JavaScript正则表达式匹配全解析
JavaScript正则表达式是处理文本的强大工具,通过RegExp对象和String方法,可实现文本的匹配、替换和分割等操作。本文深入解析了JavaScript中正则表达式的核心方法,包括`match`、`search`、`replace`、`split`、`test`和`exec`,并详细讲解了贪婪与非贪婪匹配、回溯陷阱以及字符转义等常见问题。此外,文章还探讨了正则表达式的性能优化策略,如避免循环中重复创建正则,以及构建复杂正则时的分步策略和命名捕获组的应用。最后,介绍了先行/后行断言、Unicode属性转义、matchAll及replace中的特殊变量等高级功能,助你提升JavaScript文本处理能力。
JavaScript正则表达式通过RegExp和String方法实现文本匹配、替换、分割等操作,核心方法包括match、search、replace、split、test和exec;需注意贪婪与非贪婪匹配、回溯陷阱、字符转义等常见问题;性能上应避免循环中重复创建正则、优先使用简单字符串方法;构建复杂正则时可采用分步策略、命名捕获组并借助在线工具调试;高级功能如先行/后行断言、Unicode属性转义、matchAll及replace中的特殊变量可实现强大文本处理能力。

在JavaScript中,利用正则表达式进行匹配主要依赖于RegExp对象以及字符串(String)对象上的一系列方法。说白了,就是给你一串文本,然后你用一个模式(正则表达式)去这串文本里找你想要的东西,或者替换、分割它。这东西在处理文本数据、表单验证、日志分析这些场景里简直是神器。
解决方案
JavaScript提供了两种创建正则表达式的方式:字面量和构造函数。字面量是/pattern/flags这种形式,它在脚本加载时就会被编译,适合那些固定不变的模式。而new RegExp('pattern', 'flags')则更灵活,可以在运行时动态构建模式字符串。
核心的匹配操作,我们通常会用到以下几个方法:
String.prototype.match(): 这个方法会尝试匹配字符串,并返回一个包含所有匹配结果的数组。如果正则表达式带有g(全局)标志,它会返回所有匹配的子字符串。如果没有g标志,它只返回第一个匹配,以及捕获组信息。如果没有任何匹配,则返回null。const text = "Hello World, hello JavaScript!"; const regex1 = /hello/i; // 不区分大小写,非全局 console.log(text.match(regex1)); // ["Hello", index: 0, input: "Hello World, hello JavaScript!", groups: undefined] const regex2 = /hello/gi; // 不区分大小写,全局 console.log(text.match(regex2)); // ["Hello", "hello"]
String.prototype.search(): 这个方法返回第一个匹配项的索引位置。如果找不到,返回-1。它不关心g标志,总是只找第一个。const text = "Hello World, hello JavaScript!"; console.log(text.search(/world/i)); // 6 console.log(text.search(/javascript/)); // 19 console.log(text.search(/vue/)); // -1
String.prototype.replace(): 用于替换匹配的子字符串。如果正则表达式有g标志,它会替换所有匹配项;否则只替换第一个。替换字符串可以是一个普通字符串,也可以是一个函数,这在处理复杂替换逻辑时非常有用。const text = "我爱JavaScript,你也爱JavaScript吗?"; console.log(text.replace(/JavaScript/g, "JS")); // "我爱JS,你也爱JS吗?" // 使用函数进行替换 const priceText = "价格是 $100 和 $250。"; console.log(priceText.replace(/\$(\d+)/g, (match, p1) => { return `人民币${p1}元`; })); // "价格是 人民币100元 和 人民币250元。"String.prototype.split(): 用正则表达式或固定字符串作为分隔符,将字符串分割成一个数组。const tags = "前端,JavaScript,React Vue,Node.js"; console.log(tags.split(/[, ]+/)); // 以逗号或空格分割 // ["前端", "JavaScript", "React", "Vue", "Node.js"]
RegExp.prototype.test(): 这个方法返回一个布尔值,表示字符串是否包含与正则表达式匹配的模式。const emailRegex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/; console.log(emailRegex.test("test@example.com")); // true console.log(emailRegex.test("invalid-email")); // falseRegExp.prototype.exec(): 这是最强大的方法之一。它执行一个搜索,返回一个结果数组(包含匹配的字符串、捕获组等),或者在没有匹配时返回null。与match()不同的是,当正则表达式带有g标志时,exec()每次调用只会返回一个匹配,并且会更新regex.lastIndex属性,从而实现迭代所有匹配。const text = "cat, dog, bird, cat again"; const regex = /(cat|dog)/g; let match; while ((match = regex.exec(text)) !== null) { console.log(`Found "${match[0]}" at index ${match.index}. Next search starts at ${regex.lastIndex}.`); } // Found "cat" at index 0. Next search starts at 3. // Found "dog" at index 5. Next search starts at 8. // Found "cat" at index 19. Next search starts at 22.
JavaScript正则表达式的常见陷阱和性能考量是什么?
在实际使用JavaScript正则表达式时,我们确实会遇到一些小坑,或者说,一些需要特别注意的地方。性能问题也常常是大家关心的。
一个常见的陷阱是贪婪与非贪婪匹配。默认情况下,量词(如 另一个更隐蔽、更致命的陷阱是回溯陷阱(Catastrophic Backtracking)。这通常发生在正则表达式中存在重复的、可选的、且相互重叠的模式时。例如, 字符转义也是个老生常谈的问题。 至于性能考量,这在处理大量文本数据时尤为重要。 构建和调试复杂的正则表达式,在我看来,更像是一门艺术,需要耐心和一些技巧。毕竟,一行正则可能就决定了你的数据处理质量。 首先,分而治之是一个非常实用的策略。不要试图一口气写出一个能解决所有问题的巨型正则表达式。你可以先构建匹配核心部分的模式,然后逐步添加修饰符、捕获组、边界条件等。比如,要匹配一个URL,你可以先从协议 利用捕获组( 在线正则表达式测试工具是我的“第二大脑”。像Regex101.com、RegExr.com这样的网站,它们提供了实时的匹配结果、详细的解释、甚至性能分析。你可以把你的正则表达式和测试文本放进去,它会高亮显示匹配的部分,解释每个符号的含义,这对于理解和调试简直是太方便了。我经常在这些工具上反复试验,直到模式完美为止。 在调试方面: 除了我们前面提到的那些基础功能,JavaScript正则表达式在高级文本处理方面,还藏着不少“黑科技”,能让你的文本操作能力上升好几个台阶。 首先是先行断言(Lookahead)和后行断言(Lookbehind)。这俩玩意儿特别有意思,它们允许你在不实际消耗字符的情况下,去检查当前位置的上下文。 再来就是 还有ES2020引入的 最后,Unicode属性转义( 这些高级功能,一旦你掌握了,处理各种复杂的文本解析、数据提取、格式转换任务时,你会发现正则表达式的魅力远不止于此。它们真的能让你的代码更简洁、更强大。 今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~*, +, ?, {n,m})都是贪婪的,它们会尽可能多地匹配字符。比如,你想从/,它会把整个字符串都匹配走。这时,你需要使用非贪婪模式,在量词后面加上?,变成/,它会尽可能少地匹配,直到找到第一个闭合标签。我个人觉得,理解这个“贪婪”和“非贪婪”的区别,是正则表达式进阶的第一步。/(a+)+b/去匹配aaaaaaaaaaaaaaaaaaaaac。正则表达式引擎在尝试匹配时,会进行大量的回溯操作,导致CPU占用飙升,甚至让程序崩溃。避免这种模式,或者简化表达式,是解决之道。说白了,就是不要让你的模式里有太多“选择恐惧症”的重复。., *, +, ?, ^, $, (, ), [, ], {, }, |, \这些都是有特殊含义的元字符。如果你想匹配它们本身,就必须用\进行转义,比如匹配一个点号要用\.。忘记转义,你的正则可能就完全不是你想要的效果了。RegExp对象:如果你的正则表达式是固定的,最好在循环外部定义为字面量或提前创建RegExp实例。每次new RegExp()都会有编译开销。indexOf检查比一个复杂的正则要快得多。test()通常比match()或exec()更高效,因为它不需要构建完整的匹配数组。String.prototype.includes()、indexOf()等原生字符串方法通常比正则表达式更快。正则表达式的强大在于模式匹配,而不是简单的子串查找。如何在实际项目中构建和调试复杂的JavaScript正则表达式?
https?:\/\/开始,然后是域名[\w.-]+,再是路径等等。())和非捕获组((?:))来组织你的模式。捕获组不仅能分组,还能提取匹配的内容,这在替换操作或数据提取时非常有用。而如果你只是想分组但不关心提取内容,使用非捕获组可以稍微提升性能,因为它不会存储匹配结果。ES2018引入的命名捕获组((?)更是大大提升了复杂正则表达式的可读性,你可以通过名字而不是索引来访问捕获到的内容,这在团队协作或后期维护时简直是福音。// 命名捕获组示例
const dateRegex = /(?
console.log大法好:这是最直接的方式。对于match()或exec()的结果,直接打印出来看数组结构、捕获组内容、索引位置等。exec()的迭代特性:如果你的正则表达式带有g标志,并且你使用exec()进行循环匹配,务必理解lastIndex属性。它决定了下一次搜索的起始位置。如果你不小心在循环内部重新创建了RegExp对象,或者没有正确处理lastIndex,就可能导致无限循环或漏掉匹配。除了基本的匹配,JavaScript正则表达式还能实现哪些高级文本处理功能?
(?=...):它会检查当前位置后面是否跟着某个模式,但不把这个模式包含在匹配结果里。比如,你想匹配所有后面跟着“美元”的数字,但不想匹配“美元”本身,就可以用/\d+(?=美元)/。(?!...):跟上面相反,它检查当前位置后面是否没有跟着某个模式。比如,你想匹配所有不是以.js结尾的文件名,就可以用/\w+\.(?!js$)\w+$/。(?<=...)(ES2018+):检查当前位置前面是否跟着某个模式。比如,你想匹配所有前面是“¥”的数字,但不想匹配“¥”本身,可以用/(?<=¥)\d+/。(?(ES2018+):检查当前位置前面是否没有跟着某个模式。// 先行断言示例:匹配 "bar" 但只在 "foo bar" 中
console.log("foo bar baz".match(/bar(?=\sbaz)/)); // null (因为后面是空格baz)
console.log("foo bar baz".match(/bar(?=\sbaz)/)); // null
console.log("foo bar baz".match(/bar(?=\s?baz)/)); // ["bar", index: 4, ...]
// 后行断言示例:匹配数字,但只在前面是 "$" 的情况下
console.log("Price: $100".match(/(?<=\$)\d+/)); // ["100", index: 8, ...]String.prototype.replace()方法的高级用法。除了用一个固定的字符串或函数替换,你还可以在替换字符串中使用一些特殊的变量来引用匹配到的内容:$$:插入一个$字符。$&:插入整个匹配的子串。$:插入匹配的子串之前的部分。$':插入匹配的子串之后的部分。$n 或 $nn:插入第n个捕获组匹配到的内容。$:插入命名捕获组const str = "Hello World";
console.log(str.replace(/(\w+)\s(\w+)/, "$2, $1")); // "World, Hello"
console.log(str.replace(/(\w+)\s(\w+)/, "$& - Matched")); // "Hello World - Matched"
String.prototype.matchAll()。如果你需要获取所有匹配项的完整信息(包括所有捕获组),并且正则表达式带有g标志,matchAll()会返回一个迭代器。这个迭代器每次迭代都会返回一个完整的匹配结果对象,和exec()返回的数组结构类似,但它能让你更方便地处理所有匹配。const text = "cat, dog, bird, cat again";
const regex = /(cat|dog)/g;
for (const match of text.matchAll(regex)) {
console.log(`Found "${match[0]}" at index ${match.index}. Group 1: ${match[1]}`);
}
// Found "cat" at index 0. Group 1: cat
// Found "dog" at index 5. Group 1: dog
// Found "cat" at index 19. Group 1: cat\p{...}和\P{...})也是ES2018之后的一个强大功能,它需要配合u(unicode)标志使用。你可以根据Unicode字符的各种属性来匹配,比如匹配所有字母、所有数字、所有表情符号等等,这对于处理国际化文本非常有用。// 匹配所有Unicode字母 (需要 u 标志)
const unicodeText = "Hello 世界!?";
console.log(unicodeText.match(/\p{L}/gu)); // ["H", "e", "l", "l", "o", "世", "界"]
// 匹配所有Unicode数字 (需要 u 标志)
const numbers = "123 ④⑤⑥";
console.log(numbers.match(/\p{N}/gu)); // ["1", "2", "3", "④", "⑤", "⑥"] Word段前段后间距调整方法
Word段前段后间距调整方法

-
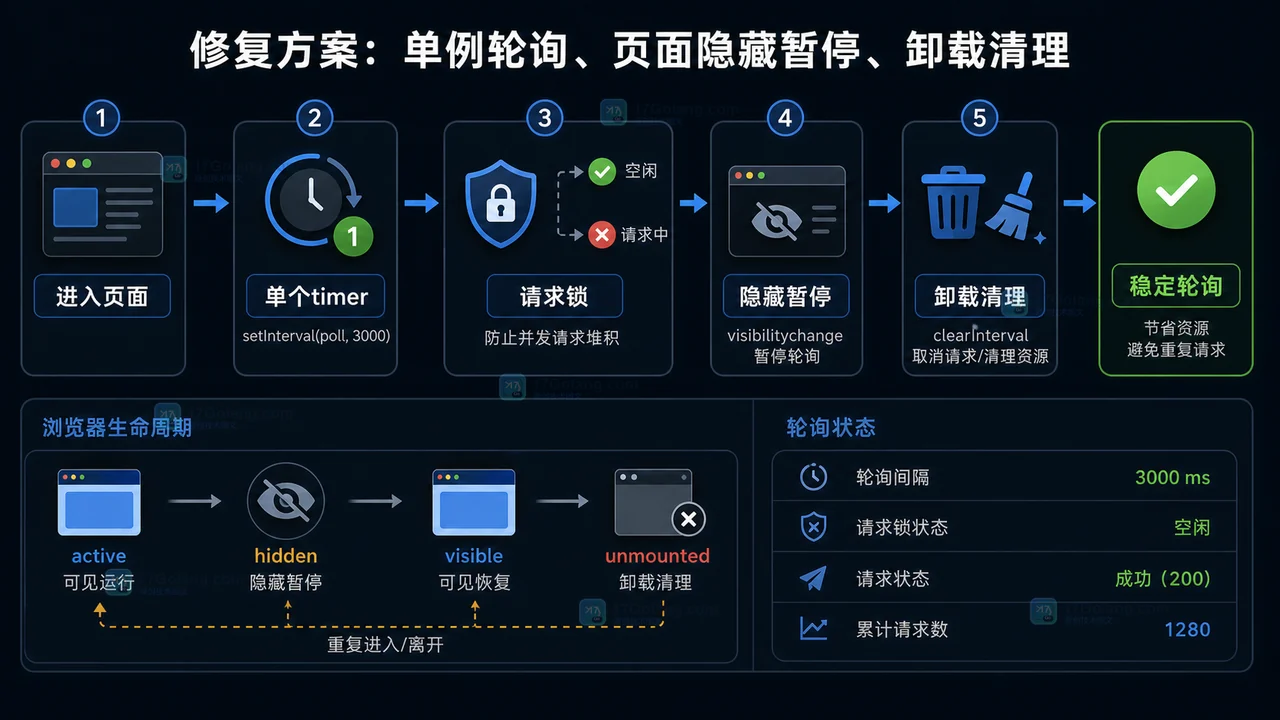
- 文章 · 前端 | 1星期前 | 定时器 · 前端 · 性能排查 · 接口请求 · 轮询 · setInterval · setInterval 页面可见性 clearInterval 前端轮询 请求堆积 定时器清理
- 前端轮询接口越打越多怎么办:从重复定时器到清理机制一步步排查
- 490浏览 收藏
-
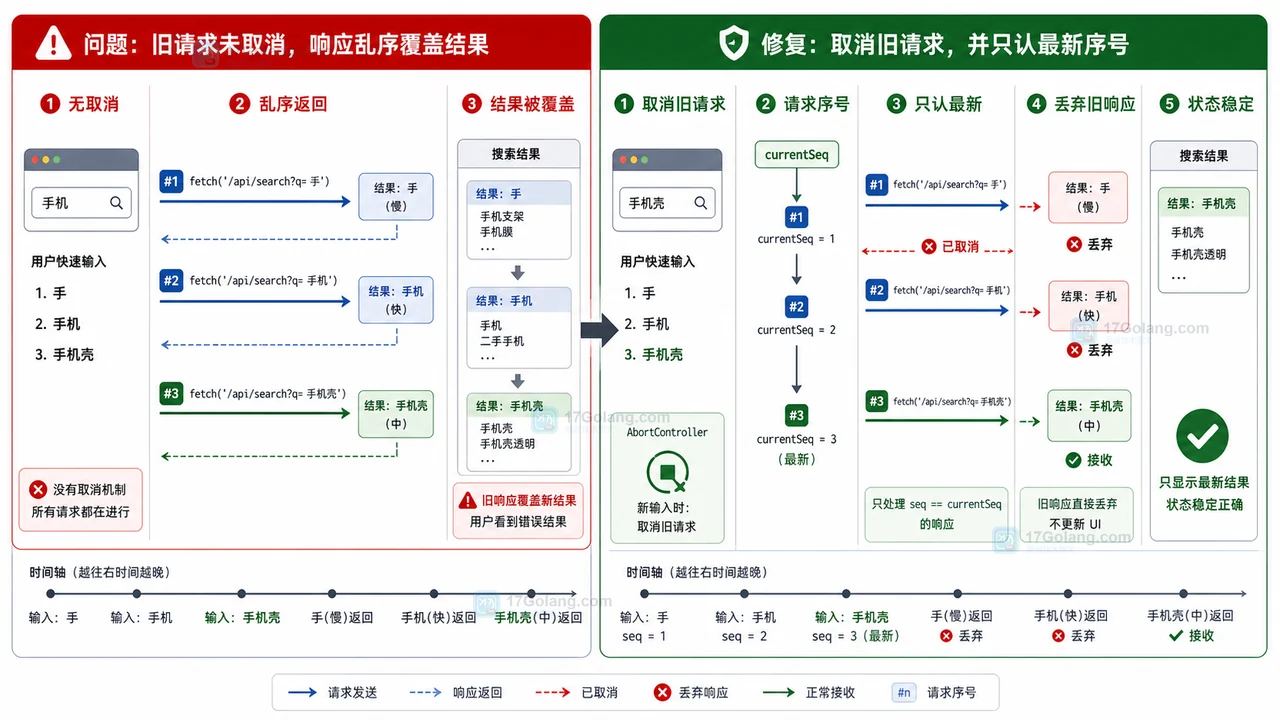
- 文章 · 前端 | 1星期前 | 前端 · 搜索框 · AbortController · 接口请求 · 状态管理 · Fetch AbortController 前端搜索 请求乱序 旧响应覆盖
- 前端搜索结果倒退怎么办:AbortController 取消旧请求和序号兜底
- 295浏览 收藏
-
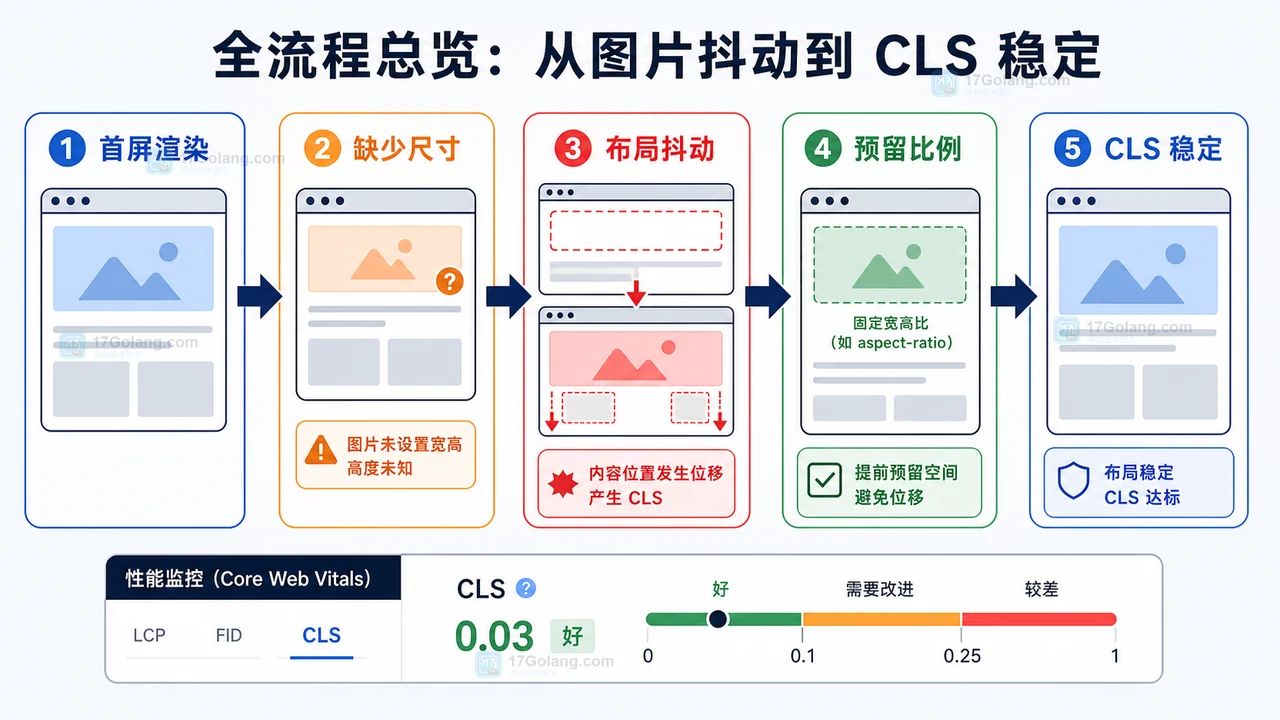
- 文章 · 前端 | 1星期前 | 前端 · 性能优化 · cls · 懒加载 · Core Web Vitals · 前端 图片懒加载 IntersectionObserver CLS 布局稳定
- 前端图片懒加载布局抖动治理完整流程:占位比例、按需加载和 CLS 复查
- 128浏览 收藏
-

- 文章 · 前端 | 1星期前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2250次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2065次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2010次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2223次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2187次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- CSS变量简化按钮悬停效果技巧
- 2026-05-31 501浏览
-
- JavaScript符号类型详解与应用
- 2026-05-31 501浏览
-
- HTML剪贴板复制粘贴怎么用
- 2026-05-26 501浏览
-
- data-*属性详解:HTML数据存储与DOM操作技巧
- 2026-05-25 501浏览


