GolangCSV包使用教程:读写CSV文件详解
在Go语言中,`encoding/csv`标准库是处理CSV文件的利器,尤其适合初学者。它提供简洁强大的API,无论是简单的数据导入导出还是复杂的ETL流程,都能胜任。本文将深入探讨如何使用`encoding/csv`包进行CSV文件的读写操作。读取CSV文件,可使用`csv.NewReader`配合`os.Open`,通过`ReadAll()`一次性读取或`Read()`逐行处理,后者更适合大型文件以降低内存占用。写入CSV文件,则使用`csv.NewWriter`结合`os.Create`,通过`Write()`逐行或`WriteAll()`批量写入,并务必使用`Flush()`确保数据写入磁盘。针对CSV编码问题,可使用`golang.org/x/text/transform`和相关编码包进行转换。此外,还可以自定义分隔符、宽容引号处理、允许字段数不一致等高级技巧,从而构建高效、稳定、兼容性强的CSV处理方案。
在Go语言中处理CSV文件首选标准库encoding/csv。1. 读取CSV文件时,使用csv.NewReader配合os.Open打开文件,通过ReadAll()一次性读取或Read()逐行处理,适合小文件或内存受限的大型文件。2. 写入CSV文件时,使用csv.NewWriter结合os.Create创建文件,通过Write()逐行或WriteAll()批量写入数据,最后调用Flush()确保数据写入磁盘。3. 处理大型CSV文件应避免一次性读取,改用Read()循环逐行处理,降低内存占用,必要时可结合Goroutines并行处理。4. 解决CSV编码问题,可在读取前使用golang.org/x/text/transform和对应编码包(如simplifiedchinese.GBK)将输入流转换为UTF-8。5. 高级技巧包括:自定义分隔符(设置Comma字段)、宽容引号处理(LazyQuotes=true)、允许字段数不一致(FieldsPerRecord=-1),以及合理处理各类解析错误。这些方法共同构成了高效、稳定、兼容性强的CSV处理方案。

在Go语言中处理CSV文件,encoding/csv标准库无疑是初学者的首选。它提供了一套简洁而强大的API,能够高效地读取和写入CSV格式的数据,无论是简单的数据导入导出,还是更复杂的ETL流程,它都能成为你可靠的起点。它内置了对CSV格式规范(如字段分隔符、引号处理)的支持,让你可以专注于数据的逻辑处理,而不是底层的格式解析。

解决方案
处理CSV文件通常涉及读取现有文件或创建新文件并写入数据。encoding/csv包在这两方面都提供了直观的接口。
读取CSV文件

要从CSV文件读取数据,你需要先打开文件,然后创建一个csv.Reader实例。最直接的方式是使用ReadAll()方法一次性读取所有记录到内存中,这对于小文件非常方便。
package main
import (
"encoding/csv"
"fmt"
"os"
)
func main() {
// 假设我们有一个名为 "data.csv" 的文件
// 内容可能如下:
// Name,Age,City
// Alice,30,New York
// Bob,24,London
// "Charlie, Jr.",35,"Paris, France"
file, err := os.Open("data.csv")
if err != nil {
fmt.Println("打开文件失败:", err)
return
}
defer file.Close() // 确保文件在函数结束时关闭
reader := csv.NewReader(file)
// reader.Comma = ';' // 如果你的分隔符不是逗号,可以在这里设置
// reader.FieldsPerRecord = -1 // 如果每行字段数不固定,设置为-1
records, err := reader.ReadAll() // 一次性读取所有记录
if err != nil {
fmt.Println("读取CSV失败:", err)
return
}
fmt.Println("读取到的CSV数据:")
for i, record := range records {
fmt.Printf("行 %d: %v\n", i+1, record)
}
}
写入CSV文件

写入CSV文件与读取类似,你需要创建一个文件用于写入,然后初始化一个csv.Writer。使用Write()方法逐行写入数据,或者WriteAll()一次性写入多行。记住,在所有数据写入完毕后,务必调用Flush()方法,确保所有缓冲区中的数据都已写入到底层文件。
package main
import (
"encoding/csv"
"fmt"
"os"
)
func main() {
// 准备要写入的数据
data := [][]string{
{"Header1", "Header2", "Header3"},
{"Value1A", "Value1B", "Value1C"},
{"Value2A", "Value2B", "Value2C"},
{"Value3A", "Value3B", "Value3C, with comma"}, // 包含逗号的字段会自动加引号
}
file, err := os.Create("output.csv") // 创建一个新文件
if err != nil {
fmt.Println("创建文件失败:", err)
return
}
defer file.Close()
writer := csv.NewWriter(file)
// writer.Comma = ';' // 同样,如果需要不同的分隔符,可以在这里设置
err = writer.WriteAll(data) // 写入所有数据
if err != nil {
fmt.Println("写入CSV失败:", err)
return
}
writer.Flush() // 确保所有数据都已写入文件
if err := writer.Error(); err != nil {
fmt.Println("刷新写入器时发生错误:", err)
}
fmt.Println("数据已成功写入 output.csv")
}如何处理大型CSV文件以避免内存问题?
当我第一次处理一个几GB的CSV文件时,直觉告诉我不能一股脑儿全读进内存,Go的encoding/csv库非常体贴地提供了逐行读取的能力。reader.ReadAll()虽然方便,但对于那些动辄几十万、上百万行的文件来说,它会瞬间占用大量内存,这在资源有限的环境下是灾难性的。
解决方案是使用reader.Read()方法在一个循环中逐行读取。这样,每次内存中只保留一行数据,大大降低了内存占用。你可以在读取每一行后立即对其进行处理,比如解析、转换或写入数据库。这种流式处理的方式是处理大数据文件的黄金法则。
package main
import (
"encoding/csv"
"fmt"
"io" // 导入io包,用于处理EOF错误
"os"
)
func main() {
file, err := os.Open("large_data.csv") // 假设这是你的大文件
if err != nil {
fmt.Println("打开文件失败:", err)
return
}
defer file.Close()
reader := csv.NewReader(file)
// reader.FieldsPerRecord = -1 // 如果某些行字段数可能不一致
// 跳过CSV文件的标题行(如果存在)
// _, err = reader.Read()
// if err != nil && err != io.EOF {
// fmt.Println("读取标题行失败:", err)
// return
// }
lineNumber := 0
for {
record, err := reader.Read() // 逐行读取
if err == io.EOF {
break // 文件读取完毕
}
if err != nil {
fmt.Printf("读取CSV第 %d 行失败: %v\n", lineNumber+1, err)
// 这里可以根据错误类型选择继续或停止
continue
}
lineNumber++
// 在这里处理每一行的数据
// 例如:fmt.Printf("处理行 %d: %v\n", lineNumber, record)
if lineNumber <= 5 { // 只打印前5行作为示例
fmt.Printf("处理行 %d: %v\n", lineNumber, record)
}
// 实际应用中,你可能会将 record 转换为结构体,然后存储到数据库或进行其他计算
}
fmt.Printf("总共处理了 %d 行数据。\n", lineNumber)
}
这种模式下,即使文件再大,你的程序也能保持稳定的内存占用。此外,如果你的处理逻辑允许,你甚至可以结合Goroutines和通道(channels)来并行处理这些行,进一步提升效率。但对于初学者,先掌握逐行读取的基础是关键。
CSV文件中的特殊字符和编码问题如何解决?
CSV文件最让人头疼的莫过于编码问题了,尤其是那些从老旧系统导出的数据,或者来自不同语系的同事发来的文件。encoding/csv默认假定你的文件是UTF-8编码,这在大多数现代应用中是合理的。然而,现实往往没那么理想:你可能会遇到带有BOM(Byte Order Mark)的UTF-8文件,或者干脆就是GBK、Latin-1、Shift-JIS等其他编码的文件。
处理这些问题,核心思路是在csv.Reader读取数据之前,先将输入流转换为UTF-8。Go标准库的扩展包golang.org/x/text/encoding系列提供了强大的编码转换能力。
处理BOM:
UTF-8文件有时会以BOM开头,这会导致csv.Reader将BOM作为文件内容的开头部分读取,从而破坏第一行的解析。你可以通过检查文件的前几个字节来判断是否有BOM,并跳过它:
// 简单的BOM检测和跳过
func removeBOM(r io.Reader) io.Reader {
bom := []byte{0xEF, 0xBB, 0xBF} // UTF-8 BOM
buf := make([]byte, 3)
n, err := r.Read(buf)
if err != nil || !bytes.Equal(buf[:n], bom[:n]) {
// 没有BOM或者读取失败,将已读字节放回
return io.MultiReader(bytes.NewReader(buf[:n]), r)
}
// 有BOM,直接返回原Reader,跳过BOM
return r
}
// 在打开文件后使用:
// file, err := os.Open("bom_data.csv")
// ...
// reader := csv.NewReader(removeBOM(file))处理非UTF-8编码:
当文件是其他编码时,你需要使用golang.org/x/text/encoding/charmap或golang.org/x/text/encoding/simplifiedchinese等子包来创建一个转换器,然后用transform.NewReader包装原始文件读取器。
package main
import (
"encoding/csv"
"fmt"
"io"
"os"
"golang.org/x/text/encoding/simplifiedchinese" // 用于GBK/GB18030
"golang.org/x/text/transform" // 用于创建转换器
)
func main() {
// 假设有一个GBK编码的CSV文件
// 你可以手动创建一个测试文件,例如:
// echo "姓名,年龄\n张三,25\n李四,30" | iconv -f UTF-8 -t GBK > gbk_data.csv
file, err := os.Open("gbk_data.csv")
if err != nil {
fmt.Println("打开文件失败:", err)
return
}
defer file.Close()
// 创建一个GBK到UTF-8的转换器
// simplifiedchinese.GBK.NewDecoder() 用于从GBK解码到UTF-8
// simplifiedchinese.GBK.NewEncoder() 用于从UTF-8编码到GBK
decoder := simplifiedchinese.GBK.NewDecoder()
reader := csv.NewReader(transform.NewReader(file, decoder))
records, err := reader.ReadAll()
if err != nil {
fmt.Println("读取CSV失败:", err)
return
}
fmt.Println("读取到的GBK编码CSV数据 (已转换为UTF-8):")
for i, record := range records {
fmt.Printf("行 %d: %v\n", i+1, record)
}
}通过这种方式,无论原始CSV文件是何种编码,你都能将其统一转换为Go字符串默认的UTF-8编码进行处理,避免了乱码问题。这在处理国际化数据或遗留系统数据时尤其重要。
除了基本读写,还有哪些高级技巧可以提升CSV处理效率?
除了基本的读写和编码处理,encoding/csv还提供了一些配置选项,能让你更灵活地应对各种“不标准”的CSV文件,或者优化特定场景下的处理逻辑。这些小技巧虽然不复杂,但在关键时刻能省去你不少麻烦。
自定义分隔符 (reader.Comma / writer.Comma)
CSV文件不总是用逗号分隔,很多时候会遇到用分号、制表符或其他字符分隔的。reader.Comma和writer.Comma字段允许你轻松修改这个默认行为。
// 读取分号分隔的CSV reader := csv.NewReader(file) reader.Comma = ';' // 设置分隔符为分号 // 写入制表符分隔的TSV writer := csv.NewWriter(file) writer.Comma = '\t' // 设置分隔符为制表符
懒惰引号模式 (reader.LazyQuotes)
有些CSV文件可能不严格遵守RFC 4180规范,例如,某个字段内容包含逗号但却没有被引号包围。默认情况下,csv.Reader会因为这种格式错误而报错。设置reader.LazyQuotes = true可以告诉解析器在遇到不规范的引号时,尝试更宽容地处理,而不是直接报错。但请注意,这可能会导致一些不期望的解析结果,所以最好在确认文件格式确实不规范且需要这种宽容处理时才使用。
reader := csv.NewReader(file) reader.LazyQuotes = true // 允许不严格的引号处理
字段数量不一致的处理 (reader.FieldsPerRecord)
在某些情况下,CSV文件的每一行可能包含不同数量的字段。默认情况下,如果FieldsPerRecord为0,csv.Reader会根据第一行的字段数来判断后续行的字段数,不一致时会报错。将其设置为-1则表示不对每行的字段数进行检查,这在处理某些日志文件或非标准数据源时非常有用。
reader := csv.NewReader(file) reader.FieldsPerRecord = -1 // 不检查每行字段数量是否一致
错误处理与io.EOF
在逐行读取时,io.EOF是表示文件结束的正常信号,不应作为错误处理。但其他类型的错误,比如csv.ErrFieldCount(字段数量不匹配),csv.ErrQuote(引号不匹配)等,则需要你根据业务逻辑决定如何处理:是跳过这一行,记录错误,还是直接终止程序。
for {
record, err := reader.Read()
if err == io.EOF {
break // 文件结束
}
if err != nil {
// 例如,如果只是字段数量不匹配,可以跳过
if err, ok := err.(*csv.ParseError); ok && err.Err == csv.ErrFieldCount {
fmt.Printf("警告:行 %d 字段数量不匹配,跳过。原始错误: %v\n", err.Line, err)
continue
}
fmt.Println("读取CSV时发生严重错误:", err)
return // 遇到无法处理的错误,终止
}
// 处理 record
}这些配置和技巧,虽然看起来只是参数调整,但在实际工作中能显著提升你处理各种“脏数据”的效率和程序的健壮性。掌握它们,能让你在面对复杂的CSV处理任务时更加从容。
本篇关于《GolangCSV包使用教程:读写CSV文件详解》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于Golang的相关知识,请关注golang学习网公众号!
 千牛卖家工作台入口指南
千牛卖家工作台入口指南
- 上一篇
- 千牛卖家工作台入口指南

- 下一篇
- Windows文件关联设置方法详解
-
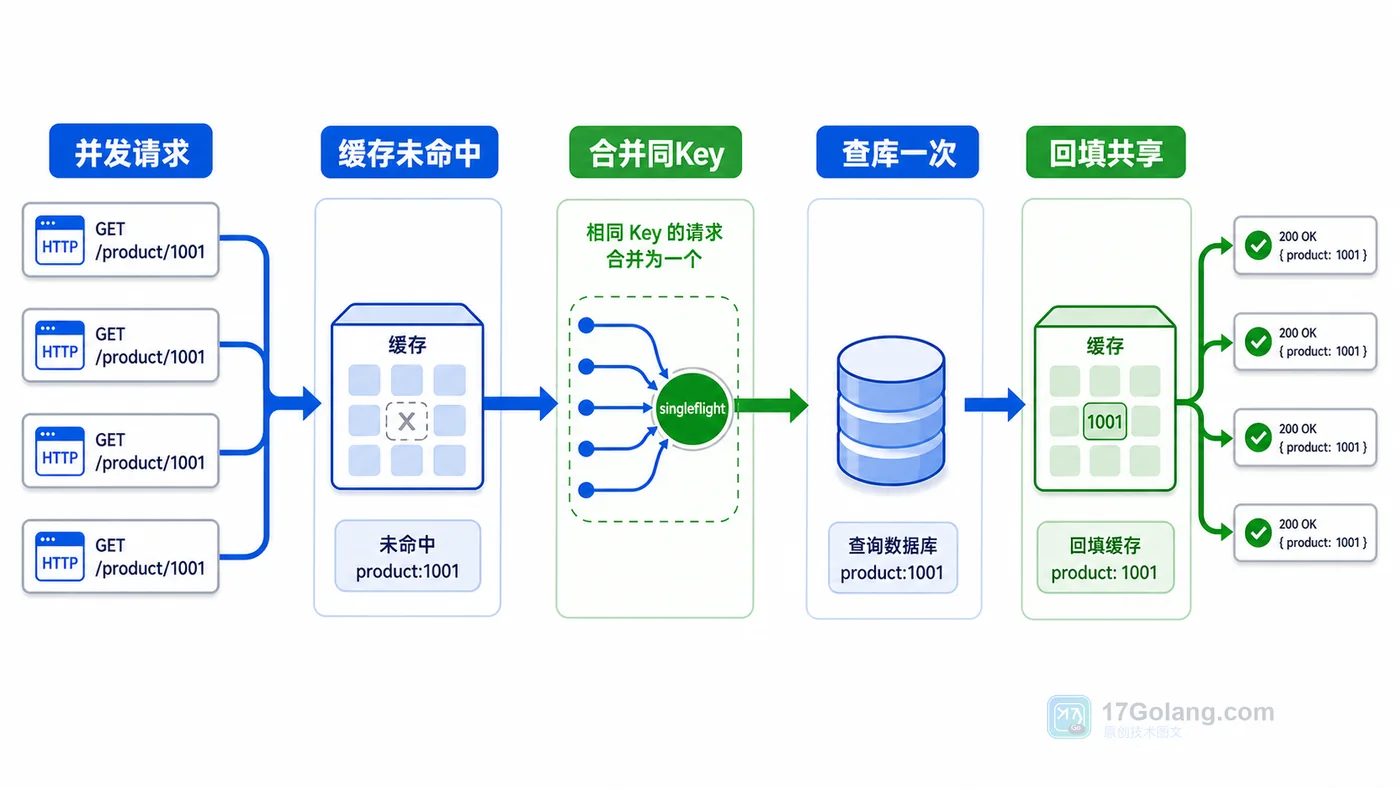
- Golang · Go教程 | 1天前 | singleflight · 并发控制 · Go教程 · 缓存治理 · 接口优化 · Go 并发请求 缓存击穿 singleflight 缓存回填
- Go singleflight 防缓存击穿实战:相同请求只查一次数据库
- 114浏览 收藏
-
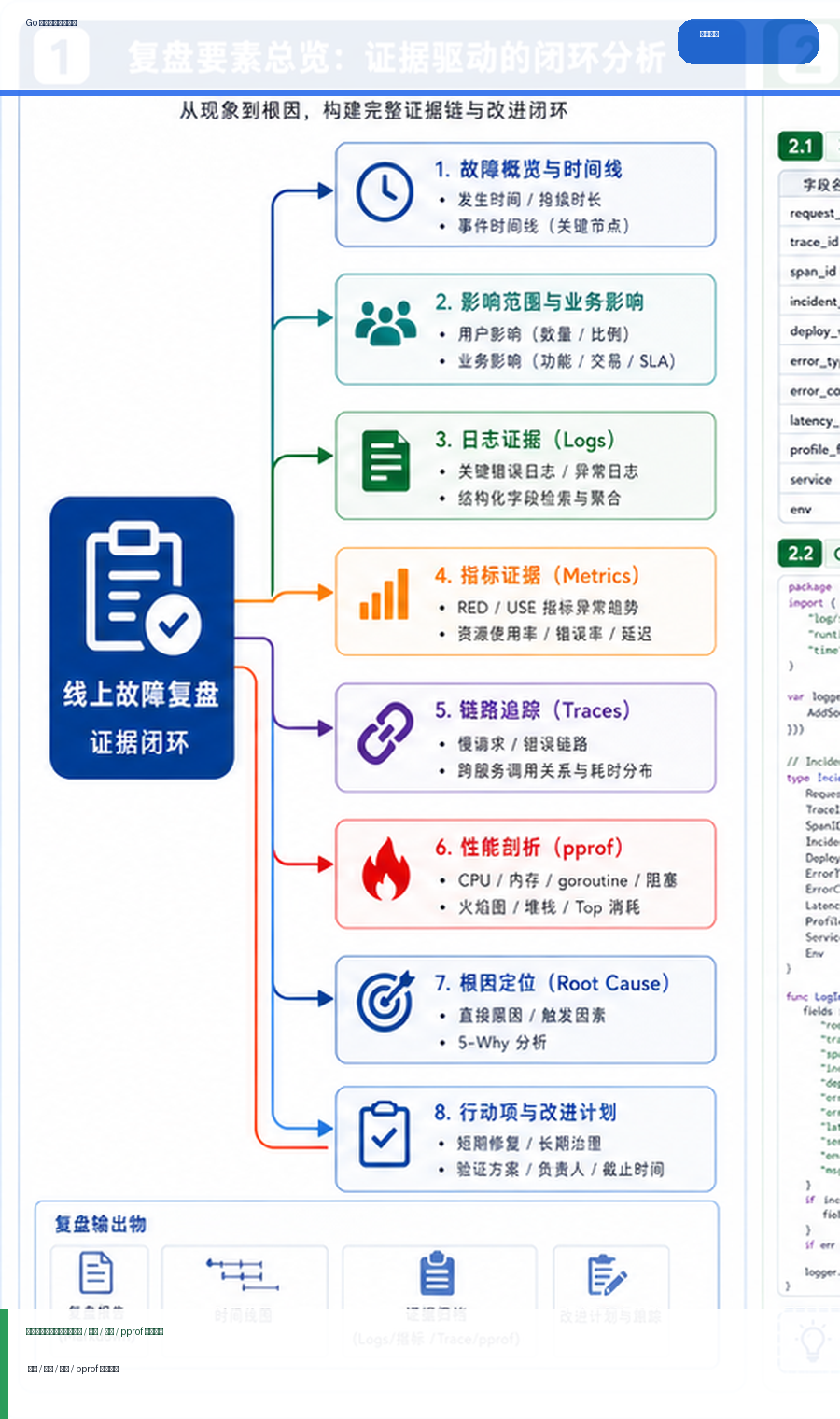
- Golang · Go教程 | 2天前 | golang
- Go 线上故障复盘模板:日志、指标、链路追踪与 pprof 证据闭环
- 710浏览 收藏
-
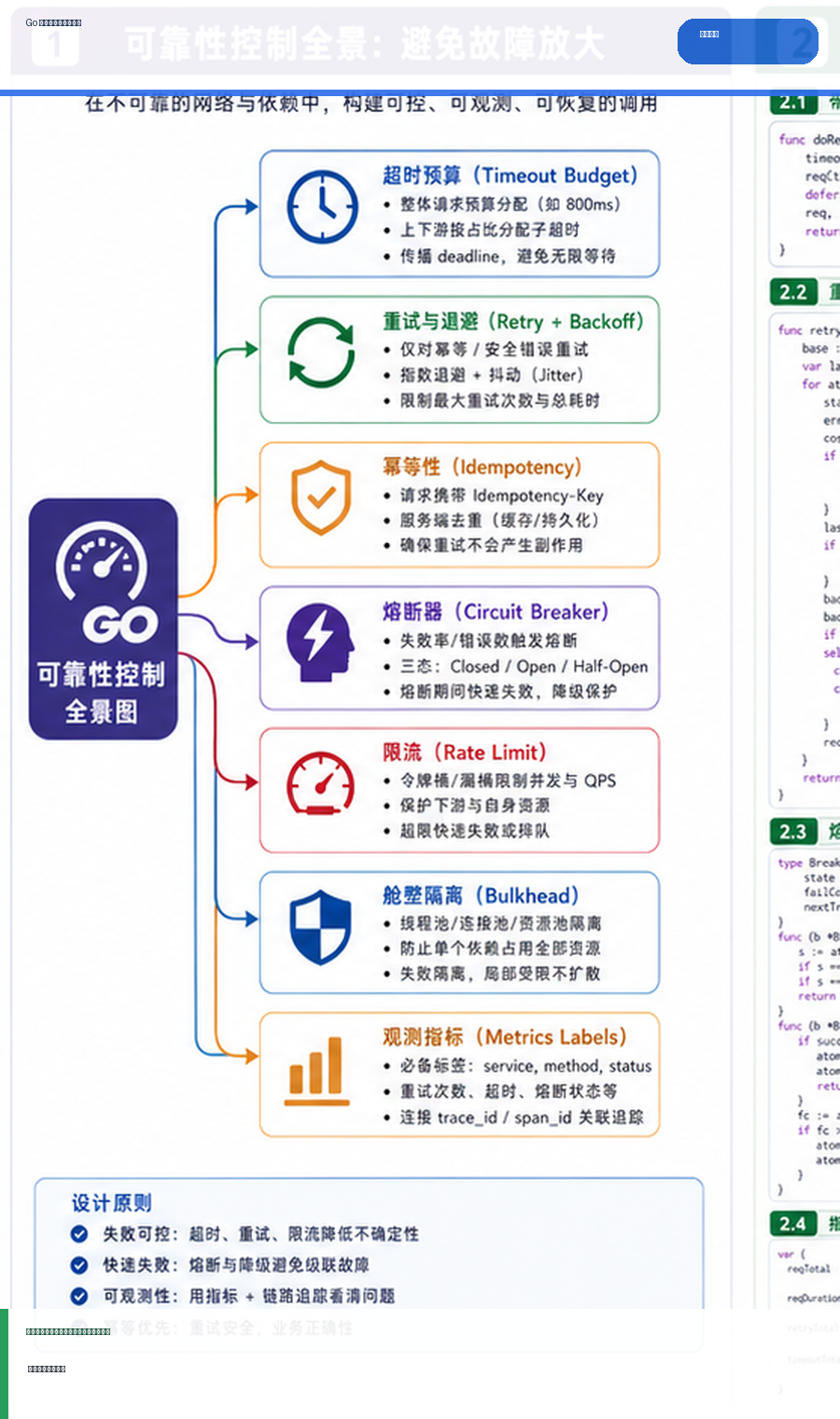
- Golang · Go教程 | 2天前 | golang
- Go 微服务超时、重试与熔断观测:避免故障放大的实践
- 687浏览 收藏
-
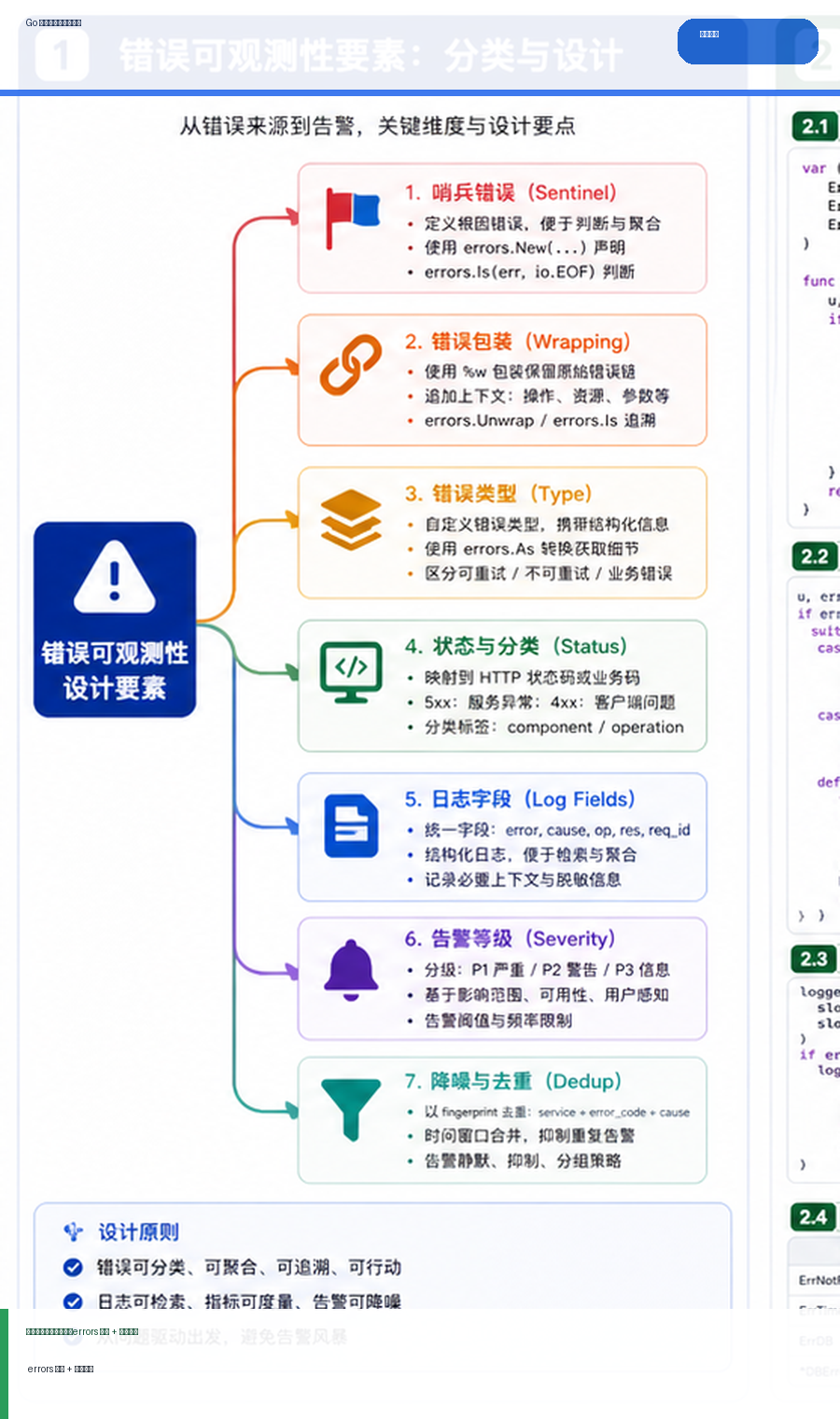
- Golang · Go教程 | 2天前 | golang
- Go 错误处理与告警设计:errors 包装、日志字段与告警降噪
- 664浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8471次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8891次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8715次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10621次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9549次使用
-
- Java 性能优化上线清单:从定位、改造到灰度发布
- 2026-06-11 860浏览
-
- Spring Boot 压测验证:Gatling、JMeter 与性能回归门禁
- 2026-06-11 843浏览
-
- Java NMT 非堆内存排查:Direct Buffer、线程栈与 Metaspace 分析
- 2026-06-11 826浏览
-
- Spring Boot 容器内存优化:JVM 堆、非堆与 MaxRAMPercentage
- 2026-06-11 809浏览
-
- Tomcat 连接与线程参数调优:maxThreads、acceptCount 与 KeepAlive
- 2026-06-11 792浏览


