokens,并将其累加到预先定义的计数器中。
示例代码
以下是实现Token追踪的示例代码:
import { ChatOpenAI } from 'langchain/chat_models/openai';
import { BaseMessage } from 'langchain/schema';
// 定义用于累积Token使用量的变量
let totalCompletionTokens = 0; // 模型生成的Token数量
let totalPromptTokens = 0; // 用户输入的提示Token数量
let totalExecutionTokens = 0; // 总Token数量 (提示Token + 完成Token)
// 初始化ChatOpenAI实例,并配置回调函数
const llm = new ChatOpenAI({
// 配置callbacks属性,传入一个回调函数数组
callbacks: [
{
// handleLLMEnd 在每次LLM调用结束时触发
handleLLMEnd: (output, runId, parentRunId?, tags?) => {
// 从 output.llmOutput?.tokenUsage 中获取Token使用详情
const { completionTokens, promptTokens, totalTokens } = output.llmOutput?.tokenUsage || {};
// 累加Token数量,使用 ?? 0 确保在值为 undefined 时默认为 0
totalCompletionTokens += completionTokens ?? 0;
totalPromptTokens += promptTokens ?? 0;
totalExecutionTokens += totalTokens ?? 0;
console.log(`--- LLM Run ${runId} Ended ---`);
console.log(`Prompt Tokens: ${promptTokens ?? 0}`);
console.log(`Completion Tokens: ${completionTokens ?? 0}`);
console.log(`Total Tokens for this run: ${totalTokens ?? 0}`);
console.log(`Current Accumulated Total Tokens: ${totalExecutionTokens}`);
},
},
],
// 指定模型名称,注意某些模型版本可能对Token统计有特定要求
modelName: 'gpt-3.5-turbo-0613',
// 其他配置,例如温度等
temperature: 0.7,
});
// 示例:执行一次LLM调用
async function runLLMExample() {
console.log("Starting LLM call...");
const messages: BaseMessage[] = [
{ role: "user", content: "请用一句话描述什么是人工智能?" }
];
const result = await llm.call(messages);
console.log("LLM Response:", result.content);
// 可以在此处或后续需要时打印累积的Token数量
console.log("\n--- Overall Token Usage ---");
console.log(`Total Prompt Tokens: ${totalPromptTokens}`);
console.log(`Total Completion Tokens: ${totalCompletionTokens}`);
console.log(`Total Execution Tokens: ${totalExecutionTokens}`);
}
// 调用示例函数
runLLMExample().catch(console.error);
// 示例:在链中使用LLM
// 如果你使用的是ConversationalRetrievalQAChain等链,
// 只要该链内部使用了上面配置的llm实例,
// 同样会自动触发handleLLMEnd回调并累积Token。
/*
import { ConversationalRetrievalQAChain } from "langchain/chains";
import { BufferMemory } from "langchain/memory";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
async function runChainExample() {
const vectorStore = await MemoryVectorStore.fromTexts(
["LangChain 是一个用于开发由语言模型驱动的应用程序的框架。", "它简化了与大型语言模型的交互。"],
[{ id: 1 }, { id: 2 }],
new OpenAIEmbeddings()
);
const chain = ConversationalRetrievalQAChain.fromLLM(
llm, // 使用上面配置了回调的llm实例
vectorStore.asRetriever(),
{
memory: new BufferMemory({
memoryKey: "chat_history", // 必须与链的 memoryKey 匹配
inputKey: "question",
outputKey: "text",
returnMessages: true,
}),
returnSourceDocuments: true,
}
);
console.log("\nStarting Chain call...");
const res = await chain.call({
question: "什么是LangChain?",
chat_history: []
});
console.log("Chain Response:", res.text);
console.log("\n--- Overall Token Usage After Chain ---");
console.log(`Total Prompt Tokens: ${totalPromptTokens}`);
console.log(`Total Completion Tokens: ${totalCompletionTokens}`);
console.log(`Total Execution Tokens: ${totalExecutionTokens}`);
}
// runChainExample().catch(console.error);
*/注意事项与成本计算
- 模型版本与类型:根据原始问题和答案,特别提到将模型设置为'gpt-3.5-turbo-0613'时,Token统计功能在ChatOpenAI中表现良好。这可能意味着某些旧版本模型或非ChatOpenAI类的LLM实例在Token统计方面可能存在差异或限制。建议开发者在使用时,根据实际情况测试所选模型和LLM类的Token报告行为。
- llmOutput的可用性:output.llmOutput对象可能不总是存在或包含tokenUsage属性。在代码中,使用可选链操作符(?.)和空值合并运算符(??)来安全地访问这些属性,并在它们缺失时提供默认值(如0),以避免运行时错误。
- 链(Chain)中的应用:当您将这个配置了回调函数的llm实例传递给LangChain中的各种链(如ConversationalRetrievalQAChain)时,只要链内部调用了该llm实例,handleLLMEnd回调就会自动触发,从而实现对整个链运行过程中LLM调用的Token追踪。
- 成本计算:获取到Token使用量后,计算实际成本相对简单。您需要查阅OpenAI的官方定价页面,获取您所使用模型的每千Token价格。例如,如果gpt-3.5-turbo的提示Token价格为$0.0015/1K tokens,完成Token价格为$0.002/1K tokens,那么: 总成本 = (totalPromptTokens / 1000) * 提示Token价格 + (totalCompletionTokens / 1000) * 完成Token价格 请注意,不同模型和版本(如gpt-4系列)的定价策略可能不同,务必参考最新官方文档。
- 异步操作与并发:如果您的应用涉及多个并发的LLM调用,并且所有调用都共享同一个llm实例,那么全局的totalCompletionTokens等变量将会累积所有调用的Token。如果需要按用户会话或特定任务进行隔离的Token追踪,您可能需要将这些计数器封装在更细粒度的作用域内,例如每个请求或每个用户会话创建一个新的llm实例或一个专门的Token统计对象。
总结
尽管LangChain.js没有像Python版本那样直接的get_openai_callback()函数,但通过利用其灵活的callbacks机制和handleLLMEnd回调,我们依然可以有效地追踪OpenAI模型的Token使用量。这种方法不仅提供了精确的Token数据,也为开发者进行成本分析和性能优化奠定了基础。理解并正确应用这一技术,将帮助您更好地管理和维护基于LangChain.js的LLM应用。
理论要掌握,实操不能落!以上关于《LangChain.js追踪OpenAIToken与费用教程》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
 Golangreflect方法调用全解析
Golangreflect方法调用全解析
- 上一篇
- Golangreflect方法调用全解析

- 下一篇
- PHP处理异常JSON:读取与遍历方法
-
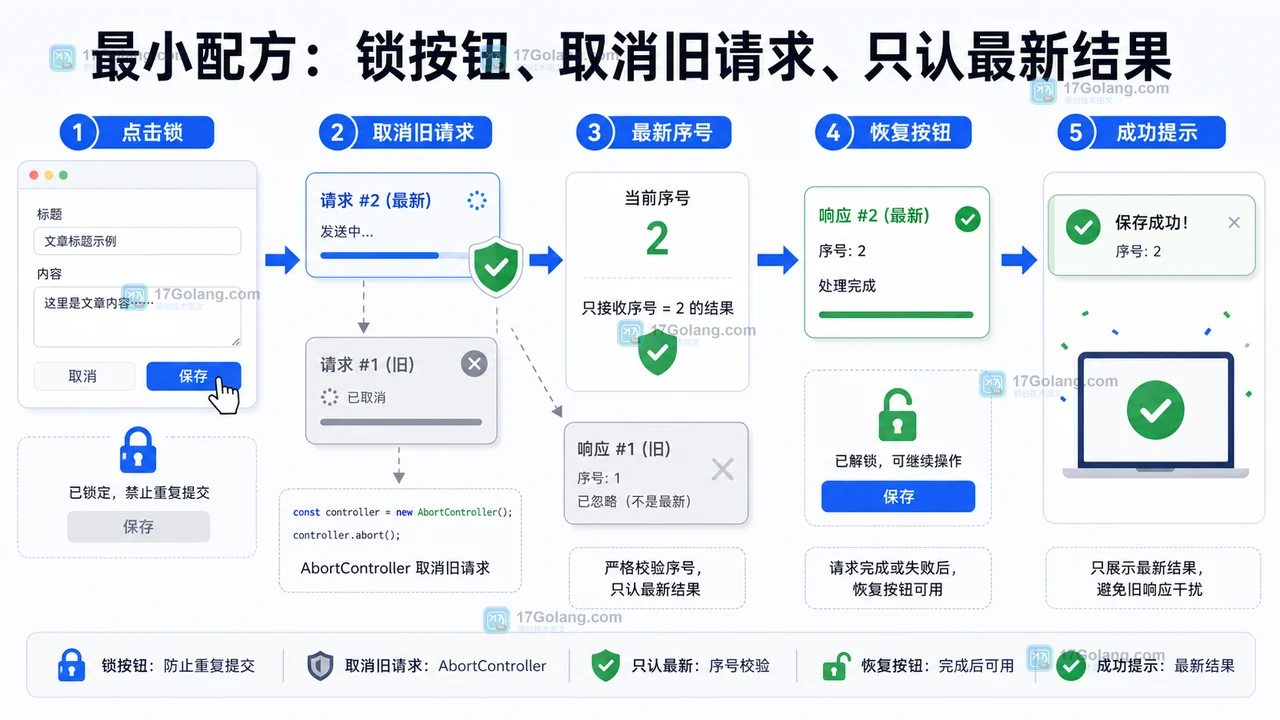
- 文章 · 前端 | 3小时前 | 前端 · javascript · AbortController · 表单提交 · AbortController 旧响应覆盖 前端重复提交 loading锁 fetch取消 按钮防抖
- 前端按钮重复提交怎么办:loading 锁和 AbortController 最小配方
- 442浏览 收藏
-
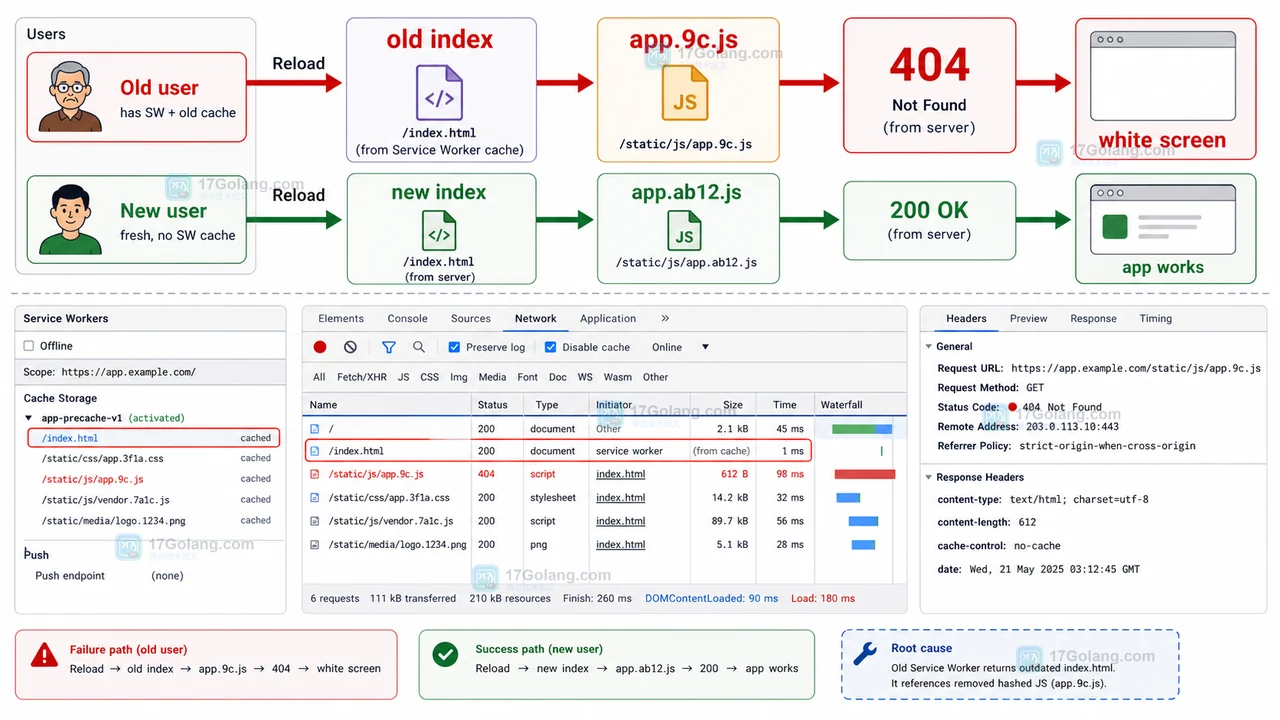
- 文章 · 前端 | 1天前 | 前端 · 缓存 · Service Worker · 白屏 · 发布故障 · 缓存策略 前端白屏 Service Worker CacheStorage 资源404 发布回滚
- 前端发布后白屏复盘:Service Worker 缓存旧入口导致 JS 资源 404
- 469浏览 收藏
-
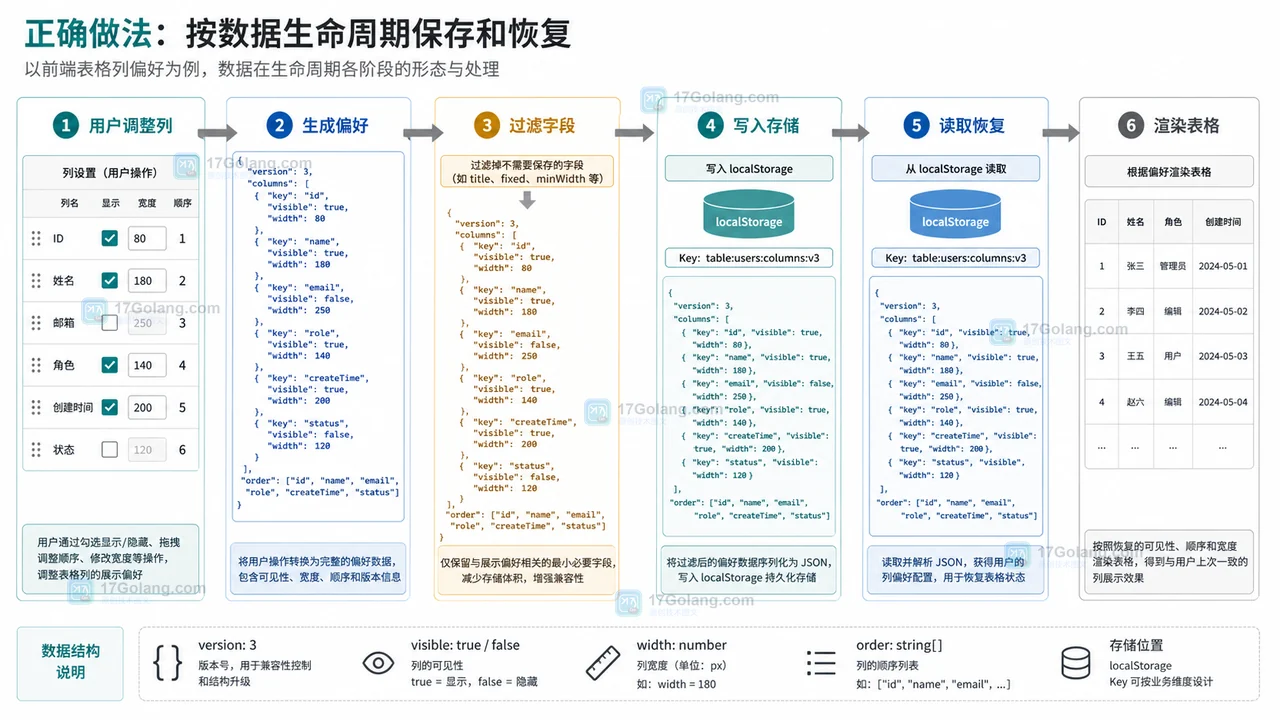
- 文章 · 前端 | 1天前 | 前端开发 · localStorage · 表格配置 · 用户偏好 · 后台系统 · 用户偏好 localStorage 前端表格 列配置 可见列 列宽保存
- 前端表格列设置刷新后丢失怎么办:可见列、列宽和顺序这样保存
- 351浏览 收藏
-
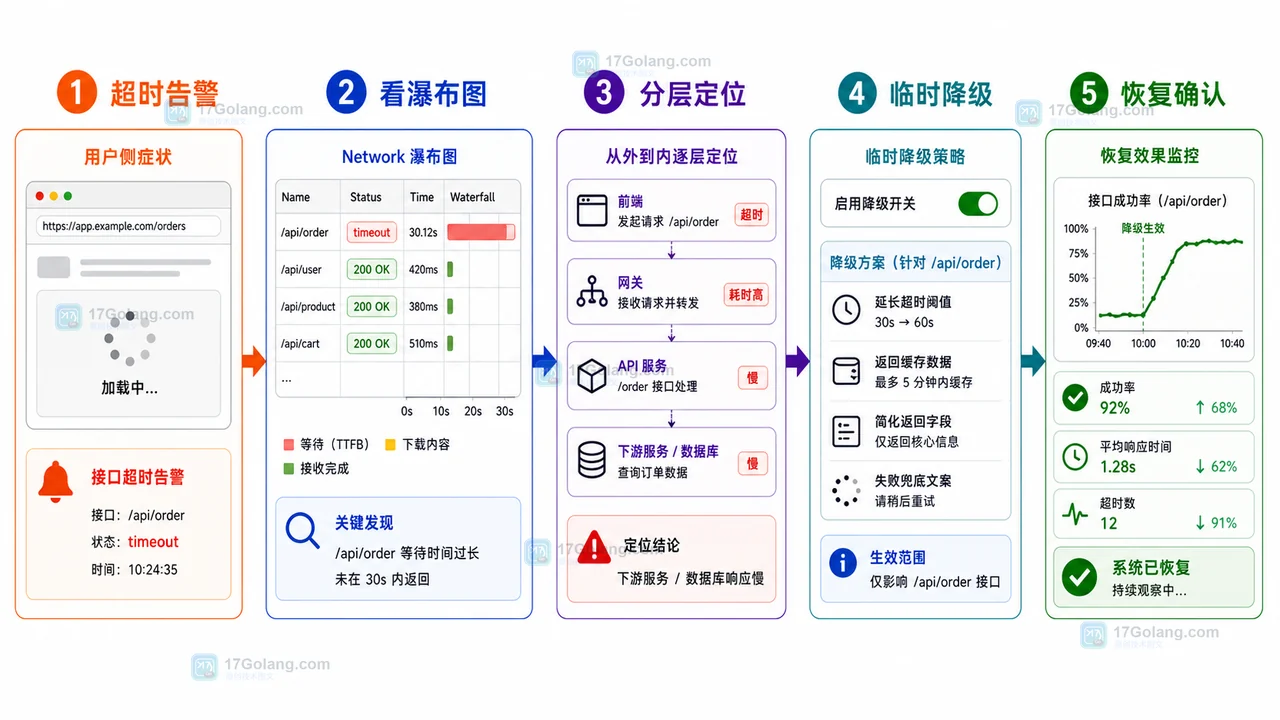
- 文章 · 前端 | 2天前 | 前端 · 接口排查 · 运维手册 · 性能告警 · 前端 AbortController 接口超时 Network瀑布图 降级回滚 线上告警
- 前端接口超时告警运行手册:从瀑布图到降级回滚
- 287浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3157次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2919次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2872次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3078次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3033次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- CSS变量简化按钮悬停效果技巧
- 2026-05-31 501浏览
-
- JavaScript符号类型详解与应用
- 2026-05-31 501浏览
-
- HTML剪贴板复制粘贴怎么用
- 2026-05-26 501浏览
-
- data-*属性详解:HTML数据存储与DOM操作技巧
- 2026-05-25 501浏览


