Mysql索引底层及优化方法是什么
大家好,今天本人给大家带来文章《Mysql索引底层及优化方法是什么》,文中内容主要涉及到,如果你对数据库方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!

一.首先我们说下什么是索引,为什么要用索引
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
二. 索引类型分为两类:
1.hash索引
2.bTree
三.下面我们简单分析一下hash索引和bTree索引。
1. 哈希表是一种以键 - 值(key-value)存储数据的结构,我们只要输入待查找的键即 key,就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。
不可避免地,多个 key 值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链表。
2. 说到bTree,就不得不提二叉树,二叉树分为很多,例:二叉查找树,平衡二叉树等。当然还有重点红黑树。
1) 二叉查找树的特点是: 父节点左子树所有节点的值小于父节点的值。右子树所有节点的值大于父节点的值。 下面以一张图为例来体现二叉查找树。
| ID | name |
|---|---|
| 5 | 张五 |
| 6 | 张六 |
| 7 | 张七 |
| 2 | 张二 |
| 1 | 张一 |
| 4 | 张四 |
| 3 | 张三 |
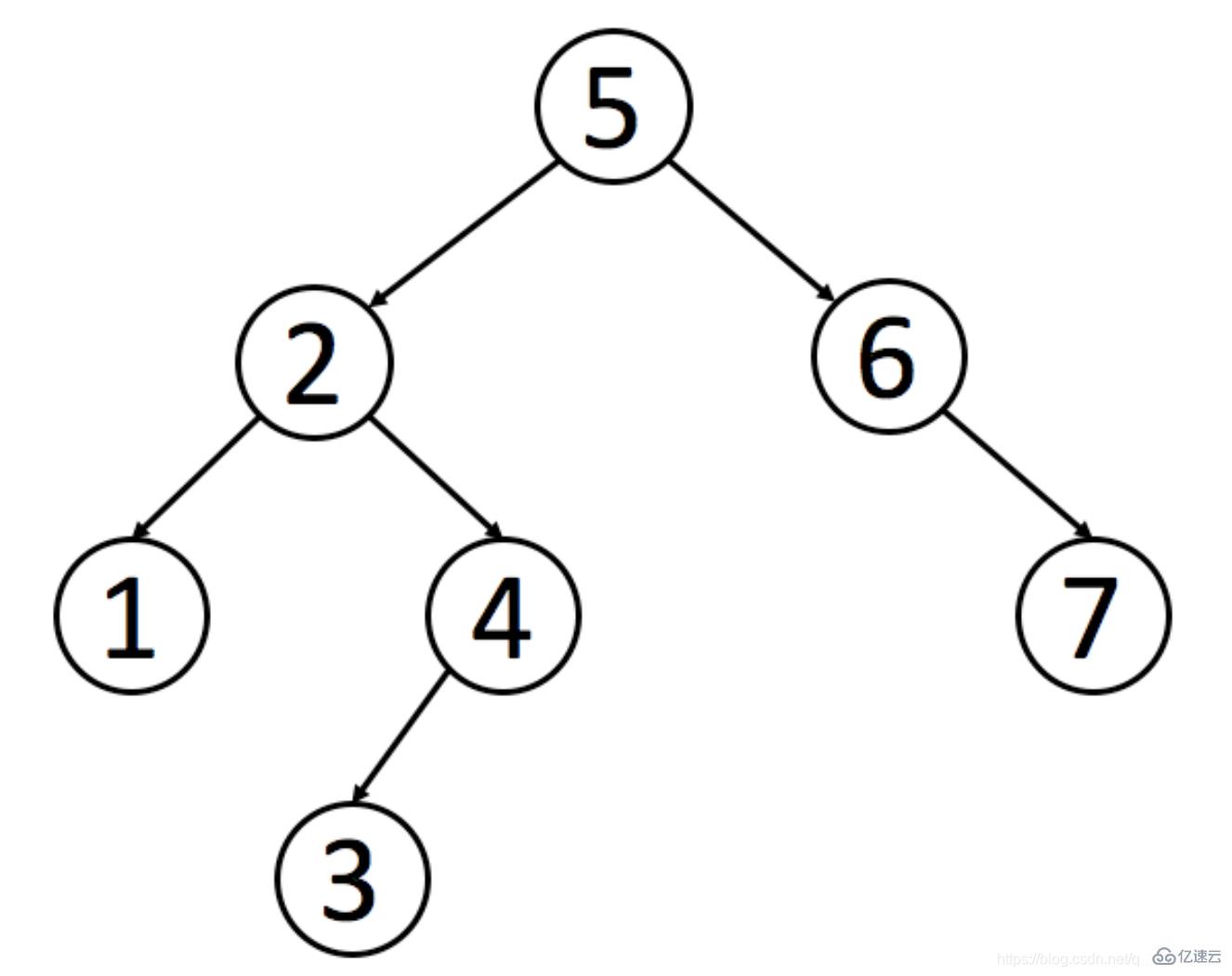 有一个需求,查找张三,如果不使用二叉查找树那么我们需要查找7次,使用二叉查找树我们只需要查找4次就可以找到我们想要的值。
有一个需求,查找张三,如果不使用二叉查找树那么我们需要查找7次,使用二叉查找树我们只需要查找4次就可以找到我们想要的值。
根据上面说的使用二叉查找树的确可以减少查询次数,但是大家有没有想过,如果数据库的数据是 1,2,3,4,5,6,7这样依次递增的数据呢,继续使用二叉查找树就会变成一个链表了。那这样如果我们想要查找7那么需要查找7次,扫描表也是需要7次。这样跟没有建立索引没有区别,这也是弊端之一。下图为例说明。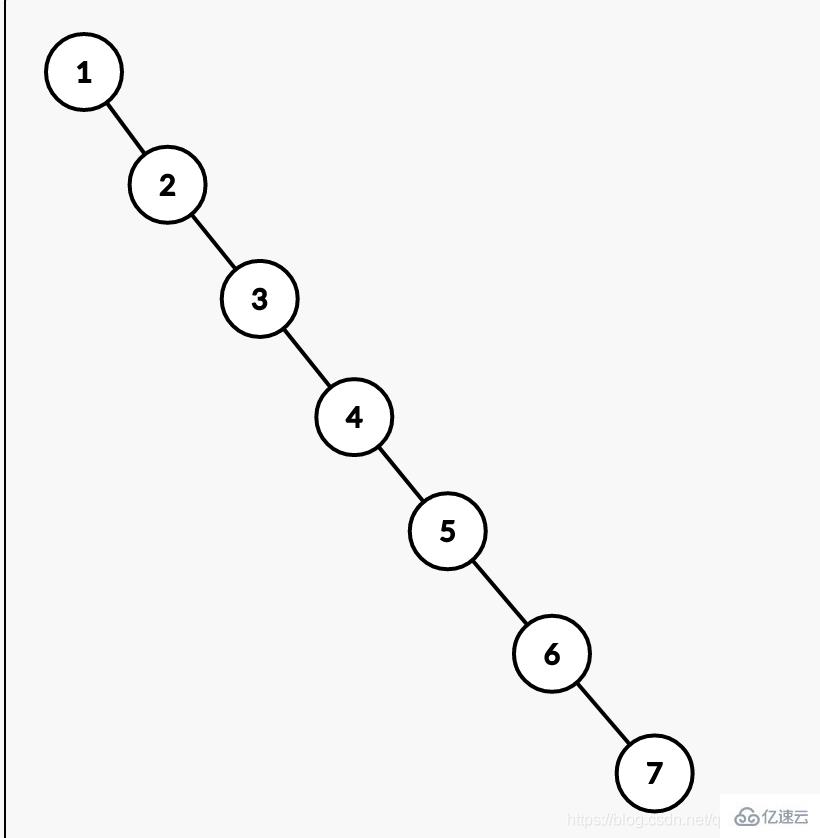
2) 平衡二叉树:又被称为AVL树,它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树,AVL树是最早发明的自平衡二叉查找树。在AVL树中,任何节点的两个子树的高度最大差别只能为1,所以它又被称为高度平衡树。查询、增加和删除在平均和最坏情况下都是O(log n)。增加和删除会需要通过一次或多次树旋转来重新平衡这个树。
我们引入二叉树的目的是为了提高二叉树的搜索的效率,从而减少树的平均搜索长度,为此,就必须在每颗二叉树插入一个结点时调整树的结构,让二叉树搜索能够保持平衡,从而可能降低树的高度,减少的平均树的搜索长度。
平衡二叉树特点如下:
1.它的左子树和右子树都是AVL树
2.左子树和右子树的高度差不能超过1
例图: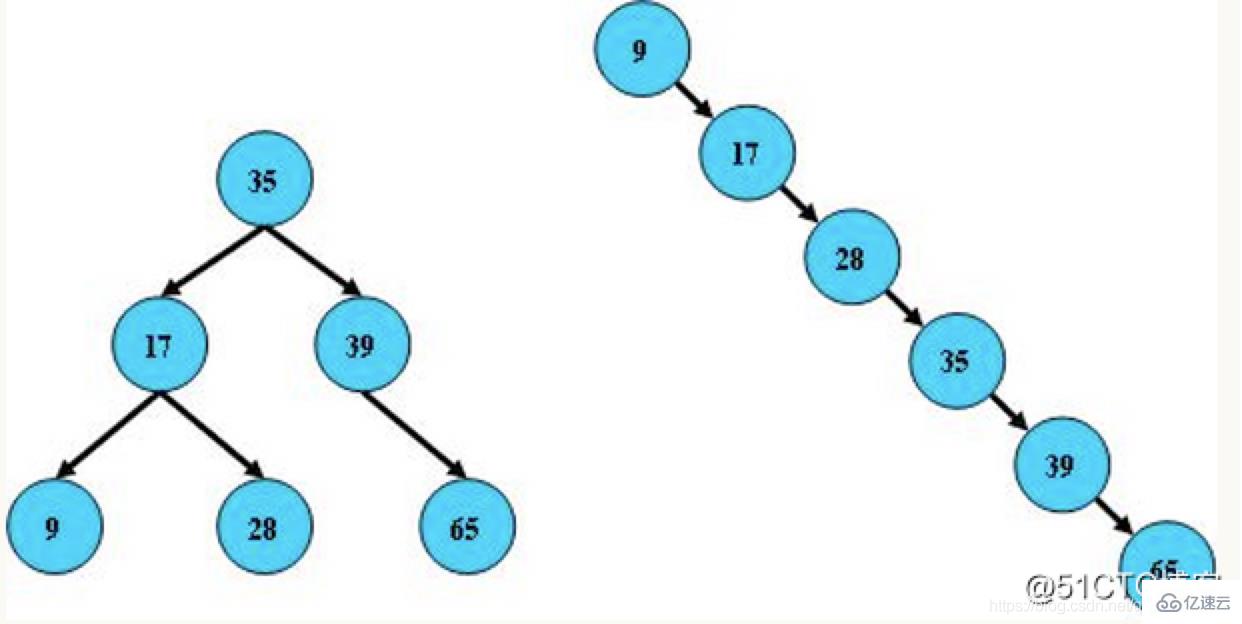 3) 红黑树:可以理解为红黑树是凌驾于平衡二叉树之上的一棵树,红黑树不会追求“完全平衡 ”,它只会求部分达到平衡要求,降低了对旋转的要求,从而提高性能。此外,由于它的设计,所有不平衡都能够在三次旋转之内解决。在红黑树中,它的算法时间复杂度与AVL相同,并且统计性能会逼AVL树更高。所以红黑树相对于平衡二叉树来说,不是严格意义上的平衡二叉树,红黑树插入和删除效率更高一些,查询的效率比平衡二叉树来说相对低一些,但是二者查询效率差值做对比,基本可以忽略不计。红黑树特点如下:
3) 红黑树:可以理解为红黑树是凌驾于平衡二叉树之上的一棵树,红黑树不会追求“完全平衡 ”,它只会求部分达到平衡要求,降低了对旋转的要求,从而提高性能。此外,由于它的设计,所有不平衡都能够在三次旋转之内解决。在红黑树中,它的算法时间复杂度与AVL相同,并且统计性能会逼AVL树更高。所以红黑树相对于平衡二叉树来说,不是严格意义上的平衡二叉树,红黑树插入和删除效率更高一些,查询的效率比平衡二叉树来说相对低一些,但是二者查询效率差值做对比,基本可以忽略不计。红黑树特点如下:
1. 节点是红色或黑色。
2. 根节点是黑色。
3. 每个红色节点的两个子节点都是黑色。(红色节点的子节点必须是黑色节点)
4. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
故红黑树是黑色平衡的树,左子树与右子树高度差不会超过2。红节点的父节点、子节点只能是黑节点。
例图: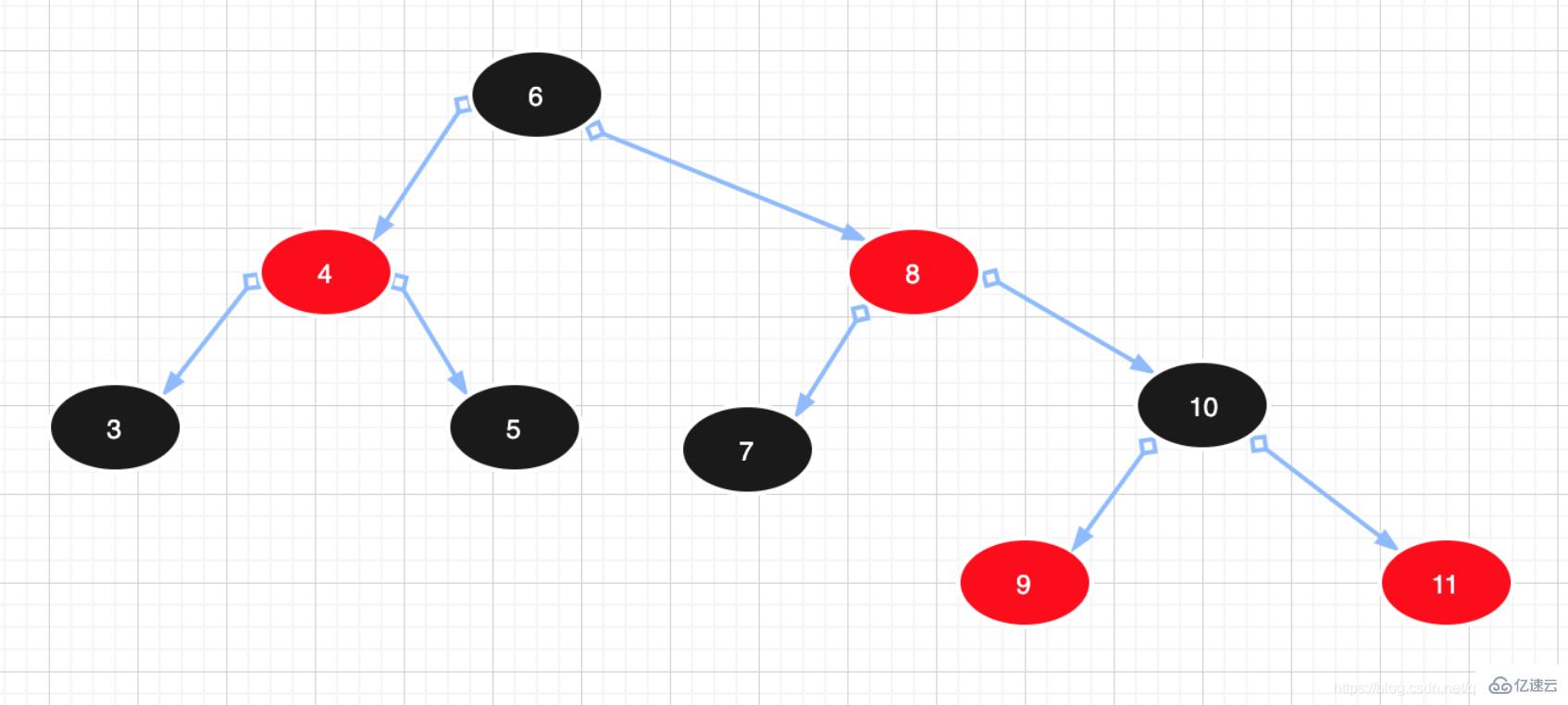
4) BTree(B树):当然上面说到了红黑树,性能非常高。以上图为例,树的高度最高才为4,共9条数据,但是对于Mysql数据库,动则几百万条数据,几千万条数据,那树的高度就不可估量了,比如说上百万条数据需要经过30-50次磁盘IO才能查询到数据,甚至更多的次数,显然不能满足Mysql索引高效的查询效率。那如果我们控制树的高度呢,那这样就会极大减少了请求磁盘IO的请求次数,如果高度控制在4,那只需要经过4次磁盘IO就可以查询到数据。
但是怎么样控制树的高度呢,红黑树是每个节点只存储一个元素,如果每个节点存多个元素呢,这样就可以解决高度问题了,肯定有同学有疑问,把所有的元素都放到一个节点上,那高度值就是1了,不是更快吗?这样想肯定是错的,Mysql每一次跟磁盘IO打交道是有大小限制的,Mysql限制每一个节点的大小是16K。 想查看自己Mysql限制节点大小的同学可以执行下面的sql。
show global status like ‘Innodb_page_size’
下面以图为例体现BTree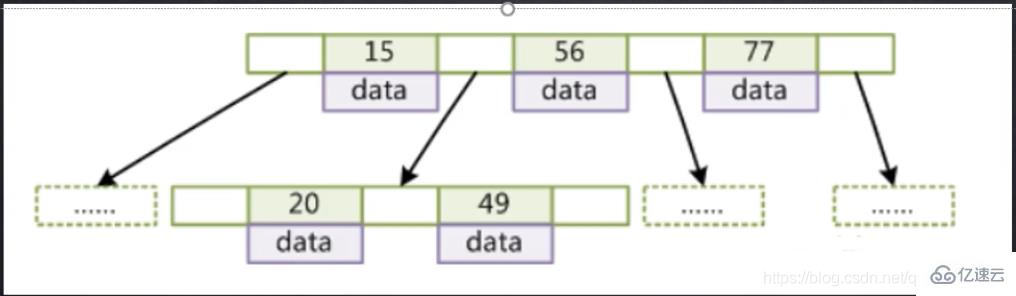 BTree特点如下:
BTree特点如下:
1.所有索引元素不重复
2.节点的数据索引从左到右依次递增
3.叶节点具有相同的深度,叶节点的指针为空
4.叶子节点和非叶子结点都存储索引和数据
5) B+树:上面说到了BTree控制了树的高度的问题,可以满足Mysql对于索引的需求,但是最终Mysq索引实现不是BTree而是B+树,Mysql对B树做了一点点改造,得到了B+树,也可以理解为B+树是B树的升级版。
下面以图为例说明: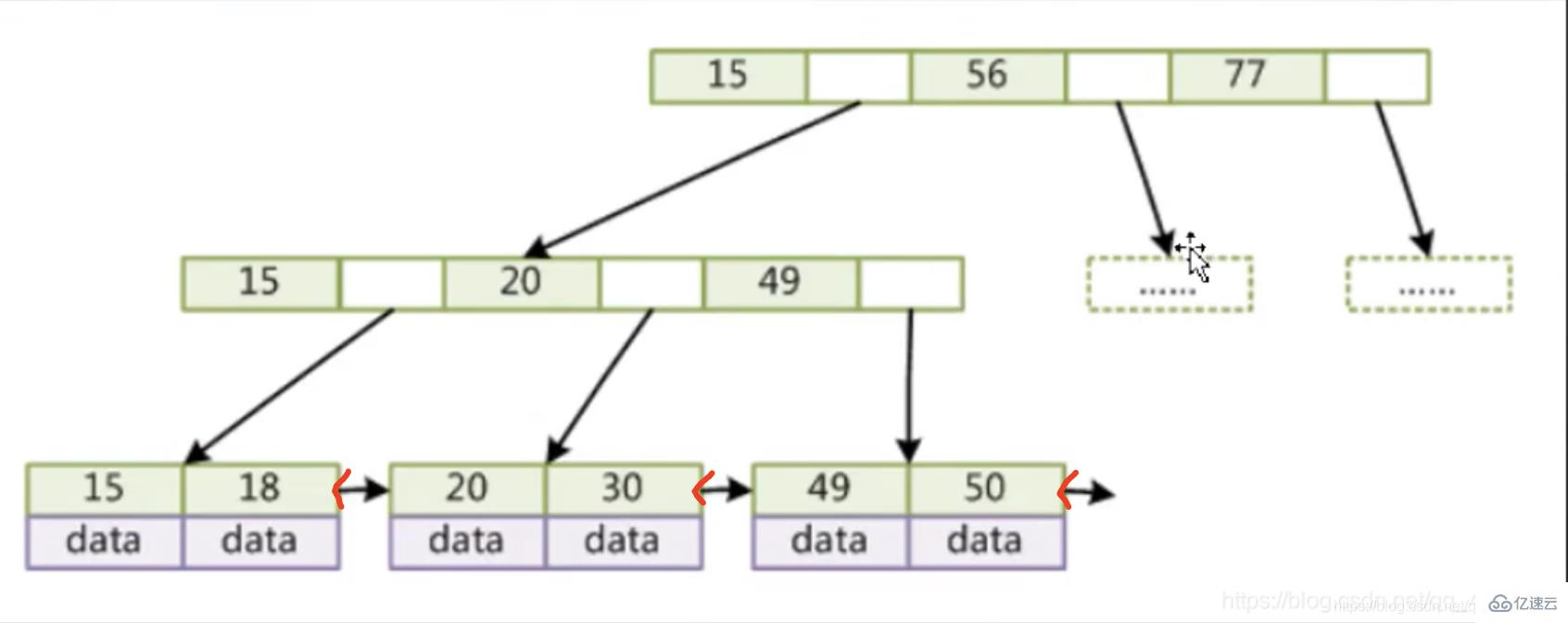
从这张图可以看到,我们的非叶子节点只存储了索引并没有存储data,而且叶子节点间用指针相连。B树的叶子节点和非叶子节点都存储了索引和数据,而且叶子结点的指针为空,B+树把数据放在了叶子节点上,这样非叶子节点就可以存放更多的索引,每次从磁盘IO也能获取更多的索引。
B+树特点如下:
1.非叶子节点不存储data,只存储索引(冗余)和下层指针,可以放更多的索引
2.叶子节点包含所有索引字段,和数据
3.叶子节点用双指针连接,提高区间访问的性能
在百度上和很多博客上画的B+树是错误的哦,一定要避坑哦。
有兴趣看Mysql官方对B+树的解释的可以去看看。
链接: Mysql官网.
四.索引分类
1.按照索引的存储关联分类:分为两大类
1.)聚集索义(聚簇索引):叶节点包含了完整的数据记录,不需要回表。
2.)非聚集索引:需要回表,二次查树,影响性能。
1.1) 大家都知道Mysql常用的存储引擎有两种MyISAM和InnoDB,但是大家实际了解过两种存储引擎底层的数据存储结构吗?
下面以图为例为大家说明: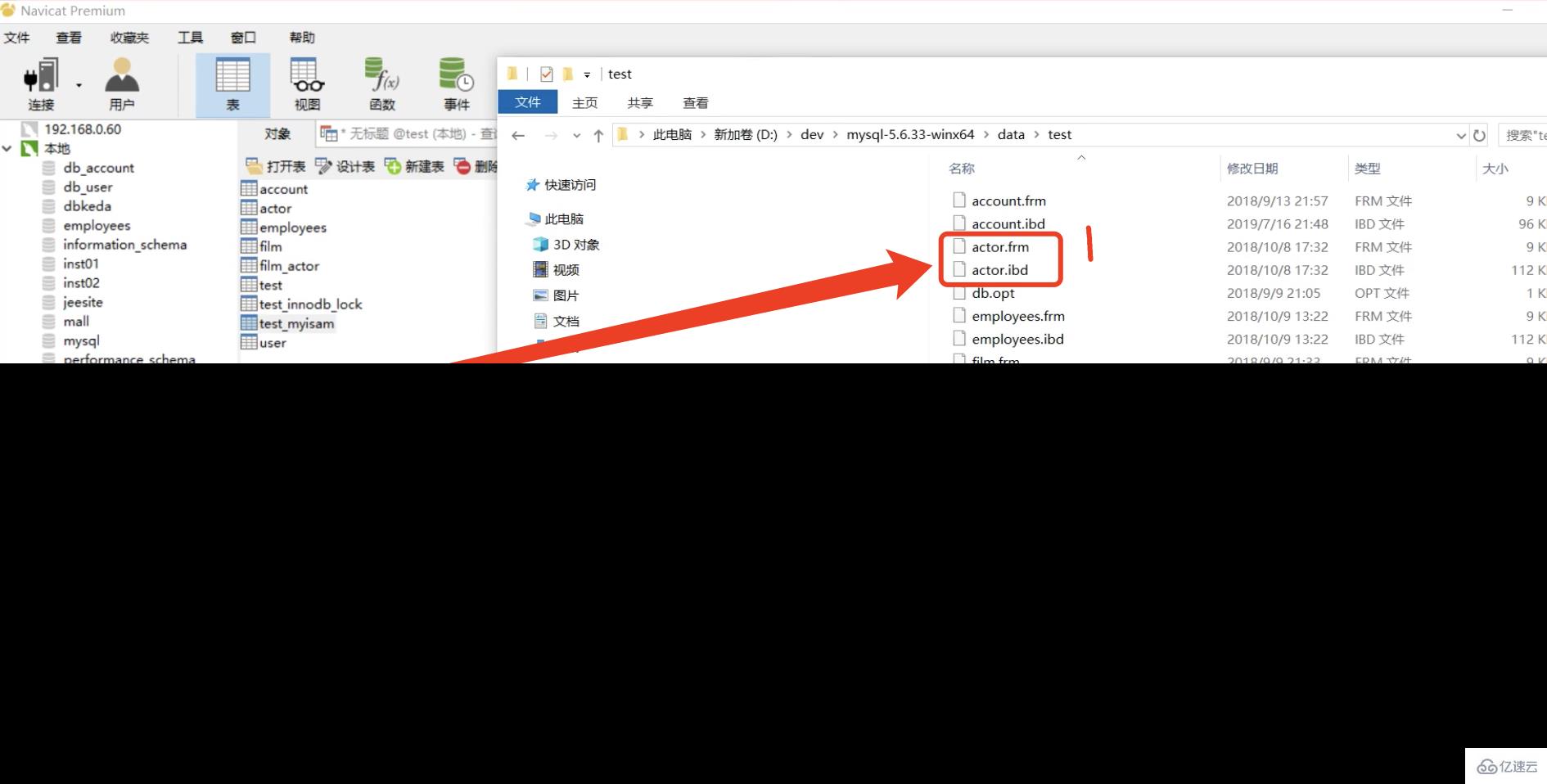 其中test.myisam表是MyISAM存储引擎,actor表是InnoDB存储引擎,可以看到MyISAM存储引擎有三个文件,分别是frm、MYD、MYI,很容易理解frm-frame的简称,存的是表的结构,MYD-MYData存的是数据,MYI-MYIndex存的是索引,索引和数据是分开存储的,再看InnoDB只有frm、IBD,其中frm一样也是存的表的结构,IBD文件存的是索引和数据,这点InnoDB和MyISAM不一样。
其中test.myisam表是MyISAM存储引擎,actor表是InnoDB存储引擎,可以看到MyISAM存储引擎有三个文件,分别是frm、MYD、MYI,很容易理解frm-frame的简称,存的是表的结构,MYD-MYData存的是数据,MYI-MYIndex存的是索引,索引和数据是分开存储的,再看InnoDB只有frm、IBD,其中frm一样也是存的表的结构,IBD文件存的是索引和数据,这点InnoDB和MyISAM不一样。
下面以图为例说明MyISAM存储引擎主键索引是需要回表操作(非聚集索引)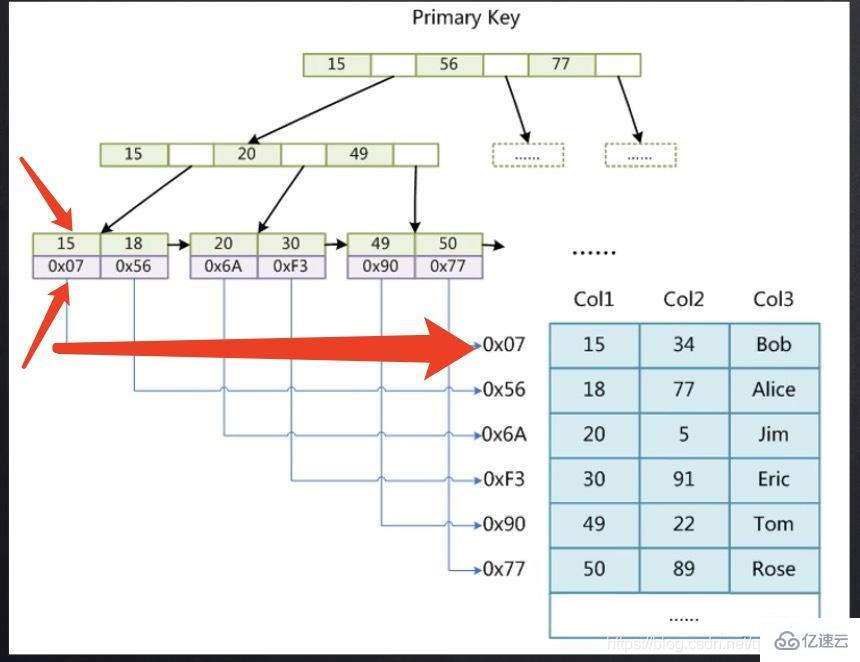 其中15存的是主键索引,0x07存的是15所在行记录的磁盘文件地址指针,比如我们想找到15的数据,那首先应该先通过主键索引树,找到15所对应的指针,然后找到了这个指针再去MyD文件中找具体的数据,需要进行二次查找,这个过程称为回表操作。
其中15存的是主键索引,0x07存的是15所在行记录的磁盘文件地址指针,比如我们想找到15的数据,那首先应该先通过主键索引树,找到15所对应的指针,然后找到了这个指针再去MyD文件中找具体的数据,需要进行二次查找,这个过程称为回表操作。
2.1) 下面以图为例说明InnoDB存储引擎主键索引不需要进行回表操作。(聚集索引)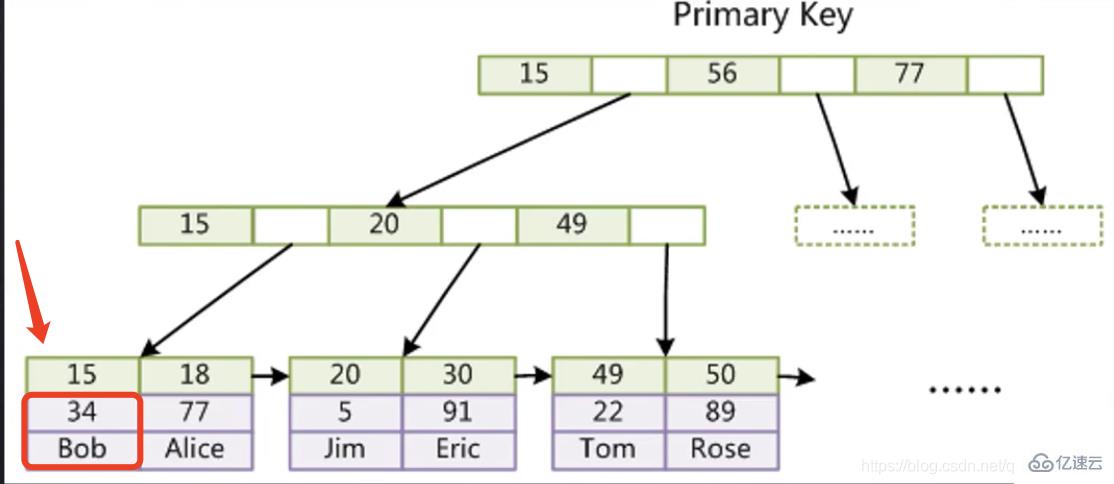 InnoDB存储引擎子节点首先15那一行存放的是索引,15下面的那一列存放的是索引所在行的其他所有字段,如果我们想要查15的数据,直接就可以找到,不需要在经过二次查树。
InnoDB存储引擎子节点首先15那一行存放的是索引,15下面的那一列存放的是索引所在行的其他所有字段,如果我们想要查15的数据,直接就可以找到,不需要在经过二次查树。
2. 按照功能分类:主要分为五大类
2.1 主键索引:InnoDB主键索引不需要回表操作
2.2 普通索引(二级索引):InnoDB普通索引需要回表操作,对于二级索引,会默认和主键做联合索引。
2.3 唯一索引
2.4 全文索引
2.5 联合索引:需要满足最左前缀原则
3. 在2.2中提到了普通索引需要回表操作,那有没有不需要回表的普通索引呢,答案是有的,在某个查询里面,索引已经覆盖了我们的查询需求,我们称为覆盖索引。这时是不需要回表操作的。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
举个例子:下面是这个表的初始化语句。
mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into T values(100,1, 'aa'),(200,2,'bb'), (300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
在上面这个表 T 中,如果我执行 select * from T where k between 3 and 5,需要执行几次树的搜索操作,会扫描多少行?
现在,我们一起来看看这条 SQL 查询语句的执行流程。看下图。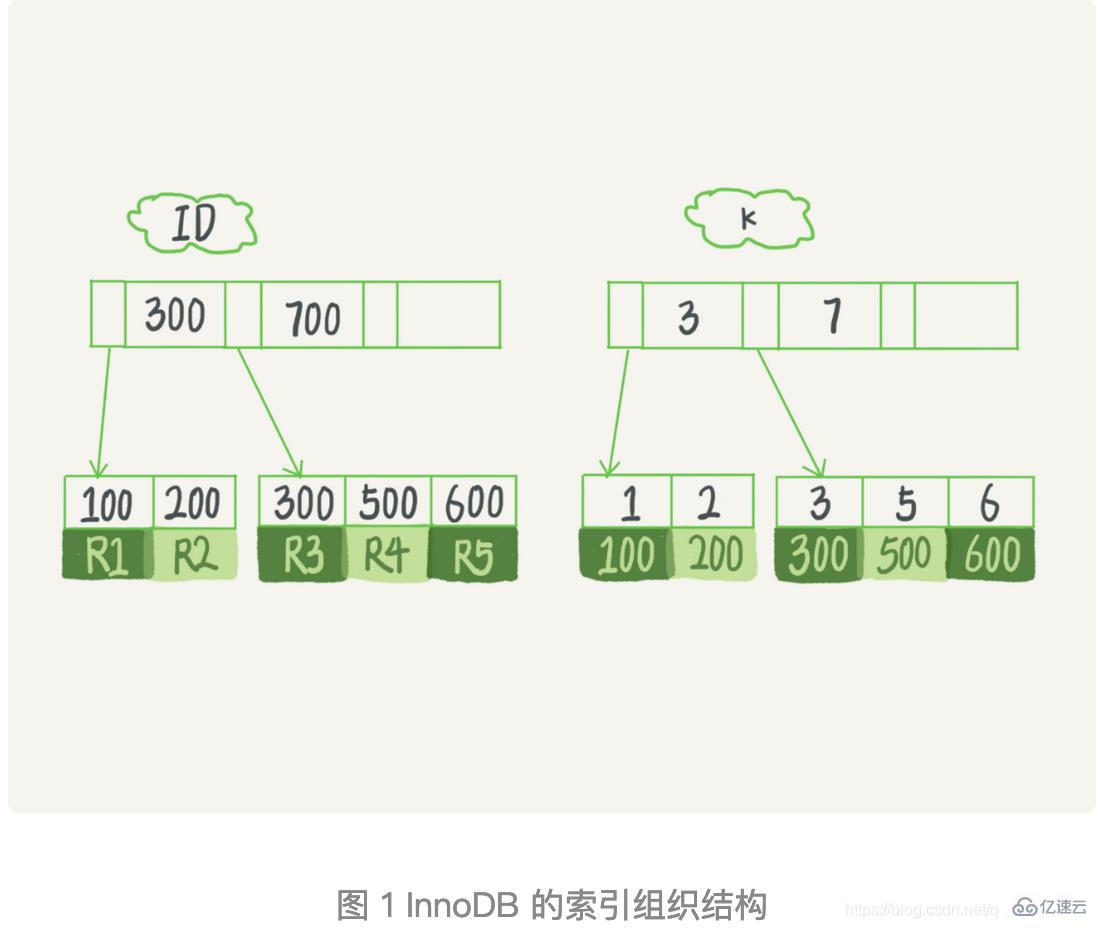
1.) 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
2.) 再到 ID 索引树查到 ID=300 对应的 R3;
3.) 在 k 索引树取下一个值 k=5,取得 ID=500;
4.) 再回到 ID 索引树查到 ID=500 对应的 R4;
5.) 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树搜索的过程,我们称为回表。可以看到,这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
在这个例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。又因为前面我们提到的,InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。每一个索引在 InnoDB 里面对应一棵 B+ 树。
五.索引优化
1.上面描述了索引基本概念、分类以及底层的基本结构相关知识。下面聊一聊索引优化的相关知识吧。
1.) 当组合索引中只要有一列含有null值,索引失效
2.) 在列上做计算索引失效,范围之后的索引全部失效
3.) 在查询条件上使用函数会造成索引失效
4.) 在where字句中使用 != 或 操作符,导致索引失效
5.) 避免使用or,导致索引失效
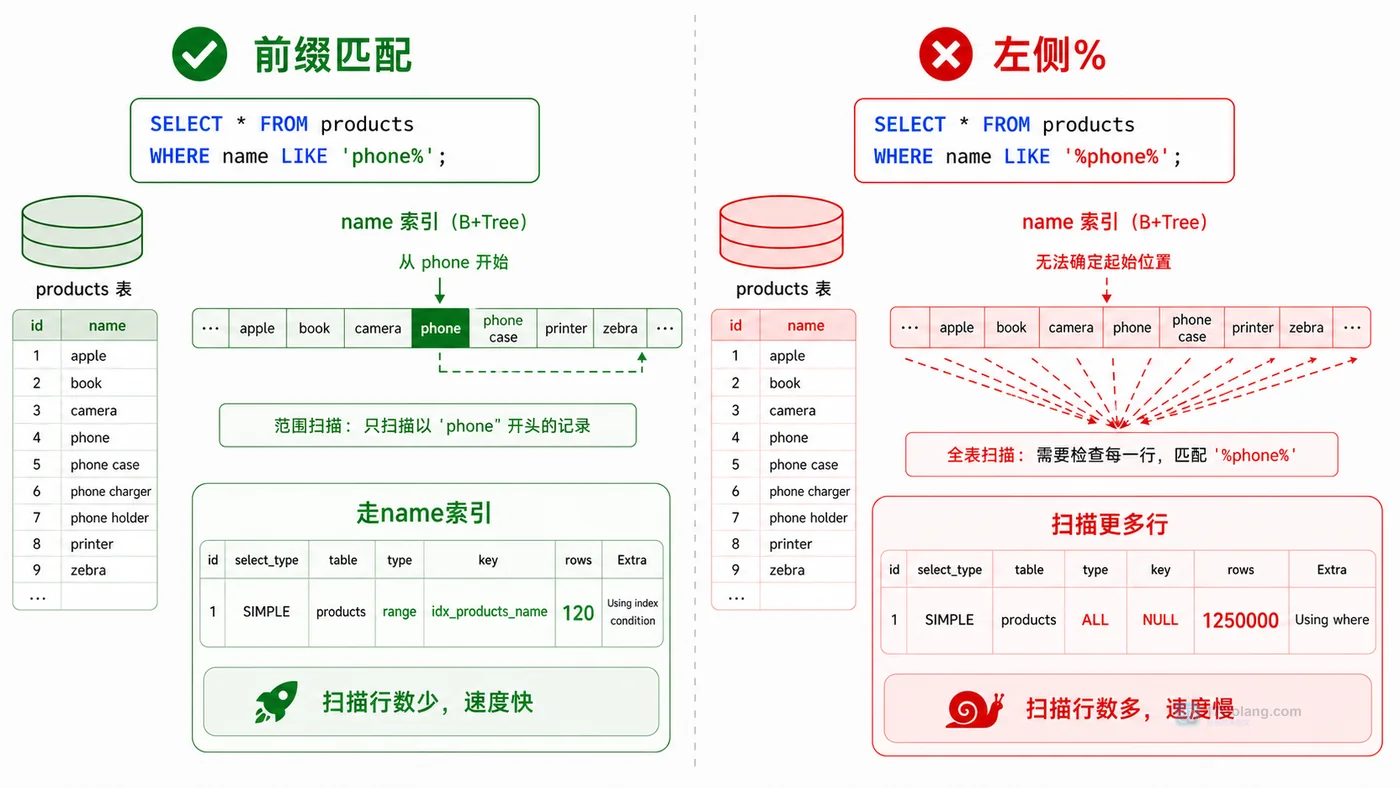
6.) 使用模糊查询也会造成索引失效,可以用like ‘a%’而不是like ‘%a%’
7.) 尽量使用覆盖索引,减少 select * 语句
8.) 满足最左前缀法则,最左前列开始并且不跳过索引中的列
9.) 字符串不加单引号索引失效
2.下面以实战说明索引优化。
新创建一个员工表,有5个属性,如下。
create table employees(
id int primary key auto_increment comment '主键自增',
name varchar(30) not null default '' comment'名字',
age int not null default 1 comment '年龄',
id_card varchar(40) not null default '' comment '身份证号',
position varchar(40) not null default '' comment '位置'
);
-- 创建联合索引
create index name_index on employees (name,age,position);
-- 插入一条数据
insert into employees(name,age,id_card,position) values('张三',15,
'201124199011035321','北京');-- 下面以10条sql测试,注意建立的联合索引顺序是 name,age,position 1.explain select * from employees where age=15 and position='北京' and name='张三'; 2.explain select * from employees where name='张三' and age=15 and position='北京'; 3.explain select * from employees where age=15 and name='张三'; 4.explain select * from employees where position='北京' and name='张三'; 5.explain select * from employees where position='北京' and age=15; 6.explain select * from employees where position='北京' and age>15 and name='张三'; 7.explain select * from employees where position='北京'; 8.explain select * from employees where age=15; 9.explain select * from employees where name='张三'; 10.explain select * from employees where name != '张三';
以上10条sql有哪些是索引失效,有哪些是索引没有失效的呢? 相信同学们已经有了答案,但是答案对不对呢,下面我们一起分析下。 首先说第1条,查询条件把3个索引全部用上了,但是索引的顺序有变化,由name,age,position变成 了age,position,name,想到这里肯定有很多同学给出的答案就是索引失效,但是事实证明这个结果 是错的,索引生效,肯定有很多同学疑惑,为什么呢,这条sql不满足最左原则法则呀,这就要涉及到sql 的执行流程了,这里博主简单说下,sql执行有1个优化器的过程,优化器的作用之一就是索引的选择优化, 所以优化器帮我们把索引的顺序变成正确的了,所以索引生效。 下面是第1条按照索引顺序sql和第2条没有按照索引顺序sql的执行结果。 执行结果入下图:可以发现全部生效。
第1条sql type的值为ref、字节是288 并且ref有3个const,全部生效。

第2条sql type的值为ref、字节是288 并且ref有3个const,全部生效。

想学习sql的执行流程的可以看博主的另一篇关于sql执行流程的文章哦。 有的同学有疑问了,那最左原则没有用了吗? 答案:有用的。
现在我们说下第3、4、5条sql 第3条: explain select * from employees where age=15 and name='张三'; sql在执行的时候,优化器替我们把索引的顺序优化了,由 age -> name 变成 name -> age,这时 索引是生效的。 第4条: explain select * from employees where position='北京' and name='张三'; 索引顺序优化为name - > position,但是这时索引只有name索引生效,position没有生效,因为我 们建立的索引顺序是 name -> age - > position,你会发现跳过了age,索引本质也是一棵树,少 了一个节点,下面的索引当然不会生效了,这就没有满足最左原则法则。 第5条: explain select * from employees where position='北京' and age=15; 这就和第4条sql一样的道理了,第一个索引都不见了,后面的不可能生效。 执行结果如下:
可以发现第3条sql type的值为ref、字节是126并且ref有2个const,全部生效。

第4条sql只有122字节并且ref只有1个const,只有name索引生效。

第5条sql type的值为all,字节和ref都是空,全部失效。

下面说第6条sql,剩下的sql都是和之前的sql一样的道理。 explain select * from employees where position='北京' and age>15 and name='张三'; 这条sql我们会发现,把索引字段全部使用了并且当作条件查询,不一样的是age是范围查找,优化器替我 们把索引顺序优化成 name -> age - > position ,按照我们索引优化第2条:在列上做计算索引失效,范围之后的索引全部失效,想必答案同学们都知道了。 执行结果如下:
第6条sql只有126字节并且type的值为range,范围查找,只有name和age索引生效。

好了,本文到此结束,带大家了解了《Mysql索引底层及优化方法是什么》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多数据库知识!
 一键重装重启后没有重装的解决方法
一键重装重启后没有重装的解决方法
- 上一篇
- 一键重装重启后没有重装的解决方法

- 下一篇
- 160亿参数,新增多项能力,复旦MOSS开源了
-
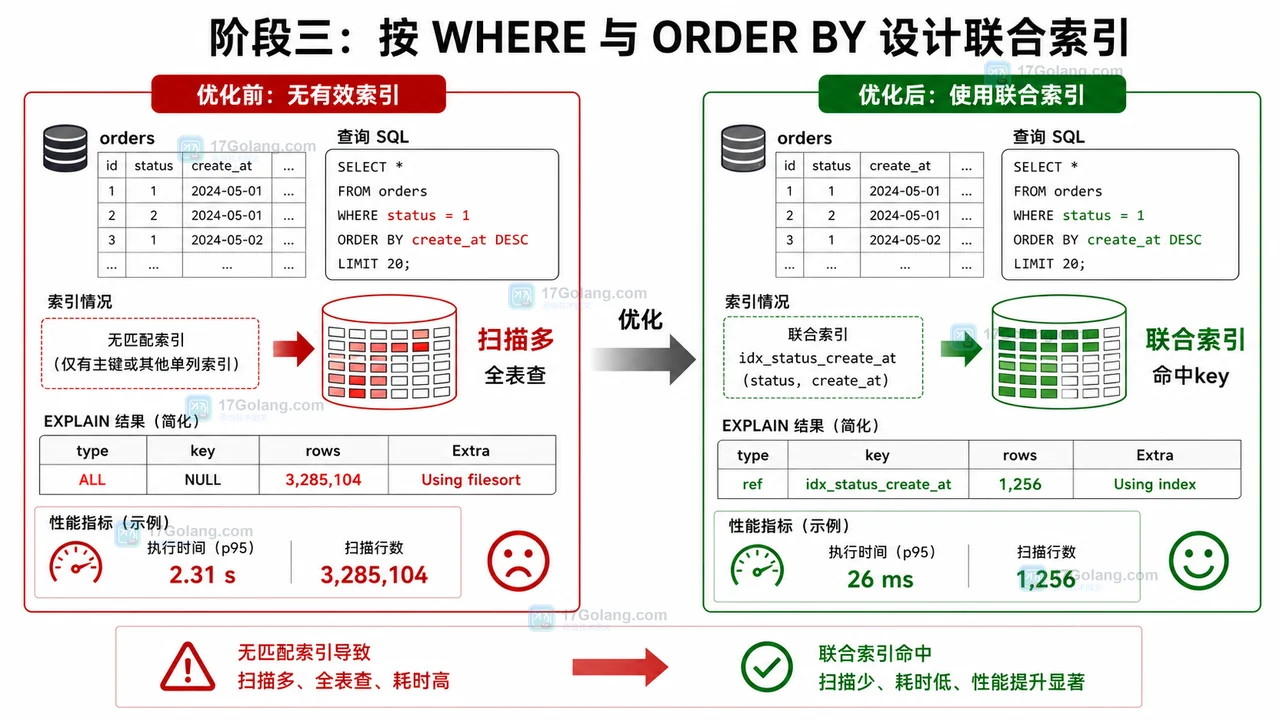
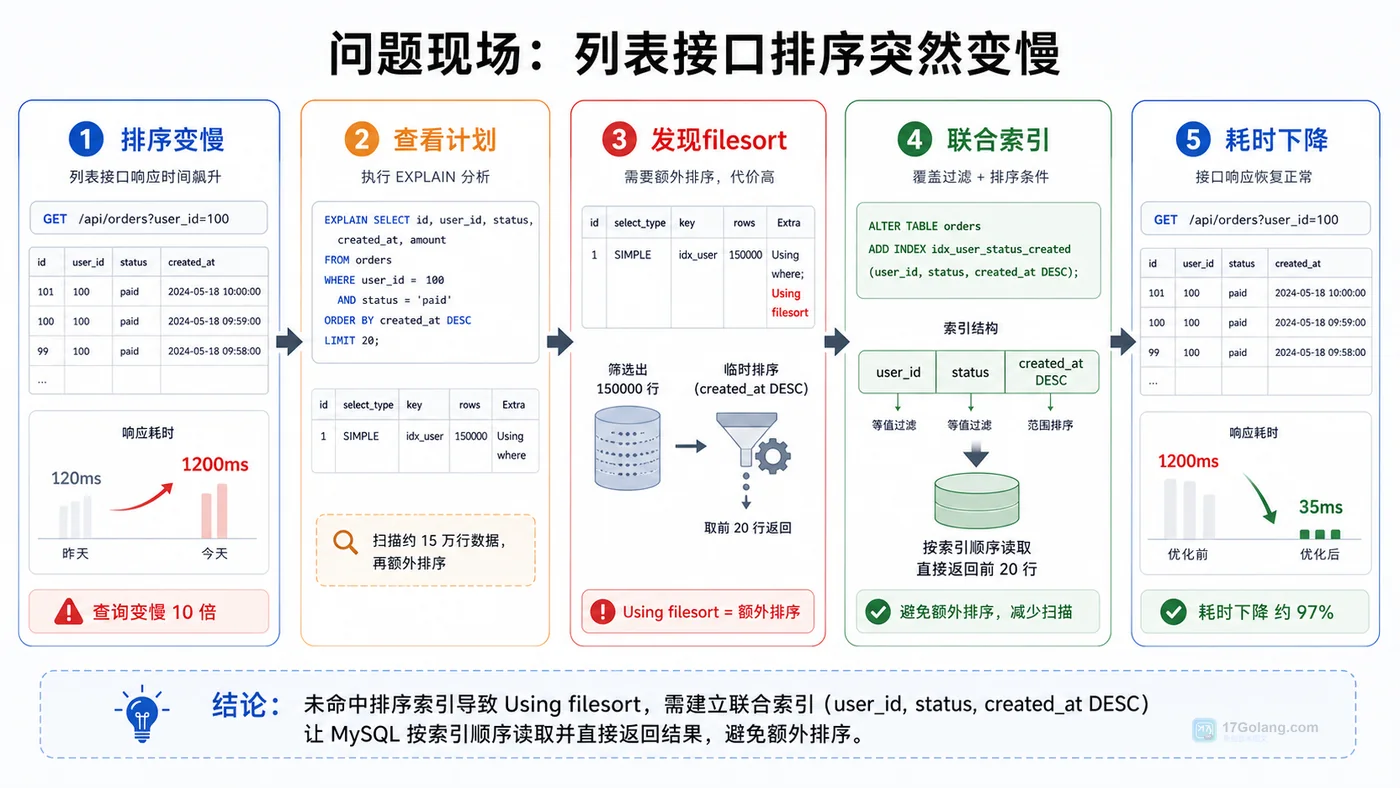
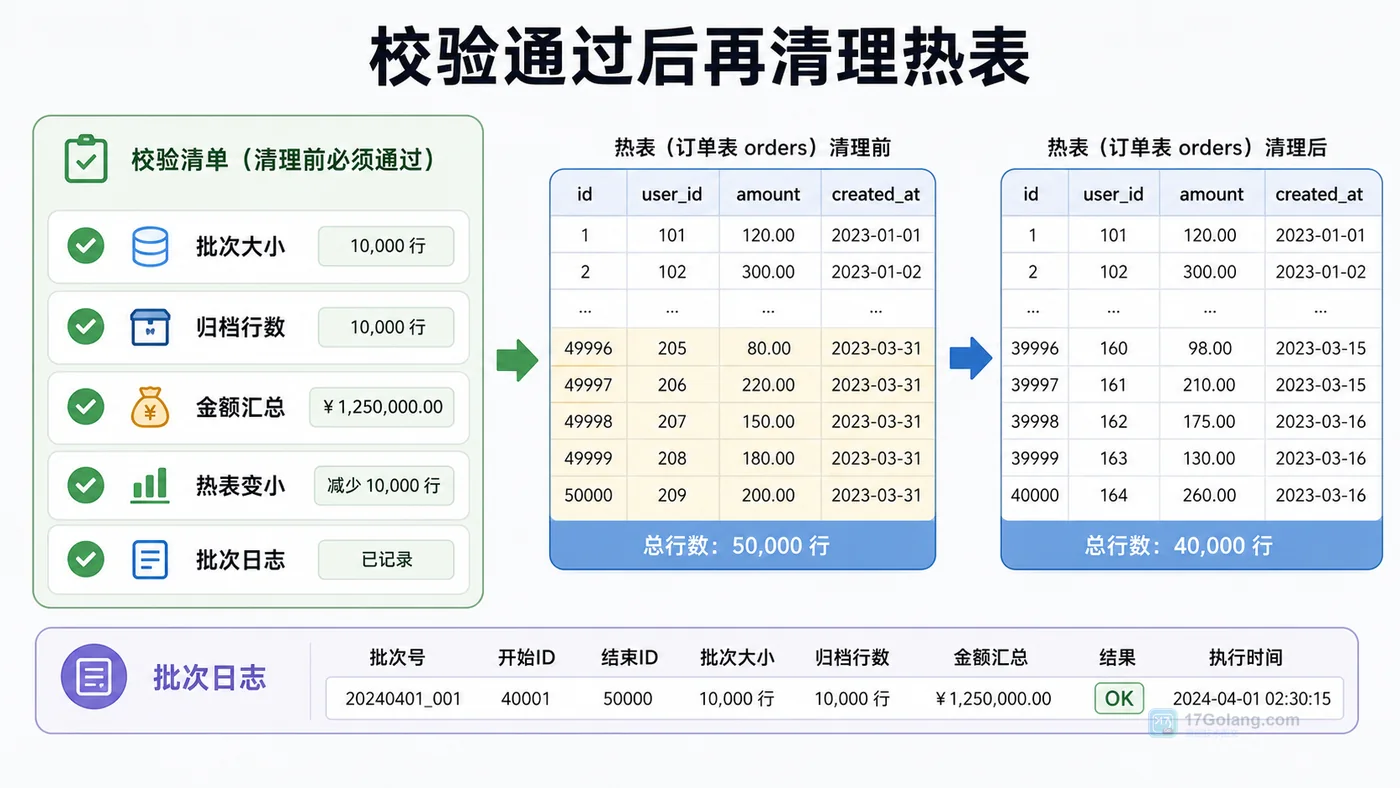
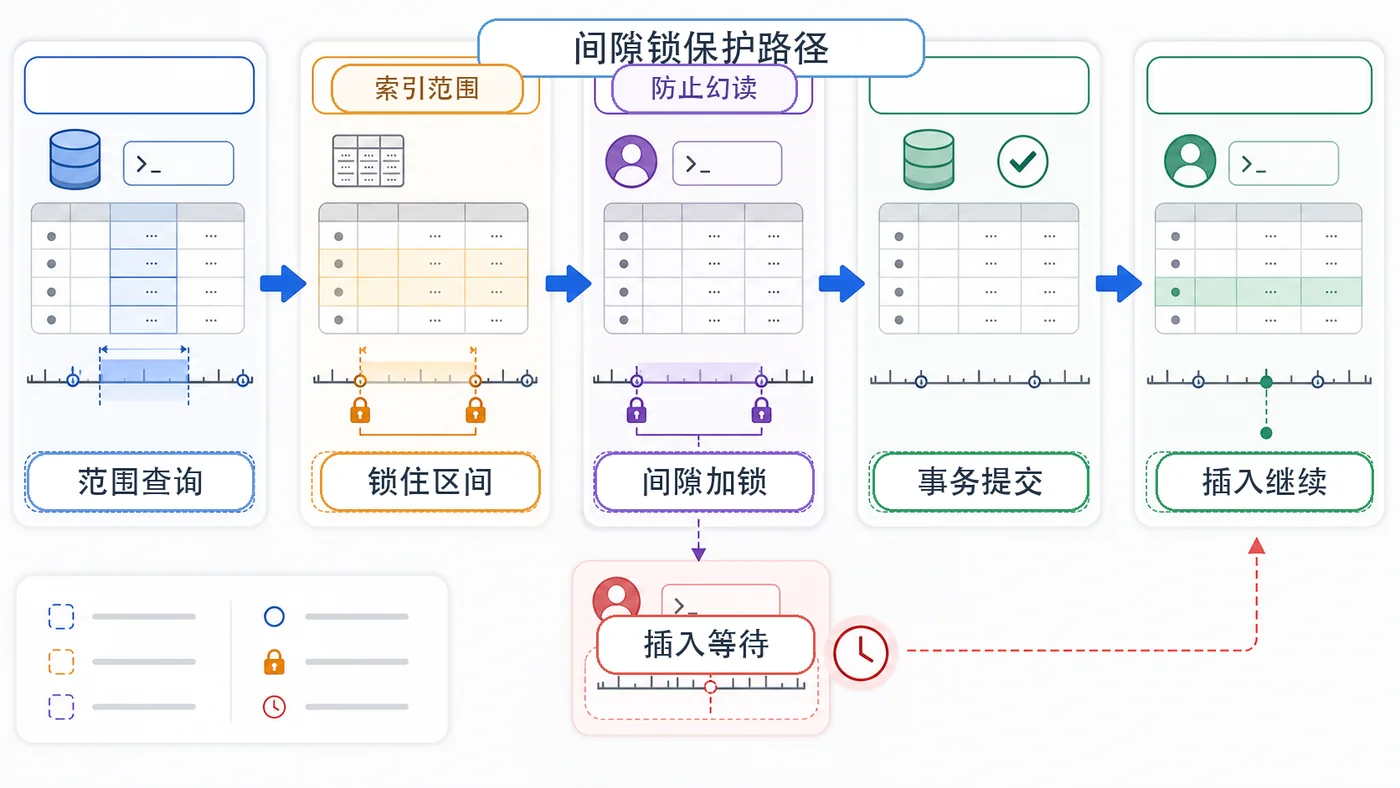
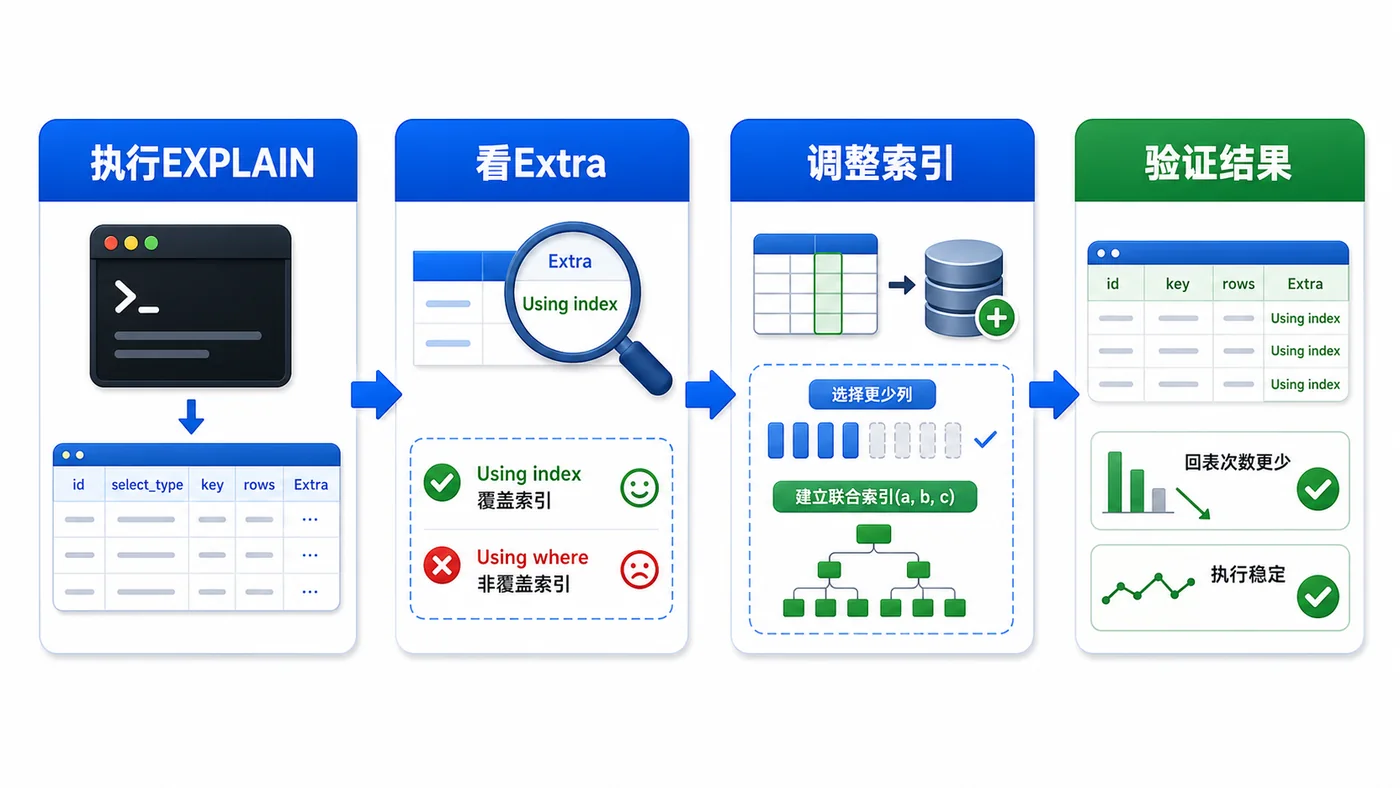
- 数据库 · MySQL | 1星期前 | MySQL · 慢查询 · 索引优化 · COUNT查询 · 汇总表 · 联合索引 覆盖索引 汇总表 MySQL COUNT慢 COUNT(*)优化
- MySQL COUNT(*) 总数查询变慢怎么办:从扫描行数到汇总表的完整治理流程
- 329浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2673次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2475次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2416次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2645次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2593次使用
-
- MySQL权限管理设置全攻略
- 2026-03-29 501浏览
-
- MySQL分片实现方法及常见方案解析
- 2025-06-24 501浏览
-
- MySQL表空间碎片怎么清理?超详细优化教程
- 2025-06-13 501浏览
-
- MySQL排序性能优化技巧及方法
- 2025-06-04 501浏览
-
- MySQL建库建表全流程详解
- 2025-05-24 501浏览


