WhisperAI工具使用全攻略
OpenAI Whisper是一款强大的AI语音识别工具,它并非单一的“混合工具”,而是通过Python库或命令行工具,将顶尖的AI能力融入各种工作流,实现高效的音频文本转换。本文将深入探讨如何利用OpenAI Whisper进行快速音频转录,包括选择合适的模型(如base、small)以平衡速度与准确性,以及利用GPU加速提升性能。同时,还将介绍在Windows、macOS和Linux等不同操作系统下的高效部署方法,以及如何利用CUDA配置和MPS加速等技巧。此外,本文还将揭秘OpenAI Whisper的高级功能,如语言检测、时间戳分段和长音频分块处理,以及如何结合NLP工具实现标点修复、说话人分离和文本摘要,从而构建完整的语音处理工作流。
OpenAI Whisper的核心是其语音识别模型及生态系统,通过Python库或命令行工具可在本地高效转录音频。选择合适的模型(如base、small)能平衡速度与准确性,结合GPU加速可提升性能。支持跨平台部署:Windows需注意CUDA配置,macOS可利用MPS加速,Linux适合服务器运行。高级功能包括语言检测、时间戳分段、长音频分块处理,以及结合NLP工具实现标点修复、说话人分离和文本摘要,形成完整的语音处理工作流。

OpenAI Whisper的AI混合工具,其实更准确地说,是它那套强大的语音识别模型和围绕它构建的生态系统。要快速转录音频,关键在于理解其核心工作原理,并选择合适的部署方式和模型。它不是一个单一的“混合工具”,而是通过灵活的接口,让我们能将顶尖的AI能力融入到各种工作流中,从而实现高效的音频文本转换。
解决方案
要高效利用OpenAI Whisper进行快速音频转录,最直接且实用的方法通常是使用其官方提供的Python库或命令行工具。这允许你直接在本地环境运行模型,避免了网络传输的延迟,同时也能根据自己的硬件条件进行优化。
首先,确保你的Python环境已配置好,并且安装了必要的库:
pip install openai-whisper
如果你有NVIDIA GPU并希望利用CUDA加速,还需要安装PyTorch的GPU版本。这通常是性能提升的关键。
安装完成后,基本的转录流程非常简单。你可以通过命令行直接调用:
whisper "你的音频文件.mp3" --model base --language Chinese --output_format txt
这里,“你的音频文件.mp3”是你想要转录的音频路径。--model base指定了使用的模型大小,--language Chinese明确了语言(虽然Whisper有语言检测能力,但明确指定能提高准确率和速度),--output_format txt则指定了输出格式。
对于更复杂的自动化或集成,你可以在Python脚本中调用:
import whisper
# 加载模型,这里我们用'base'模型,如果GPU可用,它会自动使用
model = whisper.load_model("base")
# 转录音频
result = model.transcribe("你的音频文件.wav", language="zh")
# 打印转录结果
print(result["text"])
# 如果你需要更详细的信息,比如带时间戳的片段
for segment in result["segments"]:
print(f"[{segment['start']:.2f}s -> {segment['end']:.2f}s] {segment['text']}")这种方式的“混合”体现在你可以将Whisper的转录结果,无缝地传递给后续的文本处理、翻译或内容分析工具。例如,转录完成后,你可以立即用另一个NLP库对文本进行关键词提取或情感分析,形成一个完整的自动化流程。选择合适的模型大小(tiny, base, small, medium, large)是平衡速度和准确性的核心,通常base或small就能满足大多数日常需求,且速度可观。
如何选择适合的Whisper模型以平衡速度与准确性?
选择OpenAI Whisper模型时,我们总是在“速度”和“准确性”之间寻找那个甜蜜点。这就像你买车,不可能同时拥有跑车的速度和越野车的通过性,总得有所取舍。Whisper提供了从tiny到large等一系列模型,它们各自的参数量、计算需求和识别精度都大相径庭。
tiny和base模型是速度的王者。它们的体积小,加载快,转录速度惊人,即便在CPU上也能有不错的表现。对于那些对准确率要求不是极高,或者音频质量本身就很好、口音不重、背景噪音小的场景,比如播客、清晰的会议录音,它们是绝佳的选择。我个人经常用base模型处理一些内部的快速会议纪要,因为它在中文语境下表现已经相当可靠,而且几乎是瞬间出结果。但缺点也很明显,遇到复杂的口音、专业术语或是嘈杂环境,错误率会显著上升,可能出现一些词语的混淆,甚至是对整句话的误解。
small和medium模型则代表了一种更均衡的选择。它们在准确性上有了显著提升,能够更好地处理一些语言的细微差别和更复杂的音频环境。当然,代价就是计算资源的消耗和转录时间的增加。如果你有GPU,small模型通常是一个非常实用的选择,它能在保持较快速度的同时,提供接近专业级别的转录质量。对于需要发布、存档,或对准确性有一定要求的场景,比如学术讲座、采访录音,它们往往是更稳妥的方案。
至于large模型,它无疑是准确性的巅峰。参数量巨大,能够捕捉到最细微的语音信息,尤其是在多语言、复杂口音或专业领域词汇方面,表现出无与伦比的优势。然而,它的运行速度也最慢,对硬件要求最高,强烈建议在拥有高性能GPU的环境下使用。对于那些对转录结果有“零容忍”错误率的场景,比如法律听证、医疗记录、字幕制作,large模型是你的不二之选。但对于日常快速处理,它可能显得有些“杀鸡用牛刀”,不经济也不高效。
所以,我的建议是:先从base或small开始尝试,评估其转录效果是否满足你的需求。如果不够,再逐步升级到medium或large。同时,考虑你的硬件条件,GPU是提升中大型模型运行效率的关键。
在不同操作系统下,如何高效部署和运行OpenAI Whisper?
在不同操作系统下部署和运行OpenAI Whisper,核心思路是一致的:搭建Python环境,安装必要的库。但具体操作细节和遇到的“坑”可能会有所不同。
Windows环境: Windows用户往往会遇到一些环境配置的挑战,尤其是涉及GPU加速时。
- Python环境: 推荐使用Anaconda或Miniconda来管理Python环境。它们能有效避免各种依赖冲突。安装Anaconda后,创建一个新的虚拟环境:
conda create -n whisper_env python=3.9 conda activate whisper_env
- PyTorch with CUDA (GPU加速): 这是Windows用户最容易出错的地方。你需要确保你的NVIDIA显卡驱动是最新的,并且安装了对应版本的CUDA Toolkit。然后,按照PyTorch官网的指引安装支持CUDA的PyTorch版本。例如:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # 这里的cu118对应CUDA 11.8,请根据你的CUDA版本调整
如果GPU无法正常工作,通常是CUDA版本不匹配、驱动问题或PyTorch版本错误。
- 安装Whisper:
pip install openai-whisper
- 运行: 在命令行或Python脚本中调用即可。
macOS环境: macOS用户,尤其是拥有Apple Silicon(M1/M2/M3芯片)的用户,体验会非常棒。
Python环境: Homebrew是macOS上管理软件包的利器,可以用它来安装Python。或者同样使用Anaconda。
brew install python # 或者 conda create -n whisper_env python=3.9 conda activate whisper_env
PyTorch for Apple Silicon (MPS): Apple为M系列芯片提供了Metal Performance Shaders (MPS) 后端,可以利用GPU加速。安装PyTorch时,确保选择支持MPS的版本:
pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu # 或者直接 pip install torch torchvision torchaudio # 新版PyTorch通常会自动识别并支持MPS
在Python代码中,你需要明确指定设备为
mps:import torch import whisper device = "cuda" if torch.cuda.is_available() else ("mps" if torch.backends.mps.is_available() else "cpu") model = whisper.load_model("base", device=device)这能确保模型在M芯片上获得硬件加速。
安装Whisper:
pip install openai-whisper
运行: 与Windows类似。
Linux环境: Linux环境是Whisper部署的“主场”,尤其是服务器环境。
- Python环境: 系统自带Python,但最好使用
pyenv或Anaconda来管理多个Python版本和虚拟环境。sudo apt update && sudo apt install python3-pip pip install virtualenv # 或者使用conda python3 -m venv whisper_env source whisper_env/bin/activate
- PyTorch with CUDA: 与Windows类似,确保CUDA Toolkit安装正确,并且显卡驱动与CUDA版本匹配。然后按照PyTorch官网的Linux+CUDA指引安装。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
在服务器上,你可能需要配置
LD_LIBRARY_PATH等环境变量,确保系统能找到CUDA库。 - 安装Whisper:
pip install openai-whisper
- 运行: 命令行或脚本调用。在服务器上,通常会结合
nohup或tmux来运行长时间任务。
无论哪个系统,遇到问题时,首先检查Python版本、PyTorch版本与CUDA/MPS的兼容性,以及显卡驱动是否最新。很多时候,这些基础环境问题是导致Whisper无法高效运行的根源。
除了基础转录,Whisper还能实现哪些高级功能或优化技巧?
OpenAI Whisper远不止是一个简单的“听写机”,它在设计之初就考虑到了多语言、多任务的特性,这为我们提供了很多高级功能和优化空间。
1. 语言检测与多语言转录:
Whisper本身就具备强大的语言检测能力。即使你不指定--language参数,它也能自动识别音频中的主要语言。这对于处理混合语言音频或不确定语言的音频非常有用。例如,一个国际会议的录音,可能包含中文、英文、日文等多种语言,Whisper能够智能识别并进行相应语言的转录,尽管它不会在输出中明确标记出每个词的语言,但转录的准确性会很高。
2. 时间戳与分段处理:
Whisper的输出不仅仅是纯文本,它还能提供带有时间戳的语音片段(segments)。这对于字幕制作、内容编辑或需要精确到秒的音频分析至关重要。通过result["segments"],你可以获取每个短语的开始和结束时间,这使得后期处理,比如将转录结果与视频同步,变得异常简单。
3. 处理长音频文件的策略:
Whisper模型虽然强大,但直接处理数小时的长音频文件可能会消耗大量内存,甚至导致内存溢出。一个常见的优化策略是音频分块处理。你可以将长音频文件切割成数分钟的小段,分别进行转录,然后再将结果拼接起来。市面上有一些工具(如pydub)可以帮助你实现音频切割。
from pydub import AudioSegment
import whisper
audio = AudioSegment.from_file("very_long_audio.mp3")
chunk_length_ms = 10 * 60 * 1000 # 10 minutes in milliseconds
model = whisper.load_model("base")
full_transcript = ""
for i, start_ms in enumerate(range(0, len(audio), chunk_length_ms)):
end_ms = min(start_ms + chunk_length_ms, len(audio))
chunk = audio[start_ms:end_ms]
chunk.export(f"temp_chunk_{i}.wav", format="wav")
result = model.transcribe(f"temp_chunk_{i}.wav", language="zh")
full_transcript += result["text"] + " " # 注意处理好拼接处的空格或标点
# 可以在这里删除临时文件 os.remove(f"temp_chunk_{i}.wav")
print(full_transcript)这种方式不仅能降低单次处理的内存压力,还能在多核CPU或多GPU环境下进行并行处理,进一步提升效率。
4. 针对特定场景的微调(Fine-tuning)考虑: 虽然OpenAI官方的Whisper模型通常不需要微调就能表现出色,但对于某些极其专业的领域(如医学术语、特定方言),如果通用模型的准确率仍不理想,理论上可以通过少量领域数据对Whisper模型进行微调。这需要更深入的机器学习知识和大量计算资源,但可以显著提升在特定垂直领域的识别准确性。不过,对于大多数用户来说,这可能超出了“实用方法”的范畴,更偏向于研究和开发。
5. 结合其他工具进行后处理: Whisper的输出是文本,这为与各种自然语言处理(NLP)工具的结合创造了无限可能。
- 标点符号和大小写修复: Whisper的输出有时在标点和大小写方面可能不尽如人意,可以结合像
punctuate或自定义规则的NLP库进行后处理。 - 说话人分离(Diarization): Whisper本身不区分说话人,但你可以先用其他工具(如
pyannote.audio)进行说话人分离,将音频按说话人切分,然后分别用Whisper转录,最后再将结果合并,这样就能得到带有说话人标记的转录稿。 - 摘要与关键词提取: 转录完成后,可以利用大型语言模型(LLMs)或专门的文本摘要工具,对长篇转录稿进行摘要、关键词提取,甚至生成会议纪要。
这些高级应用和优化技巧,让Whisper从一个单纯的转录工具,蜕变为一个强大且灵活的语音内容处理平台。关键在于理解其能力边界,并善用工程手段和与其他AI工具的结合。
本篇关于《WhisperAI工具使用全攻略》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
 Java随机访问文件使用详解
Java随机访问文件使用详解
- 上一篇
- Java随机访问文件使用详解

- 下一篇
- Windows搜索失效?实用修复方法大全
-
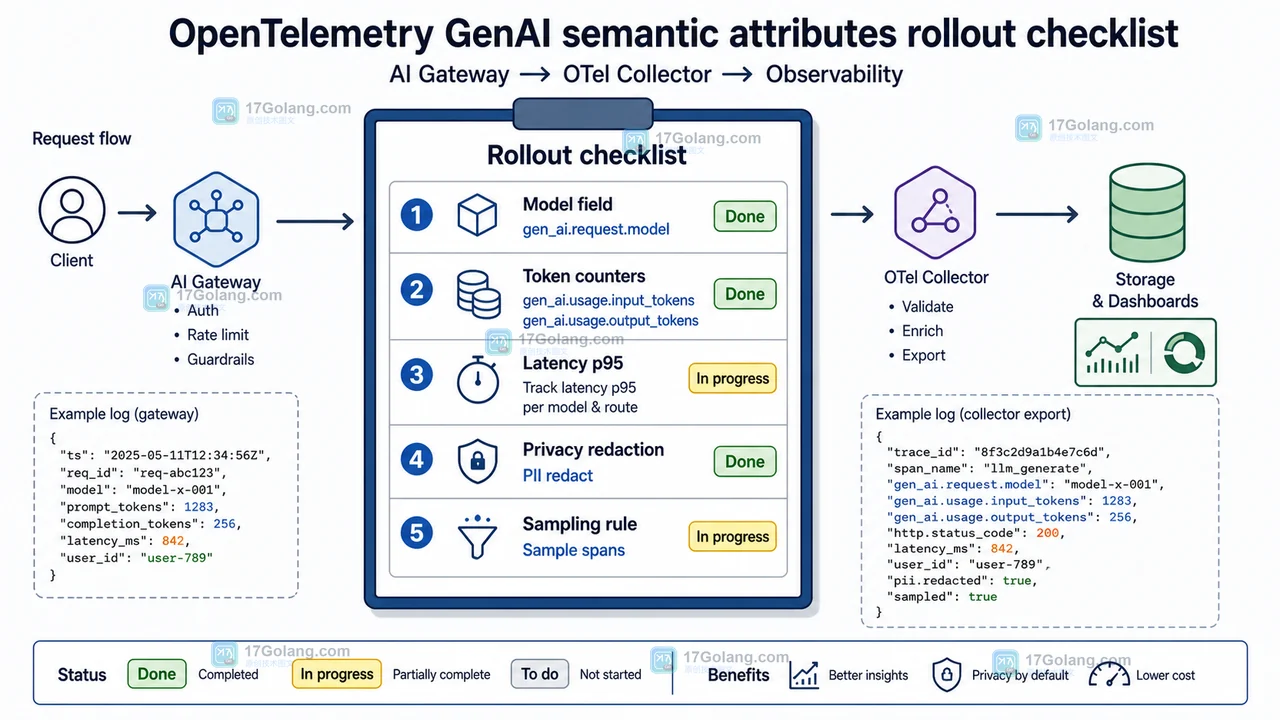
- 科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计
- AI 调用可观测架构:从散乱日志到 OpenTelemetry GenAI 字段统一
- 427浏览 收藏
-
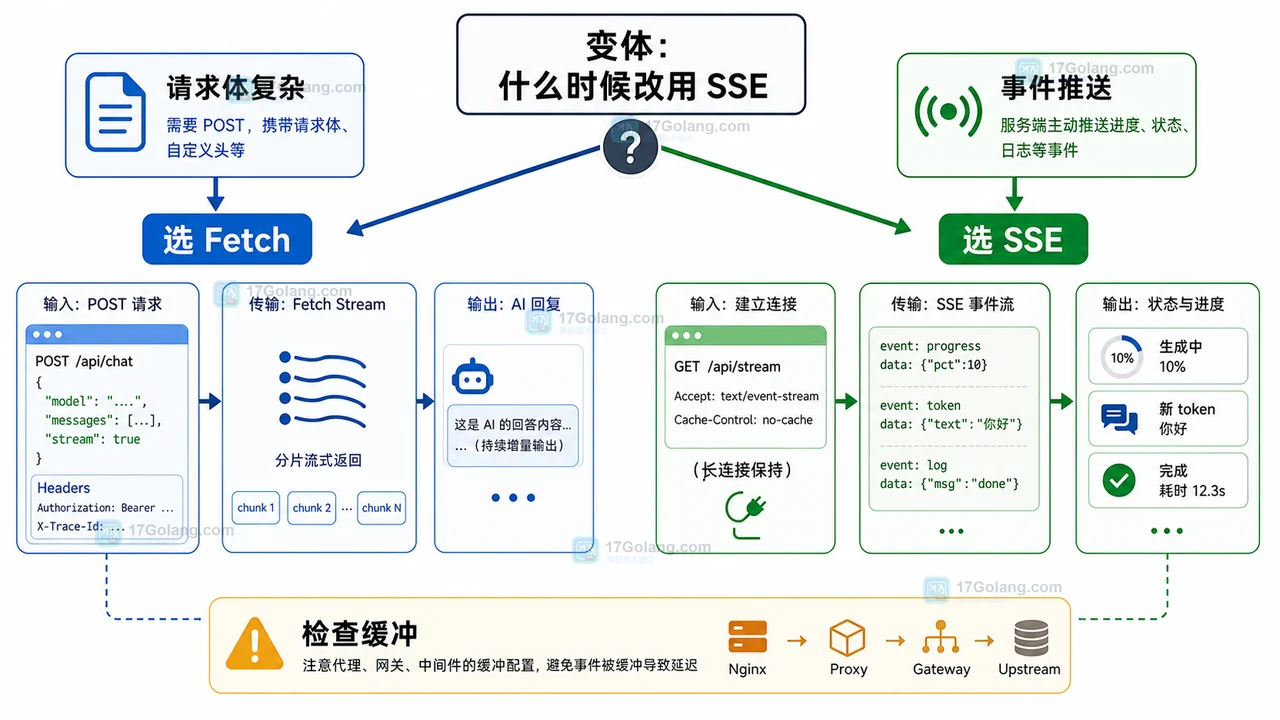
- 科技周边 · 人工智能 | 1星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream
- AI 聊天流式输出前端配方:用 Fetch Stream 实现逐字渲染和中断控制
- 448浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4384次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4062次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4044次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4229次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4198次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


