Python如何使用爬虫获取京东商品评论并存储到MySQL中?
来源:亿速云
2023-04-25 11:32:48
0浏览
收藏
大家好,今天本人给大家带来文章《Python如何使用爬虫获取京东商品评论并存储到MySQL中?》,文中内容主要涉及到,如果你对数据库方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
构建mysql数据表
问题:使用SQL alchemy时,非主键不能设置为自增长,但是我想让这个非主键仅仅是为了作为索引,autoincrement=True无效,该怎么实现让它自增长呢?
from sqlalchemy import String,Integer,Text,Column from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from sqlalchemy.orm import scoped_session from sqlalchemy.ext.declarative import declarative_base engine=create_engine( "mysql+pymysql://root:root@127.0.0.1:3306/jdcrawl?charset=utf8", pool_size=200, max_overflow=300, echo=False ) BASE=declarative_base() # 实例化 class Goods(BASE): __tablename__='goods' id=Column(Integer(),primary_key=True,autoincrement=True) sku_id = Column(String(200), primary_key=True, autoincrement=False) name=Column(String(200)) price=Column(String(200)) comments_num=Column(Integer) shop=Column(String(200)) link=Column(String(200)) class Comments(BASE): __tablename__='comments' id=Column(Integer(),primary_key=True,autoincrement=True,nullable=False) sku_id=Column(String(200),primary_key=True,autoincrement=False) comments=Column(Text()) BASE.metadata.create_all(engine) Session=sessionmaker(engine) sess_db=scoped_session(Session)
第一版:
问题:爬取几页评论后就会爬取到空白页,添加refer后依旧如此
尝试解决方法:将获取评论地方的线程池改为单线程,并每获取一页评论增加延时1s
# 不能爬太快!!!不然获取不到评论
from bs4 import BeautifulSoup
import requests
from urllib import parse
import csv,json,re
import threadpool
import time
from jd_mysqldb import Goods,Comments,sess_db
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie': '__jdv=76161171|baidu|-|organic|%25E4%25BA%25AC%25E4%25B8%259C|1613711947911; __jdu=16137119479101182770449; areaId=7; ipLoc-djd=7-458-466-0; PCSYCityID=CN_410000_0_0; shshshfpa=07383463-032f-3f99-9d40-639cb57c6e28-1613711950; shshshfpb=u8S9UvxK66gfIbM1mUNrIOg%3D%3D; user-key=153f6b4d-0704-4e56-82b6-8646f3f0dad4; cn=0; shshshfp=9a88944b34cb0ff3631a0a95907b75eb; __jdc=122270672; 3AB9D23F7A4B3C9B=SEELVNXBPU7OAA3UX5JTKR5LQADM5YFJRKY23Z6HDBU4OT2NWYGX525CKFFVHTRDJ7Q5DJRMRZQIQJOW5GVBY43XVI; jwotest_product=99; __jda=122270672.16137119479101182770449.1613711948.1613738165.1613748918.4; JSESSIONID=C06EC8D2E9384D2628AE22B1A6F9F8FC.s1; shshshsID=ab2ca3143928b1b01f6c5b71a15fcebe_5_1613750374847; __jdb=122270672.5.16137119479101182770449|4.1613748918',
'Referer': 'https://www.jd.com/'
}
num=0 # 商品数量
comments_num=0 # 评论数量
# 获取商品信息和SkuId
def getIndex(url):
session=requests.Session()
session.headers=headers
global num
res=session.get(url,headers=headers)
print(res.status_code)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'lxml')
items=soup.select('li.gl-item')
for item in items[:3]: # 爬取3个商品测试
title=item.select_one('.p-name a em').text.strip().replace(' ','')
price=item.select_one('.p-price strong').text.strip().replace('¥','')
try:
shop=item.select_one('.p-shopnum a').text.strip() # 获取书籍时查找店铺的方法
except:
shop=item.select_one('.p-shop a').text.strip() # 获取其他商品时查找店铺的方法
link=parse.urljoin('https://',item.select_one('.p-img a').get('href'))
SkuId=re.search('\d+',link).group()
comments_num=getCommentsNum(SkuId,session)
print(SkuId,title, price, shop, link, comments_num)
print("开始存入数据库...")
try:
IntoGoods(SkuId,title, price, shop, link, comments_num)
except Exception as e:
print(e)
sess_db.rollback()
num += 1
print("正在获取评论...")
# 获取评论总页数
url1 = f'https://club.jd.com/comment/productPageComments.action?productId={SkuId}&score=0&sortType=5&page=0&pageSize=10'
headers['Referer'] = f'https://item.jd.com/{SkuId}.html'
headers['Connection']='keep-alive'
res2 = session.get(url1,headers=headers)
res2.encoding = res2.apparent_encoding
json_data = json.loads(res2.text)
max_page = json_data['maxPage'] # 经测试最多可获取100页评论,每页10条
args = []
for i in range(0, max_page):
# 使用此链接获取评论得到的为json格式
url2 = f'https://club.jd.com/comment/productPageComments.action?productId={SkuId}&score=0&sortType=5&page={i}&pageSize=10'
# 使用此链接获取评论得到的非json格式,需要提取
# url2_2=f'https://club.jd.com/comment/productPageComments.action?callback=jQuery9287224&productId={SkuId}&score=0&sortType=5&page={i}&pageSize=10'
args.append(([session,SkuId,url2], None))
pool2 = threadpool.ThreadPool(2) # 2个线程
reque2 = threadpool.makeRequests(getComments,args) # 创建任务
for r in reque2:
pool2.putRequest(r) # 提交任务到线程池
pool2.wait()
# 获取评论总数量
def getCommentsNum(SkuId,sess):
headers['Referer']=f'https://item.jd.com/{SkuId}.html'
url=f'https://club.jd.com/comment/productCommentSummaries.action?referenceIds={SkuId}'
res=sess.get(url,headers=headers)
try:
res.encoding=res.apparent_encoding
json_data=json.loads(res.text) # json格式转为字典
num=json_data['CommentsCount'][0]['CommentCount']
return num
except:
return 'Error'
# 获取评论
def getComments(sess,SkuId,url2):
global comments_num
print(url2)
headers['Referer'] = f'https://item.jd.com/{SkuId}.html'
res2 = sess.get(url2,headers=headers)
res2.encoding='gbk'
json_data=res2.text
'''
# 如果用url2_2需要进行如下操作提取json
start = res2.text.find('jQuery9287224(') + len('jQuery9287224(')
end = res2.text.find(');')
json_data=res2.text[start:end]
'''
dict_data = json.loads(json_data)
try:
comments=dict_data['comments']
for item in comments:
comment=item['content'].replace('\n','')
# print(comment)
comments_num+=1
try:
IntoComments(SkuId,comment)
except Exception as e:
print(e)
sess_db.rollback()
except:
pass
# 商品信息入库
def IntoGoods(SkuId,title, price, shop, link, comments_num):
goods_data=Goods(
sku_id=SkuId,
name=title,
price=price,
comments_num=comments_num,
shop=shop,
link=link
)
sess_db.add(goods_data)
sess_db.commit()
# 评论入库
def IntoComments(SkuId,comment):
comments_data=Comments(
sku_id=SkuId,
comments=comment
)
sess_db.add(comments_data)
sess_db.commit()
if __name__ == '__main__':
start_time=time.time()
urls=[]
KEYWORD=parse.quote(input("请输入要查询的关键词:"))
for i in range(1,2): # 爬取一页进行测试
url=f'https://search.jd.com/Search?keyword={KEYWORD}&wq={KEYWORD}&page={i}'
urls.append(([url,],None)) # threadpool要求必须这样写
pool=threadpool.ThreadPool(2) # 2个线程的线程池
reque=threadpool.makeRequests(getIndex,urls) # 创建任务
for r in reque:
pool.putRequest(r) # 向线程池提交任务
pool.wait() # 等待所有任务执行完毕
print("共获取{}件商品,获得{}条评论,耗时{}".format(num,comments_num,time.time()-start_time))第二版 :
经测试,的确不会出现空白页的情况
进一步优化:同时获取2个以上商品的评论
# 不能爬太快!!!不然获取不到评论
from bs4 import BeautifulSoup
import requests
from urllib import parse
import csv,json,re
import threadpool
import time
from jd_mysqldb import Goods,Comments,sess_db
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie': '__jdv=76161171|baidu|-|organic|%25E4%25BA%25AC%25E4%25B8%259C|1613711947911; __jdu=16137119479101182770449; areaId=7; ipLoc-djd=7-458-466-0; PCSYCityID=CN_410000_0_0; shshshfpa=07383463-032f-3f99-9d40-639cb57c6e28-1613711950; shshshfpb=u8S9UvxK66gfIbM1mUNrIOg%3D%3D; user-key=153f6b4d-0704-4e56-82b6-8646f3f0dad4; cn=0; shshshfp=9a88944b34cb0ff3631a0a95907b75eb; __jdc=122270672; 3AB9D23F7A4B3C9B=SEELVNXBPU7OAA3UX5JTKR5LQADM5YFJRKY23Z6HDBU4OT2NWYGX525CKFFVHTRDJ7Q5DJRMRZQIQJOW5GVBY43XVI; jwotest_product=99; __jda=122270672.16137119479101182770449.1613711948.1613738165.1613748918.4; JSESSIONID=C06EC8D2E9384D2628AE22B1A6F9F8FC.s1; shshshsID=ab2ca3143928b1b01f6c5b71a15fcebe_5_1613750374847; __jdb=122270672.5.16137119479101182770449|4.1613748918',
'Referer': 'https://www.jd.com/'
}
num=0 # 商品数量
comments_num=0 # 评论数量
# 获取商品信息和SkuId
def getIndex(url):
session=requests.Session()
session.headers=headers
global num
res=session.get(url,headers=headers)
print(res.status_code)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'lxml')
items=soup.select('li.gl-item')
for item in items[:2]: # 爬取2个商品测试
title=item.select_one('.p-name a em').text.strip().replace(' ','')
price=item.select_one('.p-price strong').text.strip().replace('¥','')
try:
shop=item.select_one('.p-shopnum a').text.strip() # 获取书籍时查找店铺的方法
except:
shop=item.select_one('.p-shop a').text.strip() # 获取其他商品时查找店铺的方法
link=parse.urljoin('https://',item.select_one('.p-img a').get('href'))
SkuId=re.search('\d+',link).group()
headers['Referer'] = f'https://item.jd.com/{SkuId}.html'
headers['Connection'] = 'keep-alive'
comments_num=getCommentsNum(SkuId,session)
print(SkuId,title, price, shop, link, comments_num)
print("开始将商品存入数据库...")
try:
IntoGoods(SkuId,title, price, shop, link, comments_num)
except Exception as e:
print(e)
sess_db.rollback()
num += 1
print("正在获取评论...")
# 获取评论总页数
url1 = f'https://club.jd.com/comment/productPageComments.action?productId={SkuId}&score=0&sortType=5&page=0&pageSize=10'
res2 = session.get(url1,headers=headers)
res2.encoding = res2.apparent_encoding
json_data = json.loads(res2.text)
max_page = json_data['maxPage'] # 经测试最多可获取100页评论,每页10条
print("{}评论共{}页".format(SkuId,max_page))
if max_page==0:
IntoComments(SkuId,'0')
else:
for i in range(0, max_page):
# 使用此链接获取评论得到的为json格式
url2 = f'https://club.jd.com/comment/productPageComments.action?productId={SkuId}&score=0&sortType=5&page={i}&pageSize=10'
# 使用此链接获取评论得到的非json格式,需要提取
# url2_2=f'https://club.jd.com/comment/productPageComments.action?callback=jQuery9287224&productId={SkuId}&score=0&sortType=5&page={i}&pageSize=10'
print("开始获取第{}页评论:{}".format(i+1,url2) )
getComments(session,SkuId,url2)
time.sleep(1)
# 获取评论总数量
def getCommentsNum(SkuId,sess):
url=f'https://club.jd.com/comment/productCommentSummaries.action?referenceIds={SkuId}'
res=sess.get(url)
try:
res.encoding=res.apparent_encoding
json_data=json.loads(res.text) # json格式转为字典
num=json_data['CommentsCount'][0]['CommentCount']
return num
except:
return 'Error'
# 获取评论
def getComments(sess,SkuId,url2):
global comments_num
res2 = sess.get(url2)
res2.encoding=res2.apparent_encoding
json_data=res2.text
'''
# 如果用url2_2需要进行如下操作提取json
start = res2.text.find('jQuery9287224(') + len('jQuery9287224(')
end = res2.text.find(');')
json_data=res2.text[start:end]
'''
dict_data = json.loads(json_data)
comments=dict_data['comments']
for item in comments:
comment=item['content'].replace('\n','')
# print(comment)
comments_num+=1
try:
IntoComments(SkuId,comment)
except Exception as e:
print(e)
sess_db.rollback()
# 商品信息入库
def IntoGoods(SkuId,title, price, shop, link, comments_num):
goods_data=Goods(
sku_id=SkuId,
name=title,
price=price,
comments_num=comments_num,
shop=shop,
link=link
)
sess_db.add(goods_data)
sess_db.commit()
# 评论入库
def IntoComments(SkuId,comment):
comments_data=Comments(
sku_id=SkuId,
comments=comment
)
sess_db.add(comments_data)
sess_db.commit()
if __name__ == '__main__':
start_time=time.time()
urls=[]
KEYWORD=parse.quote(input("请输入要查询的关键词:"))
for i in range(1,2): # 爬取一页进行测试
url=f'https://search.jd.com/Search?keyword={KEYWORD}&wq={KEYWORD}&page={i}'
urls.append(([url,],None)) # threadpool要求必须这样写
pool=threadpool.ThreadPool(2) # 2个线程的线程池
reque=threadpool.makeRequests(getIndex,urls) # 创建任务
for r in reque:
pool.putRequest(r) # 向线程池提交任务
pool.wait() # 等待所有任务执行完毕
print("共获取{}件商品,获得{}条评论,耗时{}".format(num,comments_num,time.time()-start_time))第三版:
。。。。不行,又出现空白页了
# 不能爬太快!!!不然获取不到评论
from bs4 import BeautifulSoup
import requests
from urllib import parse
import csv,json,re
import threadpool
import time
from jd_mysqldb import Goods,Comments,sess_db
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie': '__jdv=76161171|baidu|-|organic|%25E4%25BA%25AC%25E4%25B8%259C|1613711947911; __jdu=16137119479101182770449; areaId=7; ipLoc-djd=7-458-466-0; PCSYCityID=CN_410000_0_0; shshshfpa=07383463-032f-3f99-9d40-639cb57c6e28-1613711950; shshshfpb=u8S9UvxK66gfIbM1mUNrIOg%3D%3D; user-key=153f6b4d-0704-4e56-82b6-8646f3f0dad4; cn=0; shshshfp=9a88944b34cb0ff3631a0a95907b75eb; __jdc=122270672; 3AB9D23F7A4B3C9B=SEELVNXBPU7OAA3UX5JTKR5LQADM5YFJRKY23Z6HDBU4OT2NWYGX525CKFFVHTRDJ7Q5DJRMRZQIQJOW5GVBY43XVI; jwotest_product=99; __jda=122270672.16137119479101182770449.1613711948.1613738165.1613748918.4; JSESSIONID=C06EC8D2E9384D2628AE22B1A6F9F8FC.s1; shshshsID=ab2ca3143928b1b01f6c5b71a15fcebe_5_1613750374847; __jdb=122270672.5.16137119479101182770449|4.1613748918',
'Referer': 'https://www.jd.com/'
}
num=0 # 商品数量
comments_num=0 # 评论数量
# 获取商品信息和SkuId
def getIndex(url):
global num
skuids=[]
session=requests.Session()
session.headers=headers
res=session.get(url,headers=headers)
print(res.status_code)
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,'lxml')
items=soup.select('li.gl-item')
for item in items[:3]: # 爬取3个商品测试
title=item.select_one('.p-name a em').text.strip().replace(' ','')
price=item.select_one('.p-price strong').text.strip().replace('¥','')
try:
shop=item.select_one('.p-shopnum a').text.strip() # 获取书籍时查找店铺的方法
except:
shop=item.select_one('.p-shop a').text.strip() # 获取其他商品时查找店铺的方法
link=parse.urljoin('https://',item.select_one('.p-img a').get('href'))
SkuId=re.search('\d+',link).group()
skuids.append(([SkuId,session],None))
headers['Referer'] = f'https://item.jd.com/{SkuId}.html'
headers['Connection'] = 'keep-alive'
comments_num=getCommentsNum(SkuId,session) # 评论数量
print(SkuId,title, price, shop, link, comments_num)
print("开始将商品存入数据库...")
try:
IntoGoods(SkuId,title, price, shop, link, comments_num)
except Exception as e:
print(e)
sess_db.rollback()
num += 1
print("开始获取评论并存入数据库...")
pool2=threadpool.ThreadPool(3) # 可同时获取3个商品的评论
task=threadpool.makeRequests(getComments,skuids)
for r in task:
pool2.putRequest(r)
pool2.wait()
# 获取评论
def getComments(SkuId,sess):
# 获取评论总页数
url1 = f'https://club.jd.com/comment/productPageComments.action?productId={SkuId}&score=0&sortType=5&page=0&pageSize=10'
res2 = sess.get(url1, headers=headers)
res2.encoding = res2.apparent_encoding
json_data = json.loads(res2.text)
max_page = json_data['maxPage'] # 经测试最多可获取100页评论,每页10条
print("{}评论共{}页".format(SkuId, max_page))
if max_page == 0:
IntoComments(SkuId, '0')
else:
for i in range(0, max_page):
# 使用此链接获取评论得到的为json格式
url2 = f'https://club.jd.com/comment/productPageComments.action?productId={SkuId}&score=0&sortType=5&page={i}&pageSize=10'
# 使用此链接获取评论得到的非json格式,需要提取
# url2_2=f'https://club.jd.com/comment/productPageComments.action?callback=jQuery9287224&productId={SkuId}&score=0&sortType=5&page={i}&pageSize=10'
print("开始获取第{}页评论:{}".format(i + 1, url2))
getComments_one(sess, SkuId, url2)
time.sleep(1)
# 获取评论总数量
def getCommentsNum(SkuId,sess):
url=f'https://club.jd.com/comment/productCommentSummaries.action?referenceIds={SkuId}'
res=sess.get(url)
try:
res.encoding=res.apparent_encoding
json_data=json.loads(res.text) # json格式转为字典
num=json_data['CommentsCount'][0]['CommentCount']
return num
except:
return 'Error'
# 获取单个评论
def getComments_one(sess,SkuId,url2):
global comments_num
res2 = sess.get(url2)
res2.encoding=res2.apparent_encoding
json_data=res2.text
'''
# 如果用url2_2需要进行如下操作提取json
start = res2.text.find('jQuery9287224(') + len('jQuery9287224(')
end = res2.text.find(');')
json_data=res2.text[start:end]
'''
dict_data = json.loads(json_data)
comments=dict_data['comments']
for item in comments:
comment=item['content'].replace('\n','')
# print(comment)
comments_num+=1
try:
IntoComments(SkuId,comment)
except Exception as e:
print(e)
print("rollback!")
sess_db.rollback()
# 商品信息入库
def IntoGoods(SkuId,title, price, shop, link, comments_num):
goods_data=Goods(
sku_id=SkuId,
name=title,
price=price,
comments_num=comments_num,
shop=shop,
link=link
)
sess_db.add(goods_data)
sess_db.commit()
# 评论入库
def IntoComments(SkuId,comment):
comments_data=Comments(
sku_id=SkuId,
comments=comment
)
sess_db.add(comments_data)
sess_db.commit()
if __name__ == '__main__':
start_time=time.time()
urls=[]
KEYWORD=parse.quote(input("请输入要查询的关键词:"))
for i in range(1,2): # 爬取一页进行测试
url=f'https://search.jd.com/Search?keyword={KEYWORD}&wq={KEYWORD}&page={i}'
urls.append(([url,],None)) # threadpool要求必须这样写
pool=threadpool.ThreadPool(2) # 2个线程的线程池
reque=threadpool.makeRequests(getIndex,urls) # 创建任务
for r in reque:
pool.putRequest(r) # 向线程池提交任务
pool.wait() # 等待所有任务执行完毕
print("共获取{}件商品,获得{}条评论,耗时{}".format(num,comments_num,time.time()-start_time)) 好了,本文到此结束,带大家了解了《Python如何使用爬虫获取京东商品评论并存储到MySQL中?》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多数据库知识!
版本声明
本文转载于:亿速云 如有侵犯,请联系study_golang@163.com删除
 ChatGPT如何驱动数码通信和数据隐私的进步
ChatGPT如何驱动数码通信和数据隐私的进步
- 上一篇
- ChatGPT如何驱动数码通信和数据隐私的进步
- 下一篇
- 如何在 Windows 11 中禁用或限制通知?
查看更多
最新文章
-
- 数据库 · MySQL | 1星期前 | MySQL · 慢查询 · 索引优化 · COUNT查询 · 汇总表 · 联合索引 覆盖索引 汇总表 MySQL COUNT慢 COUNT(*)优化
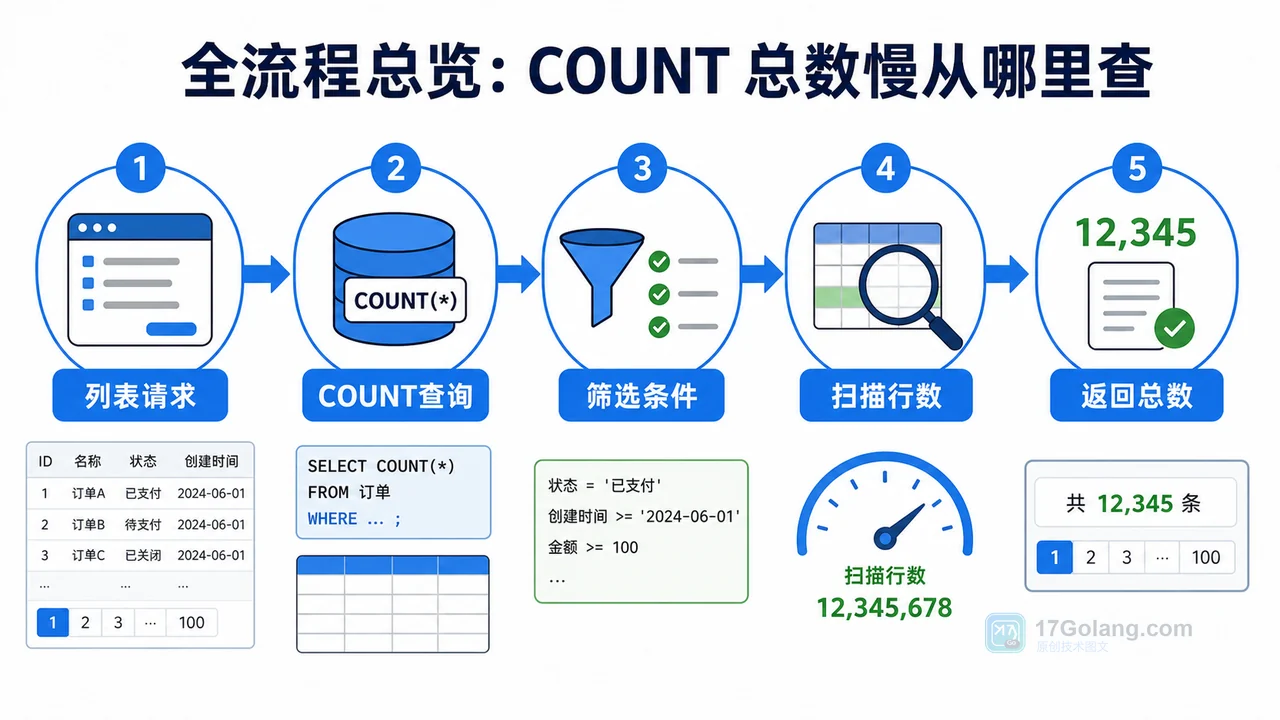
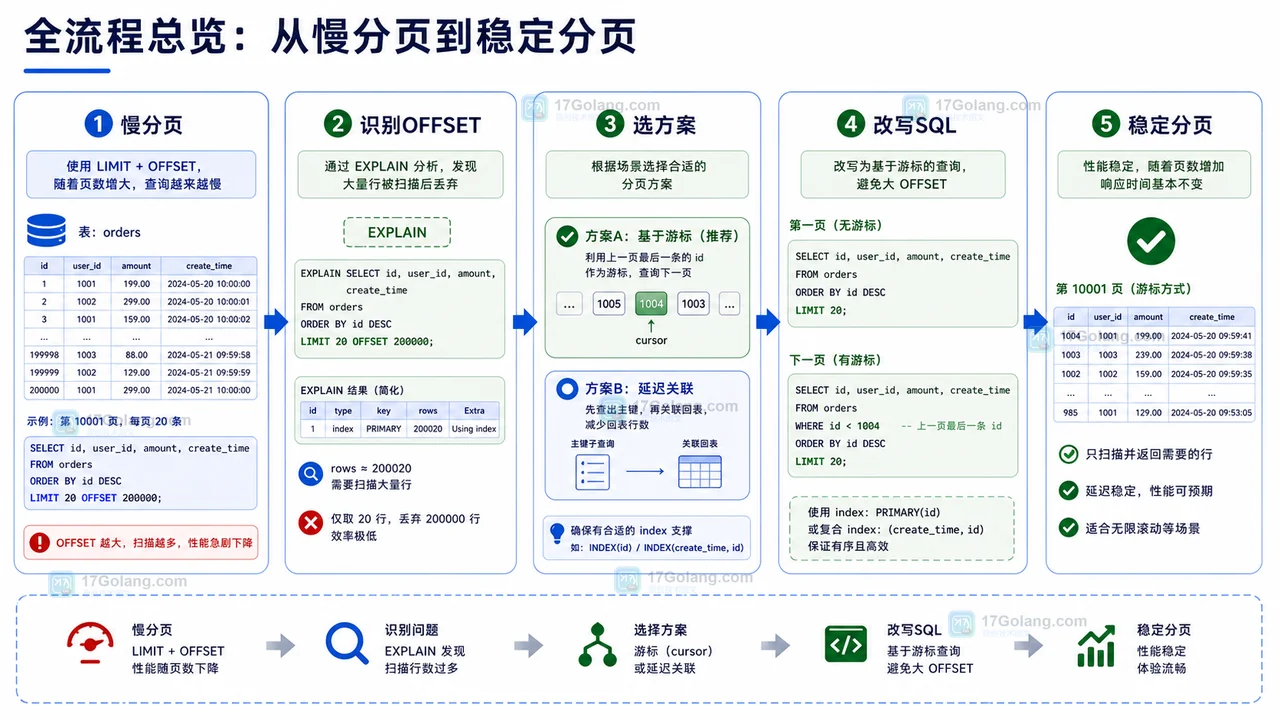
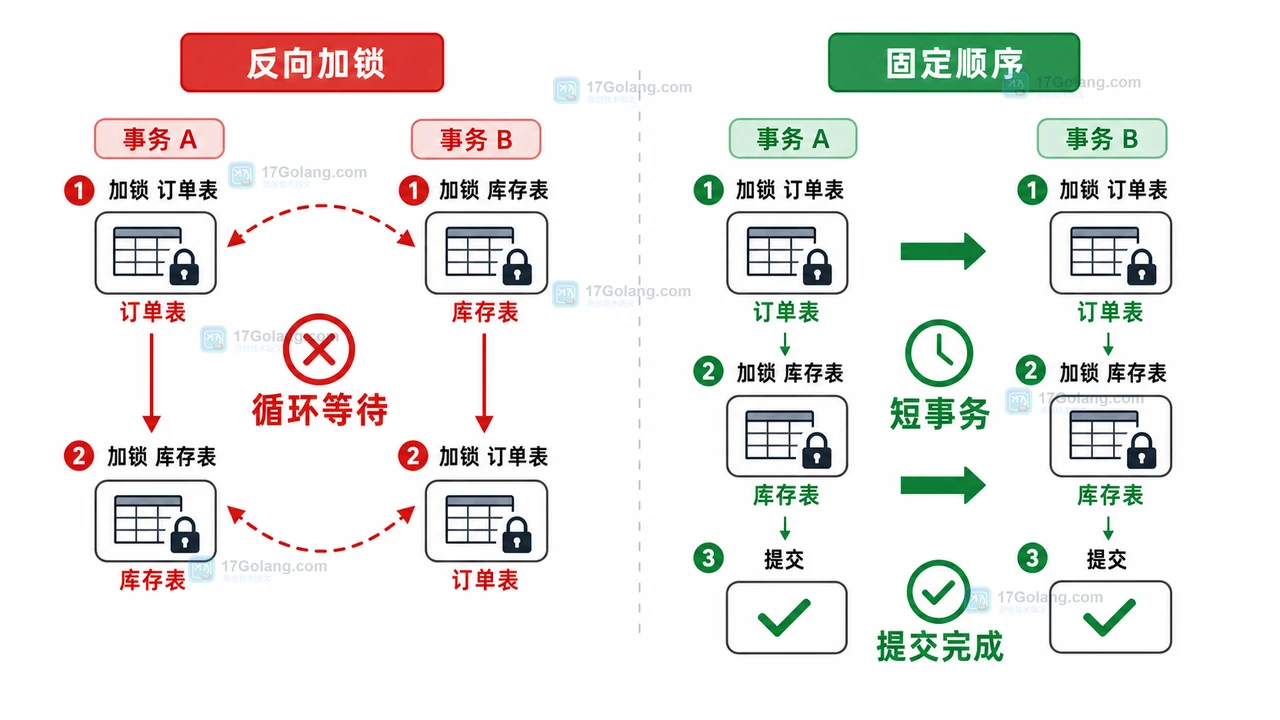
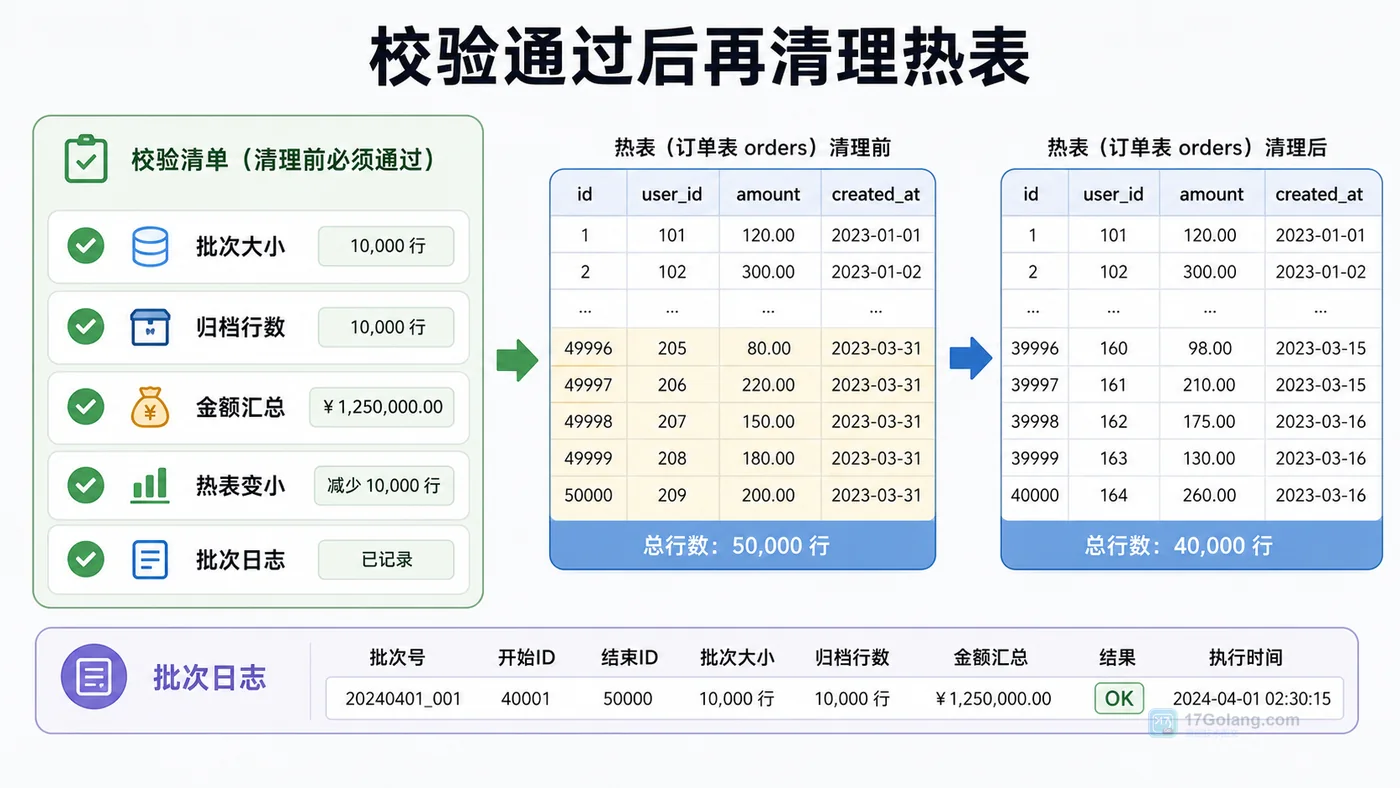
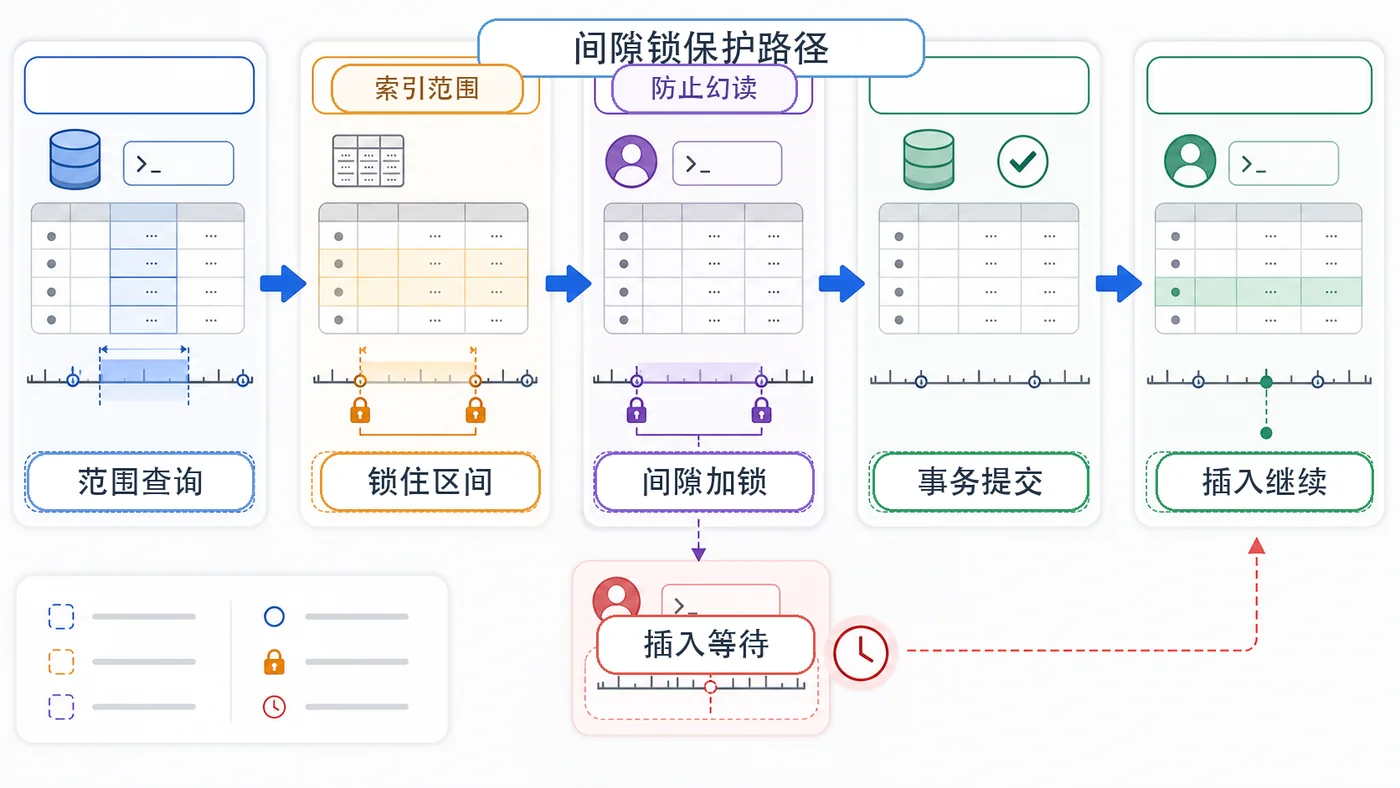
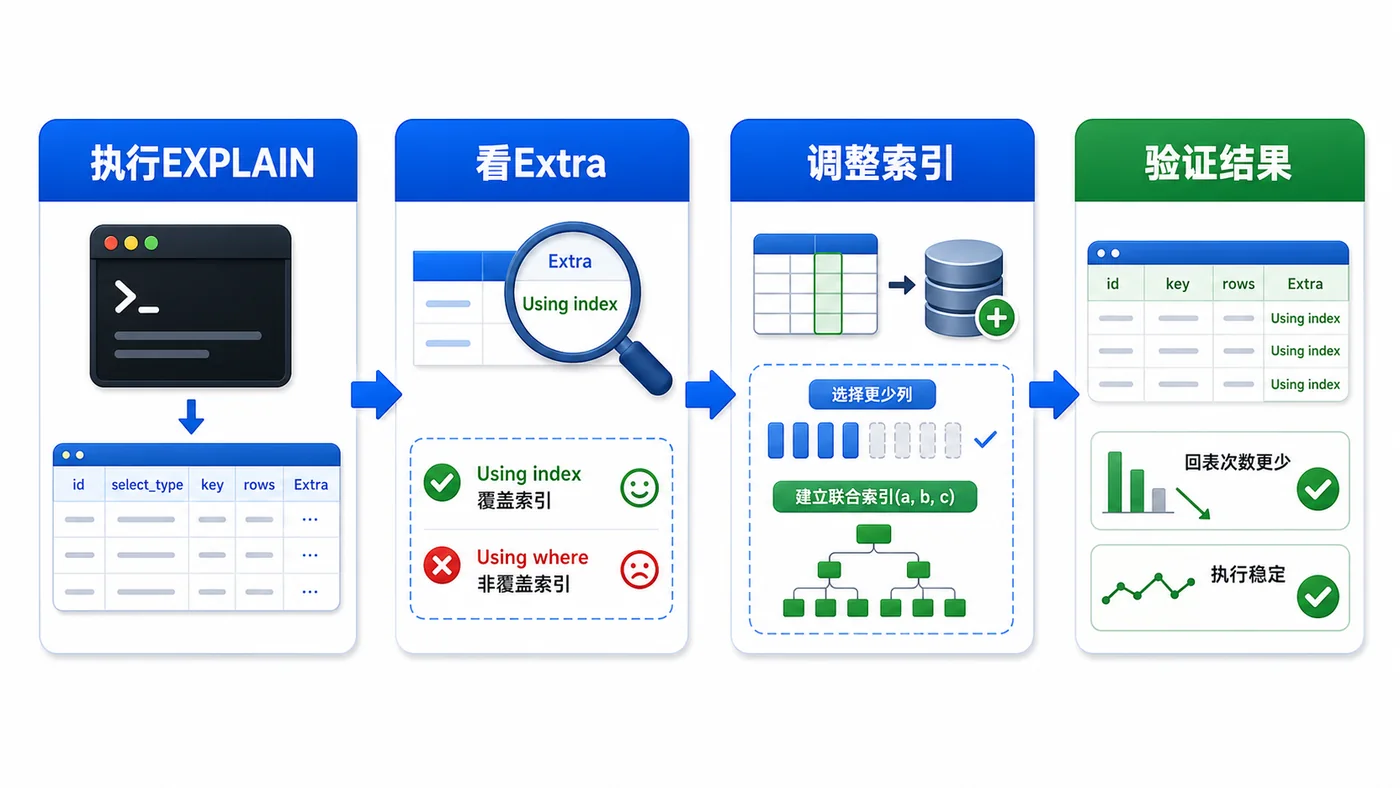
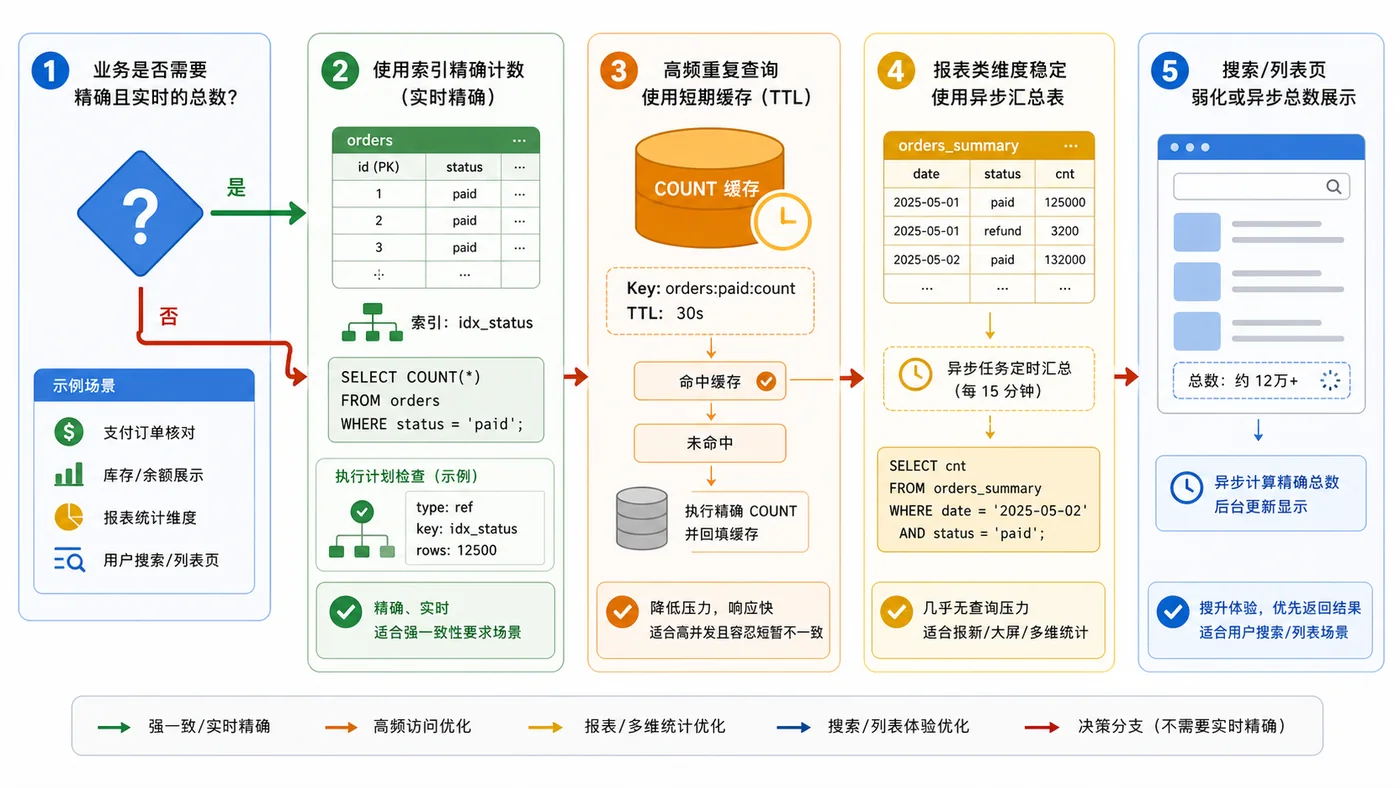
- MySQL COUNT(*) 总数查询变慢怎么办:从扫描行数到汇总表的完整治理流程
- 329浏览 收藏
查看更多
课程推荐
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
查看更多
AI推荐
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2235次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2046次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1999次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2213次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2172次使用
查看更多
相关文章
-
- MySQL权限管理设置全攻略
- 2026-03-29 501浏览
-
- MySQL分片实现方法及常见方案解析
- 2025-06-24 501浏览
-
- MySQL表空间碎片怎么清理?超详细优化教程
- 2025-06-13 501浏览
-
- MySQL排序性能优化技巧及方法
- 2025-06-04 501浏览
-
- MySQL建库建表全流程详解
- 2025-05-24 501浏览


