Java常见Map实现与使用全解析
Java中的Map接口是日常开发中不可或缺的基础,它提供了一种键值对的存储方式,方便快速查找数据。本文深入解析了`HashMap`、`LinkedHashMap`、`TreeMap`和`ConcurrentHashMap`这四种常用的`Map`实现,详细阐述了它们各自的特性、适用场景以及线程安全问题。`HashMap`适用于单线程无序存储,`LinkedHashMap`适用于需要保持插入或访问顺序的场景,`TreeMap`适用于需要键排序的场景,而`ConcurrentHashMap`则为高并发环境下的首选。此外,本文还探讨了`Map`的线程安全解决方案,包括使用`Collections.synchronizedMap()`、`ConcurrentHashMap`、读写锁以及创建不可变`Map`。最后,针对`Map`的性能优化,特别是哈希冲突和容量调整,给出了实用的建议,帮助开发者选择最合适的`Map`实现,提升代码效率和质量。
答案:Java中Map接口的常用实现包括HashMap、LinkedHashMap、TreeMap和ConcurrentHashMap,分别适用于不同场景。HashMap基于哈希表实现,查找插入删除平均O(1),适合单线程无序存储;LinkedHashMap通过双向链表保持插入或访问顺序,适用于需顺序处理或LRU缓存场景;TreeMap基于红黑树实现键排序,支持范围查找,时间复杂度O(logN);ConcurrentHashMap为高并发设计,采用CAS+synchronized(JDK8)保证线程安全,性能优于全局锁的synchronizedMap。选择依据是性能、顺序、排序和并发需求:无特殊需求用HashMap;需顺序用LinkedHashMap;需排序用TreeMap;多线程用ConcurrentHashMap。线程安全可通过ConcurrentHashMap、synchronizedMap、读写锁或不可变Map解决。性能优化关键在于重写合理的hashCode()和equals()以减少冲突,并预设initialCapacity和loadFactor避免频繁扩容。

Java中的Map接口,说白了,就是一种“字典”或者“查找表”的数据结构,它把键(Key)和值(Value)关联起来,每个键都是唯一的,你可以通过键快速找到对应的值。理解Map的常用实现及其应用场景,是Java开发者日常工作中绕不开的基础,也是提升代码效率和质量的关键。选择合适的Map实现,能让你的程序在性能、内存和并发控制上达到最佳平衡。
解决方案
在Java的java.util包中,Map接口有几个非常重要的实现类,它们各自有着独特的特性和适用场景。我个人在项目中用得最多的,基本上就是HashMap、LinkedHashMap、TreeMap和ConcurrentHashMap这四位“老大哥”。
1. HashMap:最常用的无序键值对存储HashMap是Map家族里最常用的一员,它的核心优势就是查找、插入和删除操作的平均时间复杂度都是O(1),效率极高。它允许使用null作为键和值。不过,它有个明显的缺点:非线程安全。在多线程环境下直接使用HashMap,很容易出现数据不一致甚至死循环的问题。
它的底层原理是哈希表,通过键的hashCode()方法来确定存储位置。JDK8之后,当链表长度超过一定阈值(默认为8)时,链表会转换为红黑树,以保证最坏情况下的查找性能也能达到O(logN)。
2. LinkedHashMap:有序的键值对存储LinkedHashMap继承自HashMap,但它在HashMap的基础上增加了一个双向链表,所以它能保持元素的插入顺序,或者按访问顺序排序(这可以通过构造函数参数控制)。它同样非线程安全,也允许null键和值。
我个人在需要实现LRU(最近最少使用)缓存淘汰策略时,LinkedHashMap几乎是我的首选,因为它能非常方便地实现按访问顺序排序,并快速移除最不常用的元素。
3. TreeMap:有序的键值对存储(基于键的自然排序或自定义排序)TreeMap与前两者不同,它基于红黑树(一种自平衡二叉查找树)实现。这意味着TreeMap中的键是有序的,可以按照键的自然顺序(比如数字大小、字母顺序)进行排序,或者通过自定义Comparator来指定排序规则。它的查找、插入和删除操作的时间复杂度都是O(logN)。
TreeMap同样非线程安全,且不允许null键(因为null无法进行比较),但允许null值。当我需要对Map中的键进行范围查找,或者需要一个始终保持排序状态的Map时,TreeMap就是不二之选。
4. ConcurrentHashMap:高并发场景下的首选ConcurrentHashMap是为了解决多线程环境下HashMap的线程安全问题而设计的。它是一个线程安全的Map实现,并且在并发性能上远超传统的Hashtable(Hashtable通过对整个Map加锁实现线程安全,效率低下)。ConcurrentHashMap不允许null键和null值。
在JDK1.7中,它通过分段锁(Segment)实现了并发控制;而在JDK1.8中,它进一步优化,采用了CAS(Compare-And-Swap)操作和synchronized关键字结合的方式,对哈希桶的头节点进行锁定,进一步提升了并发度。对于需要共享Map数据的高并发应用,ConcurrentHashMap几乎是唯一的合理选择。
如何在不同场景下选择最适合的Map实现?
选择合适的Map实现,核心在于理解你的具体需求:你关心的是性能、数据顺序、线程安全,还是键的排序?在我看来,这是一个权衡的艺术。
- 追求极致性能,且在单线程环境或自行管理并发:
HashMap这是最常见的场景。如果你不需要关心元素的顺序,也不涉及多线程并发修改,那么HashMap通常是你的第一选择。它的O(1)平均时间复杂度在绝大多数情况下都能提供最佳性能。 - 需要保持插入顺序,或实现LRU缓存:
LinkedHashMap当你的业务逻辑对元素的插入顺序有要求,比如你需要按照数据进入的先后顺序进行处理,或者像我前面提到的,要实现一个基于访问顺序的缓存淘汰机制,LinkedHashMap就能派上大用场。 - 需要对键进行排序,或进行范围查找:
TreeMap如果你的键需要按照某种规则(自然顺序或自定义规则)进行排序,并且你可能需要执行“找出所有键在X到Y之间的元素”这类操作,那么TreeMap的有序特性就显得尤为重要。它能让你轻松地获取子Map或进行迭代。 - 多线程环境下,需要高并发地访问和修改Map:
ConcurrentHashMap这是最关键的决策点之一。一旦你的Map数据会被多个线程同时读写,并且你对性能有要求,那么请毫不犹豫地选择ConcurrentHashMap。它在保证线程安全的同时,提供了优秀的并发性能,避免了Hashtable那种粗粒度的全局锁带来的性能瓶颈。如果你只是偶尔需要同步,并且Map的数据量不大,也可以考虑Collections.synchronizedMap(new HashMap<>()),但通常ConcurrentHashMap是更优的选择。
我的经验是,除非有明确的有序性或线程安全需求,我通常会从HashMap开始。只有当这些特定需求浮现时,我才会转向LinkedHashMap、TreeMap或ConcurrentHashMap。
Map实现中的线程安全问题与解决方案有哪些?
HashMap、LinkedHashMap和TreeMap本质上都是非线程安全的。这意味着,在多线程环境下,如果没有适当的同步机制,对它们进行并发的读写操作,可能会导致各种意想不到的问题,比如数据丢失、ConcurrentModificationException,甚至在HashMap扩容时可能出现死循环。
解决这些线程安全问题,主要有以下几种策略:
使用
Collections.synchronizedMap()包装: 这是Java提供的一个简单粗暴的解决方案。你可以用Collections.synchronizedMap(new HashMap<>())来创建一个线程安全的Map。它的原理是对Map的所有方法都加上了synchronized关键字,这意味着在任何时候,只有一个线程能访问Map的任何方法。Map
这种方式虽然简单,但性能开销较大,因为它使用了全局锁。在并发量高的情况下,所有线程都会在同一个锁上竞争,导致性能急剧下降。所以,除非并发量极低,或者你对性能不敏感,否则我一般不推荐这种方式。
使用
ConcurrentHashMap: 这是高并发场景下最推荐的解决方案。ConcurrentHashMap在设计上就考虑了并发访问,它通过更细粒度的锁机制(JDK1.7的分段锁,JDK1.8的CAS+synchronized)来允许多个线程同时进行读写操作,从而提供了比Collections.synchronizedMap()更高的并发性能。import java.util.concurrent.ConcurrentHashMap; ConcurrentHashMap
它在保证数据一致性的同时,最大化了并发度。在我看来,只要是多线程共享Map的场景,
ConcurrentHashMap几乎是默认且最优的选择。使用读写锁(
ReentrantReadWriteLock)手动实现: 对于某些读操作远多于写操作的特殊场景,你可以考虑自己封装一个Map,并使用java.util.concurrent.locks.ReentrantReadWriteLock来提供更精细的控制。读写锁允许多个线程同时读取,但在写入时会独占锁。import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReentrantReadWriteLock; public class ReadWriteLockedMap
这种方式相对复杂,需要手动管理锁,但它提供了最大的灵活性。不过,在绝大多数情况下,
ConcurrentHashMap的性能和易用性已经足够满足需求了。创建不可变Map: 如果你的Map内容在创建后就不再需要修改,那么最彻底的线程安全方案就是创建不可变Map。一旦创建,它就不能被修改,自然也就不存在并发修改的问题。
- Java 9+
Map.of()/Map.ofEntries():Map
- Guava 的
ImmutableMap:// import com.google.common.collect.ImmutableMap; ImmutableMap
这种方式在配置信息、常量数据等场景下非常有用,它从根本上消除了线程安全问题。
- Java 9+
Map性能优化:从哈希冲突到容量调整的实践考量
Map的性能,尤其是HashMap和ConcurrentHashMap这类基于哈希表的实现,很大程度上取决于其内部的哈希机制和容量管理。理解这些细节,能在实际开发中避免一些常见的性能陷阱。
1. 良好的hashCode()和equals()方法
这是优化基于哈希的Map性能的基石。如果你的自定义对象作为Map的键,那么正确地实现hashCode()和equals()方法至关重要。
哈希冲突: 当不同的键计算出相同的哈希值时,就发生了哈希冲突。冲突越多,哈希桶中的链表(或红黑树)就越长,查找效率就会从理想的O(1)退化到O(N)甚至O(logN),严重影响性能。
实现原则:
- 如果两个对象
equals()为true,那么它们的hashCode()必须相同。 - 如果两个对象
equals()为false,它们的hashCode()可以相同也可以不同,但最好是不同,以减少冲突。 hashCode()应该尽可能均匀地分布哈希值,减少冲突。
- 如果两个对象
实践: 现代IDE(如IntelliJ IDEA)通常能自动生成高质量的
hashCode()和equals()方法,或者你可以使用Objects.hash()来简化hashCode()的实现。import java.util.Objects; class MyKey { private String name; private int id; // 构造函数、getter略 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; MyKey myKey = (MyKey) o; return id == myKey.id && Objects.equals(name, myKey.name); } @Override public int hashCode() { return Objects.hash(name, id); } }一个糟糕的
hashCode()实现(比如总是返回常数)会把所有键都映射到同一个桶,将哈希表退化成一个链表,性能直接降到O(N)。
2. 容量调整:initialCapacity 和 loadFactor
HashMap和ConcurrentHashMap在构造时可以指定initialCapacity(初始容量)和loadFactor(负载因子)。合理地设置这两个参数,能有效减少扩容(rehash)的次数,从而提升性能。
initialCapacity(初始容量):- 过小: 如果Map中将要存储大量元素,而初始容量设置过小,会导致Map频繁地进行扩容操作。每次扩容都需要重新计算所有元素的哈希值并重新分布到新的更大的底层数组中,这是一个非常耗时的操作。
- 过大: 浪费内存空间。
- 经验: 预估Map中最终会存储的元素数量
N。为了避免扩容,初始容量通常设置为N / loadFactor + 1,然后向上取最接近的2的幂。例如,如果你预计有100个元素,默认loadFactor是0.75,那么需要的容量大约是100 / 0.75 = 133.33,向上取2的幂就是256。 - 我的习惯: 在Map中元素数量可预知且较大时,我通常会主动设置一个合理的
initialCapacity,这比让Map自己频繁扩容要高效得多。
理论要掌握,实操不能落!以上关于《Java常见Map实现与使用全解析》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
 B站高级弹幕怎么发?代码弹幕教程分享
B站高级弹幕怎么发?代码弹幕教程分享
- 上一篇
- B站高级弹幕怎么发?代码弹幕教程分享

- 下一篇
- Java面向对象:类与对象全面解析
-
- 文章 · java教程 | 1天前 | http接口 · httpclient · Java教程 · 接口调试 · 超时处理 · java 接口调用 httpclient 超时控制 状态码 响应体
- Java HttpClient 调接口实战:超时、状态码和响应体这样处理
- 224浏览 收藏
-
- 文章 · java教程 | 1天前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT
- Java 时间与时区处理实战:Instant、ZoneId 和 DateTimeFormatter 怎么配
- 461浏览 收藏
-
- 文章 · java教程 | 1天前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
- Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
- 478浏览 收藏
-
- 文章 · java教程 | 2天前 | Java · 文件读取 · 异常处理 · 资源管理 · try-with-resources · java 异常处理 try-with-resources 资源关闭 AutoCloseable 文件流
- Java try-with-resources 资源关闭实战:文件流和目录扫描这样写更稳
- 268浏览 收藏
-
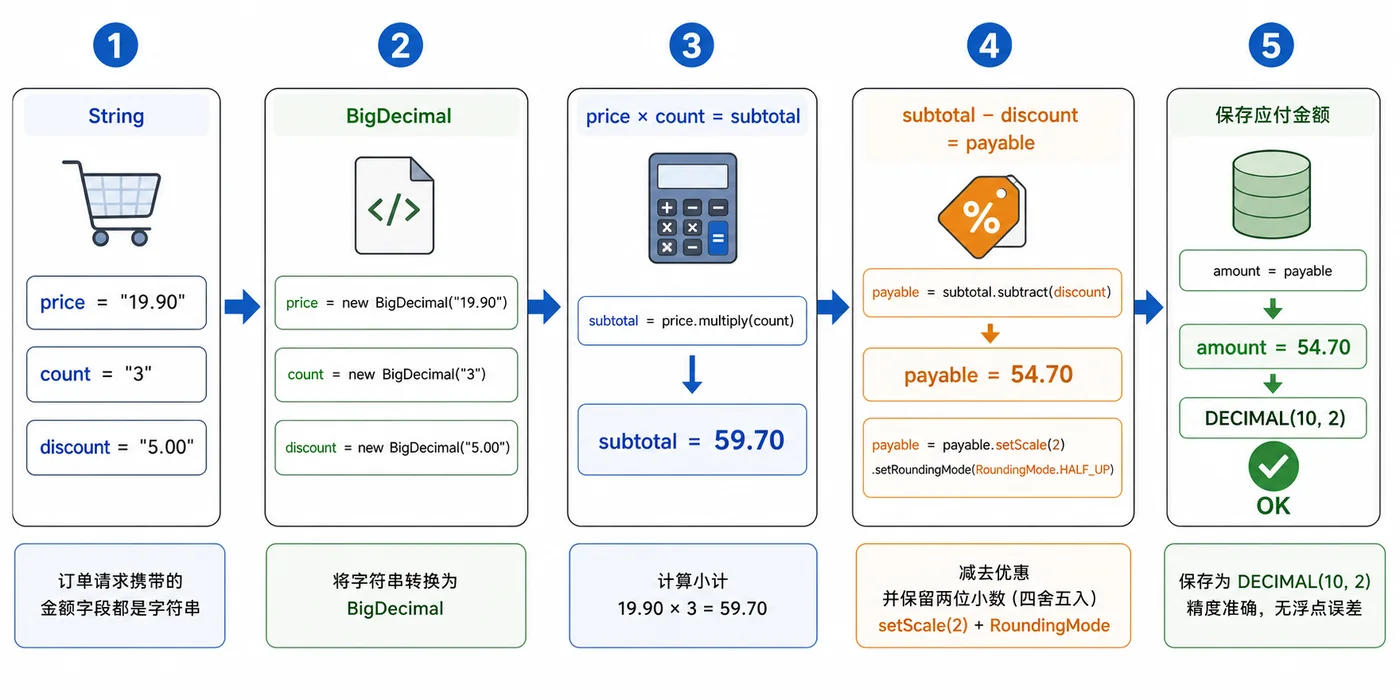
- 文章 · java教程 | 2天前 | Java教程 · 后端开发 · BigDecimal · 金额计算 · java 舍入 bigdecimal 浮点误差 金额计算 RoundingMode
- Java BigDecimal 金额计算实战:避免浮点误差和舍入问题
- 324浏览 收藏
-
- 文章 · java教程 | 2天前 | 异步编程 · Java教程 · 超时治理 · CompletableFuture · java 异步任务 超时处理 completablefuture orTimeout completeOnTimeout
- Java CompletableFuture 超时处理实战:orTimeout 和兜底结果怎么选
- 421浏览 收藏
-

- 文章 · java教程 | 6天前 | 并发编程 · 生产实践 · Java教程 · JDK25 · 虚拟线程 · 虚拟线程 Java 25 JEP 505 Structured Concurrency StructuredTaskScope
- Java 25 Structured Concurrency 实战:别让 CompletableFuture 把超时拖散
- 443浏览 收藏
-
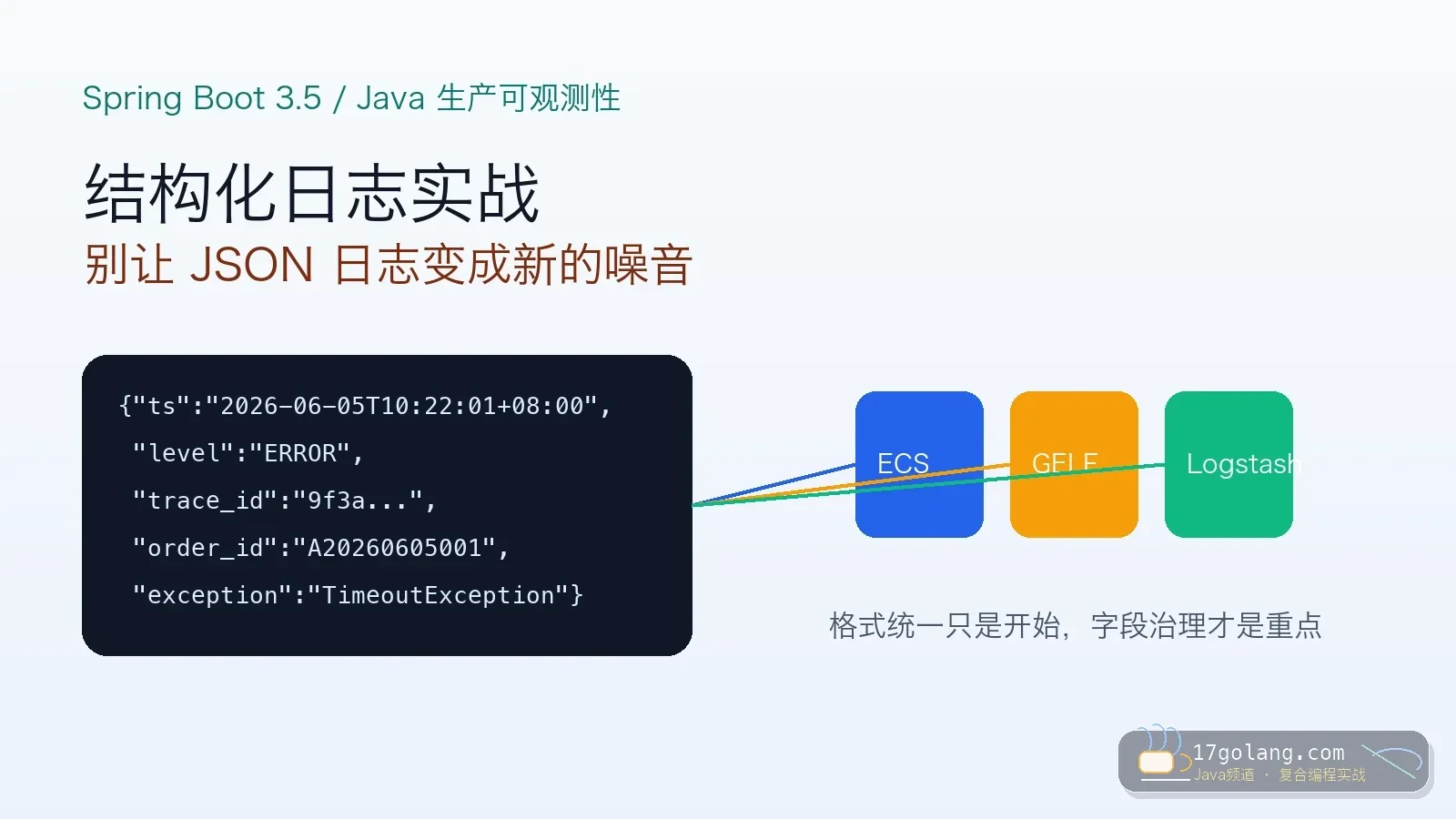
- 文章 · java教程 | 1星期前 | 日志 · Spring Boot · 生产实践 · 可观测性 · Java教程 · java 可观测性 MDC 结构化日志 Spring Boot 3.5
- Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
- 332浏览 收藏
-
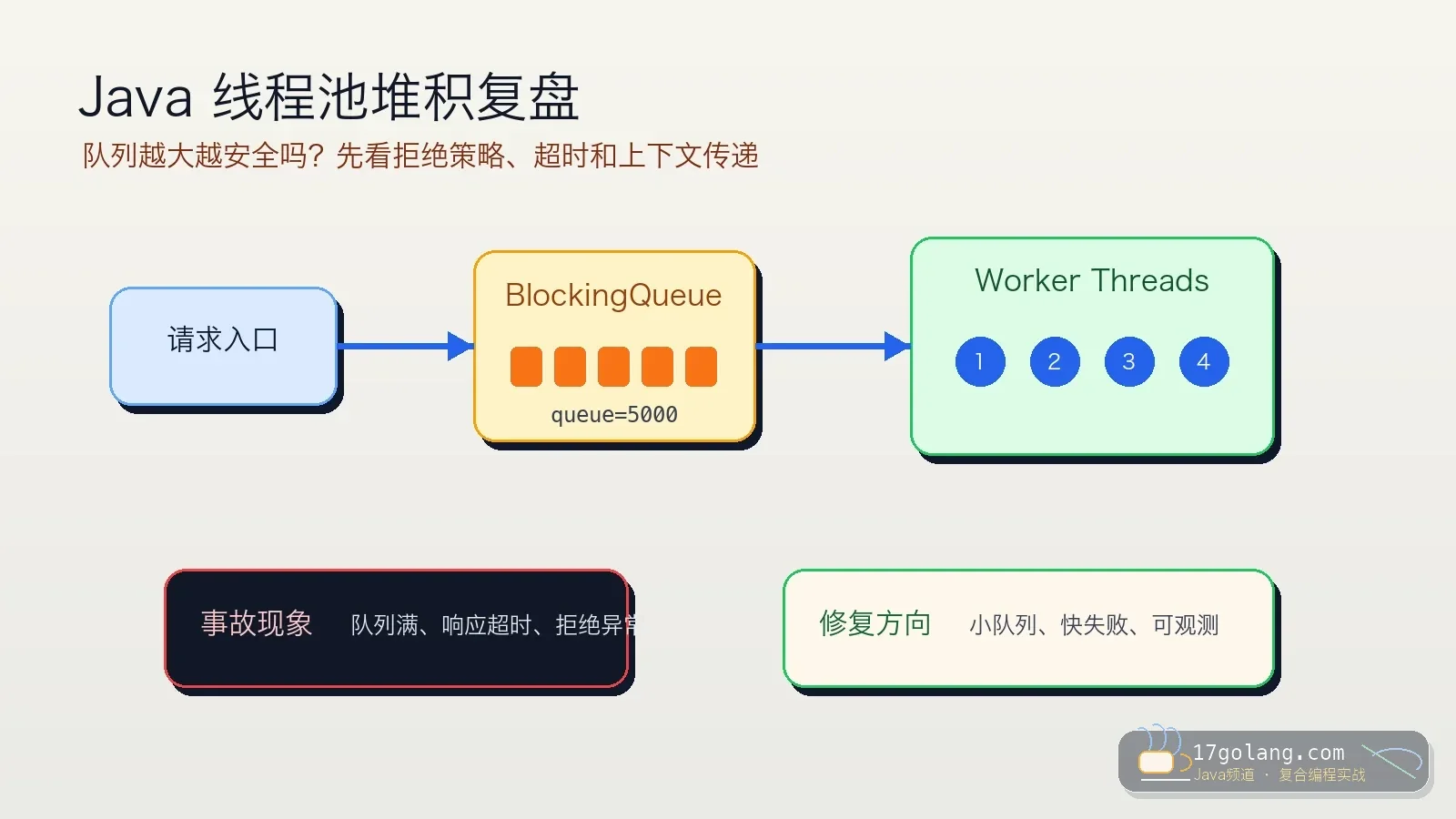
- 文章 · java教程 | 1星期前 | 线程池 · Spring Boot · 生产实践 · Java教程 · ThreadPoolExecutor · java 性能优化 线程池 spring boot threadpoolexecutor
- Java 线程池队列堆积复盘:别让无界队列把慢故障藏起来
- 326浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8611次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9029次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8853次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10756次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9695次使用
-
- 提升Java功能开发效率的有力工具:微服务架构
- 2023-10-06 501浏览
-
- 掌握Java海康SDK二次开发的必备技巧
- 2023-10-01 501浏览
-
- 如何使用java实现桶排序算法
- 2023-10-03 501浏览
-
- Java开发实战经验:如何优化开发逻辑
- 2023-10-31 501浏览
-
- 如何使用Java中的Math.max()方法比较两个数的大小?
- 2023-11-18 501浏览


