20GB内存本地运行DeepSeek-R1-0528教程
想在本地运行媲美 OpenAI 的大型语言模型吗?本文为你带来 DeepSeek-R1-0528 的本地部署教程!即使只有 20GB 内存,也能体验 6710 亿参数的强大 AI 模型。DeepSeek-R1-0528 原始模型体积庞大,但得益于 Unsloth 团队的动态量化技术,模型大小被压缩至约 168GB,大大降低了运行门槛。文章详细介绍了运行完整版模型和 8B 蒸馏版模型的配置要求、性能表现,以及利用 Ollama 等工具进行部署的方法。同时,还分享了 Reddit 社区关于 DeepSeek-R1-0528 的实测反馈、硬件选择建议和未来展望,助你轻松玩转本地 AI 大模型。
 图片大家好,我是专注 AI 学习的老章
图片大家好,我是专注 AI 学习的老章
最近在 Reddit 上看到一个热门讨论,主题是如何在资源有限的情况下本地部署运行 DeepSeek-R1-0528 模型。
《你也能在本地运行 DeepSeek-R1-0528 了!(最低仅需 20GB 内存)》[1]
一、模型简介
DeepSeek-R1-0528 是由 DeepSeek 发布的最新一代推理模型,参数量高达 6710 亿(671B),官方宣称其性能可与 OpenAI 的 o3 和 o4-mini-high 相匹敌。
原始模型体积约为 715GB,对存储和算力要求极为严苛。得益于 Unsloth 团队开发的动态量化技术(如 1.78-bit、2-bit 等),该模型被压缩至约 168GB,压缩率接近 80%,大幅降低了本地运行门槛,使得消费级设备也能承载。
此外,DeepSeek 还推出了基于 Qwen3 架构的 8B 蒸馏版模型,性能接近 Qwen3(235B),非常适合硬件配置较低的用户使用。
二、运行 671B 完整模型的配置要求与性能表现
完整版 R1 的 GGUF 模型文件获取地址[2]
最低配置:
- 内存:20GB RAM(可勉强启动完整 671B 模型)
- 存储:至少 190GB 磁盘空间(量化后模型为 168GB)
- 推理速度:约 1 token/s,适合基础功能测试,响应较慢
推荐配置:
- 内存:64GB 或更高,显著改善加载和推理体验
- 显卡:例如 RTX 3090(24GB 显存),推理速度可达 3 tokens/s
- 存储:建议预留 200GB 以上空间,用于模型文件及缓存
理想配置:
- 总显存 + 内存 ≥ 120GB(如单张 H100 GPU),推理速度可达 5+ tokens/s
- 高端方案:3x H100 GPU(成本约 7.5 万美元),速度可达 14 tokens/s,适用于企业级本地部署
轻量选择:
8B 蒸馏版本可在低配设备上流畅运行,例如搭载 16GB RAM 的 Android 手机或 M 系列芯片的 iPad。其表现接近 GPT-3/3.5 水平,移动设备上可达约 3.5 tokens/s,桌面端则更快。
三、技术实现与部署方法
详细部署教程见[3]
量化技术:
Unsloth 团队推出了 UD-Q4_K_XL、Q2_K_L 等动态量化格式,兼容 llama.cpp、Ollama 等主流推理引擎。这些格式将模型从 715GB 压缩至 168GB,同时尽可能保留原始精度。提供多种精度选项:
- Q8:高保真,适合高性能设备
- bf16:精度与效率平衡
- Q2_K_L:专为低配设备优化
相关文档详见 Unsloth 官方指南(https://docs.unsloth.ai/basics/unsloth-dynamic-2.0-ggufs),支持 GGUF 格式模型如 DeepSeek-R1-0528-GGUF:TQ1_0 [4]
运行方式:
- 使用 Ollama 加载:
ollama run hf.co/unsloth/DeepSeek-R1-0528-GGUF:TQ1_0 - 或直接从 HuggingFace 下载模型文件
- 参数建议:温度设为 0.6 可减少输出重复;编码任务中可关闭“思考”模式(/no_think)以提升效率
平台支持:
- 支持 LM Studio、Ollama、MLX(Apple 设备)等主流框架
- 移动端:8B 蒸馏模型可在 iPhone 16 Pro 或 M 系列 iPad 上通过 MLX 运行,但长时间高负载可能引发设备过热
- Android 设备(16GB RAM)运行 7B 级模型可达 3.5 tokens/s,需注意内存管理以防崩溃
四、社区反馈精选(Reddit 用户热议)
性能实测:
- 有用户在 RTX 5090 上运行 70B 蒸馏模型(Q4KM),速度仅为 1-2 tokens/s,未达预期。Unsloth 建议搭配 64GB 内存以提升表现。
- 另一用户使用 220GB DDR4 内存 + 2x RTX 3090(共 48GB 显存)运行 131GB 模型,速度稳定在 1.5–2.2 tokens/s,称这是家用设备运行 671B 模型的重大突破。
- 在 32 核 Epyc CPU(无独立 GPU)环境下运行 Q4 量化模型,速度可达 6–9 tokens/s,证明纯 CPU 推理的可行性。
模型行为观察:
- DeepSeek-R1 对系统提示词极为敏感,合理调整提示可显著提升输出质量,甚至在某些复杂任务中超越 Gemini 2.0 Flash 和 OpenAI o1 preview。
- “越狱”测试中模型成功扮演“horny bot”,展现出较强的灵活性,但也引发了关于蒸馏模型与原版能力差异的讨论。
硬件与成本考量:
- 完整 671B 模型运行成本高昂,例如 3x H100 GPU 需约 7.5 万美元,普通用户更倾向选择蒸馏版。
- 一位用户用 16 块二手 Tesla M40(总投入约 7500 美元)运行 Q3KM 模型,速度尚可但功耗极高。
- 社区普遍认为 RTX 3090 等消费级显卡性价比不错,建议优先提升内存容量。
蒸馏模型争议:
- 部分用户质疑 Ollama 上的“DeepSeek R1”实际是 Qwen 或 Llama 的蒸馏版本,并非完整 R1。
- Unsloth 官方澄清:这些是官方发布的 8B 蒸馏模型,专为低配设备设计。
- 8B 模型在代码生成方面表现突出,但缺乏原生网页访问和 PDF 解析能力,需依赖外部工具集成。
未来期待:
- 社区强烈期待 DeepSeek 推出 30B 或 32B 蒸馏模型,认为其可能成为本地运行的最佳平衡点。
- 有人提议开发类似 Claude Code 的本地智能代理,结合 R1-0528 的强大推理能力,拓展实际应用场景。
五、总结与展望
DeepSeek-R1-0528 借助 Unsloth 的动态量化技术,成功实现了从高端服务器到普通用户的跨平台部署。无论是 20GB 内存起步的入门配置,还是 H100 集群的高性能方案,都能找到适用场景。8B 蒸馏模型进一步推动了大模型在移动端的普及。
然而,完整 671B 模型仍面临硬件成本高、蒸馏版本性能缩水、移动设备稳定性不足等问题。未来,DeepSeek 与 Unsloth 若能推出 30B/32B 中型蒸馏模型、优化移动端适配、增强生态兼容性,将极大促进本地大模型的广泛应用。
我也在默默期待:DeepSeek 何时会发布 32B 蒸馏版?
参考资料
[1]
现在你可以在本地设备上运行 DeepSeek-R1-0528 了!(最低需 20GB 内存): https://www.reddit.com/r/LocalLLM/comments/1kz6tl1/you_can_now_run_deepseekr10528_on_your_local/
[2]
完整版 R1 的 GGUF 模型文件下载链接: https://huggingface.co/unsloth/DeepSeek-R1-0528-GGUF
[3]
完整运行指南: https://docs.unsloth.ai/basics/deepseek-r1-0528
[
终于介绍完啦!小伙伴们,这篇关于《20GB内存本地运行DeepSeek-R1-0528教程》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布文章相关知识,快来关注吧!
 HTML中<section>标签的作用是定义文档中的一个独立部分,通常用于对内容进行分组,使其在语义上更具结构和意义。它常用于将页面内容划分为不同的逻辑区块,例如文章的不同章节、导航栏、侧边栏、页脚等。<section>标签的使用场景:文章或博客的章节划分在长篇文章中,可以使用<section>来区分不同的段落或主题部分,比如“引言”、“正文”、“结论”等。&l
HTML中<section>标签的作用是定义文档中的一个独立部分,通常用于对内容进行分组,使其在语义上更具结构和意义。它常用于将页面内容划分为不同的逻辑区块,例如文章的不同章节、导航栏、侧边栏、页脚等。<section>标签的使用场景:文章或博客的章节划分在长篇文章中,可以使用<section>来区分不同的段落或主题部分,比如“引言”、“正文”、“结论”等。&l
- 上一篇
- HTML中<section>标签的作用是定义文档中的一个独立部分,通常用于对内容进行分组,使其在语义上更具结构和意义。它常用于将页面内容划分为不同的逻辑区块,例如文章的不同章节、导航栏、侧边栏、页脚等。<section>标签的使用场景:文章或博客的章节划分在长篇文章中,可以使用<section>来区分不同的段落或主题部分,比如“引言”、“正文”、“结论”等。&l

- 下一篇
- 萤石云app支持多设备登录,如何管理权限?
-
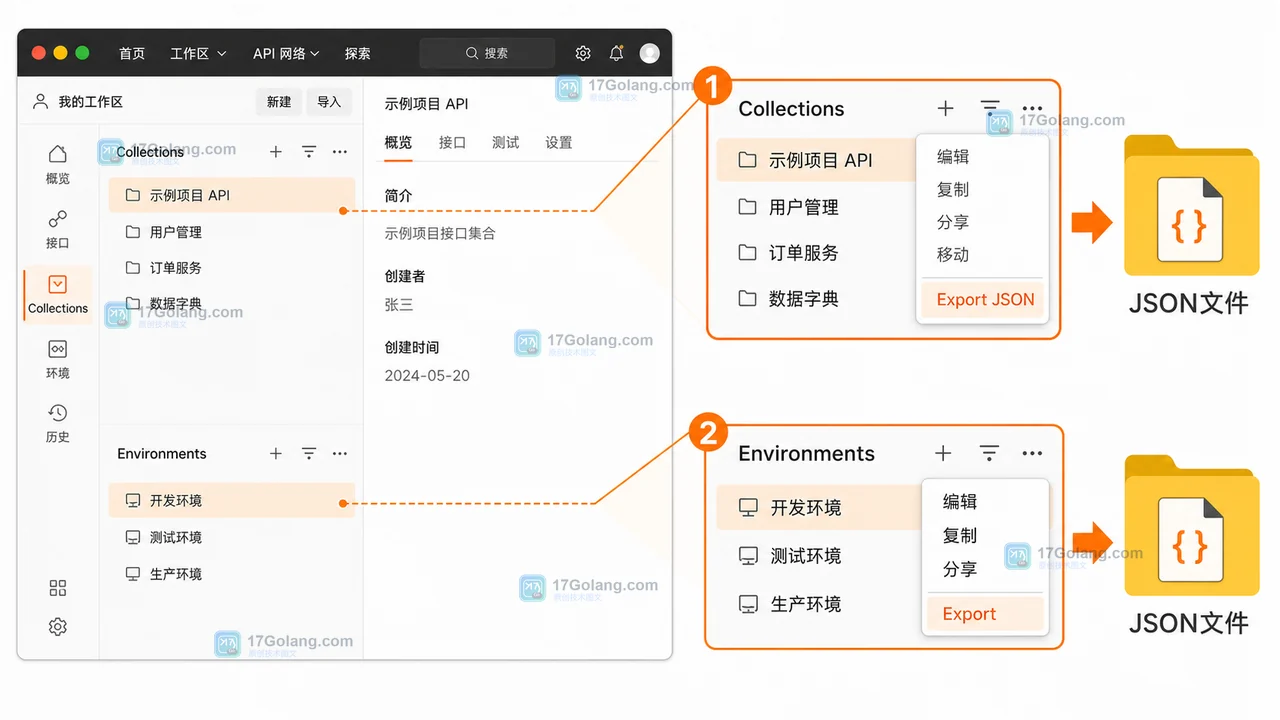
- 文章 · 软件教程 | 6天前 | 环境变量 · postman · 软件教程 · 接口测试 · 导入导出 · 环境变量 Collection JSON文件 导入导出 Postman Environment 接口集合
- Postman 导出和导入接口集合:Collection 与 Environment 迁移检查
- 308浏览 收藏
-
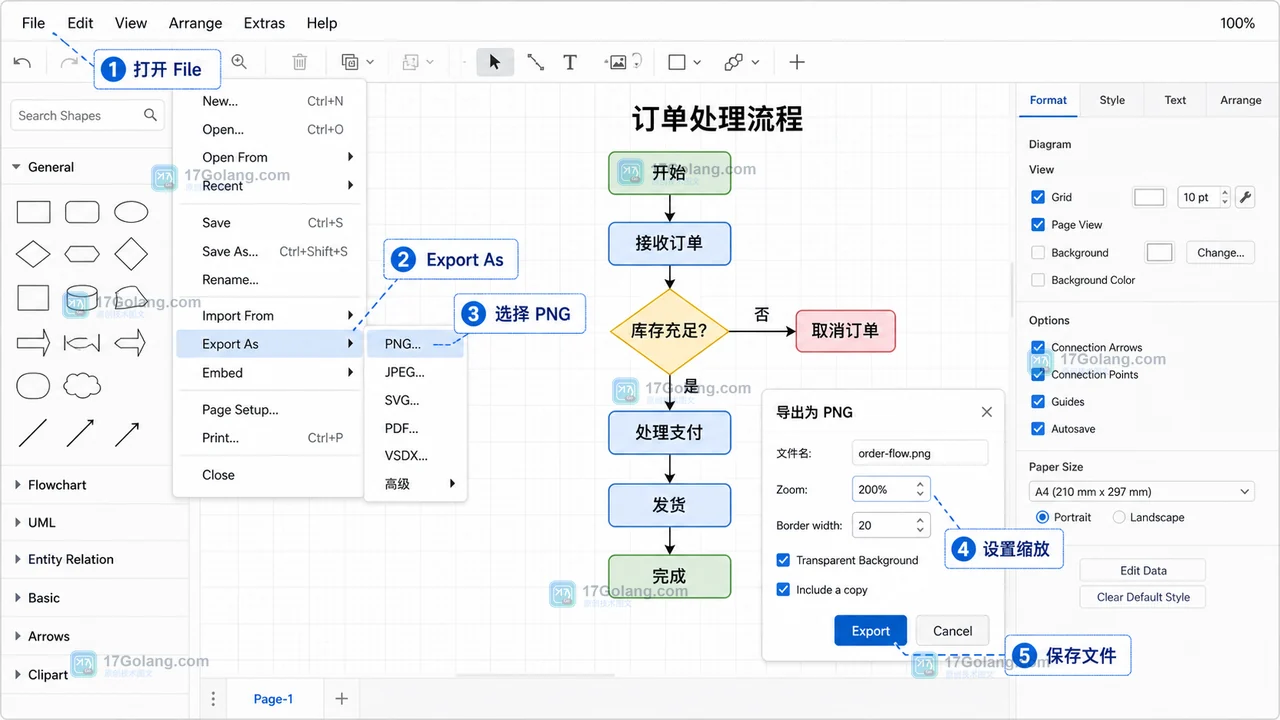
- 文章 · 软件教程 | 6天前 | PNG · diagrams.net · 软件教程 · draw.io · 流程图 · 透明背景 流程图 软件教程 Diagrams.net PNG导出 draw.io 图片归档
- diagrams.net 导出高清 PNG:透明背景、缩放比例和回导核对流程
- 130浏览 收藏
-
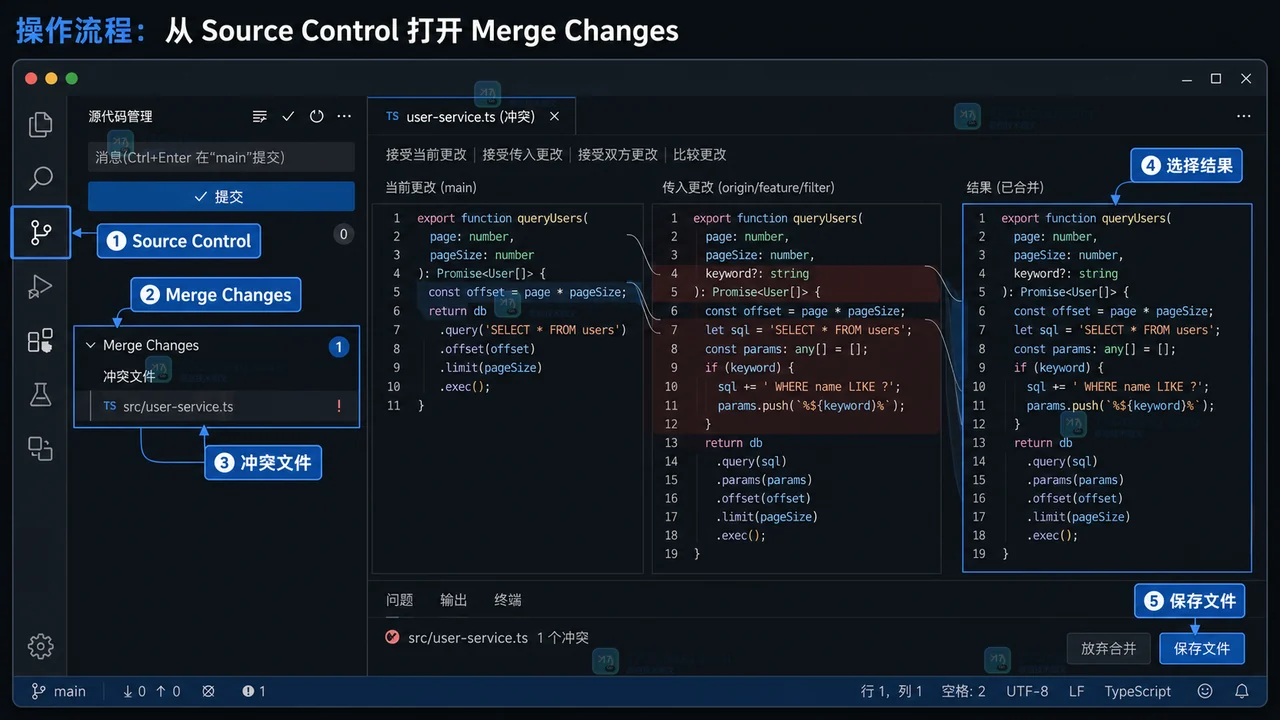
- 文章 · 软件教程 | 1星期前 | 版本控制 · source control · 软件教程 · VS Code教程 · Git冲突 · VS Code 软件教程 Git冲突 Source Control Merge Editor 提交核对
- VS Code 解决 Git 合并冲突:从 Source Control 到提交核对
- 395浏览 收藏
-
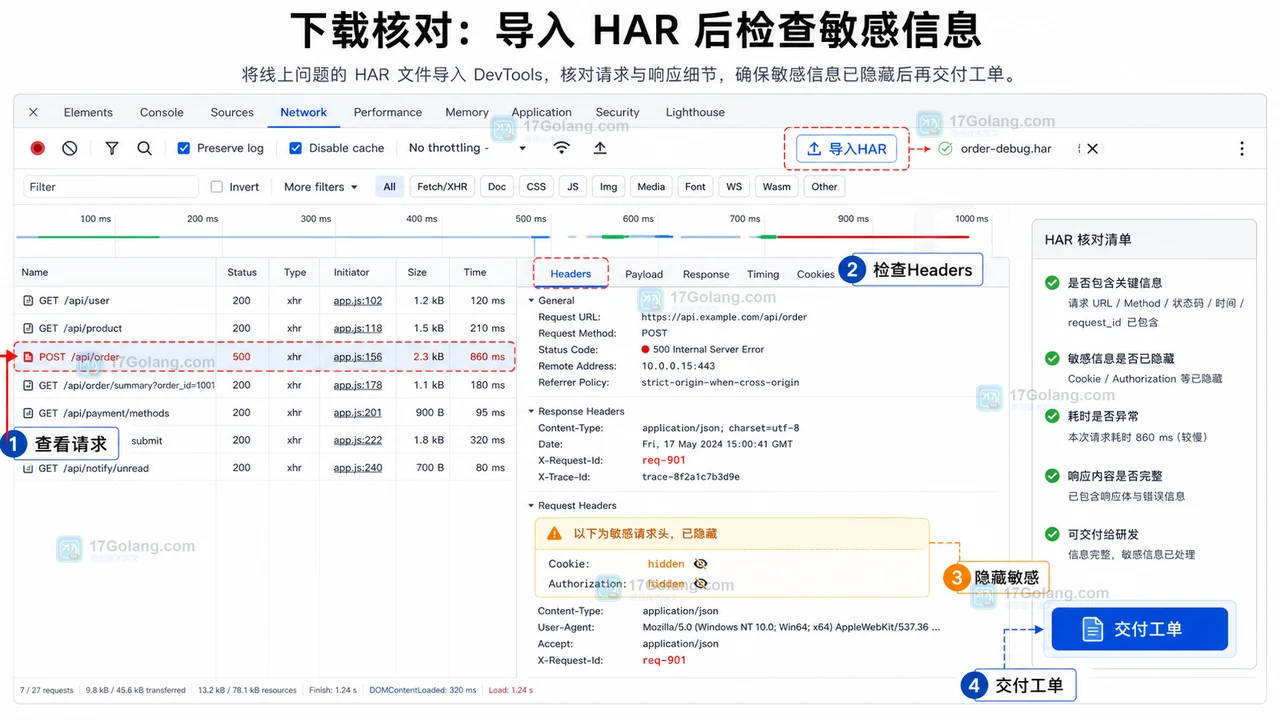
- 文章 · 软件教程 | 1星期前 | network · Har · 软件教程 · Chrome DevTools · 前端调试 · 软件教程 Chrome DevTools HAR文件 Network面板 前端排查
- Chrome DevTools 导出 HAR 文件:从 Network 捕获到脱敏核对
- 410浏览 收藏
-
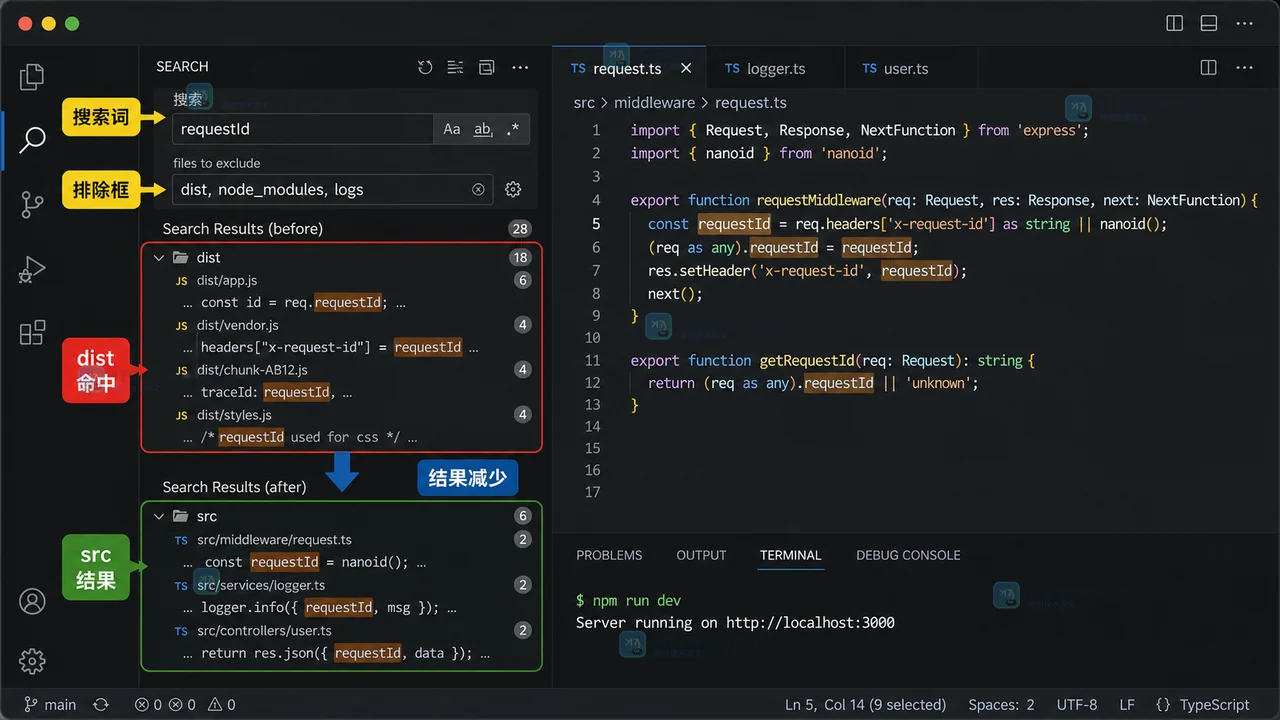
- 文章 · 软件教程 | 1星期前 | 开发工具 · vs code · 软件教程 · 设置排错 · VS Code 搜索排除 search.exclude files.exclude Use Exclude Settings
- VS Code 搜索排除不生效:search.exclude 和 Use Exclude Settings 设置排查
- 256浏览 收藏
-
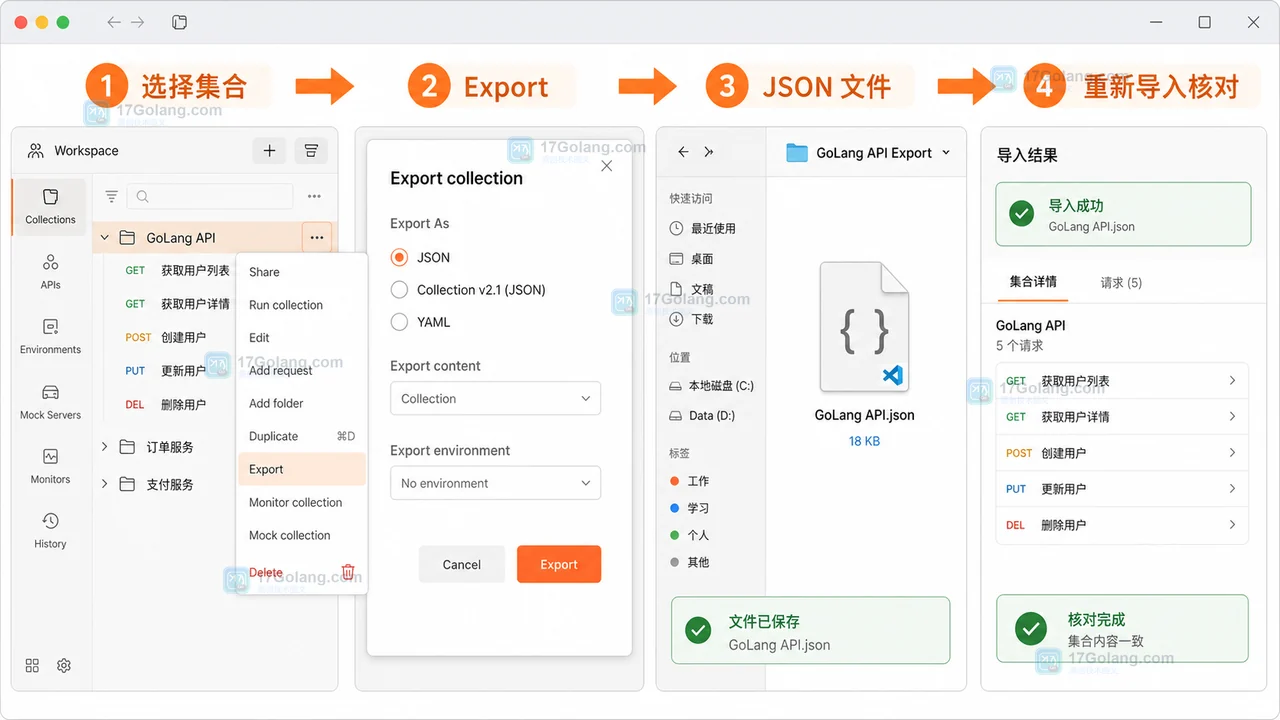
- 文章 · 软件教程 | 1星期前 | 接口文档 · postman · openapi · 接口测试 · Collection导出 · OpenAPI 软件教程 Collection Postman 接口调试
- Postman 导入 OpenAPI 并导出 Collection:把接口文档变成可共享调试集合
- 363浏览 收藏
-
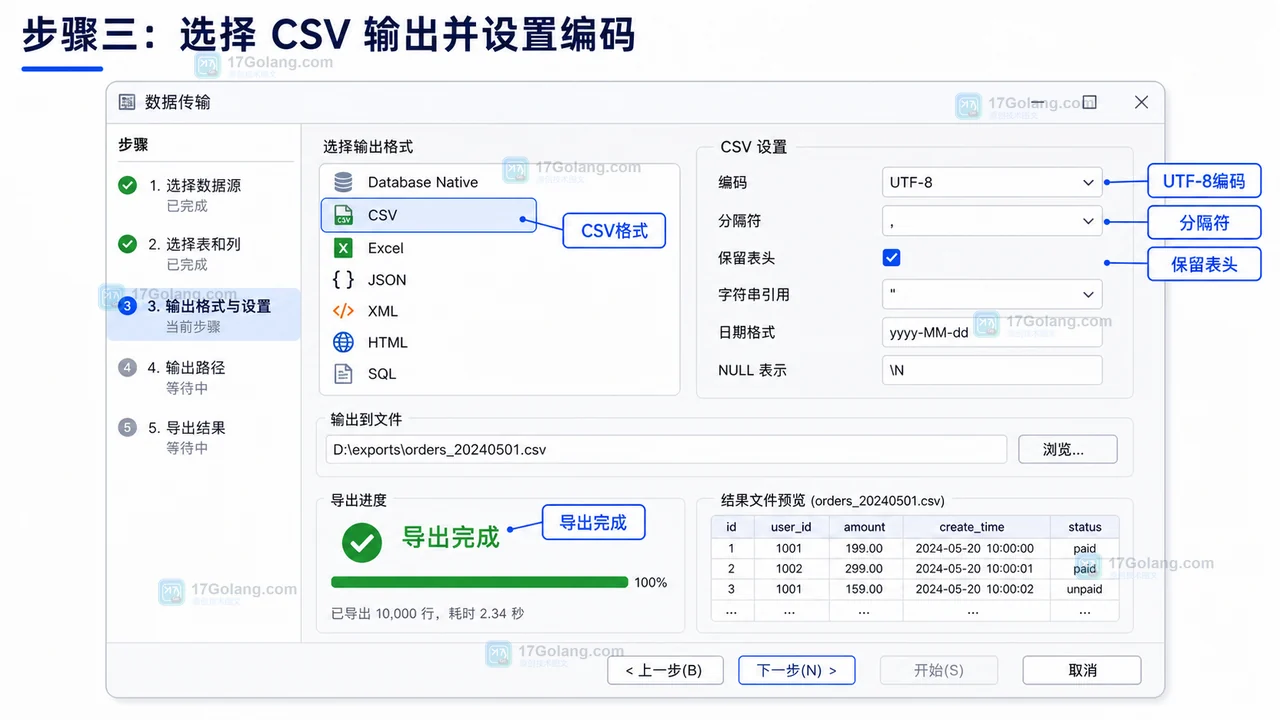
- 文章 · 软件教程 | 2星期前 | csv · 数据库工具 · dbeaver · 软件教程 · 数据导出 · SQL Editor 查询结果 CSV导出 DBeaver Data Transfer
- DBeaver 导出查询结果为 CSV:从结果集到编码检查
- 366浏览 收藏
-
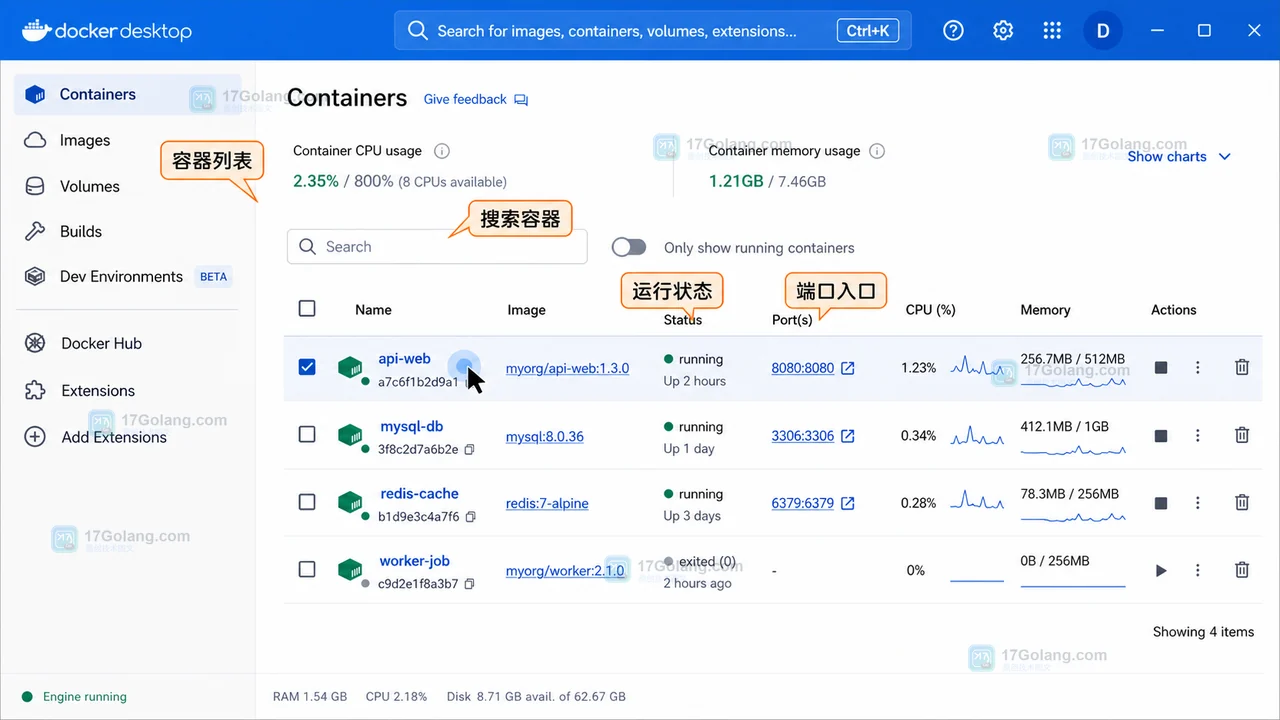
- 文章 · 软件教程 | 2星期前 | 软件教程 · Docker Desktop · 容器排查 · 日志查看 · 软件教程 Debug 容器日志 Docker Desktop Containers
- Docker Desktop 查看容器日志教程:定位异常容器、筛错误和 Debug 排查
- 422浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4372次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4052次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4037次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4222次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4190次使用
-
- Windows 11 如何开启 HEIF 图片支持
- 2026-05-31 501浏览
-
- TikTok用户画像与付费订阅变现方法
- 2026-05-27 501浏览
-
- 学信网学历翻译件申请方法
- 2026-05-27 501浏览
-
- Windows 11 24H2 更新失败0x80070005解决方法
- 2026-05-26 501浏览
-
- 微信关闭自动下载照片视频方法
- 2026-05-25 501浏览


