Java实时风控系统:深度学习规则引擎解析
在当今快速变化的风险环境中,传统的风控系统已难以满足需求。**基于Java的实时风控系统:深度学习规则引擎设计**,旨在打造一个能够毫秒级响应、智能识别并有效拦截潜在风险的自动化防御体系。该系统通过集成深度学习规则引擎,利用Kafka、Flink等构建实时数据流,并结合ONNX Runtime或DJL在Java环境运行深度学习模型,输出风险分数,再与Drools等规则引擎进行混合决策,支持动态阈值与模型热更新。相比传统规则引擎的静态性和滞后性,该方案通过AI自动学习复杂行为模式,显著提升了风险识别的准确性和适应性,广泛适用于支付反欺诈、信贷评估等场景。未来,该系统将向可解释性、联邦学习、自适应进化等方向发展,为金融风控领域带来革新。
答案:基于Java的实时风险控制系统通过集成深度学习规则引擎,实现毫秒级智能风控决策。系统以Kafka、Flink等构建实时数据流,利用ONNX Runtime或DJL在Java环境运行深度学习模型,输出风险分数并结合Drools等规则引擎进行混合决策,支持动态阈值与模型热更新。相比传统规则引擎的静态、滞后问题,该方案通过AI自动学习复杂行为模式,提升准确率与适应性,适用于支付反欺诈、信贷评估等场景,并向可解释性、联邦学习、自适应进化方向发展。

基于Java的实时风险控制系统,结合深度学习规则引擎,其核心在于构建一个能够迅速响应、智能识别并有效拦截潜在风险的自动化防御体系。它不再仅仅依赖于预设的、静态的业务规则,而是通过深度学习模型对海量数据进行实时分析,动态地生成或调整风险判断逻辑,从而在毫秒级的时间内做出决策,显著提升了风险识别的准确性和适应性。这就像给传统的风控系统装上了一个不断学习、进化的大脑,使其能够应对日益复杂和隐蔽的欺诈模式。
解决方案
要构建这样一个基于Java的实时风险控制系统,并集成深度学习规则引擎,我们需要一套端到端的设计思路。这不仅仅是技术栈的堆砌,更是一种架构哲学的体现:追求极致的实时性、智能性和可扩展性。
首先,数据是核心。系统需要强大的实时数据摄取能力,比如通过Kafka集群汇聚来自交易、用户行为、设备指纹等多种异构数据流。接着,这些原始数据会进入一个轻量级的实时特征工程管道,这通常会用到Apache Flink或Spark Streaming这样的流处理框架,快速提取出对风险判断至关重要的特征,例如交易频率、金额、地理位置变化等。
然后,核心的深度学习规则引擎登场。离线训练好的深度学习模型(例如,基于循环神经网络RNN或Transformer处理序列行为数据,或者使用卷积神经网络CNN处理图像/文本信息,以及多层感知机MLP处理结构化数据)会被部署到在线推理服务中。在Java环境中,我们可以利用ONNX Runtime、TensorFlow Serving的Java客户端,或者像Deeplearning4j、DJL(Deep Java Library)这样的本地库来加载和执行模型。
这里,"规则引擎"的概念被拓宽了。深度学习模型可以直接输出一个风险分数或一个风险类别预测。这个输出本身就可以被视为一种“规则”的触发条件。例如,如果模型预测的欺诈概率超过某个动态调整的阈值,系统就立即触发高风险处理流程。同时,我们也可以将模型的输出作为事实(Facts)注入到传统的Java规则引擎(如Drools)中,让传统规则与AI模型共同决策,形成一种混合规则集。这种设计允许我们既保留了业务专家经验的确定性规则,又引入了AI的自适应能力。
最后,决策执行模块根据规则引擎的输出,采取相应的风控措施,如拒绝交易、要求二次验证、发送预警通知或直接冻结账户。整个过程形成一个闭环,每次决策的结果都会被收集起来,用于模型的持续监控和再训练,确保系统始终处于最佳状态。
为什么传统的规则引擎在实时风控中显得力不从心?
我个人觉得,传统的规则引擎在面对瞬息万变的欺诈手段时,确实显得有些笨拙。它们本质上是基于“如果A发生,那么B”的逻辑,这些规则往往是业务专家根据历史经验和已知模式手动编写和维护的。想象一下,当新的欺诈手法出现时,你需要人工分析,然后编写新的规则,测试,部署。这个过程不仅耗时,而且滞后性很强。欺诈者可不会等你。
更深层次地看,传统规则引擎的局限性在于其静态性和离散性。它们难以捕捉到复杂、非线性的关联模式,比如某个用户在特定时间段内,从某个IP地址登录,并尝试进行一笔看似正常的交易,但结合其历史行为序列和设备指纹,可能就会发现异常。这种微妙的模式,人工编写的规则很难穷尽,也容易产生大量的误报或漏报。而且,规则数量一旦爆炸式增长,维护成本会变得非常高昂,规则之间的冲突也难以避免。这就好比你试图用一张张静态的地图去追踪一个高速移动且不断变道的物体,效率自然不高。深度学习的优势,恰恰在于它能从海量数据中自动学习这些隐蔽的、动态的复杂特征和模式,从而提供更精细、更实时的风险判断。
如何将深度学习模型有效融入Java规则引擎架构?
将深度学习模型融入Java规则引擎架构,这其实是关于如何让“智能大脑”与“执行手臂”高效协作的问题。在我看来,关键在于模型推理服务的构建与数据流的无缝衔接。
首先,深度学习模型本身通常是用Python框架(如TensorFlow、PyTorch)训练的。为了在Java生产环境中高效运行,我们需要将训练好的模型进行格式转换和优化。例如,可以将其转换为ONNX(Open Neural Network Exchange)格式,然后利用Java的ONNX Runtime库进行推理。或者,如果模型比较复杂,可以部署一个独立的模型服务(如TensorFlow Serving、TorchServe),Java应用通过gRPC或RESTful API调用这个服务获取推理结果。对于一些轻量级或特定领域的模型,也可以考虑使用DJL或Deeplearning4j等Java原生深度学习库直接加载和运行。
数据流方面,实时特征工程管道处理后的数据,会作为输入传递给深度学习模型。模型输出的通常是一个风险分数、概率值或一个分类标签。这个输出就是深度学习模型对当前事件的“判断”。这个判断结果可以有几种融入规则引擎的方式:
- 直接作为决策因子: 这是最直接的方式。例如,如果模型输出的欺诈概率高于0.8,系统就直接触发“高风险拦截”动作。此时,深度学习模型本身就扮演了核心“规则”的角色。
- 作为传统规则的“事实”: 模型的输出可以被包装成一个Java对象,作为事实(Fact)注入到传统的规则引擎(如Drools)中。比如,模型输出
fraudScore=0.75,那么Drools规则可以这样写:when transaction.amount > 1000 && fraudFact.score > 0.7 then action "review_transaction"。这种混合模式能更好地结合专家经验和AI能力。 - 动态规则阈值: 深度学习模型不仅可以预测风险,甚至可以动态调整传统规则的阈值。例如,模型可以根据当前风险环境的整体评估,建议将某个交易限额从5000元临时调整到3000元。
在实现上,为了保证低延迟,模型推理服务通常会以微服务形式部署,并进行性能优化,比如使用GPU加速、Batch Inference等。Java应用通过异步调用或线程池管理与模型服务的交互,避免阻塞主业务流程。同时,还需要考虑模型的版本管理和热更新,确保在不中断服务的情况下,能够平滑切换到新的模型版本。
// 假设这是从实时特征工程管道获取的特征数据
public class TransactionFeatures {
private String userId;
private double amount;
private int transactionCountLastHour;
// ... 其他特征
// Getters and Setters
}
// 示例:通过RESTful API调用模型服务
public class DeepLearningModelClient {
private final String modelServiceUrl = "http://localhost:8501/v1/models/fraud_detector:predict";
private final OkHttpClient httpClient = new OkHttpClient();
public double predictFraudScore(TransactionFeatures features) throws IOException {
// 将特征转换为模型服务所需的JSON格式
String jsonInput = convertFeaturesToJson(features);
RequestBody body = RequestBody.create(jsonInput, MediaType.get("application/json; charset=utf-8"));
Request request = new Request.Builder()
.url(modelServiceUrl)
.post(body)
.build();
try (Response response = httpClient.newCall(request).execute()) {
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
String responseBody = response.body().string();
// 解析模型返回的JSON,提取风险分数
return parseFraudScoreFromJson(responseBody);
}
}
private String convertFeaturesToJson(TransactionFeatures features) {
// 实际场景会使用Jackson/Gson等库序列化
return "{\"instances\": [{\"userId\": \"" + features.getUserId() + "\", \"amount\": " + features.getAmount() + "}]}";
}
private double parseFraudScoreFromJson(String jsonResponse) {
// 实际场景会使用Jackson/Gson等库反序列化
// 假设返回格式为 {"predictions": [[0.123]]}
return 0.123; // 示例值
}
}
// 示例:将模型分数注入Drools规则引擎
public class RiskDecisionEngine {
private KieContainer kieContainer; // Drools KieContainer
public RiskDecisionEngine() {
// 初始化Drools KIE容器
// kieContainer = KieServices.Factory.get().getKieClasspathContainer();
}
public void evaluateTransaction(TransactionFeatures features, double fraudScore) {
// KieSession kieSession = kieContainer.newKieSession();
// kieSession.insert(features);
// kieSession.insert(new FraudScoreFact(fraudScore)); // 将分数作为事实插入
// kieSession.fireAllRules();
// kieSession.dispose();
// 模拟Drools规则判断
if (features.getAmount() > 5000 && fraudScore > 0.7) {
System.out.println("高风险交易,需要人工复核或直接拒绝。");
} else if (fraudScore > 0.5) {
System.out.println("中等风险交易,建议短信验证。");
} else {
System.out.println("低风险交易,正常放行。");
}
}
}在Java中实现深度学习规则引擎,会面临哪些技术挑战和性能考量?
在Java生态中实现深度学习规则引擎,绝不是简单的技术堆砌,它涉及一系列复杂的技术挑战和严苛的性能考量。这就像是试图让一辆赛车在复杂的城市道路上以最高效率行驶,既要快,又要稳。
最大的挑战之一是延迟(Latency)。实时风控要求决策在毫秒级完成,这意味着从数据进入系统到模型推理,再到规则触发,整个链路都必须极度优化。Java的JVM虽然强大,但其启动时间、垃圾回收(GC)机制在极端低延迟场景下可能会成为瓶颈。为此,我们可能需要采用一些高级优化手段,比如利用GraalVM进行AOT(Ahead-Of-Time)编译,生成原生可执行文件,以减少启动时间和内存占用;精心调优JVM参数,选择合适的垃圾回收器;或者将模型推理服务独立部署,并通过高性能的RPC框架(如gRPC)进行通信。
资源管理也是一个痛点。深度学习模型,尤其是大型模型,通常占用大量内存和计算资源。在Java应用中加载和运行这些模型,需要仔细管理堆内存和非堆内存,避免OOM(Out Of Memory)错误。如果使用GPU进行推理,Java与底层GPU驱动的交互也需要专门的库(如CUDA的Java绑定),这增加了系统的复杂性。
模型管理与生命周期是另一个不容忽视的挑战。模型不是一劳永逸的,它们需要定期更新、迭代。如何在不停机的情况下,平滑地加载新模型、切换模型版本、进行A/B测试,并回滚到旧版本,这需要一套健壮的模型服务管理机制。这通常涉及到服务发现、负载均衡、蓝绿部署或金丝雀发布策略。
数据漂移(Data Drift)问题,在我看来,是深度学习风控系统长期稳定运行的隐形杀手。欺诈模式会不断演变,导致训练时的模型在生产环境中表现下降。系统必须有能力实时监控模型的性能指标,及时发现数据漂移,并触发模型的再训练和部署流程。这要求有完善的数据监控、模型监控和自动化模型训练管道。
最后,可解释性(Explainability)虽然不是纯粹的技术挑战,但在金融风控领域却至关重要。深度学习模型往往被视为“黑箱”,其决策过程难以理解。但在金融领域,合规性要求我们能够解释为什么一笔交易被拒绝,为什么一个用户被标记为高风险。在Java规则引擎中,我们可以尝试结合LIME、SHAP等可解释性AI技术,或者设计混合规则,让传统规则部分负责解释性,而深度学习模型负责准确性,以此来缓解这一问题。
总的来说,构建这样的系统,需要在性能、稳定性、可维护性和可解释性之间找到一个最佳平衡点,这需要深厚的技术积累和对业务场景的深刻理解。
这种深度学习规则引擎的实际应用场景和未来发展方向是什么?
在我看来,这种深度学习规则引擎的应用场景非常广泛,几乎涵盖了所有需要实时风险判断的领域,而且未来还有巨大的发展潜力。
实际应用场景:
- 支付与交易欺诈检测: 这是最典型的应用。系统可以实时分析用户的支付习惯、设备信息、地理位置、交易金额、频率等特征,结合深度学习模型识别出信用卡盗刷、虚假交易、羊毛党等欺诈行为,并在交易完成前进行拦截或验证。
- 信贷风险评估: 在线贷款、消费金融等场景下,需要对用户的信用风险进行快速评估。深度学习规则引擎可以综合分析用户的多维度数据(如社交行为、消费记录、征信报告等),预测违约风险,辅助审批决策。
- 反洗钱(AML)与合规性: 识别复杂的洗钱网络和异常资金流动模式,通过深度学习模型发现隐藏在海量交易数据中的可疑行为,帮助金融机构满足监管要求。
- 保险欺诈检测: 分析理赔申请中的各种信息,识别虚假报案、骗保等行为。
- 内容安全与风控: 在社交媒体、电商平台等,实时识别和拦截涉黄、涉暴、广告骚扰等违规内容和恶意行为。
- 网络安全入侵检测: 分析网络流量、系统日志,利用深度学习模型识别异常访问、DDoS攻击、恶意软件传播等安全威胁。
未来发展方向:
- 更强的可解释性(XAI): 随着AI在关键决策领域应用的深入,对模型决策过程透明度的要求会越来越高。未来的深度学习规则引擎会更深入地集成可解释性AI技术,不仅给出风险分数,还能提供“为什么”的解释,这对于合规性、用户信任和模型调试都至关重要。
- 自适应与强化学习: 现在的深度学习模型虽然能学习,但通常是离线训练、在线部署。未来,系统可能会引入强化学习,让规则引擎能够根据实时反馈和环境变化,自动学习和调整风险策略,实现真正的自适应风控。例如,在面对新型攻击时,系统能更快地调整防御策略。
- 联邦学习与隐私保护: 在金融等数据敏感行业,数据共享面临严格的隐私法规。联邦学习(Federated Learning)允许不同机构在不共享原始数据的情况下,协同训练模型,共同提升风控能力,这将是未来一个重要的发展方向。
- 多模态与跨域融合: 风险控制不再局限于单一数据源。未来的引擎将能更好地融合处理文本、图像、视频、行为序列等多种模态的数据,并实现跨业务、跨平台的数据融合,构建更全面的风险画像。
- 模型鲁棒性与对抗性攻击防御: 随着AI技术的发展,欺诈者也可能利用对抗性攻击来绕过深度学习模型。未来的风控系统需要更强的模型鲁棒性,能够有效抵御这种有意的干扰。
- 低代码/无代码AI风控平台: 降低AI风控系统的开发和部署门槛,让更多的业务专家能够参与到规则和模型的构建中,实现业务与技术的深度融合。
在我看来,这种深度学习规则引擎的未来,是走向一个更加智能、自主、安全且透明的风险管理新范式。它将不再仅仅是一个被动的防御者,而是一个主动学习、持续进化的智能守卫者。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
 Java代理模式详解:静态与动态代理对比
Java代理模式详解:静态与动态代理对比
- 上一篇
- Java代理模式详解:静态与动态代理对比
- 下一篇
- ApplicationData访问失败解决方法
-

- 文章 · java教程 | 4天前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95
- Java CompletableFuture 聚合接口优化:用超时兜底把 P95 从 920ms 降到 330ms
- 255浏览 收藏
-
- 文章 · java教程 | 5天前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签
- Java Webhook 回调接收接口设计:验签、幂等和状态流转
- 488浏览 收藏
-
- 文章 · java教程 | 1星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
- Java 本地 TTL 缓存小项目:用 ConcurrentHashMap 实现过期淘汰和命中统计
- 394浏览 收藏
-
- 文章 · java教程 | 1星期前 | Java · Stream · 数据处理 · 后端教程 · Java Stream bigdecimal 分组统计 Collectors 订单汇总
- Java Stream 分组统计实验:从订单列表到客户消费汇总
- 355浏览 收藏
-
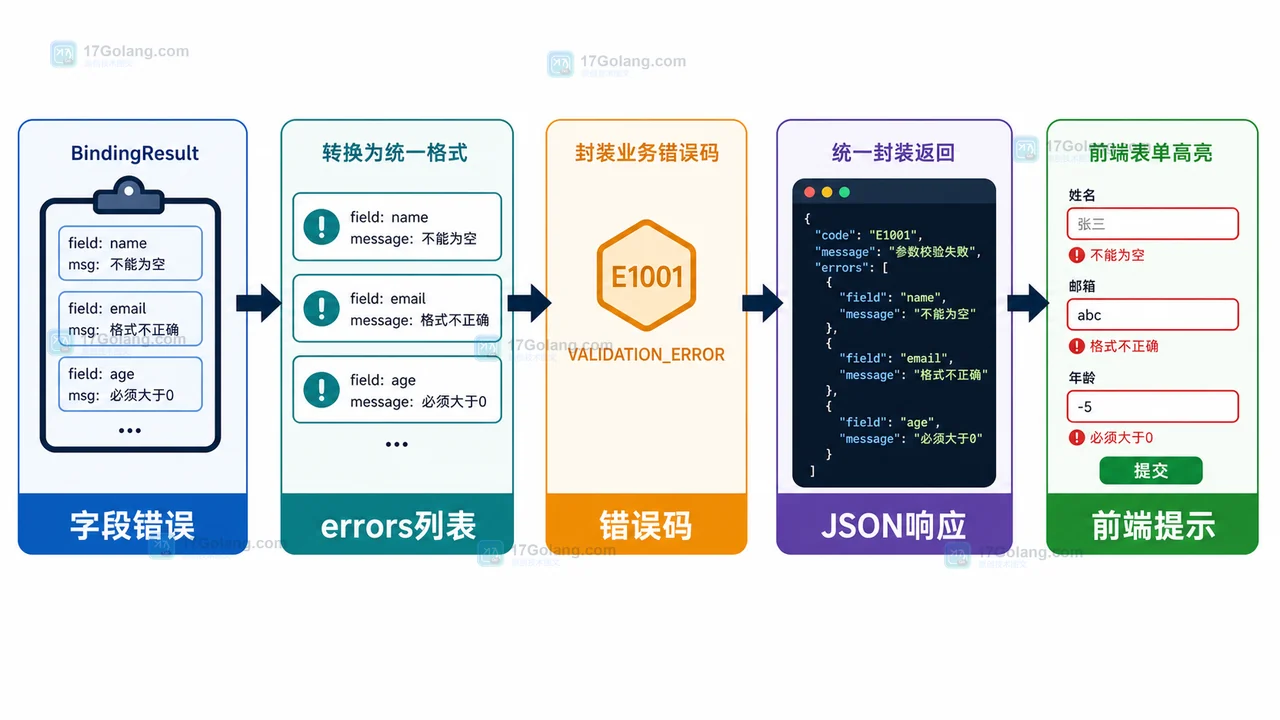
- 文章 · java教程 | 1星期前 | Java · Spring Boot · 后端开发 · 接口校验 · java spring boot dto 接口设计 参数校验
- Spring Boot 参数校验工作流:DTO、注解和统一错误响应
- 495浏览 收藏
-
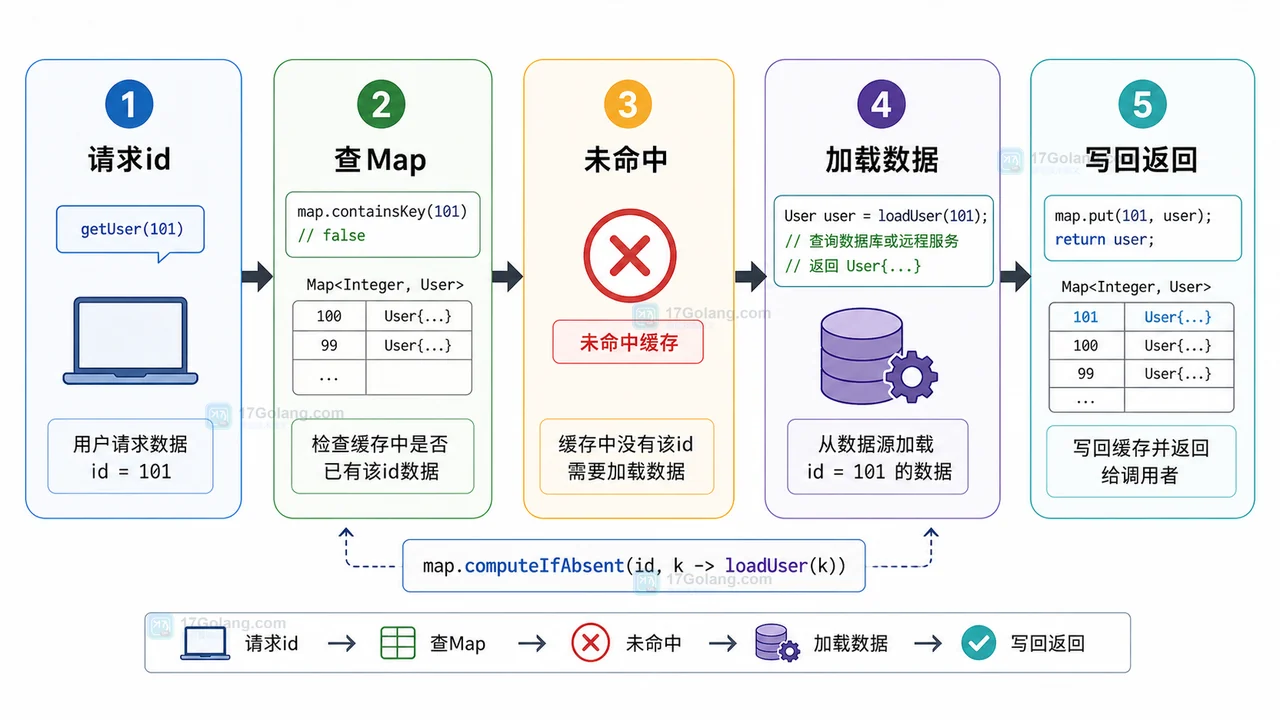
- 文章 · java教程 | 2星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3864次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 3569次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 3556次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3738次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3700次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


