一个Pod调度失败后重新触发调度的所有情况分析
编程并不是一个机械性的工作,而是需要有思考,有创新的工作,语法是固定的,但解决问题的思路则是依靠人的思维,这就需要我们坚持学习和更新自己的知识。今天golang学习网就整理分享《一个Pod调度失败后重新触发调度的所有情况分析》,文章讲解的知识点主要包括Pod调度失败、重新触发,如果你对Golang方面的知识点感兴趣,就不要错过golang学习网,在这可以对大家的知识积累有所帮助,助力开发能力的提升。
正文
在 k8s 中一个Pod由于某些原因调度失败后,会被放入调度失败队列,这个队列里面的Pod后面都怎么样了呢?
他们怎么样才能重新获取到”重新做人的机会“呢?这篇文章,我们从源码的角度来看看来龙去脉
在 k8s 中会起两个协程,定期把 backoffQ 和 unscheduledQ 里面的 Pod拿到activeQ里面去
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}
flushUnschedulablePodsLeftover
func (p *PriorityQueue) flushUnschedulablePodsLeftover() {
p.lock.Lock()
defer p.lock.Unlock()
var podsToMove []*framework.QueuedPodInfo
currentTime := p.clock.Now()
for _, pInfo := range p.unschedulablePods.podInfoMap {
lastScheduleTime := pInfo.Timestamp
if currentTime.Sub(lastScheduleTime) > p.podMaxInUnschedulablePodsDuration {
podsToMove = append(podsToMove, pInfo)
}
}
if len(podsToMove) > 0 {
p.movePodsToActiveOrBackoffQueue(podsToMove, UnschedulableTimeout)
}
}
func (p *PriorityQueue) movePodsToActiveOrBackoffQueue(podInfoList []*framework.QueuedPodInfo, event framework.ClusterEvent) {
activated := false
for _, pInfo := range podInfoList {
// If the event doesn't help making the Pod schedulable, continue.
// Note: we don't run the check if pInfo.UnschedulablePlugins is nil, which denotes
// either there is some abnormal error, or scheduling the pod failed by plugins other than PreFilter, Filter and Permit.
// In that case, it's desired to move it anyways.
if len(pInfo.UnschedulablePlugins) != 0 && !p.podMatchesEvent(pInfo, event) {
continue
}
pod := pInfo.Pod
if p.isPodBackingoff(pInfo) {
if err := p.podBackoffQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the backoff queue", "pod", klog.KObj(pod))
} else {
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", event.Label).Inc()
p.unschedulablePods.delete(pod)
}
} else {
if err := p.activeQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the scheduling queue", "pod", klog.KObj(pod))
} else {
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", event.Label).Inc()
p.unschedulablePods.delete(pod)
}
}
}
p.moveRequestCycle = p.schedulingCycle
if activated {
p.cond.Broadcast()
}
}
将在unscheduledQ里面停留时长超过podMaxInUnschedulablePodsDuration(默认是5min)的pod放入到 ActiveQ 或 BackoffQueue,具体是放到哪个队列里面,根据下面规则判断:
- 根据这个Pod尝试被调度的次数,计算这个Pod应该等待下一次调度的时间,计算规则为指数级增长,即按照1s,2s,4s,8s这样的时间进行等待,但是这个等待时间也不会无限增加,会受到 podMaxBackoffDuration(默认10s) 的限制,这个参数的意思是一个 Pod处于Backoff的最大时间,如果等待的时间如果超过了 podMaxBackoffDuration,那么就只等待 podMaxBackoffDuration 就会再次被调度;
- 当前时间 - 上次调度的时间 > 根据1获取到的应该等待的时间,那么就把Pod放到activeQ里面,将会被调度,否则Pod被放入 backoff 队列里继续等待,如果是在backoff 队列等待的话,后面就会被flushBackoffQCompleted取出
所以这里 Pod 如果满足条件的话 就一定会从unscheduleQ里面移到 backooff里面或者activeQ里面
flushBackoffQCompleted
去取 backoff 队列(优先队列)里面取等待时间结束的 Pod,放入 activeQ
func (p *PriorityQueue) flushBackoffQCompleted() {
p.lock.Lock()
defer p.lock.Unlock()
activated := false
for {
rawPodInfo := p.podBackoffQ.Peek()
if rawPodInfo == nil {
break
}
pod := rawPodInfo.(*framework.QueuedPodInfo).Pod
boTime := p.getBackoffTime(rawPodInfo.(*framework.QueuedPodInfo))
if boTime.After(p.clock.Now()) {
break
}
_, err := p.podBackoffQ.Pop()
if err != nil {
klog.ErrorS(err, "Unable to pop pod from backoff queue despite backoff completion", "pod", klog.KObj(pod))
break
}
p.activeQ.Add(rawPodInfo)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", BackoffComplete).Inc()
activated = true
}
if activated {
p.cond.Broadcast()
}
}
那么除了上述定期主动去判断一个 UnscheduledQ 或 backoffQ 里面的Pod是不是可以再次被调度,那么还有没有其他情况呢?
答案是有的。
还有四种情况会重新判断这两个队列里的 Pod 是不是要重新调度
- 有新节点加入集群
- 节点配置或状态发生变化
- 已经存在的 Pod 发生变化
- 集群内有Pod被删除
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.addNodeToCache,
UpdateFunc: sched.updateNodeInCache,
DeleteFunc: sched.deleteNodeFromCache,
},
)
新加入节点
func (sched *Scheduler) addNodeToCache(obj interface{}) {
node, ok := obj.(*v1.Node)
if !ok {
klog.ErrorS(nil, "Cannot convert to *v1.Node", "obj", obj)
return
}
nodeInfo := sched.Cache.AddNode(node)
klog.V(3).InfoS("Add event for node", "node", klog.KObj(node))
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(queue.NodeAdd, preCheckForNode(nodeInfo))
}
func preCheckForNode(nodeInfo *framework.NodeInfo) queue.PreEnqueueCheck {
// Note: the following checks doesn't take preemption into considerations, in very rare
// cases (e.g., node resizing), "pod" may still fail a check but preemption helps. We deliberately
// chose to ignore those cases as unschedulable pods will be re-queued eventually.
return func(pod *v1.Pod) bool {
admissionResults := AdmissionCheck(pod, nodeInfo, false)
if len(admissionResults) != 0 {
return false
}
_, isUntolerated := corev1helpers.FindMatchingUntoleratedTaint(nodeInfo.Node().Spec.Taints, pod.Spec.Tolerations, func(t *v1.Taint) bool {
return t.Effect == v1.TaintEffectNoSchedule
})
return !isUntolerated
}
}
可以看到,当有节点加入集群的时候,会把unscheduledQ 里面的Pod 依次拿出来做下面的判断:
- Pod 对 节点的亲和性
- Pod 中 Nodename不为空 那么判断新加入节点的Name判断pod Nodename是否相等
- 判断 Pod 中容器对端口的要求是否和新加入节点已经被使用的端口冲突
- Pod 是否容忍了Node的Pod
只有上述4个条件都满足,那么新加入节点这个事件才会触发这个未被调度的Pod加入到 backoffQ 或者 activeQ,至于是加入哪个queue,上面已经分析过了
节点更新
func (sched *Scheduler) updateNodeInCache(oldObj, newObj interface{}) {
oldNode, ok := oldObj.(*v1.Node)
if !ok {
klog.ErrorS(nil, "Cannot convert oldObj to *v1.Node", "oldObj", oldObj)
return
}
newNode, ok := newObj.(*v1.Node)
if !ok {
klog.ErrorS(nil, "Cannot convert newObj to *v1.Node", "newObj", newObj)
return
}
nodeInfo := sched.Cache.UpdateNode(oldNode, newNode)
// Only requeue unschedulable pods if the node became more schedulable.
if event := nodeSchedulingPropertiesChange(newNode, oldNode); event != nil {
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(*event, preCheckForNode(nodeInfo))
}
}
func nodeSchedulingPropertiesChange(newNode *v1.Node, oldNode *v1.Node) *framework.ClusterEvent {
if nodeSpecUnschedulableChanged(newNode, oldNode) {
return &queue.NodeSpecUnschedulableChange
}
if nodeAllocatableChanged(newNode, oldNode) {
return &queue.NodeAllocatableChange
}
if nodeLabelsChanged(newNode, oldNode) {
return &queue.NodeLabelChange
}
if nodeTaintsChanged(newNode, oldNode) {
return &queue.NodeTaintChange
}
if nodeConditionsChanged(newNode, oldNode) {
return &queue.NodeConditionChange
}
return nil
}
首先是判断节点是何种配置发生了变化,有如下情况
- 节点可调度情况发生变化
- 节点可分配资源发生变化
- 节点标签发生变化
- 节点污点发生变化
- 节点状态发生变化
如果某个 Pod 调度失败的原因可以匹配到上面其中一个原因,那么节点更新这个事件才会触发这个未被调度的Pod加入到 backoffQ 或者 activeQ
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedPod(t)
case cache.DeletedFinalStateUnknown:
if _, ok := t.Obj.(*v1.Pod); ok {
// The carried object may be stale, so we don't use it to check if
// it's assigned or not. Attempting to cleanup anyways.
return true
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToCache,
UpdateFunc: sched.updatePodInCache,
DeleteFunc: sched.deletePodFromCache,
},
},
)
已经存在的 Pod 发生变化
func (sched *Scheduler) addPodToCache(obj interface{}) {
pod, ok := obj.(*v1.Pod)
if !ok {
klog.ErrorS(nil, "Cannot convert to *v1.Pod", "obj", obj)
return
}
klog.V(3).InfoS("Add event for scheduled pod", "pod", klog.KObj(pod))
if err := sched.Cache.AddPod(pod); err != nil {
klog.ErrorS(err, "Scheduler cache AddPod failed", "pod", klog.KObj(pod))
}
sched.SchedulingQueue.AssignedPodAdded(pod)
}
func (p *PriorityQueue) AssignedPodAdded(pod *v1.Pod) {
p.lock.Lock()
p.movePodsToActiveOrBackoffQueue(p.getUnschedulablePodsWithMatchingAffinityTerm(pod), AssignedPodAdd)
p.lock.Unlock()
}
func (p *PriorityQueue) getUnschedulablePodsWithMatchingAffinityTerm(pod *v1.Pod) []*framework.QueuedPodInfo {
var nsLabels labels.Set
nsLabels = interpodaffinity.GetNamespaceLabelsSnapshot(pod.Namespace, p.nsLister)
var podsToMove []*framework.QueuedPodInfo
for _, pInfo := range p.unschedulablePods.podInfoMap {
for _, term := range pInfo.RequiredAffinityTerms {
if term.Matches(pod, nsLabels) {
podsToMove = append(podsToMove, pInfo)
break
}
}
}
return podsToMove
}
可以看到,已经存在的Pod发生变化后,会把这个Pod亲和性配置依次和unscheduledQ里面的Pod匹配,如果能够匹配上,那么节点更新这个事件才会触发这个未被调度的Pod加入到 backoffQ 或者 activeQ。
集群内有Pod删除
func (sched *Scheduler) deletePodFromCache(obj interface{}) {
var pod *v1.Pod
switch t := obj.(type) {
case *v1.Pod:
pod = t
case cache.DeletedFinalStateUnknown:
var ok bool
pod, ok = t.Obj.(*v1.Pod)
if !ok {
klog.ErrorS(nil, "Cannot convert to *v1.Pod", "obj", t.Obj)
return
}
default:
klog.ErrorS(nil, "Cannot convert to *v1.Pod", "obj", t)
return
}
klog.V(3).InfoS("Delete event for scheduled pod", "pod", klog.KObj(pod))
if err := sched.Cache.RemovePod(pod); err != nil {
klog.ErrorS(err, "Scheduler cache RemovePod failed", "pod", klog.KObj(pod))
}
sched.SchedulingQueue.MoveAllToActiveOrBackoffQueue(queue.AssignedPodDelete, nil)
}
可以看到,Pod删除时间不像其他时间需要做额外的判断,这个preCheck函数是空的,所以所有 unscheduledQ 里面的Pod都会被放到 activeQ或者backoffQ里面。
从上面的情况,我们可以看到,集群内有事件发生变化,是可以加速调度失败的Pod被重新调度的进程的。常规的是,调度失败的 Pod 需要等5min 然后才会被重新加入 backoff 或 activeQ。backoffQ里面的Pod也需要等一段时间才会重新调度。这也就是为什么,当你修改节点配置的时候,能看到Pod马上重新被调度的原因
上面就是一个Pod调度失败后,重新触发调度的所有情况了。
更多关于Pod调度失败重新触发的资料请关注golang学习网!
终于介绍完啦!小伙伴们,这篇关于《一个Pod调度失败后重新触发调度的所有情况分析》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布Golang相关知识,快来关注吧!
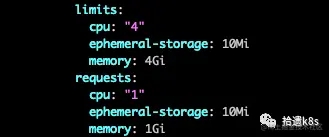 一文详解kubernetes 中资源分配的那些事
一文详解kubernetes 中资源分配的那些事
- 上一篇
- 一文详解kubernetes 中资源分配的那些事
- 下一篇
- 深入string理解Golang是怎样实现的
-
- Golang · Go教程 | 1天前 | golang
- Go 线上故障复盘模板:日志、指标、链路追踪与 pprof 证据闭环
- 710浏览 收藏
-
- Golang · Go教程 | 1天前 | golang
- Go 微服务超时、重试与熔断观测:避免故障放大的实践
- 687浏览 收藏
-
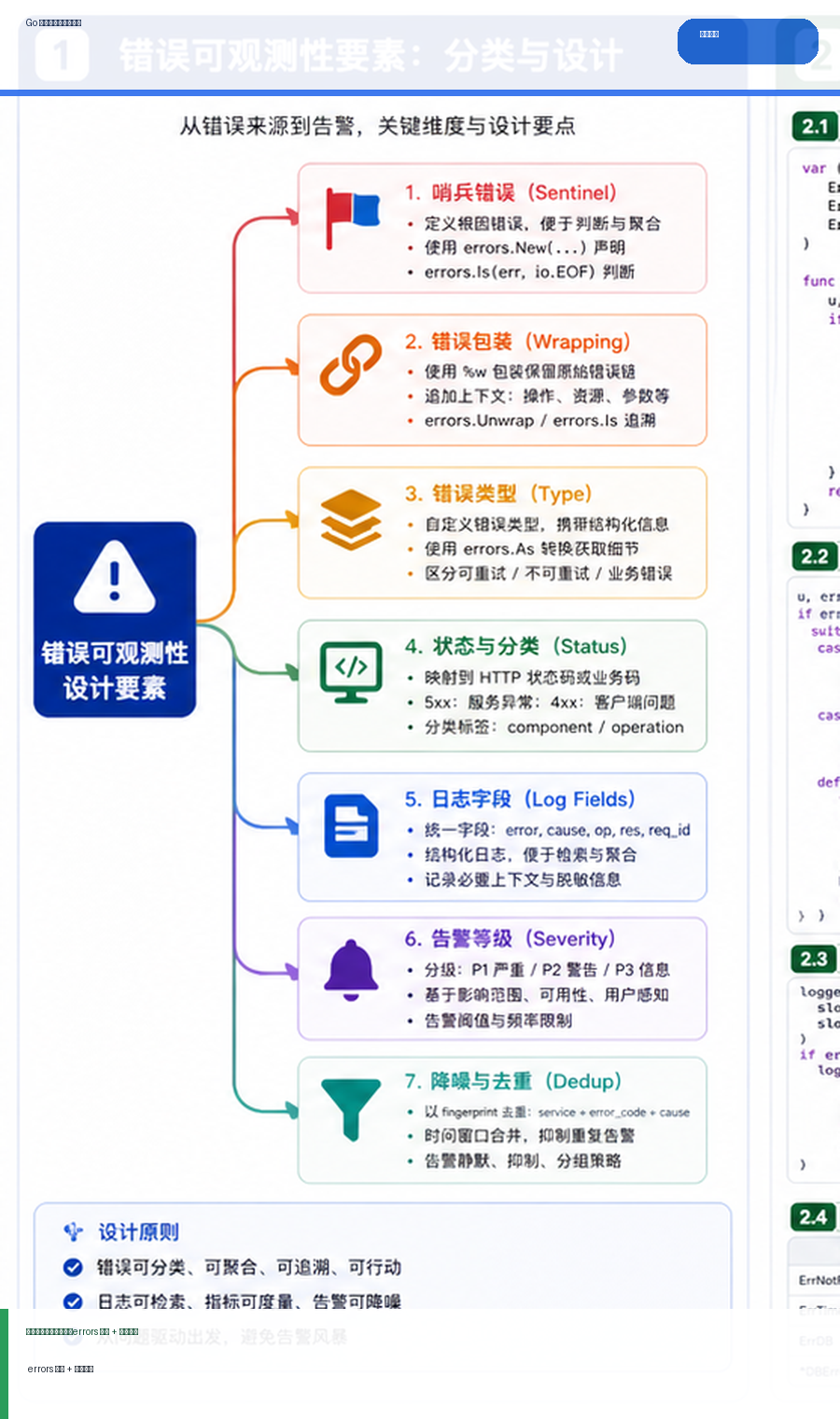
- Golang · Go教程 | 1天前 | golang
- Go 错误处理与告警设计:errors 包装、日志字段与告警降噪
- 664浏览 收藏
-
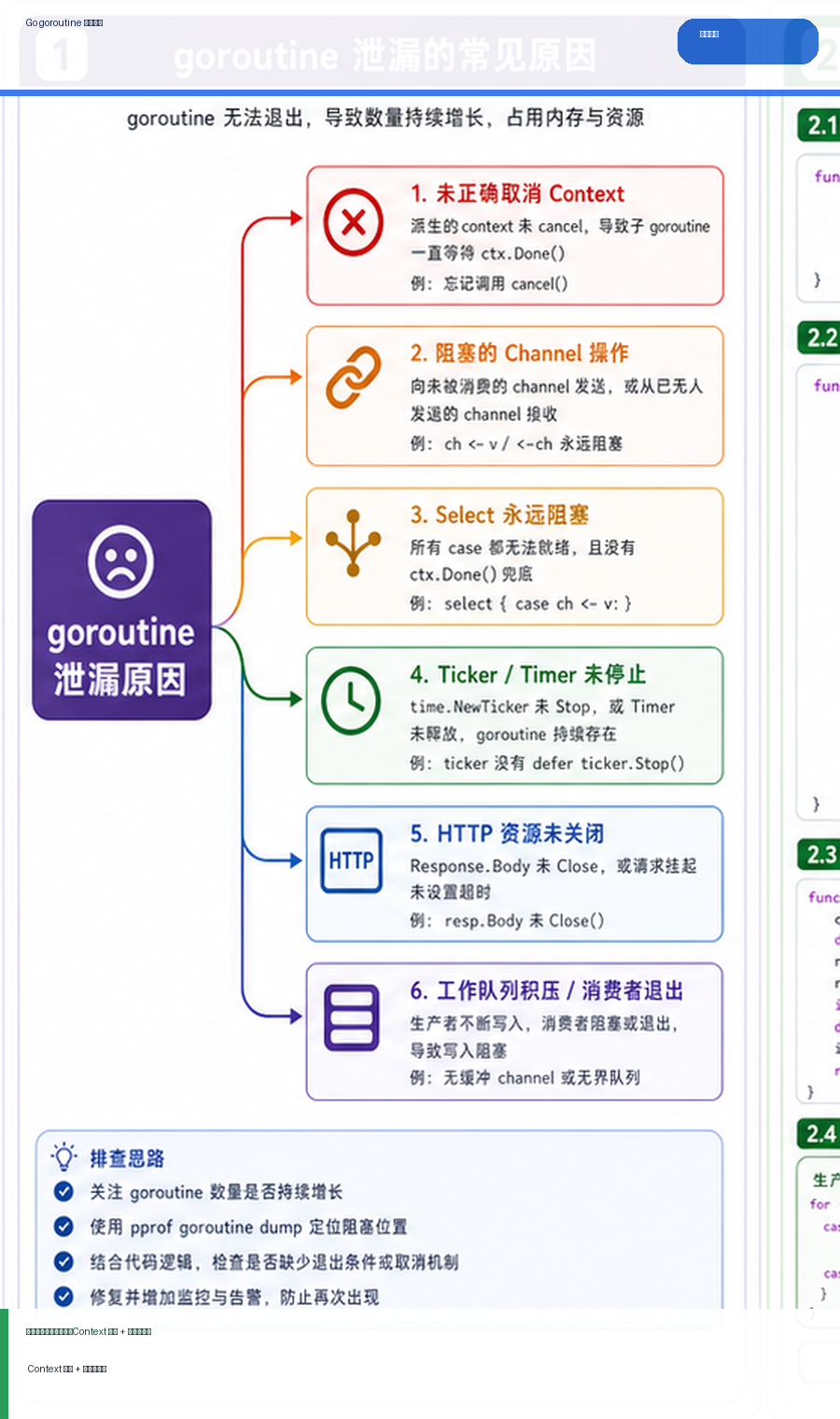
- Golang · Go教程 | 1天前 | golang
- Go goroutine 泄漏排查:Context 取消、阻塞栈与泄漏定位
- 641浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8139次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8568次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8391次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10302次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9189次使用
-
- Java 性能优化上线清单:从定位、改造到灰度发布
- 2026-06-11 860浏览
-
- Spring Boot 压测验证:Gatling、JMeter 与性能回归门禁
- 2026-06-11 843浏览
-
- Java NMT 非堆内存排查:Direct Buffer、线程栈与 Metaspace 分析
- 2026-06-11 826浏览
-
- Spring Boot 容器内存优化:JVM 堆、非堆与 MaxRAMPercentage
- 2026-06-11 809浏览
-
- Tomcat 连接与线程参数调优:maxThreads、acceptCount 与 KeepAlive
- 2026-06-11 792浏览


