Spring单例Bean内存优化技巧分享
本文深入探讨了Spring单例Bean的内存管理与优化,尤其是有状态单例Bean可能带来的内存消耗问题。**Spring单例Bean**的生命周期与应用上下文一致,虽无状态Bean内存占用小,但有状态Bean若持有大量数据,则可能导致内存压力。文章重点介绍了通过引入**缓存机制**并设置**过期策略**来优化内存使用,例如利用Spring的缓存抽象或集成Caffeine、Guava等**内存缓存库**,实现数据的按需加载与及时释放。通过有效管理有状态单例Bean内部的动态数据,避免不必要的内存驻留,从而提升Spring应用的性能和稳定性,是解决**Spring内存优化**的关键。本文旨在帮助开发者更好地理解和应用这些技巧,确保**Spring应用性能**达到最佳状态。

Spring单例Bean的生命周期与内存特性
在Spring框架中,singleton是默认的Bean作用域,意味着在每个Spring IoC容器中,只存在一个指定Bean定义的实例。当Spring应用启动并初始化其应用上下文时,所有单例Bean都会被创建并加载到容器中。这些Bean实例将驻留在内存中,并伴随整个应用上下文的生命周期,直至应用关闭或上下文销毁。
对于Spring单例Bean的内存占用,需要区分两种情况:
无状态(Stateless)单例Bean: 这类Bean通常不持有任何可变实例变量,其方法执行不依赖于任何内部状态,例如服务层(Service)或数据访问层(DAO)的接口实现。由于它们仅包含方法逻辑,不存储大量数据,因此这类Bean实例本身的内存占用通常非常小,对应用的整体内存消耗影响微乎其微。JVM能够高效管理数百万个小型对象。
有状态(Stateful)单例Bean: 这类Bean内部持有可变的实例变量,例如缓存数据、用户会话信息或其他随时间变化的数据结构。内存消耗的主要因素并非Bean实例本身的大小,而是其内部维护的“状态”数据量。如果这些状态数据持续增长且未得到有效管理,即使Bean实例是单例的,其内部数据也可能导致显著的内存压力,甚至引发内存溢出。
因此,问题的核心不在于单例Bean实例本身是否会被垃圾回收,因为它们将始终存在于应用上下文中;而在于如何有效管理有状态单例Bean内部所持有的动态数据,使其在不再需要时能够被垃圾回收。
有状态单例Bean的内存优化策略
既然单例Bean实例本身无法在应用运行时被“释放”以供垃圾回收,那么我们的优化重点就应放在其内部维护的“状态”数据上。最常见的策略是引入缓存机制并设置过期策略。
1. 基于Spring Cache抽象的内存管理
Spring框架提供了强大的缓存抽象,允许开发者以声明式的方式为方法添加缓存功能。结合外部缓存库(如Caffeine、Ehcache等),可以轻松实现数据的按需加载和自动过期清理。
配置步骤:
引入缓存依赖: 以Caffeine为例,在pom.xml中添加:
org.springframework.boot spring-boot-starter-cache com.github.ben-manes.caffeine caffeine 启用缓存: 在Spring Boot主应用类或配置类上添加@EnableCaching注解。
import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCaching; @SpringBootApplication @EnableCaching public class MyApplication { public static void main(String[] args) { SpringApplication.run(MyApplication.class, args); } }配置Caffeine缓存管理器: 在application.properties或application.yml中配置缓存策略:
spring.cache.type=caffeine spring.cache.cache-names=myCache spring.cache.caffeine.spec=maximumSize=1000,expireAfterWrite=60s
这里配置了一个名为myCache的缓存,最大容量1000条,写入后60秒过期。
在Bean中使用缓存注解:
import org.springframework.cache.annotation.CacheEvict; import org.springframework.cache.annotation.Cacheable; import org.springframework.stereotype.Service; import java.util.HashMap; import java.util.Map; import java.util.concurrent.TimeUnit; @Service public class DataService { private Map通过@Cacheable注解,getData方法的返回结果会被缓存。当缓存中的数据过期或被@CacheEvict清除时,这部分数据就可以被JVM垃圾回收,从而释放内存。
2. 直接集成内存缓存库
如果Spring Cache抽象无法满足特定需求,或者希望更细粒度地控制缓存行为,可以直接在单例Bean中集成Caffeine、Guava Cache等高性能内存缓存库。
以Caffeine为例:
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
@Service
public class DirectCacheService {
private final Cache dataCache;
private final AtomicLong cacheMissCounter = new AtomicLong(0);
public DirectCacheService() {
// 构建Caffeine缓存实例
this.dataCache = Caffeine.newBuilder()
.maximumSize(10_000) // 最大缓存条目数
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.recordStats() // 开启统计功能
.build();
}
public String getCachedData(String key) {
// 尝试从缓存获取数据
String value = dataCache.getIfPresent(key);
if (value == null) {
// 缓存未命中,从数据源加载
cacheMissCounter.incrementAndGet();
System.out.println("Cache miss for key: " + key + ". Loading from source...");
value = loadDataFromSource(key); // 模拟从数据库或外部服务加载
dataCache.put(key, value); // 将数据放入缓存
} else {
System.out.println("Cache hit for key: " + key + ".");
}
return value;
}
private String loadDataFromSource(String key) {
// 模拟实际的数据加载逻辑
try {
TimeUnit.MILLISECONDS.sleep(100); // 模拟耗时操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "LoadedValueFor_" + key;
}
public void invalidateCache(String key) {
dataCache.invalidate(key);
System.out.println("Invalidated cache for key: " + key);
}
public void invalidateAllCache() {
dataCache.invalidateAll();
System.out.println("Invalidated all cache entries.");
}
public long getCacheMisses() {
return cacheMissCounter.get();
}
public com.github.benmanes.caffeine.cache.stats.CacheStats getCacheStats() {
return dataCache.stats();
}
} 这种方式给予了开发者更大的灵活性,可以根据业务需求自定义缓存的加载、驱逐、统计等行为。当缓存中的数据因为过期或容量限制被驱逐时,这些数据对象将不再被缓存引用,从而有机会被垃圾回收。
注意事项与最佳实践
- 单例Bean实例的不可释放性: 再次强调,单例Bean实例本身在应用上下文生命周期内是不会被垃圾回收的。我们所做的优化是针对其内部持有的动态数据。
- 选择合适的缓存策略:
- 过期策略: 根据数据的时效性选择合适的过期时间(expireAfterAccess访问后过期,expireAfterWrite写入后过期)。
- 容量限制: 设置合理的maximumSize或maximumWeight,防止缓存无限增长。
- 驱逐策略: 了解缓存库的默认驱逐策略(如LRU、LFU),并根据访问模式进行调整。
- 并发安全: 如果缓存中存储的对象是可变的,需要确保多线程访问时的并发安全。Caffeine和Guava Cache本身是线程安全的,但如果缓存的值是自定义的可变对象,则需要自行处理其内部状态的线程安全问题。
- 内存监控与性能分析: 即使采用了缓存,也应定期监控应用的内存使用情况(如通过JMX、VisualVM等工具),分析GC日志,确保内存优化达到了预期效果,并及时发现潜在的内存泄漏。
- 谨慎使用prototype作用域: 虽然prototype作用域的Bean每次请求都会创建新实例,并在不再被引用时被垃圾回收,但它与用户希望“只存在一个实例”的需求相悖。如果业务确实需要管理大量短生命周期的、独立的有状态对象,且不希望它们被缓存,那么prototype可能是一个选择,但这通常意味着需要重新评估业务模型和数据生命周期管理。
总结
Spring单例Bean在应用启动时创建并常驻内存。对于无状态的单例Bean,其内存开销微不足道。然而,对于有状态的单例Bean,其内部维护的数据才是内存消耗的关键。为了有效管理这部分内存,推荐采用带有过期策略的缓存机制。无论是利用Spring的缓存抽象,还是直接集成如Caffeine、Guava等高性能内存缓存库,核心目标都是在数据不再活跃或达到生命周期终点时,使其脱离强引用,从而允许JVM进行垃圾回收,实现内存的动态优化,确保应用高效稳定运行。
今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 Excel高级筛选使用教程详解
Excel高级筛选使用教程详解
- 上一篇
- Excel高级筛选使用教程详解

- 下一篇
- MySQL入门到精通:SQL语法全收录
-
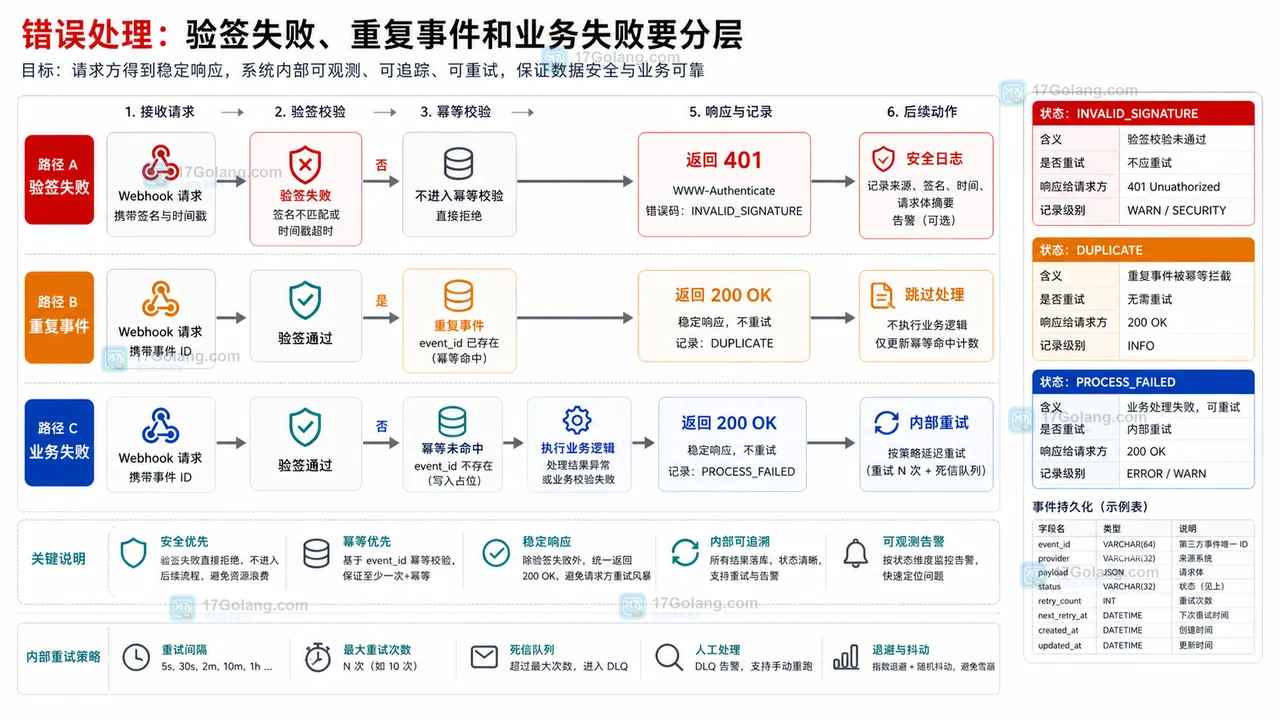
- 文章 · java教程 | 17小时前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签
- Java Webhook 回调接收接口设计:验签、幂等和状态流转
- 488浏览 收藏
-
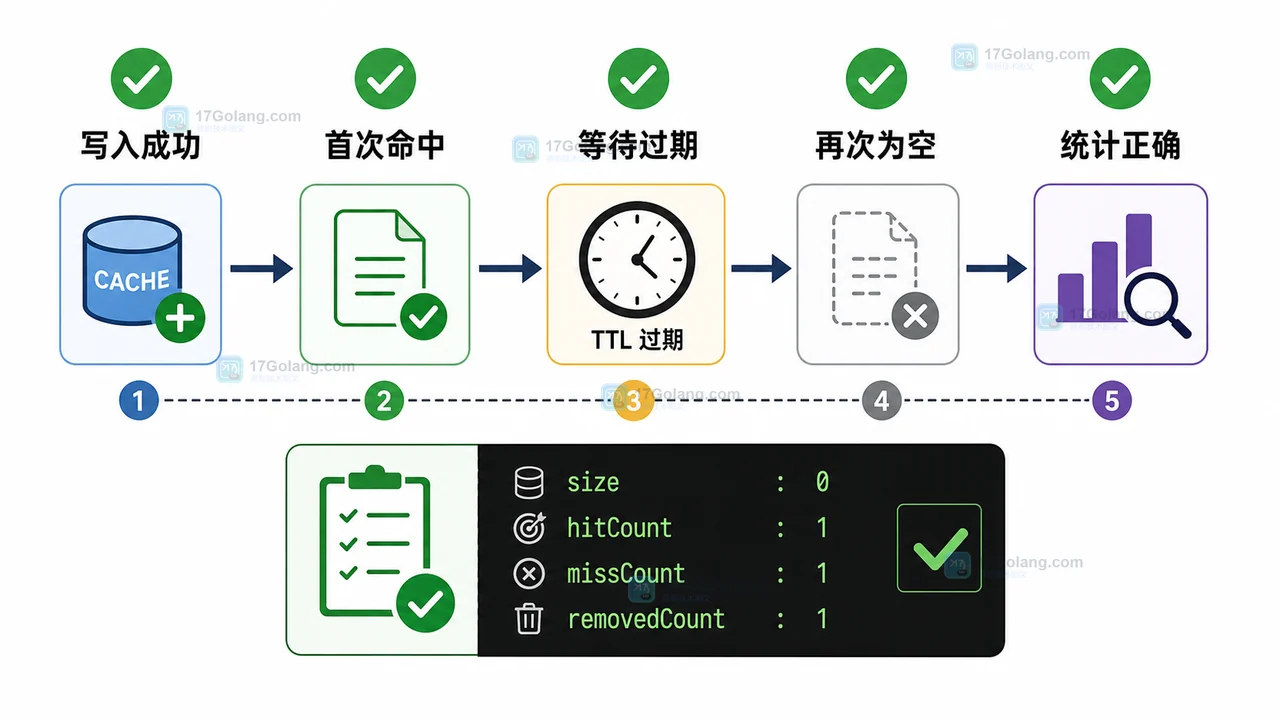
- 文章 · java教程 | 2天前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
- Java 本地 TTL 缓存小项目:用 ConcurrentHashMap 实现过期淘汰和命中统计
- 394浏览 收藏
-
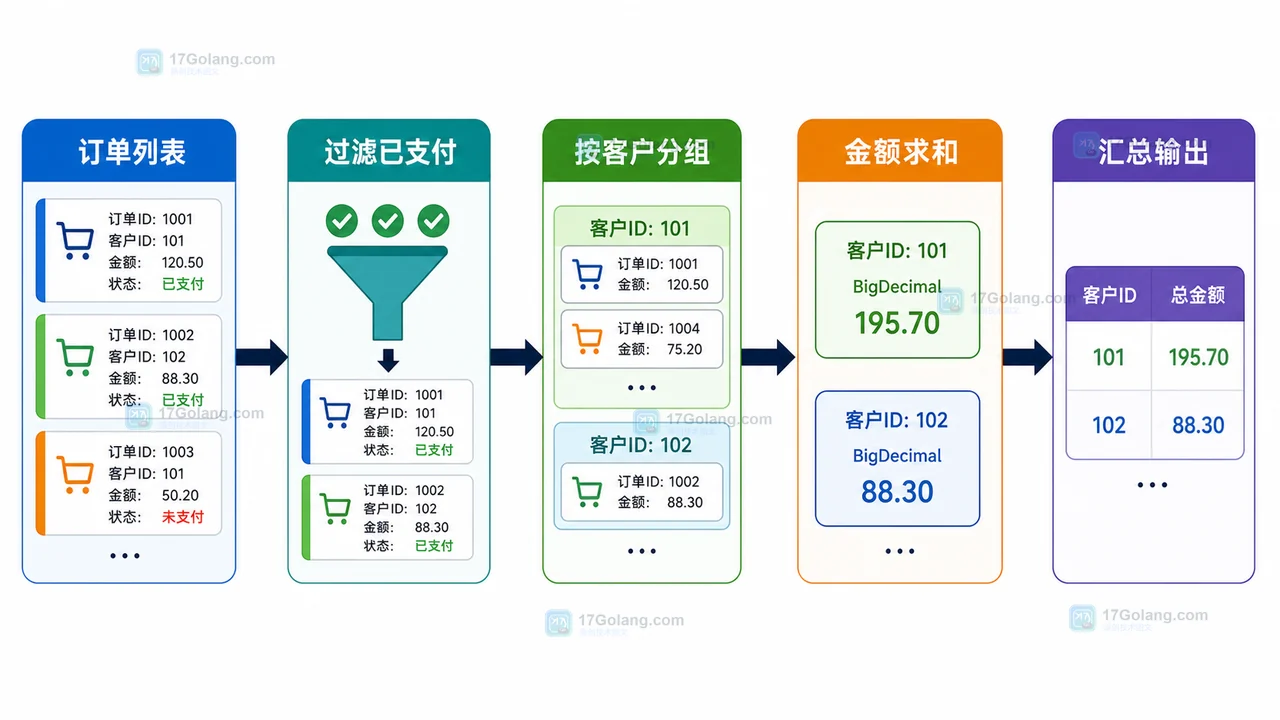
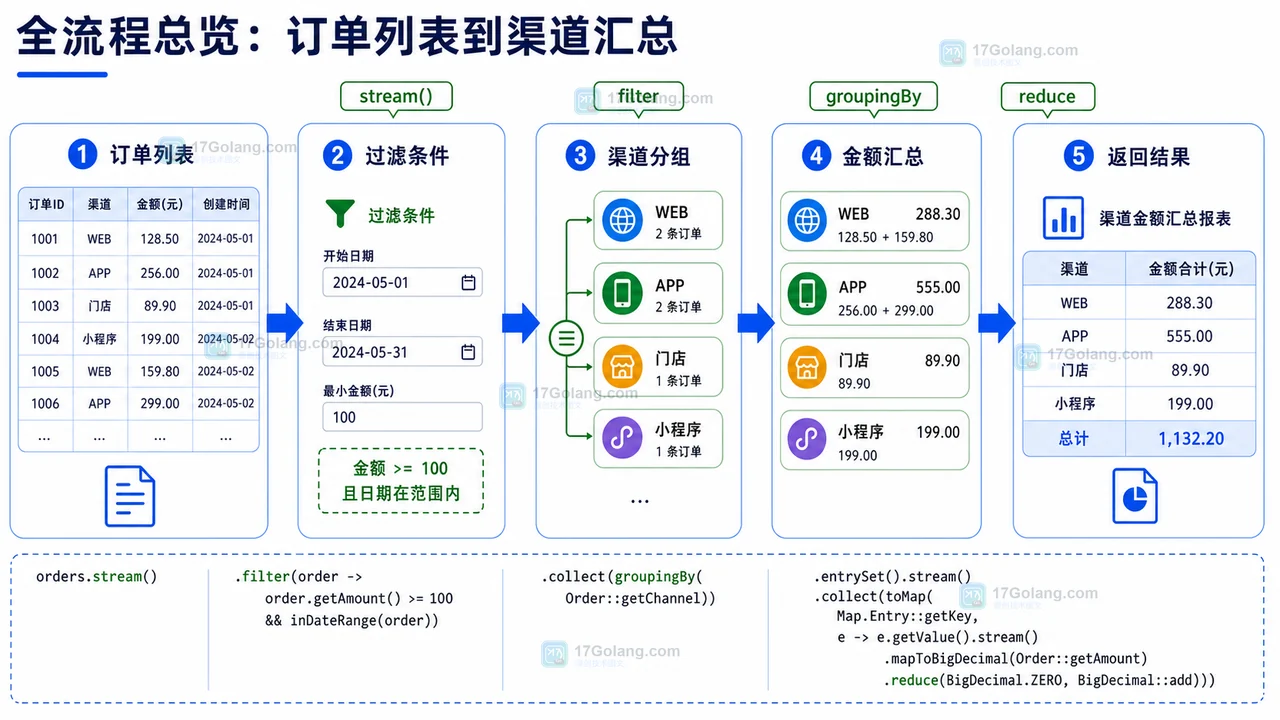
- 文章 · java教程 | 2天前 | Java · Stream · 数据处理 · 后端教程 · Java Stream bigdecimal 分组统计 Collectors 订单汇总
- Java Stream 分组统计实验:从订单列表到客户消费汇总
- 355浏览 收藏
-
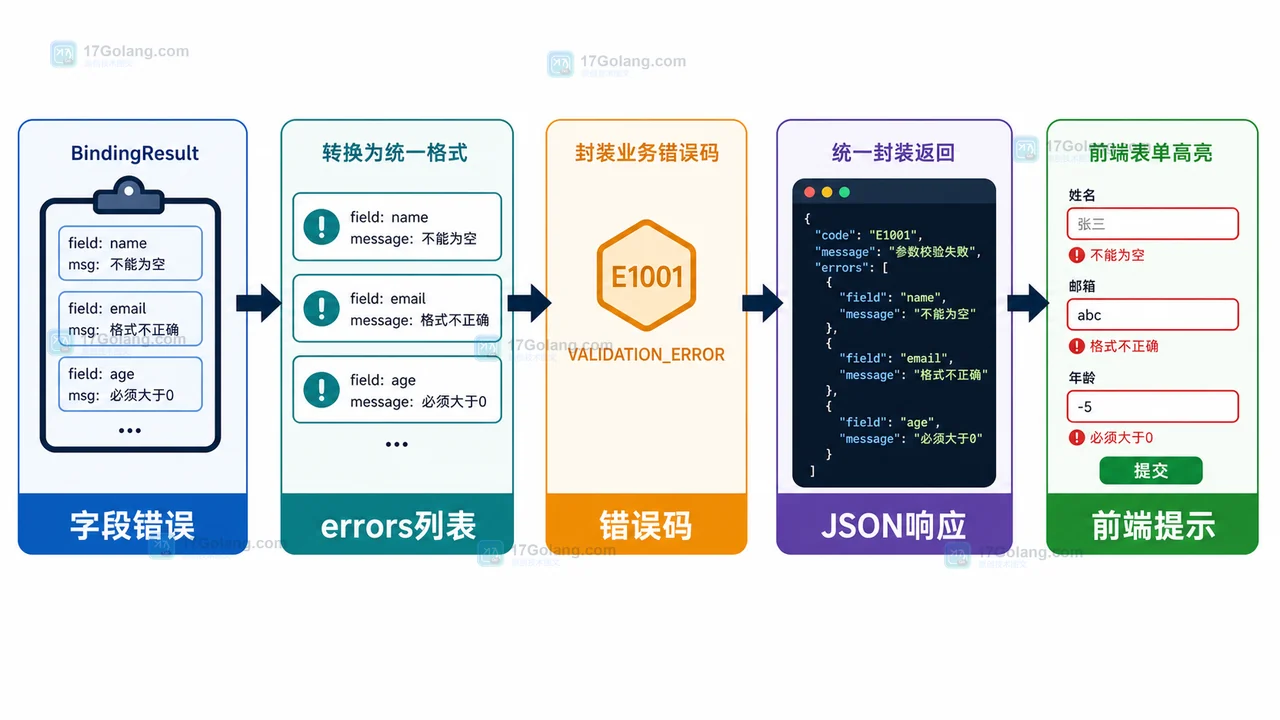
- 文章 · java教程 | 2天前 | Java · Spring Boot · 后端开发 · 接口校验 · java spring boot dto 接口设计 参数校验
- Spring Boot 参数校验工作流:DTO、注解和统一错误响应
- 495浏览 收藏
-
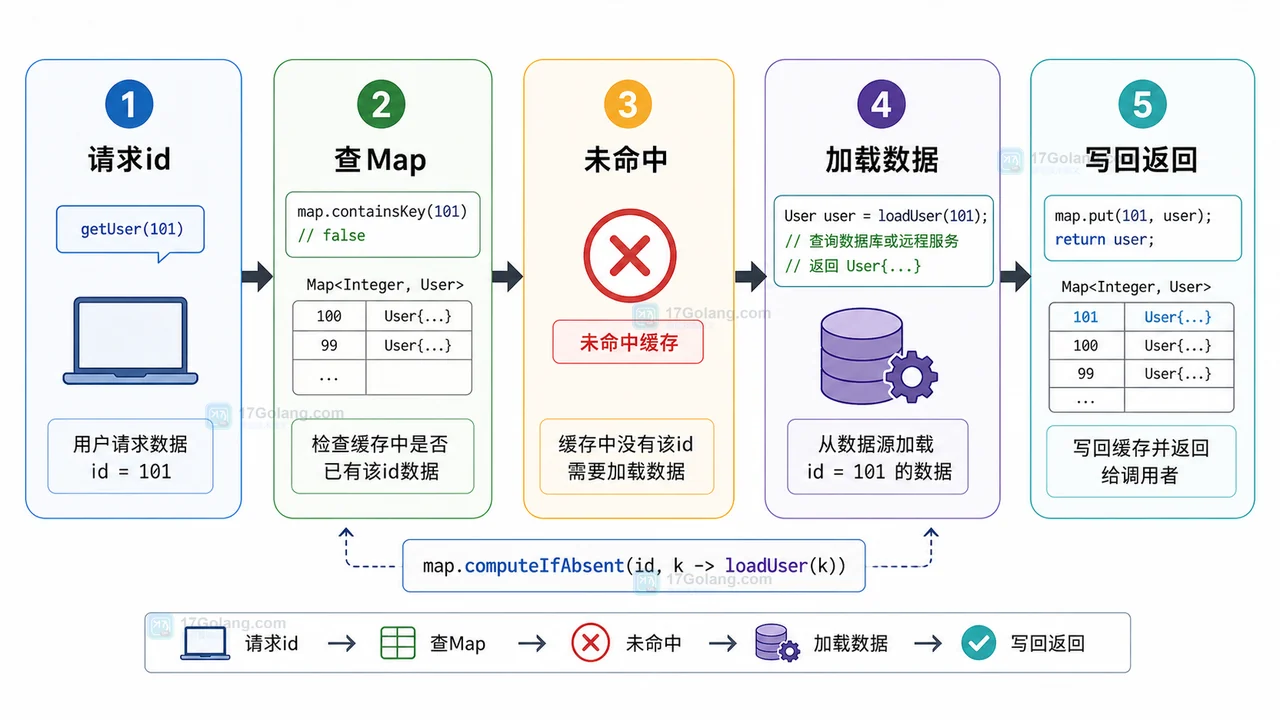
- 文章 · java教程 | 1星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-
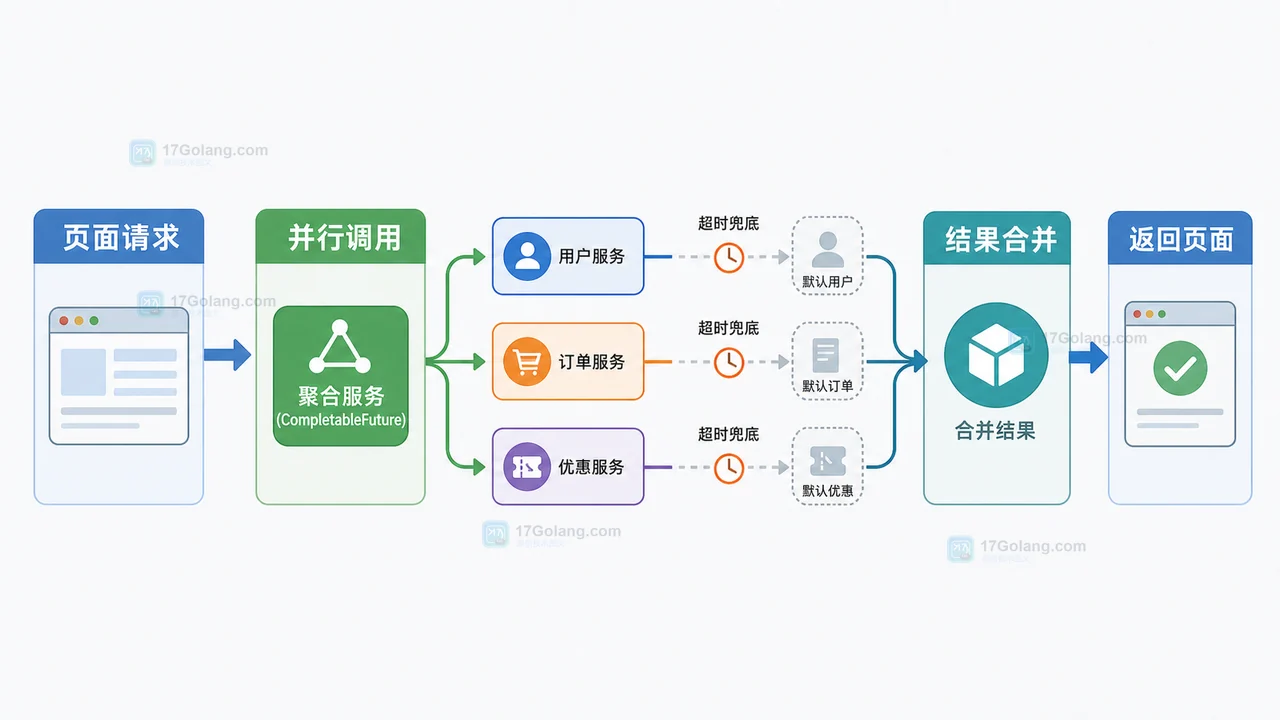
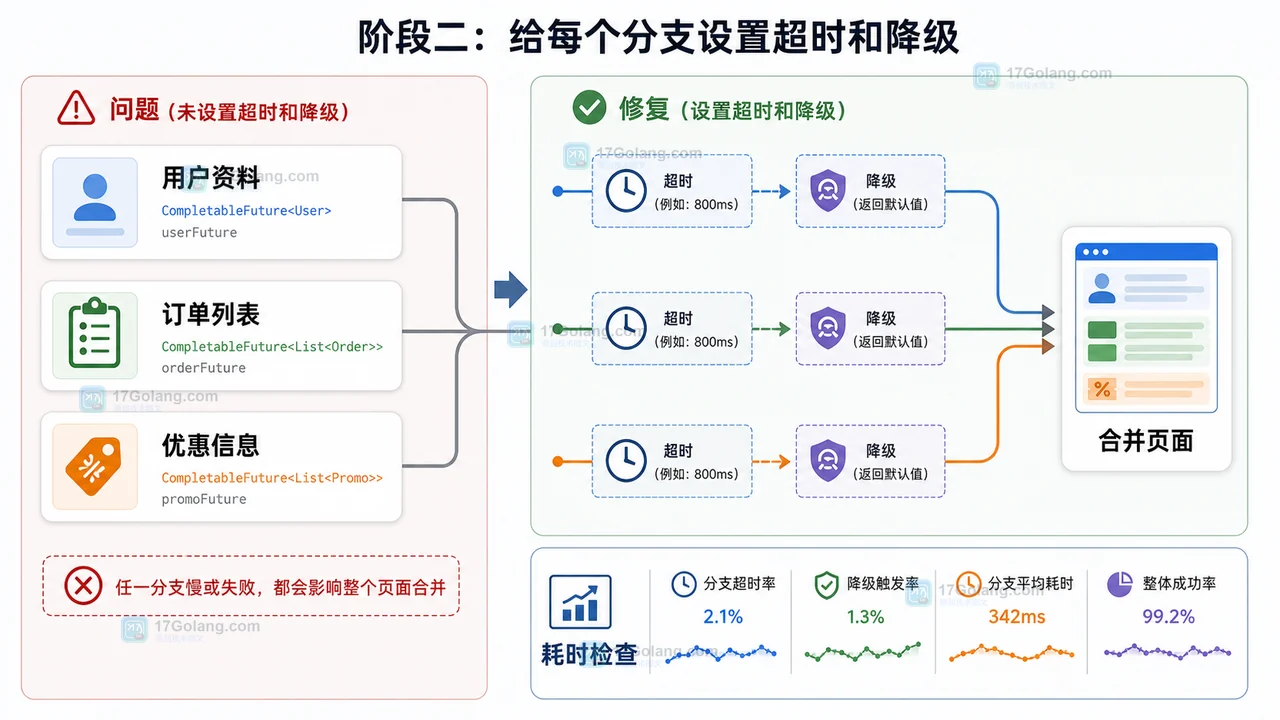
- 文章 · java教程 | 2星期前 | Java · 异步编程 · 后端开发 · CompletableFuture · 接口聚合 · java 结果合并 completablefuture 并行调用 超时兜底
- Java CompletableFuture 多接口聚合完整流程:并行调用、超时兜底和结果合并
- 428浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2913次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2698次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2628次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2865次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2804次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


