Golang原子操作解析与实战教程
本文深入解析了Golang中`sync/atomic`库的原子操作,旨在解决并发环境下共享变量一致性问题,提升程序性能。`sync/atomic`提供了诸如`Add`、`Load`、`Store`和`CompareAndSwap`等核心操作,适用于计数器、状态标志、配置更新等多种场景。相较于传统的互斥锁`sync.Mutex`,原子操作在性能上更具优势,开销更小,但其应用也存在局限性,仅限于基本类型和指针操作。对于复杂数据结构,开发者可结合`atomic.Value`实现原子更新,同时需注意复合操作的非原子性以及内存对齐等潜在问题。本文通过实战案例,详细阐述了`sync/atomic`在并发编程中的应用技巧与注意事项,助力开发者编写出更高效、更健壮的Golang并发程序。
答案:sync/atomic提供原子操作解决并发下共享变量一致性问题,核心操作包括Add、Load、Store和CompareAndSwap,适用于计数器、状态标志、配置更新等场景,相比Mutex性能更高、开销更小,但仅限于基本类型和指针操作,复杂结构需结合atomic.Value使用,且需注意复合操作非原子、内存对齐等问题。

Golang的sync/atomic库,说白了,就是给那些在并发环境下需要安全更新的共享变量,提供了一套轻量级的“原子”操作。它不是万能药,但对于一些特定的,比如计数器、标志位或者单次数据更新的场景,它能比传统的互斥锁(sync.Mutex)提供更高的性能和更精细的控制。我个人觉得,理解它,就像是理解了并发编程里那些微妙的“一致性”和“可见性”问题,它在某些场景下,真的是一把利器,能让你的代码跑得更快,也更健壮。
解决方案
在并发编程中,当我们有多个goroutine同时读写同一个变量时,如果不加保护,就会出现数据竞态(race condition),导致结果不可预测。sync/atomic库提供了一系列原子操作,这些操作在CPU指令层面保证了其执行的不可中断性,即要么完全执行成功,要么完全不执行,中间状态不会被其他goroutine观察到。这避免了使用锁带来的上下文切换开销,对于简单的数值操作或指针交换,性能优势非常明显。它主要解决了共享变量的读写一致性问题,尤其是在高并发的计数、状态标记和单值更新等场景下,它比sync.Mutex更高效。
Golang sync/atomic库的核心操作有哪些,它们各自的应用场景是什么?
sync/atomic库的核心在于提供了一系列针对基本数据类型(如int32, int64, uint32, uint64)以及unsafe.Pointer的原子操作。这些操作包括:
AddInt32/AddInt64: 原子地增加一个值。- 应用场景: 最典型的就是并发计数器。比如一个网站的访问量统计,每次请求到来就对计数器加一。如果用普通的
++操作,在并发环境下就会出现统计不准的情况,因为++实际上是“读取-修改-写入”三个步骤,这期间可能被其他goroutine打断。import "sync/atomic"
var requestCount int64
func handleRequest() { // 处理请求... atomic.AddInt64(&requestCount, 1) // 原子地增加计数 }
- 应用场景: 最典型的就是并发计数器。比如一个网站的访问量统计,每次请求到来就对计数器加一。如果用普通的
LoadInt32/LoadInt64/LoadPointer: 原子地读取一个值。- 应用场景: 确保读取到的值是最新的,而不是某个旧的缓存值。这在并发环境下,尤其是涉及到内存可见性问题时非常重要。比如,你有一个配置变量,它可能在运行时被更新,你希望所有读取操作都能看到最新的配置。
import "sync/atomic"
var configVersion int32 var currentConfig atomic.Value // 存储配置结构体
func getConfig() interface{} { return currentConfig.Load() // 原子地加载最新的配置 }
func updateConfig(newConfig interface{}) { currentConfig.Store(newConfig) // 原子地存储新配置 atomic.AddInt32(&configVersion, 1) }
这里顺便提到了`atomic.Value`,它能原子地存储和加载任意类型的值,非常适合那些需要频繁读取但更新不那么频繁的配置或数据结构。
- 应用场景: 确保读取到的值是最新的,而不是某个旧的缓存值。这在并发环境下,尤其是涉及到内存可见性问题时非常重要。比如,你有一个配置变量,它可能在运行时被更新,你希望所有读取操作都能看到最新的配置。
StoreInt32/StoreInt64/StorePointer: 原子地存储一个值。- 应用场景: 更新一个共享变量,确保更新过程是原子的。比如一个状态标志位,从“未处理”变为“已处理”。
import "sync/atomic"
var isReady int32 // 0表示未就绪,1表示已就绪
func setReady() { atomic.StoreInt32(&isReady, 1) // 原子地设置状态 }
- 应用场景: 更新一个共享变量,确保更新过程是原子的。比如一个状态标志位,从“未处理”变为“已处理”。
CompareAndSwapInt32/CompareAndSwapInt64/CompareAndSwapPointer(CAS操作): 这是原子操作的基石,也是最强大的一个。它尝试将一个变量的值从“旧值”更新为“新值”,但只有当变量当前的值确实是“旧值”时才执行更新。- 应用场景: 实现无锁数据结构、单例模式、乐观锁等。例如,你希望某个操作只执行一次,或者在某个条件满足时才更新一个值。
import "sync/atomic"
var initialized uint32 // 0表示未初始化,1表示已初始化
func initializeOnce() { if atomic.CompareAndSwapUint32(&initialized, 0, 1) { // 只有当initialized为0时,才将其设置为1,并执行初始化逻辑 // 这段代码块只会执行一次 println("Performing one-time initialization...") // 实际的初始化代码... } }
CAS操作的强大之处在于它提供了一种“乐观”的并发控制策略:先尝试,如果发现有人抢先了,那就再试一次或者放弃。这在很多场景下比悲观锁(Mutex)效率更高。
- 应用场景: 实现无锁数据结构、单例模式、乐观锁等。例如,你希望某个操作只执行一次,或者在某个条件满足时才更新一个值。
为什么在Go并发编程中需要使用sync/atomic而非简单的锁(Mutex)?
这是一个非常好的问题,也是很多初学者容易混淆的地方。我的看法是,sync/atomic和sync.Mutex并非互相替代,而是针对不同场景的互补工具。
sync.Mutex是一种悲观锁,它在访问共享资源前先获取锁,确保在同一时间只有一个goroutine能够访问该资源。这就像给共享资源加了一把大锁,每次进出都要钥匙。它的优点是简单粗暴,能处理任意复杂的共享数据结构。但缺点也很明显:
- 开销大: 获取和释放锁涉及到系统调用(或更轻量级的futex),可能导致goroutine的上下文切换,这本身就是有性能开销的。在高并发、锁竞争激烈的情况下,这种开销会变得非常显著。
- 死锁风险: 不当的锁使用,比如锁的嵌套,很容易导致死锁,让程序彻底卡住。
- 粒度粗: 锁通常保护的是一个代码块或一个数据结构,即使你只是想对一个简单的整数进行加一操作,也需要整个代码块加锁,这可能限制了并发度。
而sync/atomic提供的是CPU指令级别的原子操作,它通常通过特殊的CPU指令(如x86的LOCK前缀指令)来保证操作的原子性。它的优势在于:
- 性能极高: 对于简单的操作(如整数加减、读写、CAS),
atomic操作通常比互斥锁快得多,因为它避免了上下文切换,直接在CPU层面完成。这对于那些对性能有极致要求的计数器或标志位更新尤其重要。 - 无锁/非阻塞: 从概念上讲,原子操作是一种无锁(lock-free)或非阻塞(non-blocking)的并发原语。它不会让goroutine阻塞等待,而是通过重试或直接完成操作。
- 细粒度控制:
atomic操作直接作用于单个变量,提供了非常细粒度的并发控制,避免了不必要的锁范围扩大。
当然,sync/atomic也有其局限性:
- 适用范围窄: 它只能用于简单的数值类型或指针操作。对于复杂的数据结构(如
map、slice、自定义结构体),你无法直接用atomic来保证其所有操作的原子性,这时你可能就需要sync.Mutex或者更高级的并发原语。 - 编程复杂度: 尤其是在使用CAS操作构建无锁数据结构时,逻辑会比使用锁复杂得多,需要对内存模型和并发原理有更深入的理解。
总结来说,如果你的并发操作只是针对单个、简单的值进行读、写、加、减或比较交换,并且对性能有较高要求,那么sync/atomic是更好的选择。如果你的操作涉及多个变量的协同更新,或者复杂的数据结构,那么sync.Mutex(或sync.RWMutex)会是更安全、更易于维护的选择。在我看来,这两种工具的选择,更多是基于“最小化开销”和“最大化并发度”的权衡。
在实际项目中,如何安全有效地利用sync/atomic处理复杂数据结构或计数器?
处理复杂数据结构时,sync/atomic并非直接作用于整个结构体,而是其内部的某个字段,或者通过atomic.Value来间接管理。而对于计数器,它就是sync/atomic最典型的应用场景,但也有一些值得注意的地方。
1. 高性能计数器:
对于简单的计数,atomic.AddInt64是首选。但如果计数器需要频繁重置或有更复杂的逻辑(比如带阈值的计数),我们可能需要一个封装。
import (
"sync/atomic"
"time"
)
// HighPerformanceCounter 是一个高性能的并发计数器
type HighPerformanceCounter struct {
value int64
}
// Increment 原子地增加计数
func (c *HighPerformanceCounter) Increment() {
atomic.AddInt64(&c.value, 1)
}
// Get 获取当前计数
func (c *HighPerformanceCounter) Get() int64 {
return atomic.LoadInt64(&c.value)
}
// Reset 重置计数
func (c *HighPerformanceCounter) Reset() {
// 使用CAS来重置,确保在并发重置时只有一个成功
for {
oldVal := atomic.LoadInt64(&c.value)
if atomic.CompareAndSwapInt64(&c.value, oldVal, 0) {
break
}
// 如果CAS失败,说明有其他goroutine修改了值,重试
time.Sleep(1 * time.Microsecond) // 稍微等待,避免忙循环
}
}
// 示例用法
// var myCounter HighPerformanceCounter
// myCounter.Increment()
// count := myCounter.Get()
// myCounter.Reset()这里,Reset方法就用到了CAS,它避免了直接StoreInt64(0)可能带来的竞态问题(如果你想基于某个旧值来重置)。虽然StoreInt64(0)本身是原子的,但如果你的重置逻辑依赖于“只有在某个特定值时才重置”,CAS就不可或缺。
2. 复杂数据结构的原子更新:atomic.Value
对于map、slice或自定义结构体这类复杂数据,sync/atomic库提供了一个atomic.Value类型。它允许你原子地存储和加载任意类型的interface{}值。关键在于,你存储进去的值应该是不可变的。每次更新,你都应该创建一个新的、修改后的数据结构实例,然后用Store方法替换掉旧的。
import (
"fmt"
"sync/atomic"
"time"
)
// Config 是一个示例配置结构体
type Config struct {
Endpoint string
Timeout time.Duration
// 更多配置项...
}
var globalConfig atomic.Value // 存储 *Config 类型
func init() {
// 初始化时存储一个默认配置
globalConfig.Store(&Config{
Endpoint: "default.api.com",
Timeout: 5 * time.Second,
})
}
// GetCurrentConfig 获取当前配置
func GetCurrentConfig() *Config {
return globalConfig.Load().(*Config) // 原子地加载并类型断言
}
// UpdateGlobalConfig 更新全局配置
func UpdateGlobalConfig(newEndpoint string, newTimeout time.Duration) {
// 创建一个新的Config实例,因为Config是不可变的
newConfig := &Config{
Endpoint: newEndpoint,
Timeout: newTimeout,
}
globalConfig.Store(newConfig) // 原子地替换旧配置
fmt.Printf("配置已更新为: %+v\n", newConfig)
}
func main() {
// 多个goroutine可以并发读取配置
go func() {
for {
cfg := GetCurrentConfig()
fmt.Printf("Goroutine 1 正在使用配置: %+v\n", cfg)
time.Sleep(1 * time.Second)
}
}()
go func() {
for {
cfg := GetCurrentConfig()
fmt.Printf("Goroutine 2 正在使用配置: %+v\n", cfg)
time.Sleep(1500 * time.Millisecond)
}
}()
// 模拟配置更新
time.Sleep(3 * time.Second)
UpdateGlobalConfig("new.api.com", 10*time.Second)
time.Sleep(5 * time.Second)
UpdateGlobalConfig("another.api.com", 2*time.Second)
select {} // 保持主goroutine运行
}这里面的核心思想是“写时复制”(Copy-on-Write)。每次更新配置,我们不是修改原有的Config对象,而是创建一个新的Config对象,然后用atomic.Value的Store方法原子地替换掉旧的引用。这样,所有正在读取旧配置的goroutine不会受到影响,而后续读取的goroutine则会看到新配置。这避免了在读取配置时加锁,极大地提高了读取性能。
3. 陷阱与注意事项:
- 复合操作非原子:
atomic操作只保证单个操作的原子性。如果你有多个atomic操作组成一个逻辑单元,这个逻辑单元整体上并不是原子的。例如,先Load再根据值做判断,再Store,这整个过程就需要CAS或者sync.Mutex来保护。 - 内存对齐: 在某些架构上,为了保证原子操作的正确性和性能,
int64和uint64类型的变量需要进行64位对齐。Go语言运行时通常会处理好这个问题,但在某些特殊情况下(例如,将int64嵌入到非对齐的结构体中),可能需要注意。 - 误用
unsafe.Pointer:atomic.Pointer是基于unsafe.Pointer实现的,它的使用需要非常小心,因为它绕过了Go的类型系统。通常,atomic.Value是更安全、更推荐的选择,除非你确实需要处理原始指针。 - 不是所有并发问题都能用
atomic解决:atomic主要解决的是单值操作的竞态问题。对于涉及多个变量的复杂状态转换、同步事件、任务编排等,sync.Mutex、sync.WaitGroup、sync.Cond、channel等才是更合适的工具。
总的来说,sync/atomic是一个强大的工具,但它要求开发者对并发编程的底层机制有较深的理解。用得好,能显著提升特定场景下的性能;用不好,可能引入更隐蔽的bug。在实际项目中,我倾向于在性能瓶颈明确且场景匹配时才考虑它,否则,sync.Mutex通常是更安全、更易于理解和维护的选择。
到这里,我们也就讲完了《Golang原子操作解析与实战教程》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于的知识点!
 苹果返校季补贴能叠加国补吗?
苹果返校季补贴能叠加国补吗?
- 上一篇
- 苹果返校季补贴能叠加国补吗?

- 下一篇
- 7881游戏交易怎么用?平台买卖教程详解
-
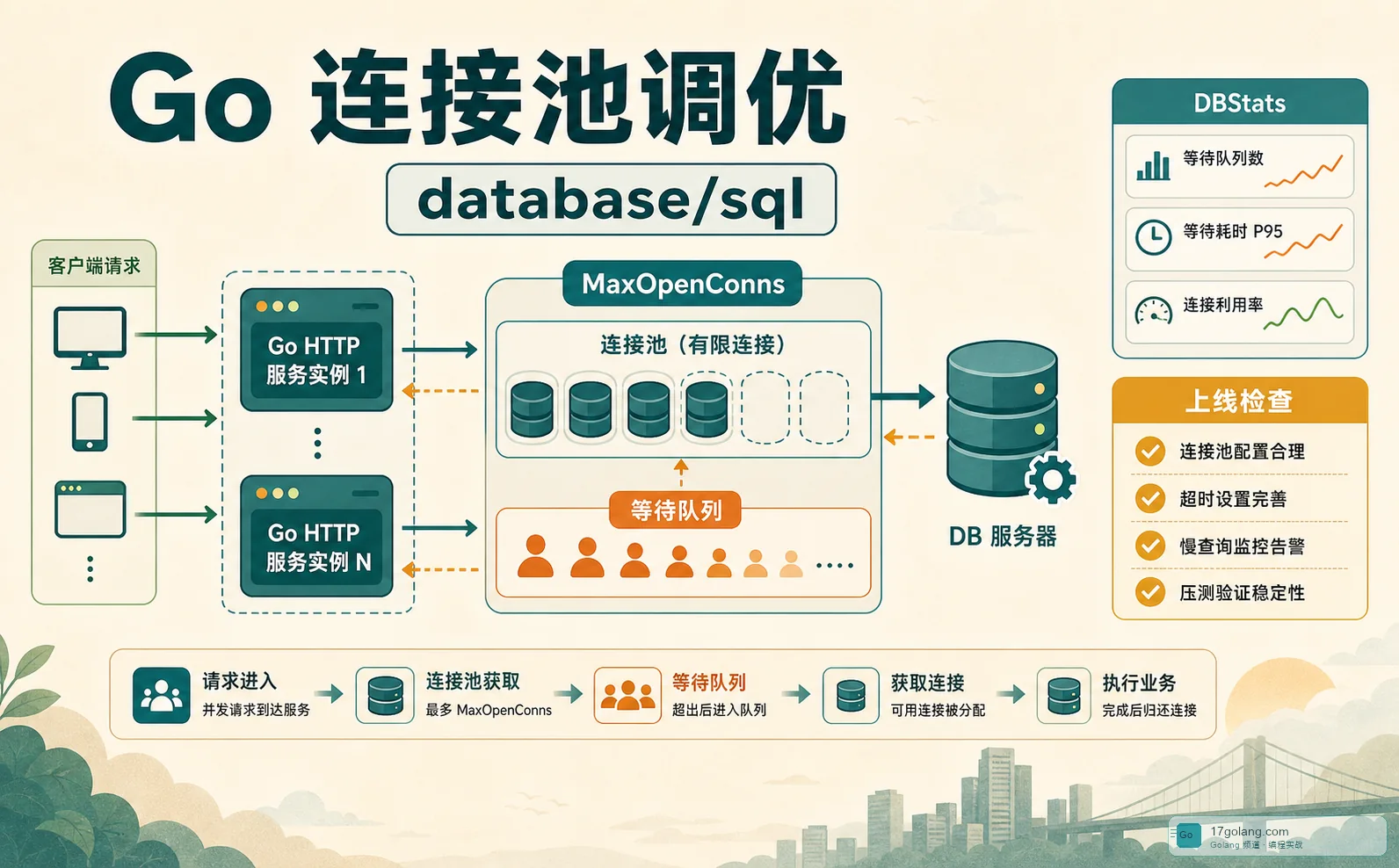
- Golang · Go教程 | 3天前 | 性能优化 · Go教程 · 后端工程 · Golang实战 · database/sql · 连接池调优 · golang Go 性能优化 连接池 MaxOpenConns database/sql 后端工程 DBStats
- Go database/sql 连接池实战:别让 MaxOpenConns 把接口拖成排队机
- 242浏览 收藏
-

- Golang · Go教程 | 3天前 | 并发编程 · 数据竞争 · Go教程 · 生产实践 · race detector · golang Go 数据竞争 并发 sync atomic race detector go test -race
- Go race detector 实战:别让数据竞争混进线上服务
- 147浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 6453次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6866次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6660次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8612次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 7302次使用
-
- Golangmap实践及实现原理解析
- 2022-12-28 505浏览
-
- go和golang的区别解析:帮你选择合适的编程语言
- 2023-12-29 503浏览
-
- 试了下Golang实现try catch的方法
- 2022-12-27 502浏览
-
- 如何在go语言中实现高并发的服务器架构
- 2023-08-27 502浏览
-
- 提升工作效率的Go语言项目开发经验分享
- 2023-11-03 502浏览


