Pandas分段技巧:pd.cut使用详解
想要高效处理 Pandas DataFrame 中的数值分段?本文将深入解析 `pd.cut` 函数的强大功能与灵活应用。通过自定义分界点(`bins`)、调整区间开闭规则(`right` 参数)以及设定个性化标签(`labels`),`pd.cut` 助你轻松实现数据分箱,避免手动编写复杂且易错的逻辑判断。无论是将销售额划分为不同等级,还是将年龄进行分组,`pd.cut` 都能以简洁、高效的方式完成任务,尤其适用于创建如 `x

在数据分析和预处理中,经常需要将连续的数值数据离散化,即将其划分为不同的区间或类别。例如,将销售额划分为“低”、“中”、“高”三个等级,或者将年龄划分为“儿童”、“青少年”、“成年”等组。手动编写一系列的if-elif条件判断虽然可以实现这一目标,但当区间复杂、数据量大或需要动态调整时,这种方法会变得冗长、易错且难以维护。Pandas库提供了pd.cut函数,专为解决此类问题而设计,它提供了一种简洁、高效且鲁棒的方式来执行数值分箱操作。
pd.cut 函数概述
pd.cut函数用于将数值数据划分为离散的区间。它接受一个一维数组(Series或list-like)作为输入,并根据指定的分界点(bins)将其划分为不同的类别。其核心优势在于能够灵活定义分界点和区间标签,并处理各种边界情况。
核心参数详解
pd.cut函数有几个关键参数,理解它们对于正确使用该函数至关重要:
bins:定义分界点 这是pd.cut最重要的参数,它决定了如何划分数据。
- 整数: 如果bins是一个整数,pd.cut将数据范围等宽地划分为指定数量的区间。例如,bins=4会将数据从最小值到最大值等分为4个区间。
- 序列(list-like): 如果bins是一个数值序列(如列表或NumPy数组),则这些数值将被用作区间的边界。例如,bins=[0, 15000, 30000, 45000]将创建三个区间:[0, 15000)、[15000, 30000)和[30000, 45000)(具体开闭取决于right参数)。这是实现自定义区间划分的关键。
right:区间开闭规则 这是一个布尔值,默认为True。
- right=True: 表示区间是右闭合的,即(a, b]。例如,bins=[0, 10, 20]会生成(0, 10]和(10, 20]这样的区间。
- right=False: 表示区间是右开的,即[a, b)。例如,bins=[0, 10, 20]会生成[0, 10)和[10, 20)这样的区间。这在需要明确排除上限值,或在多个区间中避免重复包含边界值时非常有用。
labels:自定义区间标签 此参数允许您为每个生成的区间分配有意义的名称。
- 如果labels是一个列表或数组,其长度必须比bins的数量少1(因为bins定义了边界,而标签对应的是区间)。
- 如果未指定labels,pd.cut将自动生成默认的区间表示,例如(0, 15000], (15000, 30000]等。
include_lowest:包含最小值 这是一个布尔值,默认为False。
- 当right=True时,如果include_lowest=True,则第一个区间的左边界(最小值)将被包含在内,形成[a, b]。
- 当right=False时,如果include_lowest=True,则第一个区间的左边界(最小值)将被包含在内,形成[a, b)。这对于确保数据中的最小值被正确归类到第一个区间非常有用。
实战示例
假设我们有一个包含数值列的DataFrame,我们希望将其划分为以下区间:x < 15000、x >= 15000 and x < 30000、x >= 30000 and x < 45000。
import pandas as pd
import numpy as np
# 示例数据
data = [18511.18, 82000.0, 16313.97, 24771.96, 10930.93, 22163.14, 16586.07, 15766.2, 2953.53, 912.1,
531.77, 6509.83, 8634.2, 10181.41, 1495.26, 6555.12, 10523.55, 22200.0, 20230.0, 18400.0,
17999.56, 15807.29, 4794.6, 3679.48, 5667.89, 5296.92, 4848.96, 5997.53, 3286.98, 13258.53,
15400.0, 10614.2, 12235.0, 2953.35, 9699.54, 14880.0, 6295.46, 10170.0, 6824.8, 4177.87,
3005.95, 15186.45, 7649.42, 2432.2, 3081.8, 9065.42, 6033.63, 658.68, 12310.0, 650.73,
2767.09, 9770.0, 6246.9, 2175.46, 2381.98, 12460.0, 1957.37, 2613.85, 2407.9, 4744.32,
4415.23, 2143.3, 1141.28, 2000.38, 1676.95, 1377.39, 54.08, 6864.97, 81.56, 96.68,
7583.0, 408.29, 1735.16, 272.49, 157.79, 689.56, 3586.12, 241.66, 103.98, 5620.0,
411.42, 387.96, 815.18, 536.82, 3019.5, 160.92, 315.58, 256.23, 7063.96, 10200.0,
244.01, 6199.32, 936.79, 5838.78, 8070.0, 8760.7, 4334.65, 2646.84, 900.38, 5197.19,
5450.15, 5447.3, 4961.8, 2266.28, 1675.23, 6029.51, 2066.14, 4616.34, 1437.3, 4819.49,
4470.0, 1860.66, 4040.11, 1502.95, 467.3, 251.98, 3200.53, 1499.83, 459.38, 4862.74,
2171.43, 1237.1, 2067.19, 1202.94, 3830.47, 4228.93, 6100.0, 1229.15, 3513.0, 3050.0,
3910.0, 510.05, 5201.09, 962.85, 603.92, 1237.42, 63.72, 2613.54, 319.45, 5415.0,
1425.98, 5518.09, 3646.13, 2269.72, 2804.19, 1747.12, 2646.87, 284.56, 2135.46, 3602.5,
4965.06, 508.76, 141.52, 214.94, 4320.0, 259.0, 295.75, 4955.0, 1379.58, 3730.45,
6000.0, 523.05, 1310.22, 842.35, 3319.75, 2674.75, 141.2, 1877.21, 389.7, 5547.56,
1030.0, 1206.64, 135.52, 1770.2, 4840.0, 687.53, 3412.44, 2972.23, 864.67, 3735.4,
1135.16, 669.1, 501.3, 160.23, 200.19, 1015.28, 1100.0, 244.32, 496.95, 3209.62,
1920.15, 1815.75, 2611.77, 2176.35, 1683.95, 4945.8, 781.36, 4005.25, 553.72, 514.29]
df = pd.DataFrame({"numerical_variable": data})
# 定义分界点和标签
# 注意:bins的第一个值应小于或等于数据最小值,最后一个值应大于或等于数据最大值
# 为了覆盖 x < 15000,我们将起始点设为0(或更小)
bins = [0, 15000, 30000, 45000, np.inf] # 使用np.inf表示正无穷,确保所有大于45000的值被捕获
labels = [
"x < 15000",
"x >= 15000 and x < 30000",
"x >= 30000 and x < 45000",
"x >= 45000" # 新增一个区间来覆盖大于45000的值
]
# 使用pd.cut进行分箱
# right=False 表示区间是左闭右开 [a, b)
# include_lowest=True 确保最小值(0)被包含在第一个区间内
df['FASCIA_IMPORTO'] = pd.cut(
df['numerical_variable'],
bins=bins,
right=False,
labels=labels,
include_lowest=True # 确保数据中的最小值(例如,1)被包含在第一个区间 [0, 15000) 中
)
# 查看结果
print(df.head(10))
print("\n各区间分布统计:")
print(df['FASCIA_IMPORTO'].value_counts().sort_index())示例输出(部分):
numerical_variable FASCIA_IMPORTO 0 18511.18 x >= 15000 and x < 30000 1 82000.00 x >= 45000 2 16313.97 x >= 15000 and x < 30000 3 24771.96 x >= 15000 and x < 30000 4 10930.93 x < 15000 5 22163.14 x >= 15000 and x < 30000 6 16586.07 x >= 15000 and x < 30000 7 15766.20 x >= 15000 and x < 30000 8 2953.53 x < 15000 9 912.10 x < 15000 各区间分布统计: FASCIA_IMPORTO x < 15000 167 x >= 15000 and x < 30000 12 x >= 30000 and x < 45000 0 x >= 45000 1 Name: count, dtype: int64
从输出可以看出,即使存在某个区间(如x >= 30000 and x < 45000)在当前数据集中为空,pd.cut也能正确处理,并将其计数显示为0,而不会导致代码中断。
pd.cut 的优势与注意事项
优势:
- 简洁与可读性: 相较于复杂的if-elif链,pd.cut一行代码即可完成分箱,大大提高了代码的简洁性和可读性。
- 鲁棒性: pd.cut内置了对各种边界情况和空区间的处理机制。当某个区间没有数据时,它会优雅地返回一个空类别,而不是引发错误,这避免了手动逻辑中常见的max()或min()在空Series上失败的问题。
- 效率: 对于大型数据集,pd.cut通常比基于循环或apply的自定义函数更高效,因为它在底层使用了优化的C实现。
- 灵活性: 通过bins、right、labels等参数的组合,可以满足几乎所有自定义分箱的需求。
注意事项:
- bins的完整性: 确保bins序列覆盖了数据的所有可能范围。如果数据中存在小于第一个bin边界或大于最后一个bin边界的值,它们将被分配为NaN(除非通过include_lowest或扩展bins来处理)。在上述示例中,我们使用了0作为起始点和np.inf作为终点,以确保所有数据都被包含。
- right参数的选择: 根据实际业务需求(是包含左边界还是右边界)正确设置right参数。例如,[10, 20)表示10包含在内,20不包含;(10, 20]表示10不包含,20包含。
- labels与bins的数量: labels的数量必须比bins的数量少1。例如,5个bins定义了4个区间,因此需要4个labels。
- 处理NaN值: 默认情况下,pd.cut会将输入数据中的NaN值也映射为NaN。如果需要对NaN进行特殊处理(例如填充或单独归类),应在调用pd.cut之前进行。
总结
pd.cut是Pandas库中一个强大且实用的工具,它极大地简化了数值数据分箱的任务。通过灵活配置bins、right和labels等参数,用户可以轻松地将连续数据转换为有意义的离散类别,从而为后续的数据分析和建模提供便利。掌握pd.cut的使用,能够显著提升数据处理的效率和代码的健壮性。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
 最新欧美电影网站推荐免费在线观看入口
最新欧美电影网站推荐免费在线观看入口
- 上一篇
- 最新欧美电影网站推荐免费在线观看入口

- 下一篇
- Excel智能编号技巧:4种自动序列方法
-
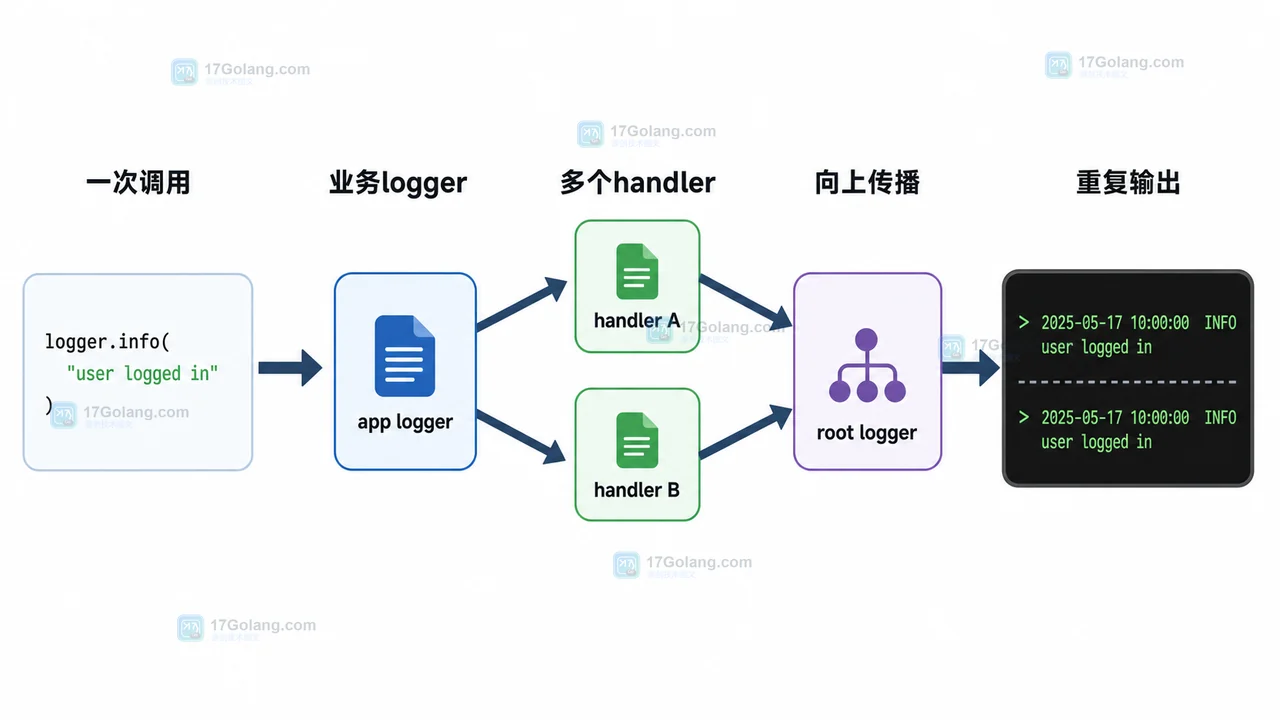
- 文章 · python教程 | 1星期前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig
- Python logging 日志重复打印排查:为什么一条记录输出了两遍
- 324浏览 收藏
-

- 文章 · python教程 | 2星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory
- Python dataclass 默认值完整工作流:从可变默认值到 default_factory
- 228浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4133次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 3844次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 3824次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4004次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3979次使用
-
- Python监控网页状态:requests异常处理实战
- 2026-05-29 501浏览
-
- TensorFlow模型部署为API的TF Serving方法
- 2026-05-26 501浏览
-
- Python字符串编码转换:encode与decode详解
- 2026-05-16 501浏览
-
- TensorFlow裁剪无用算子方法详解
- 2026-05-15 501浏览
-
- httpx 如何设置代理认证(Proxy-Authorization)
- 2026-05-05 501浏览


