JavaMDC日志追踪方案详解
全链路追踪是现代微服务架构的基石,它通过Trace ID将分布式系统中分散的日志关联起来,如同“GPS导航”般还原请求路径,大幅提升问题定位和性能分析效率。Java MDC全链路追踪方案通过为每个请求赋予唯一标识符,并将其与所有相关日志绑定,从而在海量日志中快速筛选出同一业务流的日志,还原请求处理路径。实现的关键在于Trace ID的生成、传递和清理,尤其是在跨服务调用和异步处理中,需要显式传递MDC上下文,并在流程结束时务必清除MDC,以避免上下文污染。本文将深入解析Java MDC全链路追踪的原理、实现方法,以及在Spring Boot应用中的具体实践,同时探讨常见陷阱与优化策略,助你构建高效稳定的分布式系统。
全链路追踪在现代微服务架构中不可或缺,是因为它解决了分布式系统中请求路径不可见、日志分散难以关联的问题。1. 它通过为每个请求分配唯一的Trace ID,将整个调用链中的日志串联起来;2. 使得开发者能快速定位问题、分析性能瓶颈;3. 提供了类似“GPS导航”的能力,清晰还原请求路径;4. 极大地提升了故障排查效率和用户体验。

Java日志记录中的MDC全链路追踪,核心在于为每一次请求或业务操作,在整个执行链路中,赋予一个唯一的标识符(Trace ID),并将其与所有相关的日志信息绑定起来。这样,当问题出现时,我们就能通过这个Trace ID,快速地从海量的日志中筛选出同一条业务流的所有日志,从而清晰地还原出请求的处理路径和各个环节的状态,极大地方便了分布式系统下的故障排查和性能分析。这就像给每个包裹贴上唯一的快递单号,无论包裹在哪个分拣中心、哪辆车上,都能通过这个单号追踪它的行踪。

解决方案
要实现MDC全链路追踪,关键在于Trace ID的生成、传递和清理。
一个常见的做法是在请求入口处(比如Web应用的Filter或Interceptor中)生成一个唯一的Trace ID,并将其放入MDC中。MDC是一个基于ThreadLocal的Map,它允许你在当前线程的上下文中存储键值对信息。一旦Trace ID被放入MDC,当前线程后续产生的所有日志(只要日志框架配置得当,比如Logback或Log4j2的Pattern Layout中包含%X{traceId})都会自动带上这个ID。

但事情没那么简单,微服务架构下,请求往往会跨越多个服务,甚至涉及异步处理、消息队列。这时候,MDC的线程局部性就成了挑战。当请求从一个服务调用另一个服务时,Trace ID需要被显式地传递过去,通常是通过HTTP请求头、RPC元数据或消息队列的消息头。下游服务接收到请求后,再将这个Trace ID重新放入其MDC中。对于异步操作,比如线程池中的任务,MDC上下文也需要手动传递,或者使用一些框架提供的增强功能(如Spring的@Async结合自定义TaskDecorator)。
最重要的是,无论何时何地,在业务流程结束或线程即将被回收时,务必清除MDC中的Trace ID。否则,线程复用时可能会出现上下文污染,导致错误的Trace ID被关联到新的请求上,这比没有追踪信息还糟糕,因为它会带来误导。

// 示例:在请求开始时设置MDC
public void onRequestStart(String traceId) {
MDC.put("traceId", traceId); // 设置traceId
// ... 业务逻辑 ...
logger.info("处理请求...");
}
// 示例:在请求结束时清除MDC
public void onRequestEnd() {
MDC.clear(); // 清除所有MDC内容,或者MDC.remove("traceId")
}
// 示例:Logback配置,在pattern中加入%X{traceId}
// %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - [traceId=%X{traceId}] %msg%n 为什么全链路追踪在现代微服务架构中不可或缺?
说实话,没有全链路追踪的微服务架构,调试起来简直是噩梦。想想看,一个用户请求可能穿透好几个服务,每个服务又可能调用其他服务,甚至还可能触发异步任务、消息队列。当用户抱怨某个功能有问题时,你面对的是一堆分散在不同服务、不同机器上的日志文件,它们彼此之间没有任何关联。你根本不知道哪个日志条目属于哪个请求,更别说搞清楚请求到底在哪一步出了问题,或者哪个服务响应慢了。
我个人觉得,全链路追踪就是微服务架构的“GPS导航系统”。它能清晰地描绘出请求从起点到终点的完整路径,包括经过了哪些服务、每个服务耗时多久、有没有报错。这不仅能帮助开发人员快速定位问题、分析性能瓶颈,还能让运维人员在系统出现异常时,一眼就看出是哪个环节出了岔子。这对于快速响应、提升用户体验,简直是救命稻草。它从根本上改变了我们排查分布式系统问题的方式,从大海捞针变成了按图索骥。
如何在Spring Boot应用中实现MDC全链路追踪?
在Spring Boot应用中实现MDC全链路追踪,通常会利用其AOP或拦截器机制来自动化Trace ID的设置和清理,并处理异步场景下的上下文传递。
对于Web请求,最常见的方式是使用HandlerInterceptor或Filter。你可以在请求进入时生成或获取Trace ID,并将其放入MDC;在请求处理完成后,清除MDC。
// Web请求拦截器示例
@Component
public class TraceIdInterceptor implements HandlerInterceptor {
private static final String TRACE_ID_HEADER = "X-B3-TraceId"; // 常用请求头
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
String traceId = request.getHeader(TRACE_ID_HEADER);
if (traceId == null || traceId.isEmpty()) {
traceId = UUID.randomUUID().toString().replace("-", ""); // 生成新的Trace ID
}
MDC.put("traceId", traceId);
// 如果需要,也可以把traceId放回response header,方便前端或下游服务获取
response.setHeader(TRACE_ID_HEADER, traceId);
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
MDC.clear(); // 清理MDC,非常重要!
}
}对于服务间调用,比如使用RestTemplate或Feign,你需要一个自定义的ClientHttpRequestInterceptor或RequestInterceptor来将当前的Trace ID从MDC中取出,并添加到出站请求的HTTP头中。
// RestTemplate拦截器示例
@Component
public class RestTemplateTraceIdInterceptor implements ClientHttpRequestInterceptor {
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
String traceId = MDC.get("traceId");
if (traceId != null) {
request.getHeaders().add("X-B3-TraceId", traceId);
}
return execution.execute(request, body);
}
}
// 配置RestTemplate
// @Bean
// public RestTemplate restTemplate(RestTemplateBuilder builder) {
// return builder.additionalInterceptors(new RestTemplateTraceIdInterceptor()).build();
// }对于异步任务(如@Async、CompletableFuture或自定义ThreadPoolExecutor),MDC的上下文不会自动传递。你需要一个TaskDecorator来包装Runnable或Callable,在执行前将父线程的MDC内容复制过来。
// 异步任务MDC上下文传递示例
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(20);
executor.setQueueCapacity(200);
executor.setThreadNamePrefix("async-task-");
executor.setTaskDecorator(new MDCTaskDecorator()); // 关键在这里
executor.initialize();
return executor;
}
// 自定义TaskDecorator
static class MDCTaskDecorator implements TaskDecorator {
@Override
public Runnable decorate(Runnable runnable) {
Map contextMap = MDC.getCopyOfContextMap(); // 获取当前线程的MDC副本
return () -> {
if (contextMap != null) {
MDC.setContextMap(contextMap); // 在子线程中设置MDC
}
try {
runnable.run();
} finally {
MDC.clear(); // 子线程执行完后也要清理
}
};
}
}
} 对于消息队列(如Kafka、RabbitMQ),Trace ID通常需要作为消息头的一部分发送,并在消费者端解析出来再放入MDC。这需要对消息生产者和消费者进行相应的改造。
MDC全链路追踪的常见陷阱与优化策略有哪些?
在MDC全链路追踪的实践中,确实会遇到一些让人头疼的问题,如果不注意,反而会引入新的麻烦。
一个最常见的陷阱就是MDC上下文的泄露。特别是当使用线程池来处理异步任务时,如果一个线程在处理完任务后没有清除MDC,那么这个线程被复用时,它可能仍然带着上一个任务的Trace ID。这会导致日志混乱,将不相关的日志条目错误地关联起来。所以,无论在哪种场景下,确保在请求或任务处理的finally块中调用MDC.clear()是黄金法则。这就像你用完一个公共物品后,一定要把它恢复原样。
另一个挑战是异步上下文的正确传递。前面提到了ThreadLocal的局限性,它只在当前线程有效。当你的代码涉及到线程切换(比如@Async、CompletableFuture、自定义线程池、或者响应式编程如WebFlux),MDC的上下文是不会自动传递的。这时候就需要手动复制MDC上下文到新的线程,或者利用一些框架提供的TaskDecorator、ContextWrapper等机制。我遇到过一个情况,就是因为异步调用没有正确传递MDC,导致某个耗时操作的日志突然“断链”了,排查起来非常困难。
关于性能开销,MDC本身对性能的影响微乎其微。它只是操作一个ThreadLocal的Map,这通常不是瓶颈。真正的性能瓶颈往往在于日志本身的I/O操作(写入磁盘、网络传输到日志中心)以及日志聚合工具的处理能力。所以,不要因为担心MDC的性能而犹豫不决,它的收益远大于这点开销。
最后,MDC只是全链路追踪的“骨架”,它提供了关联日志的能力。但要真正实现“全链路”,你还需要一个强大的日志聚合和可视化方案。MDC产生的带Trace ID的日志,最终需要被收集到像ELK Stack (Elasticsearch, Logstash, Kibana) 或 Grafana Loki 这样的系统中。只有这样,你才能通过Trace ID进行高效的查询、过滤和可视化,从而真正发挥全链路追踪的价值。没有日志聚合,MDC就像是只有身份证号但没有户籍系统的公民,你还是很难找到他。
今天关于《JavaMDC日志追踪方案详解》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
 表单AI助手怎么加?智能填写教程详解
表单AI助手怎么加?智能填写教程详解
- 上一篇
- 表单AI助手怎么加?智能填写教程详解

- 下一篇
- Golang依赖最小版本选择算法详解
-
- 文章 · java教程 | 1天前 | [] · []
- Java CompletableFuture 怎么加超时兜底:从同步等待改成可控异步返回
- 304浏览 收藏
-

- 文章 · java教程 | 1星期前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95
- Java CompletableFuture 聚合接口优化:用超时兜底把 P95 从 920ms 降到 330ms
- 255浏览 收藏
-
- 文章 · java教程 | 1星期前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签
- Java Webhook 回调接收接口设计:验签、幂等和状态流转
- 488浏览 收藏
-
- 文章 · java教程 | 1星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
- Java 本地 TTL 缓存小项目:用 ConcurrentHashMap 实现过期淘汰和命中统计
- 394浏览 收藏
-
- 文章 · java教程 | 1星期前 | Java · Stream · 数据处理 · 后端教程 · Java Stream bigdecimal 分组统计 Collectors 订单汇总
- Java Stream 分组统计实验:从订单列表到客户消费汇总
- 355浏览 收藏
-
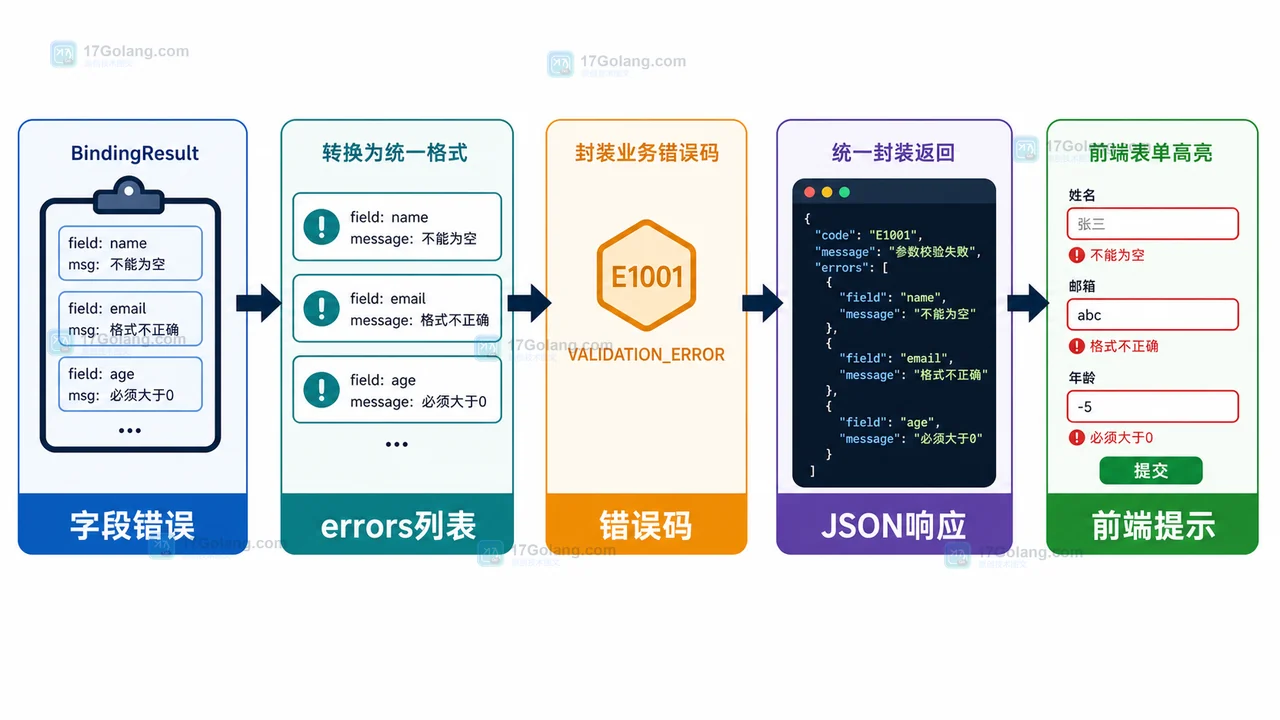
- 文章 · java教程 | 1星期前 | Java · Spring Boot · 后端开发 · 接口校验 · java spring boot dto 接口设计 参数校验
- Spring Boot 参数校验工作流:DTO、注解和统一错误响应
- 495浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4395次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4065次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4047次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4233次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4203次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


