Golangzip库使用教程:压缩解压实战详解
编程并不是一个机械性的工作,而是需要有思考,有创新的工作,语法是固定的,但解决问题的思路则是依靠人的思维,这就需要我们坚持学习和更新自己的知识。今天golang学习网就整理分享《Golang zip库压缩解压实战教程》,文章讲解的知识点主要包括,如果你对Golang方面的知识点感兴趣,就不要错过golang学习网,在这可以对大家的知识积累有所帮助,助力开发能力的提升。
Golang的archive/zip库通过zip.Writer和zip.Reader实现ZIP文件的压缩与解压,压缩时需为每个文件创建zip.FileHeader并写入相对路径以保留目录结构,解压时需校验路径防止Zip Slip漏洞;处理大文件时依赖流式I/O避免内存溢出,但需注意磁盘I/O、CPU消耗及小文件数量带来的性能瓶颈,可通过调整压缩级别、并发处理和缓冲区优化提升效率;常见错误包括文件I/O失败、ZIP格式无效、路径安全风险等,应全面检查错误、包装错误信息、验证路径合法性并确保资源及时释放。

Golang的archive/zip库是处理ZIP文件压缩与解压的官方标准,它提供了一套直观且功能强大的API,能有效应对文件和目录的打包与解包需求。尽管其设计简洁,但在实际应用中,尤其是在处理复杂目录结构、大文件或需要精细控制时,仍需一些技巧和深入理解才能发挥其最大效能,并避免常见的陷阱。
解决方案
使用archive/zip库进行ZIP文件的压缩与解压,核心在于理解zip.Writer和zip.Reader的运作方式。
文件压缩实践:
压缩文件通常涉及创建一个zip.Writer,然后逐个将文件内容写入到这个writer中,每个文件都需要一个对应的zip.FileHeader来描述其在ZIP包中的路径和元数据。
package main
import (
"archive/zip"
"io"
"os"
"path/filepath"
"fmt"
)
// CompressFiles 压缩一个或多个文件到一个ZIP包
func CompressFiles(outputZipPath string, filesToCompress []string) error {
outFile, err := os.Create(outputZipPath)
if err != nil {
return fmt.Errorf("创建ZIP文件失败: %w", err)
}
defer outFile.Close()
zipWriter := zip.NewWriter(outFile)
defer zipWriter.Close() // 确保在函数结束时关闭zipWriter,否则文件可能损坏
for _, filePath := range filesToCompress {
fileInfo, err := os.Stat(filePath)
if err != nil {
// 文件不存在或无法访问,我们选择跳过而不是中断整个压缩过程
fmt.Printf("警告:无法访问文件 %s,跳过。错误:%v\n", filePath, err)
continue
}
// 创建文件头,指定文件在ZIP包中的路径名
// 这里直接使用原始文件名作为ZIP包内的路径,如果需要保留目录结构,则需要更复杂的逻辑
header, err := zip.FileInfoHeader(fileInfo)
if err != nil {
return fmt.Errorf("创建文件头失败 %s: %w", filePath, err)
}
header.Name = filepath.Base(filePath) // 仅保留文件名,不带路径
header.Method = zip.Deflate // 默认使用Deflate压缩方法
writer, err := zipWriter.CreateHeader(header)
if err != nil {
return fmt.Errorf("在ZIP中创建文件 %s 失败: %w", header.Name, err)
}
// 如果是目录,我们通常不直接写入内容,而是在递归压缩时处理
if fileInfo.IsDir() {
// 在这里,如果filePath是目录,我们只是创建了一个空目录项。
// 真正的目录内容压缩需要递归遍历。
continue
}
// 打开源文件并将其内容拷贝到ZIP Writer中
srcFile, err := os.Open(filePath)
if err != nil {
return fmt.Errorf("打开源文件 %s 失败: %w", filePath, err)
}
defer srcFile.Close() // 确保源文件在使用后关闭
_, err = io.Copy(writer, srcFile)
if err != nil {
return fmt.Errorf("拷贝文件内容 %s 失败: %w", filePath, err)
}
}
return nil
}
// CompressDirectory 递归压缩一个目录及其内容到ZIP包
func CompressDirectory(outputZipPath, sourceDirPath string) error {
outFile, err := os.Create(outputZipPath)
if err != nil {
return fmt.Errorf("创建ZIP文件失败: %w", err)
}
defer outFile.Close()
zipWriter := zip.NewWriter(outFile)
defer zipWriter.Close()
// 使用filepath.Walk遍历目录
return filepath.Walk(sourceDirPath, func(path string, info os.FileInfo, err error) error {
if err != nil {
return fmt.Errorf("遍历文件 %s 失败: %w", path, err)
}
// 计算文件在ZIP包中的相对路径
// sourceDirPath 可能是 "my_folder",path 可能是 "my_folder/sub/file.txt"
// 相对路径就是 "sub/file.txt"
relPath, err := filepath.Rel(sourceDirPath, path)
if err != nil {
return fmt.Errorf("计算相对路径失败 %s: %w", path, err)
}
if relPath == "." { // 根目录本身不需要添加到ZIP中
return nil
}
header, err := zip.FileInfoHeader(info)
if err != nil {
return fmt.Errorf("创建文件头失败 %s: %w", path, err)
}
header.Name = relPath // 使用相对路径作为ZIP包内的名称
header.Method = zip.Deflate
if info.IsDir() {
header.Name += "/" // 确保目录以斜杠结尾
}
writer, err := zipWriter.CreateHeader(header)
if err != nil {
return fmt.Errorf("在ZIP中创建项 %s 失败: %w", header.Name, err)
}
if !info.IsDir() {
srcFile, err := os.Open(path)
if err != nil {
return fmt.Errorf("打开源文件 %s 失败: %w", path, err)
}
defer srcFile.Close()
_, err = io.Copy(writer, srcFile)
if err != nil {
return fmt.Errorf("拷贝文件内容 %s 失败: %w", path, err)
}
}
return nil
})
}文件解压实践:
解压过程是打开一个ZIP文件,然后遍历其内部的zip.File列表,逐个将文件内容解压到目标路径。
// DecompressZip 解压ZIP文件到指定目录
func DecompressZip(zipPath, destDirPath string) error {
readCloser, err := zip.OpenReader(zipPath)
if err != nil {
return fmt.Errorf("打开ZIP文件失败: %w", err)
}
defer readCloser.Close()
// 确保目标目录存在
if err := os.MkdirAll(destDirPath, 0755); err != nil {
return fmt.Errorf("创建目标目录失败 %s: %w", destDirPath, err)
}
for _, file := range readCloser.File {
// 构建目标文件路径,确保路径安全,防止zip slip漏洞
destPath := filepath.Join(destDirPath, file.Name)
if !filepath.HasPrefix(destPath, filepath.Clean(destDirPath)+string(os.PathSeparator)) {
return fmt.Errorf("非法文件路径 %s", file.Name)
}
if file.FileInfo().IsDir() {
// 创建目录
if err := os.MkdirAll(destPath, file.Mode()); err != nil {
return fmt.Errorf("创建目录 %s 失败: %w", destPath, err)
}
continue
}
// 确保文件所在的目录存在
if err := os.MkdirAll(filepath.Dir(destPath), 0755); err != nil {
return fmt.Errorf("创建文件父目录 %s 失败: %w", filepath.Dir(destPath), err)
}
outFile, err := os.OpenFile(destPath, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, file.Mode())
if err != nil {
return fmt.Errorf("创建目标文件 %s 失败: %w", destPath, err)
}
defer outFile.Close() // 每次循环内部的文件都需要defer关闭
rc, err := file.Open()
if err != nil {
return fmt.Errorf("打开ZIP内部文件 %s 失败: %w", file.Name, err)
}
defer rc.Close() // 每次循环内部的reader都需要defer关闭
_, err = io.Copy(outFile, rc)
if err != nil {
return fmt.Errorf("解压文件内容 %s 失败: %w", file.Name, err)
}
}
return nil
}如何在ZIP文件中保留原始目录结构,避免文件扁平化?
这确实是archive/zip初学者常常遇到的一个“坑”。我个人在处理这类问题时,总会先考虑文件在ZIP包中的“逻辑路径”应该是什么。zip.FileHeader.Name字段是关键,它决定了文件在ZIP包内的相对路径。如果只是简单地将filepath.Base(filePath)赋值给header.Name,那么所有文件都会被“扁平化”到ZIP包的根目录,丢失了它们原本的层级关系。
要保留原始目录结构,核心思想是计算每个文件相对于你想要压缩的“根目录”的相对路径。例如,如果你想压缩project/src/main.go,并且希望ZIP包里是src/main.go,那么project就是你的“根目录”。filepath.Walk函数在这里显得尤为重要,因为它能递归地遍历指定目录下的所有文件和子目录。在filepath.Walk的回调函数中,我们拿到的是文件的完整路径(path参数),我们需要将其转换为相对于压缩源目录的路径。
具体来说,可以使用filepath.Rel(sourceDirPath, path)来获取相对路径。这个相对路径就是我们应该赋给zip.FileHeader.Name的值。此外,对于目录本身,为了确保它们在ZIP包中被正确识别为目录,通常会在其header.Name后加上一个斜杠(例如my_dir/)。这虽然不是强制性的,但能提高兼容性,并明确表示这是一个目录项。我发现,这种方式能非常优雅地解决目录结构保留的问题,比手动拼接路径要健壮得多。
处理大型ZIP文件时,archive/zip的性能表现如何?有哪些优化策略?
archive/zip库在处理中小型文件时表现出色,其性能通常不是瓶颈。然而,当面对GB级别甚至更大的ZIP文件时,或者需要处理成千上万个小文件时,性能和内存消耗就成了需要关注的问题。
首先,archive/zip是基于io.Reader和io.Writer接口设计的,这意味着它天生支持流式处理。在压缩时,我们不是一次性将整个文件读入内存再写入ZIP,而是通过io.Copy逐块读取源文件并写入ZIP。解压时也类似,从ZIP内部文件读取内容并逐块写入目标文件。这种流式处理是其高效的关键,它避免了内存溢出,即使是处理远超可用内存的大文件也能胜任。
然而,性能瓶颈可能出现在几个方面:
- 磁盘I/O: 无论如何优化,磁盘的读写速度始终是最大的限制因素。特别是当ZIP文件位于慢速存储介质上,或者同时有大量并发I/O操作时,性能会显著下降。
- CPU消耗: 压缩算法(尤其是Deflate)是计算密集型的。对于非常大的文件,CPU会长时间处于高负载状态。
archive/zip默认使用的是Deflate算法,其压缩级别可以通过zip.Writer.SetCompressionLevel进行调整。级别越高,压缩比越高,但CPU消耗也越大。在某些场景下,牺牲一点压缩比来换取更快的速度是明智的选择。 - 小文件数量: 如果ZIP包中包含数百万个小文件,即使每个文件本身不大,创建和处理每个文件的
zip.FileHeader、打开/关闭文件句柄、以及io.Copy的调用开销累积起来也会非常显著。这种情况下,可以考虑将多个小文件打包成一个更大的临时文件再进行压缩,或者在应用层面进行批处理。
优化策略:
- 调整压缩级别: 使用
zipWriter.SetCompressionLevel(zip.BestSpeed)可以显著加快压缩速度,尽管文件会稍大一些。如果对压缩比要求不高,这是一个简单有效的优化。 - 并发处理: 对于压缩多个独立的目录或文件集合,可以考虑使用goroutine并发地创建多个ZIP文件(如果业务逻辑允许),或者在解压时并发处理不同的ZIP文件。不过,对于单个ZIP文件的内部文件,
archive/zip库本身并没有提供原生的并发压缩/解压接口,因为ZIP格式本身是顺序写入的。 - 缓冲区优化:
io.Copy内部会使用一个默认的缓冲区。在某些特定I/O场景下,通过io.CopyBuffer(dst, src, make([]byte, bufferSize))手动指定一个更大的缓冲区(例如64KB或1MB),可能会对性能有所提升,但这需要根据实际测试来确定最佳值,并非总是有效。 - 避免不必要的I/O: 在解压时,如果不需要解压所有文件,可以根据
file.Name进行过滤,只解压需要的文件,减少不必要的磁盘写入。
坦白说,对于极致的性能需求,有时可能需要考虑更底层的库或者不同的压缩格式(如tar.gz),但对于绝大多数通用场景,archive/zip已经提供了非常好的平衡。
使用archive/zip库时,常见的错误类型有哪些?如何进行有效排查与处理?
在使用archive/zip库时,我遇到过不少错误,有些是Go语言I/O操作的共性问题,有些则与ZIP格式的特性有关。有效的错误排查和处理是确保程序健壮性的关键。
常见的错误类型:
- 文件I/O错误:
os.Create或os.Open失败:通常是文件不存在、路径错误、权限不足或磁盘空间不足导致。io.Copy失败:在读写文件内容时发生,可能是源文件损坏、目标磁盘已满、或网络文件系统(NFS)问题。os.MkdirAll失败:创建目录时权限不足或路径不合法。
- ZIP格式相关错误:
zip.OpenReader失败:尝试打开的不是一个有效的ZIP文件,或者文件已损坏。错误信息可能是“zip: not a valid zip file”或“zip: read error”。zip.Writer.Close()失败:在压缩结束时,zip.Writer.Close()会写入ZIP文件的中央目录(central directory)和文件尾。如果这个过程失败,通常是底层io.Writer(即输出文件)出现问题,例如磁盘已满或文件句柄已失效。这是一个非常容易被忽视但极其重要的错误检查点。zip.File.Open()失败:解压时,ZIP包内部的某个文件可能已损坏或无法正确读取。
- 路径安全问题(Zip Slip):
- 在解压时,如果ZIP包内的文件名是
../../../../etc/passwd这样的相对路径,并且没有进行路径验证,攻击者可能利用此漏洞将文件解压到任意位置,覆盖系统文件。这是非常严重的安全问题。
- 在解压时,如果ZIP包内的文件名是
有效排查与处理:
- 全面错误检查: Go语言的错误处理模式是“显式检查”,这意味着每个可能返回
error的函数调用都应该被检查。尤其是在defer语句中,如果defer的函数(如zipWriter.Close())返回错误,也应该被捕获和处理。我个人倾向于使用一个具名返回值来捕获defer中的错误,或者在defer内部打印日志。 - 详细的错误信息: 在返回错误时,使用
fmt.Errorf("描述性信息: %w", err)来包装原始错误。这允许调用者通过errors.Is或errors.As来检查错误的具体类型,同时保留了完整的错误链,方便调试。 - 路径验证: 在解压时,务必对解压目标路径进行严格验证,以防范Zip Slip漏洞。我的
DecompressZip函数中已经加入了filepath.HasPrefix的检查,确保解压路径不会跳出预设的目标目录。这是最基本的安全措施。 - 日志记录: 在关键操作失败时记录详细的日志,包括错误类型、文件名、路径等上下文信息。这对于线上环境的问题排查至关重要。
- 资源清理: 确保所有打开的文件句柄、
zip.Writer和zip.Reader都在适当的时候被defer Close(),防止资源泄露。即使在错误发生时,defer也能保证资源被释放。 - 重试机制: 对于一些瞬时性错误(如网络文件系统的临时故障),可以考虑实现简单的重试逻辑,但这需要谨慎评估。
总的来说,处理archive/zip的错误,其实是Go语言通用错误处理原则的体现:细致、明确、安全优先。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于Golang的相关知识,也可关注golang学习网公众号。
 HTML5ReferrerPolicy详解:如何控制Referrer信息
HTML5ReferrerPolicy详解:如何控制Referrer信息
- 上一篇
- HTML5ReferrerPolicy详解:如何控制Referrer信息

- 下一篇
- 夸克日本大片免费观看入口推荐
-
- Golang · Go教程 | 8小时前 | golang
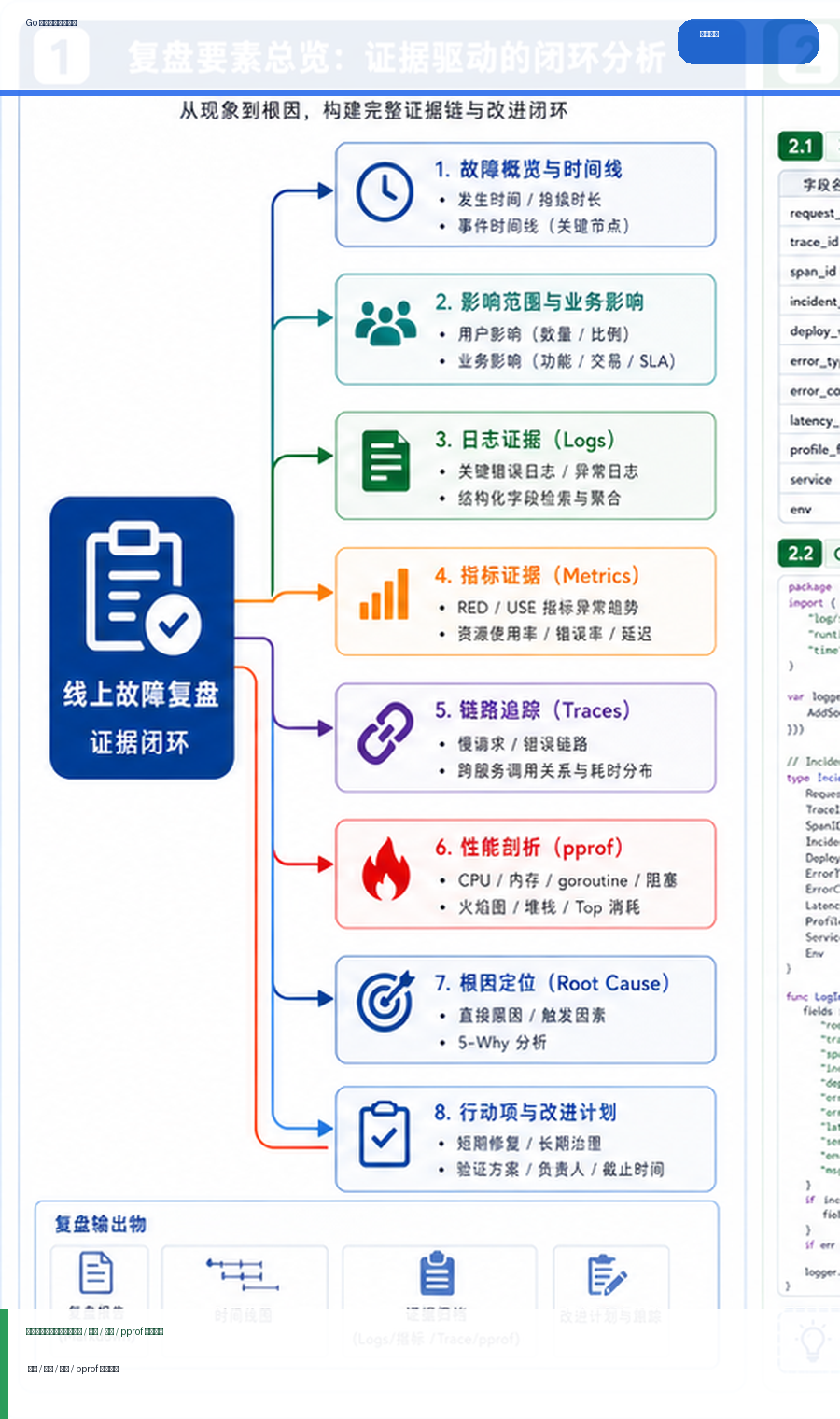
- Go 线上故障复盘模板:日志、指标、链路追踪与 pprof 证据闭环
- 710浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
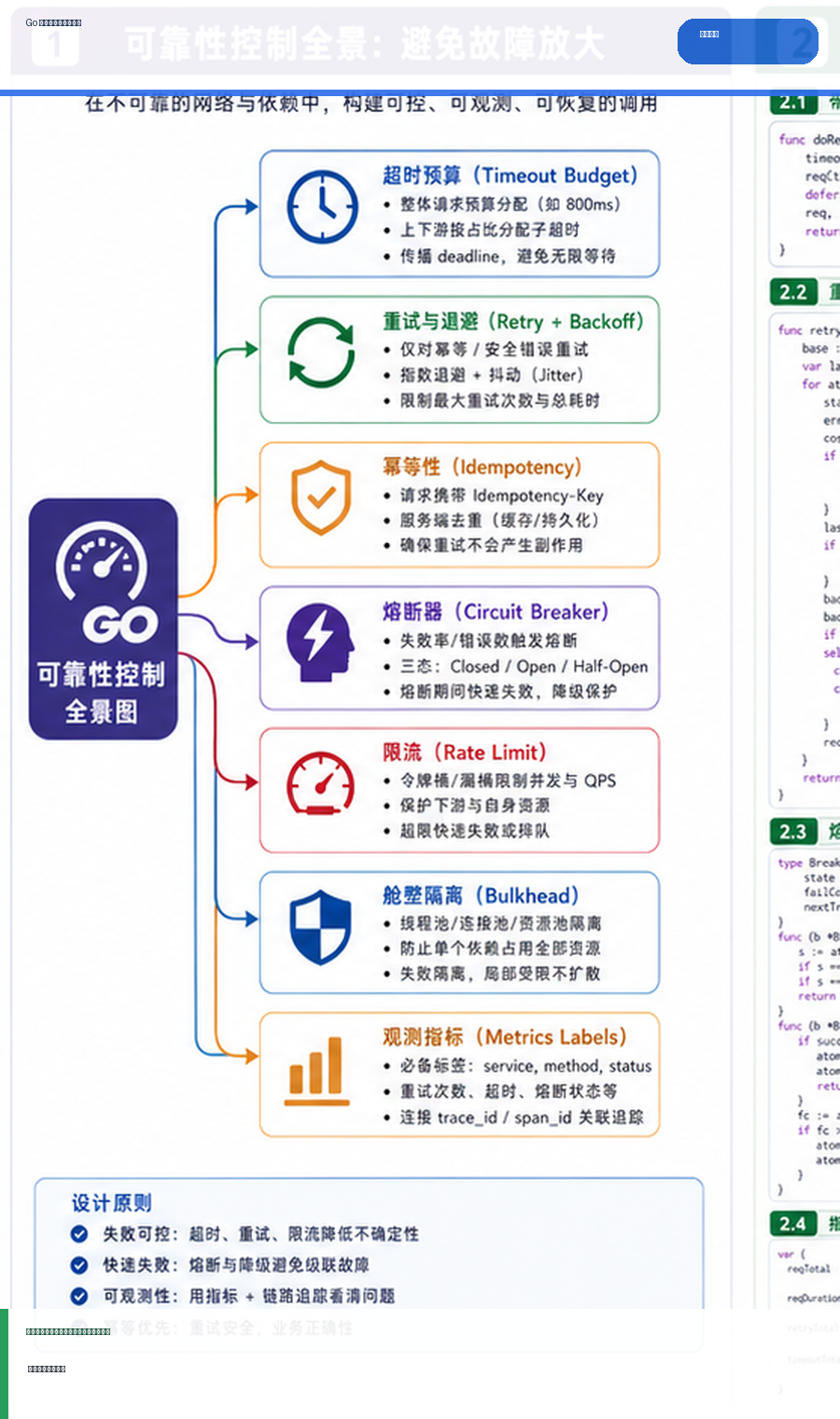
- Go 微服务超时、重试与熔断观测:避免故障放大的实践
- 687浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
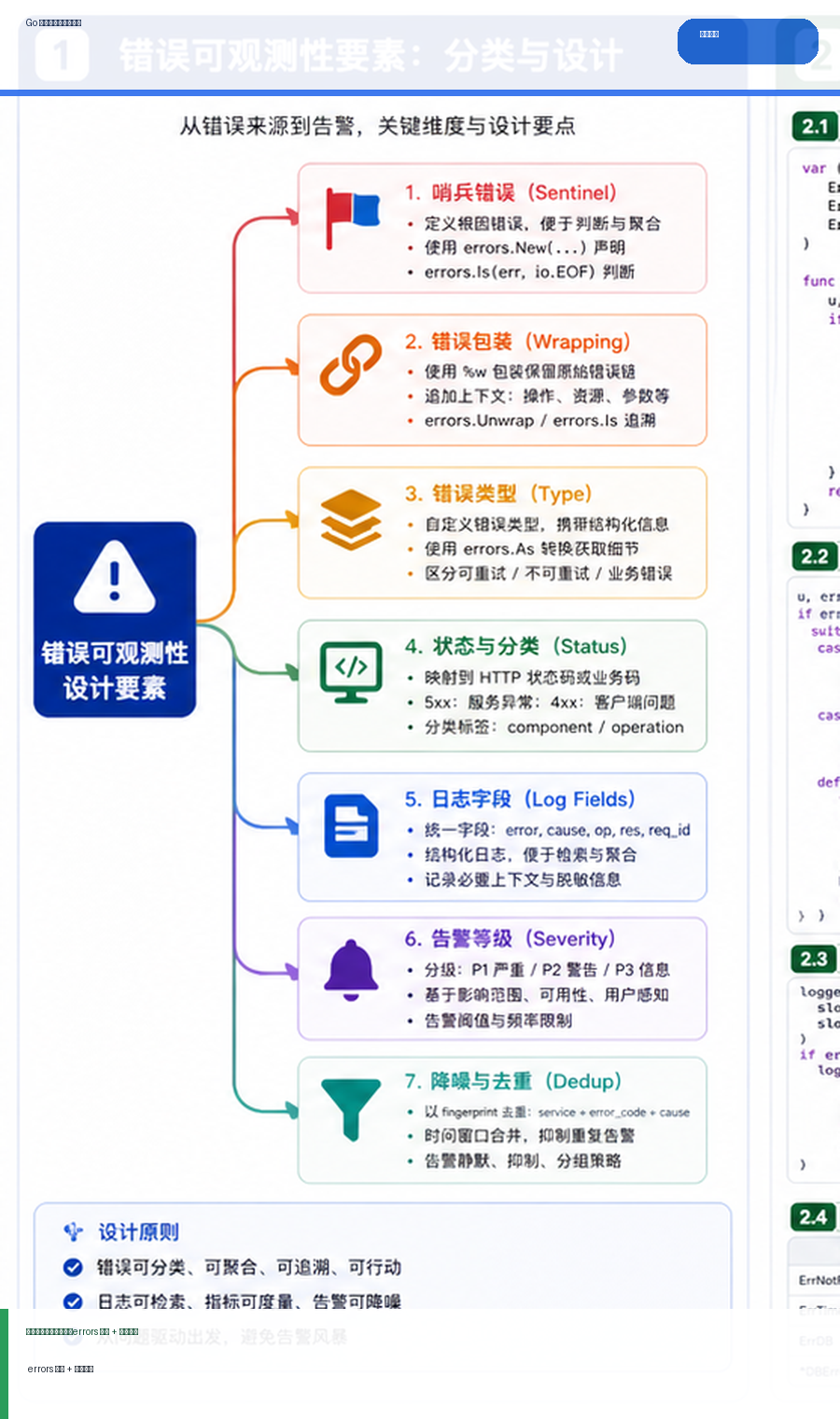
- Go 错误处理与告警设计:errors 包装、日志字段与告警降噪
- 664浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
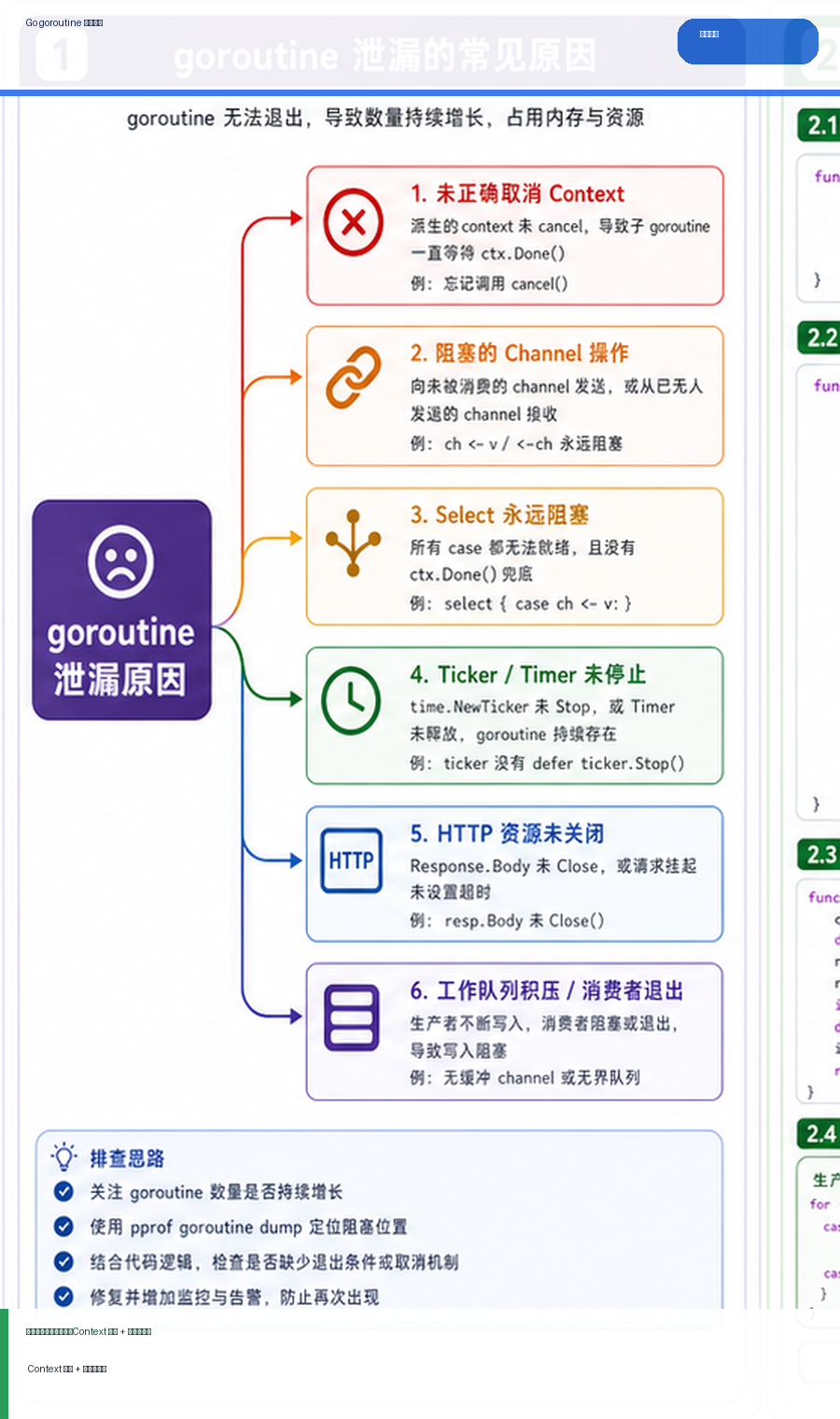
- Go goroutine 泄漏排查:Context 取消、阻塞栈与泄漏定位
- 641浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
- Go HTTP 健康检查与优雅关闭:readiness、liveness 和 Shutdown 实战
- 618浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
- Go runtime/metrics 与 expvar:低成本暴露运行时状态
- 595浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
- Go pprof 在线诊断:CPU、内存与 goroutine 问题怎么定位
- 572浏览 收藏
-
- Golang · Go教程 | 8小时前 | golang
- Go OpenTelemetry 链路追踪:Context 传播、Span 设计与慢调用定位
- 549浏览 收藏
-
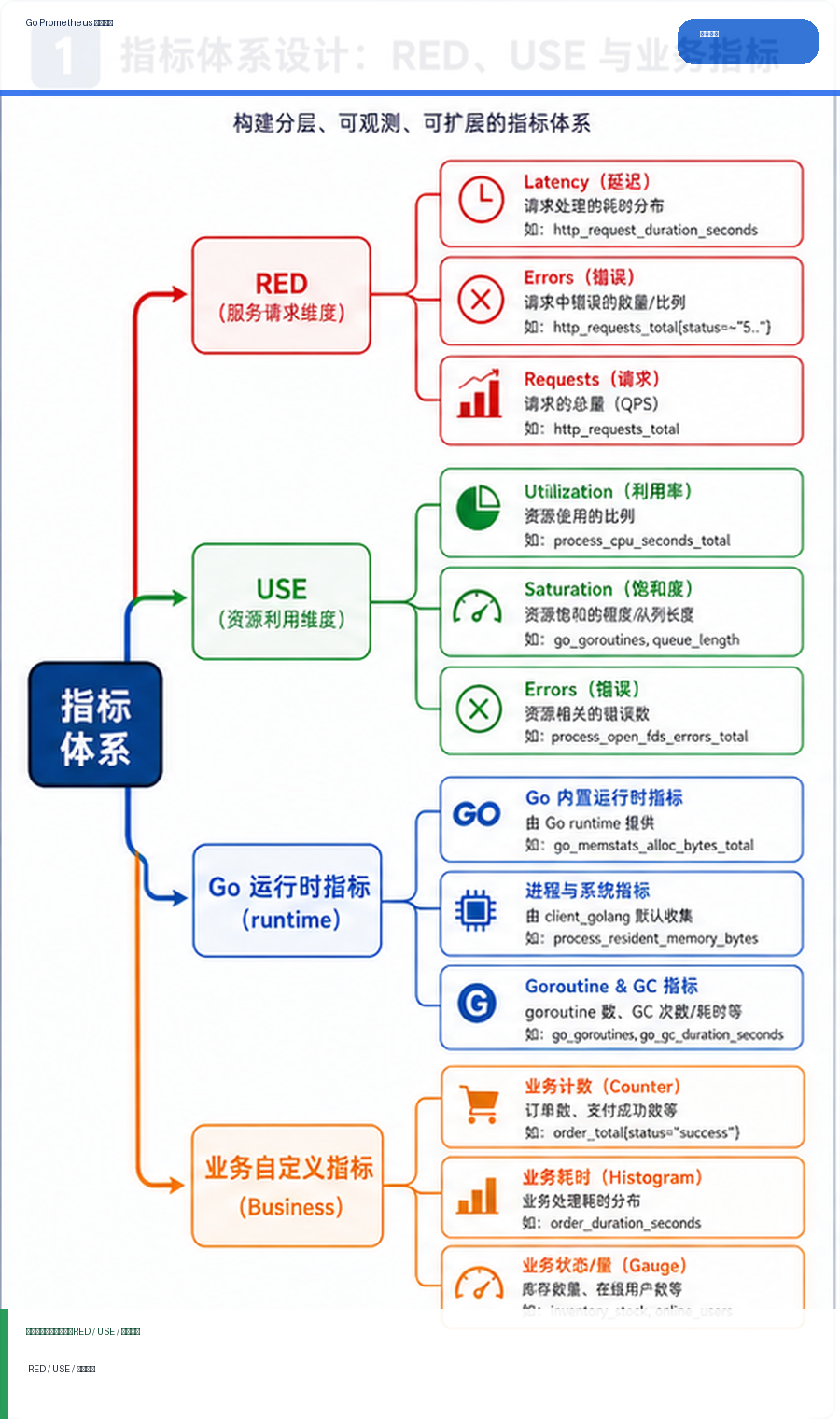
- Golang · Go教程 | 8小时前 | golang
- Go Prometheus 指标设计:RED、USE 与自定义业务指标落地
- 526浏览 收藏
-
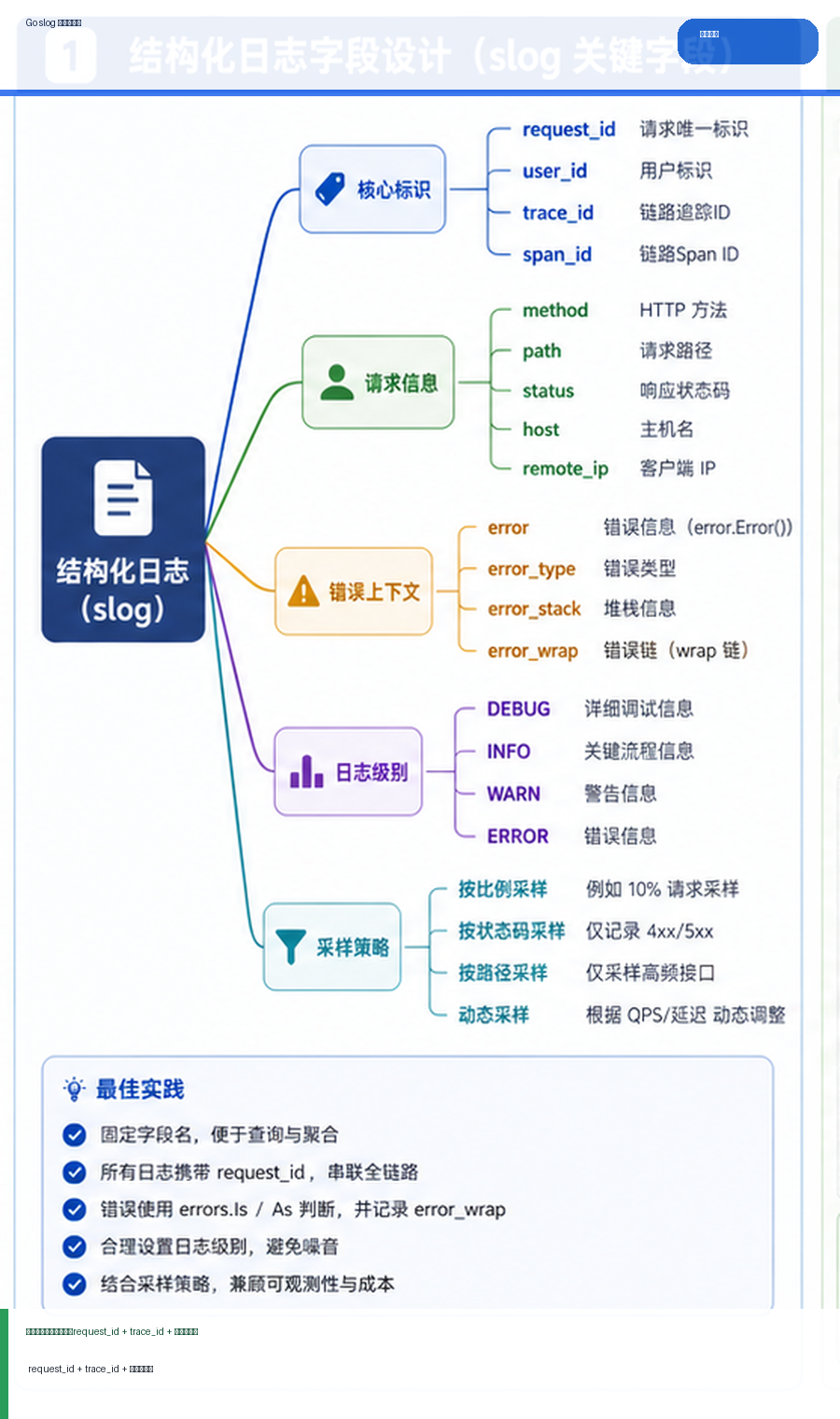
- Golang · Go教程 | 8小时前 | golang
- Go 结构化日志实践:slog、request_id 与错误上下文怎么设计
- 503浏览 收藏
-
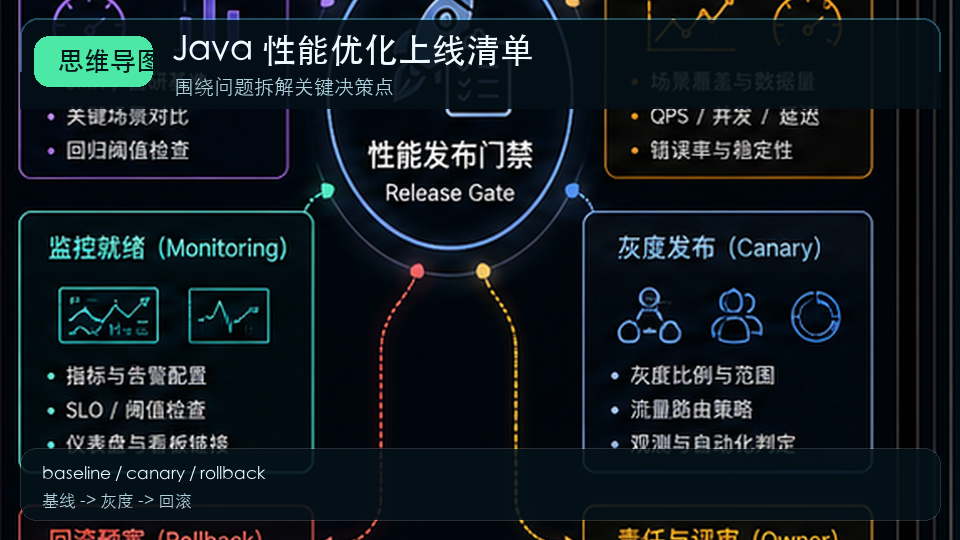
- Golang · Go教程 | 1天前 |
- Java 性能优化上线清单:从定位、改造到灰度发布
- 860浏览 收藏
-

- Golang · Go教程 | 1天前 |
- Spring Boot 压测验证:Gatling、JMeter 与性能回归门禁
- 843浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7870次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8293次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8104次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10033次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8871次使用
-
- Java 性能优化上线清单:从定位、改造到灰度发布
- 2026-06-11 860浏览
-
- Spring Boot 压测验证:Gatling、JMeter 与性能回归门禁
- 2026-06-11 843浏览
-
- Java NMT 非堆内存排查:Direct Buffer、线程栈与 Metaspace 分析
- 2026-06-11 826浏览
-
- Spring Boot 容器内存优化:JVM 堆、非堆与 MaxRAMPercentage
- 2026-06-11 809浏览
-
- Tomcat 连接与线程参数调优:maxThreads、acceptCount 与 KeepAlive
- 2026-06-11 792浏览


