如何使用TensorFlow和Keras轻松构建和训练第一个神经网络
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《如何使用TensorFlow和Keras轻松构建和训练第一个神经网络》,聊聊,我们一起来看看吧!
AI技术发展迅猛,利用各种先进的AI模型,可以打造聊天机器人、仿人机器人、自动驾驶汽车等。AI已经成为发展最快的技术,而对象检测和物体分类是最近的趋势。
本文将介绍使用卷积神经网络从头开始构建和训练一个图像分类模型的完整步骤。本文将使用公开的Cifar-10数据集来训练这个模型。这个数据集是独一无二的,因为它包含了像汽车、飞机、狗、猫等日常所见物体的图像。通过对这些物体进行神经网络训练,本文将开发出智能系统来对现实世界中的这些东西进行分类。它包含了6万多张32x32大小的10种不同类型的物体图像。在本教程结束时,你将拥有一个可以根据物体的视觉特征来判断对象的模型。

图1 数据集样本图像|图片来自datasets.activeloop
本文将从头开始讲述所有内容,所以如果你还没有学习过神经网络的实际实现,也完全没问题。
以下是本教程的完整工作流程:
- 导入必要的库
- 加载数据
- 数据的预处理
- 建立模型
- 评估模型的性能
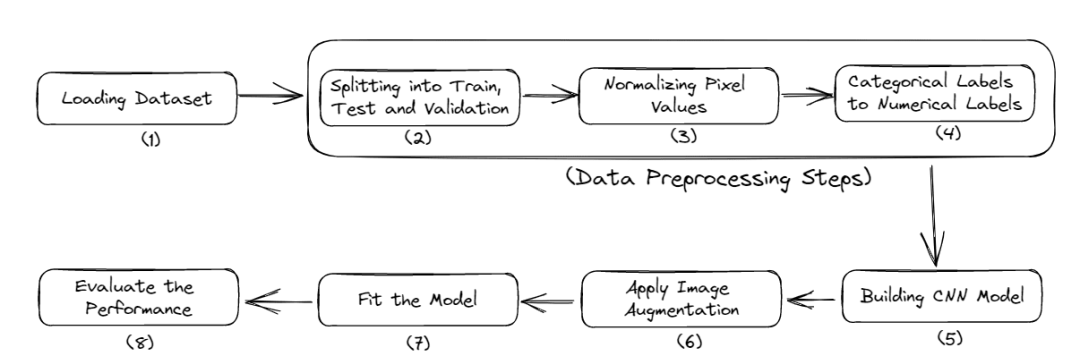
图2 完整的流程
导入必要的库
首先必须安装一些模块才能开始这个项目。本文将使用Google Colab,因为它提供免费的GPU训练。
以下是安装所需库的命令:
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
将库导入到Python文件中。
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>
- Numpy:它用于对包含图像的大型数据集进行高效的数组计算。
- Tensorflow:它是一个由谷歌开发的开源机器学习库。它提供了许多函数来建立大型和可扩展的模型。
- Keras:另一个在TensorFlow之上运行的高级神经网络API。
- Matplotlib:这个Python库可以创建图表,提供更好的数据可视化。
- Sklearn:它提供了对数据集执行数据预处理和特征提取任务的功能。它包含内置的函数,可以找到模型的评估指标,如准确率、精确度、误报、漏报等。
现在,进入数据加载的步骤。
加载数据
本节将加载数据集并执行训练-测试数据的拆分。
加载和拆分数据:
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>cifar10数据集是直接从Keras数据集库中加载的。并且这些数据也分为训练数据和测试数据。训练数据用于训练模型,以便它可以识别其中的模式。而测试数据对模型来说是不可见的,它被用来检查其性能,即相对于总的数据点,有多少数据点被正确预测。
training_label包含了与training_data中的图像对应的标签。
然后使用内置sklearn的train_test_split函数将训练数据再次拆分成验证数据。验证数据用于选择和调整最终的模型。最后,所有的训练、测试和验证数据都转换为32位的浮点数。
现在,数据集的加载已经完成。在下一节中,本文将对其执行一些预处理步骤。
数据的预处理
数据预处理是开发机器学习模型时的第一步,也是最关键的一步。跟随本文一起看看如何做到这一点。
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>输出:
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
该数据集包含10个类别的图像,每个图像的大小为32x32像素。每个像素都有一个0-255的值,我们需要在0-1之间对其进行归一化以简化计算过程。之后,我们将把分类标签转换为单热编码标签。这样做是为了将分类数据转换为数值数据,这样我们就可以毫无问题地应用机器学习算法。
现在,进入CNN模型的构建。
建立CNN模型
CNN模型分三个阶段工作。第一阶段由卷积层组成,从图像中提取相关特征。第二阶段由池化层组成,用于降低图像的尺寸。它也有助于减少模型的过度拟合。第三阶段由密集层组成,将二维图像转换为一维数组。最后,这个数组被送入全连接层,进行最后的预测。
以下是代码:
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
本文应用了三组图层,每组包含两个卷积层、一个最大池化层和一个丢弃层。Conv2D层接收input_shape为(32,32,3),必须与图像的尺寸相同。
每个Conv2D层还需要一个激活函数,即relu。激活函数是用于增加系统中的非线性。更简单地说,它决定神经元是否需要根据某个阈值被激活。有许多类型的激活函数,如ReLu、Tanh、Sigmoid、Softmax等,它们使用不同的算法来决定神经元的激发。
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
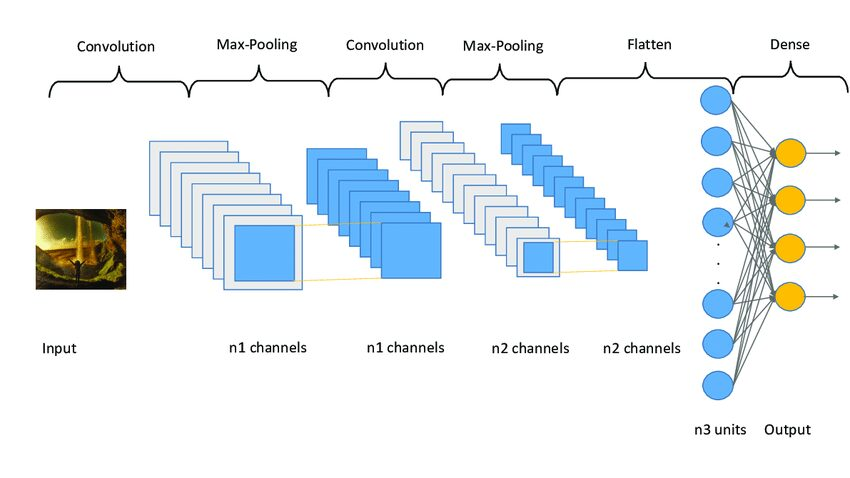
图3 Sampe CNN架构|图片来源:Researchgate
编译模型
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
拟合模型
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:
图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
评估模型性能
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>输出:
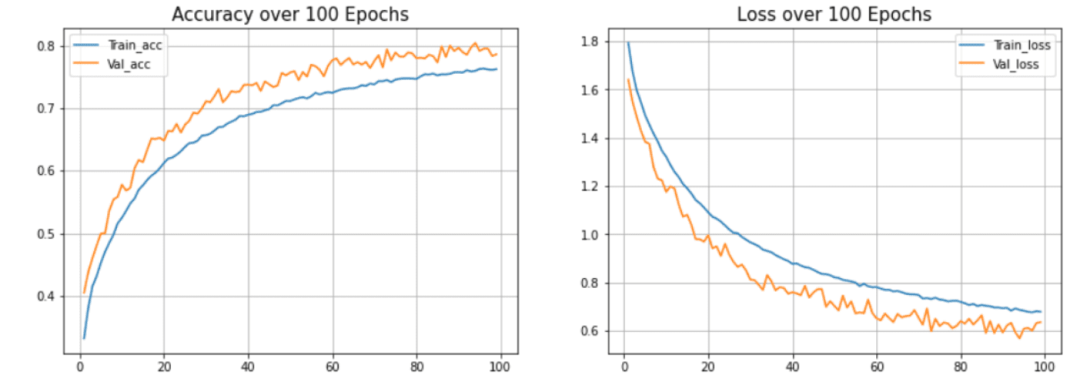
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
总结
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
到这里,我们也就讲完了《如何使用TensorFlow和Keras轻松构建和训练第一个神经网络》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于参数,神经网络,池化层的知识点!
 系统重装不了如何解决
系统重装不了如何解决
- 上一篇
- 系统重装不了如何解决

- 下一篇
- OpenAI威胁起诉开发者,因其借助免费GPT-4聊天机器人而惹上麻烦
-

- 科技周边 · 人工智能 | 19分钟前 |
- 生数科技MotuBrain登顶双榜,定义具身智能新标准
- 321浏览 收藏
-

- 科技周边 · 人工智能 | 20分钟前 |
- Workbuddy隐藏设置开启方法详解
- 250浏览 收藏
-

- 科技周边 · 人工智能 | 31分钟前 |
- Clawdbot集成Notion,AI知识库新玩法
- 117浏览 收藏
-

- 科技周边 · 人工智能 | 32分钟前 |
- Core本地部署成本与运维分析
- 312浏览 收藏
-

- 科技周边 · 人工智能 | 39分钟前 |
- Canva渐变色太生硬?柔化技巧分享
- 496浏览 收藏
-

- 科技周边 · 人工智能 | 49分钟前 |
- 快影AI卡点好用吗\_卡点技巧全解析
- 199浏览 收藏
-

- 科技周边 · 人工智能 | 53分钟前 |
- PerplexityAI与Kimi对比解析
- 334浏览 收藏
-

- 科技周边 · 人工智能 | 55分钟前 | Seedance 2.0
- Seedance2.0注册激活方法详解
- 200浏览 收藏
-

- 科技周边 · 人工智能 | 55分钟前 |
- 零基础学AI,Capybara入门指南
- 239浏览 收藏
-

- 科技周边 · 人工智能 | 57分钟前 |
- PerplexityAI文章大纲生成方法解析
- 444浏览 收藏
-

- 科技周边 · 人工智能 | 1小时前 |
- AI引领游戏开发,谷歌高管解读行业趋势
- 291浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 4431次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 4791次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 4669次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 6454次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 5039次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


