Java日志记录教程:代码使用指南
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《Java日志记录实用教程:代码应用指南》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下,希望所有认真读完的童鞋们,都有实质性的提高。
不应只用System.out.println()是因为它缺乏日志级别控制、无法灵活配置输出目标、存在性能开销、无法自动记录上下文信息且维护性差;2. 应使用SLF4J作为日志门面,搭配Logback(适用于大多数项目)或Log4j2(适用于高吞吐量场景)以实现解耦、高性能和可配置的日志系统;3. 日志配置最佳实践包括合理设置日志级别、使用参数化日志避免不必要的字符串拼接、正确记录异常堆栈、避免输出敏感信息、配置文件滚动与异步写入策略、利用MDC增强上下文追踪,并通过桥接器解决多日志框架冲突,最终实现高效、安全、可观测的日志管理。

在Java开发中,记录程序运行信息,也就是日志,是件再寻常不过但又至关重要的事情。它远不止是简单的System.out.println(),而是构建一个健壮、可观测应用的基础。通过日志,我们能追踪程序的执行路径,定位潜在问题,监控系统健康状况,甚至分析用户行为。可以说,没有一套好的日志系统,你的应用在生产环境里就是个“黑箱”,出了问题也只能抓瞎。
解决方案
要实现Java代码的日志记录,我们通常会借助成熟的日志框架。这就像是给你的程序装上了一双“眼睛”和一套“记录系统”。目前业界主流的做法是使用SLF4J作为日志门面(Facade),然后选择一个具体的实现,比如Logback或者Log4j2。
为什么是SLF4J + Logback/Log4j2?
System.out.println() 固然能输出信息,但它缺乏灵活性:你不能轻易控制输出级别(是调试信息还是错误警告?),不能把日志输出到文件、数据库或者远程服务,也无法在不修改代码的情况下调整日志格式。日志框架则完美解决了这些痛点。
SLF4J(Simple Logging Facade for Java)是一个抽象层,它定义了一套通用的日志API。你的代码只需要依赖SLF4J,而无需关心底层具体使用的是Logback、Log4j2还是其他什么日志库。这极大地提高了代码的解耦性和可维护性。当你想更换日志实现时,只需修改Maven/Gradle依赖和配置文件,而不用改动一行业务代码。
以SLF4J + Logback为例,实现日志记录的基本步骤:
添加依赖: 在你的
pom.xml(Maven)或build.gradle(Gradle)中引入SLF4J API和Logback实现。org.slf4j slf4j-api 1.7.30 ch.qos.logback logback-classic 1.2.3 创建配置文件: Logback默认会在classpath下查找
logback.xml、logback-test.xml或logback.groovy。我们通常在src/main/resources目录下创建一个logback.xml文件。一个简单的
logback.xml配置示例:%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n logs/my-app.log logs/my-app.%d{yyyy-MM-dd}.log 30 %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n 在代码中使用Logger:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyService { // 推荐将Logger声明为静态final,并使用当前类名作为Logger名称 private static final Logger logger = LoggerFactory.getLogger(MyService.class); public void processOrder(String orderId, double amount) { // TRACE: 最详细的日志,一般用于追踪方法内部执行的每一个步骤 logger.trace("Entering processOrder method for orderId: {}", orderId); if (amount <= 0) { // DEBUG: 调试信息,开发阶段常用,生产环境可能关闭 logger.debug("Invalid amount detected: {}", amount); // WARN: 警告信息,可能存在问题,但不影响程序正常运行 logger.warn("Order {} has an invalid amount: {}. Processing might be affected.", orderId, amount); return; } try { // INFO: 关键业务流程信息,记录程序正常运行状态 logger.info("Processing order: {} with amount: {}", orderId, amount); // 模拟业务逻辑 Thread.sleep(100); logger.info("Order {} processed successfully.", orderId); } catch (InterruptedException e) { // ERROR: 错误信息,程序出现异常,影响正常功能 logger.error("Failed to process order {}. An unexpected interruption occurred.", orderId, e); // 异常处理时,务必将异常对象作为最后一个参数传入,以便日志框架打印堆栈信息 } catch (Exception e) { logger.error("An unknown error occurred while processing order {}.", orderId, e); } } public static void main(String[] args) { MyService service = new MyService(); service.processOrder("ORD123", 100.50); service.processOrder("ORD456", -5.00); } }
通过以上步骤,你的Java应用就能开始输出结构化、可配置的日志信息了。这比简单的println不知道高到哪里去了。
为什么我们不应该只用System.out.println()来调试和记录?
很多人在初学Java时,习惯用System.out.println()来输出一些变量值或者判断程序执行到了哪里。这在写一些小程序或者快速验证逻辑时确实方便,但一旦项目稍微复杂一点,或者需要部署到生产环境,它的局限性就暴露无遗了。
想象一下,如果你的应用部署在服务器上,用户反馈一个问题,你总不能直接去服务器的控制台看输出吧?即便能看,控制台的输出是混杂的,各种信息一股脑地涌出来,你很难分辨哪些是错误,哪些是警告,哪些是正常信息。
System.out.println()最致命的几个缺点在于:
- 缺乏日志级别: 所有的输出都是一样的,没有“调试”、“信息”、“警告”、“错误”之分。你无法在生产环境中轻松地关闭调试信息,只保留错误和警告。
- 无法配置输出目标: 它只能输出到标准输出流(通常是控制台)。你没办法让它把日志写到文件里,或者发送到远程日志收集系统(比如ELK Stack、Splunk)。
- 性能开销: 每次调用
println都会涉及到IO操作,这在I/O密集型操作中可能会成为性能瓶颈。而且,即使你不需要看某条日志,它也照样会执行字符串拼接并输出,无法像日志框架那样根据级别动态判断是否输出。 - 缺乏上下文信息:
println输出的只有你给的字符串。它不会自动告诉你这条日志是哪个类、哪个方法、哪个线程在什么时候发出的,也无法自动带上请求ID等上下文信息。 - 维护性差: 当你需要调整日志策略时(比如从控制台输出改为文件输出),你不得不修改所有
println的地方,这简直是噩梦。
而日志框架,从设计之初就考虑到了这些问题,提供了灵活的配置、分级的输出、多种输出目标、异步写入等高级功能,让日志管理变得高效且可控。
如何选择合适的Java日志框架?SLF4J、Logback还是Log4j2?
在Java的日志生态系统中,选择一个合适的框架确实会让一些初学者感到困惑,因为名字听起来都差不多。但其实,它们各自扮演着不同的角色,或者说,代表着不同的演进方向。
SLF4J (Simple Logging Facade for Java):日志门面
它不是一个具体的日志实现,而是一个抽象层,一套API规范。你可以把它理解为一个“接口”。你的应用程序代码只需要依赖SLF4J的API,然后通过配置,在运行时将这个接口“绑定”到具体的日志实现(如Logback、Log4j2)。
- 优点:
- 解耦: 你的业务代码不再直接依赖某个具体的日志库,切换底层实现变得轻而易举。
- 统一: 避免了项目中引入多个日志库(比如一个模块用Log4j,另一个用Logback)导致的混乱和冲突。
- 缺点: 它本身不提供日志功能,必须搭配一个具体的实现才能工作。
Logback:SLF4J的“亲儿子”,Log4j的继任者
Logback是Log4j项目的创始人Ceki Gülcü开发的,旨在作为Log4j的改进版本。它原生支持SLF4J,性能优异,内存占用低,并且提供了非常灵活的配置。
- 优点:
- 性能好: 比Log4j 1.x更快,与Log4j2相比也毫不逊色。
- 原生支持SLF4J: 配置简单,无需额外的桥接包。
- 灵活的配置: 支持XML、Groovy配置,支持条件配置,日志文件滚动策略丰富。
- 自动重新加载配置: 默认情况下,如果
logback.xml文件发生变化,Logback会自动重新加载配置而无需重启应用。
- 缺点: 在某些极端高并发、日志吞吐量巨大的场景下,其异步日志的性能可能不如Log4j2的LMAX Disruptor实现。
Log4j2:高性能的日志框架
Log4j2是Apache Log4j的最新版本,它从头开始设计,旨在解决Log4j 1.x的架构问题,并提供比Logback更优异的性能,尤其是在高并发场景下。它引入了LMAX Disruptor来实现异步日志,性能表现非常出色。
- 优点:
- 卓越的性能: 尤其是在异步日志方面,其吞吐量远超Logback和Log4j 1.x。
- 灵活的插件架构: 几乎所有组件都可以作为插件配置。
- 高级过滤: 支持更复杂的过滤器链。
- 无锁设计: 在高并发写入时减少了竞争。
- 缺点:
- 配置相对复杂: 相较于Logback,其配置文件的学习成本稍高一些。
- 依赖较多: 如果使用异步日志,需要额外引入LMAX Disruptor库。
如何选择?
- 绝大多数项目:SLF4J + Logback。 这是最推荐的组合。Logback性能足够好,配置相对简单,功能强大,对于大部分企业级应用来说绰绰有余。
- 对日志吞吐量有极致要求,或需要处理海量日志的系统:SLF4J + Log4j2。 如果你的应用每秒需要产生数万甚至数十万条日志,并且性能是首要考虑因素,那么Log4j2的异步日志会是更好的选择。
- 遗留系统: 如果是维护老旧项目,可能还会遇到Log4j 1.x或JDK自带的
java.util.logging。通常建议使用SLF4J的桥接器(bridging modules)将它们统一到SLF4J门面下,以便未来迁移。
我的个人经验是,对于新项目,通常会毫不犹豫地选择SLF4J + Logback。它提供了很好的平衡,既有出色的性能,又有易于理解和维护的配置。除非有明确的、经过压测验证的性能瓶颈出现在日志部分,才会考虑切换到Log4j2。
日志配置中常见的陷阱和最佳实践有哪些?
日志配置看着简单,但里面其实有不少“坑”和一些值得遵循的最佳实践,它们能直接影响你的应用性能、可维护性和问题排查效率。
常见的陷阱:
过度日志或日志不足:
- 过度日志: 生产环境把日志级别设为
DEBUG或TRACE,导致日志文件迅速膨胀,磁盘空间耗尽,甚至影响应用性能。这就像你把所有细枝末节的对话都录下来,结果发现根本没人听得过来。 - 日志不足: 生产环境把日志级别设得太高(比如只记录
ERROR),导致一旦出现问题,关键的上下文信息缺失,根本无法定位问题。这就像你只记录了“出事了”,但没记录“谁、在哪、怎么出的事”。
- 过度日志: 生产环境把日志级别设为
字符串拼接式日志:
logger.info("User " + userId + " logged in at " + loginTime);这种写法在日志级别低于INFO时(例如,生产环境只记录WARN及以上),依然会执行字符串拼接操作,造成不必要的性能开销。日志敏感信息: 不小心将用户密码、身份证号、银行卡号等敏感信息直接打印到日志中。这是严重的安全漏洞,可能导致数据泄露。
忽略异常: 捕获了异常(
catch (Exception e)),但仅仅是打印了一句“发生错误”,却没有将异常对象e传递给日志方法,导致无法看到完整的堆栈信息。这让问题排查变得异常困难。不合理的日志文件滚动策略: 日志文件不按大小或时间滚动,导致单个日志文件无限增大,难以打开和传输。或者滚动策略设置不当,导致旧日志被过早删除。
多个日志框架冲突(依赖地狱): 项目中不小心引入了多个日志框架的依赖(比如Log4j 1.x、Logback、JCL),导致类加载冲突,日志输出混乱或根本不输出。这在复杂的Maven/Gradle项目中尤其常见。
最佳实践:
始终使用SLF4J作为日志门面: 这一点怎么强调都不为过。它提供了统一的API,让你的代码与具体的日志实现解耦,便于未来切换和管理。
合理设置日志级别:
TRACE/DEBUG: 仅在开发环境或需要详细调试时开启。生产环境通常关闭。INFO: 记录关键业务流程的正常运行信息,例如用户登录、订单创建、重要接口调用等。这是生产环境最常用的级别。WARN: 记录可能存在问题但程序仍能继续运行的情况,例如配置缺失、资源即将耗尽、非预期但可恢复的异常。ERROR: 记录程序运行中发生的严重错误,导致功能受损或程序崩溃,需要立即关注。FATAL: 极少使用,通常表示系统不可恢复的严重错误,程序即将终止。
使用参数化日志(Parameterized Logging):
logger.info("User {} logged in at {}", userId, loginTime);这种方式只有在日志级别被激活时,才会执行参数的格式化和字符串拼接,大大提高了性能。正确记录异常:
logger.error("Error processing request for user {}.", userId, e);务必将异常对象作为最后一个参数传递给日志方法,这样日志框架才能打印完整的堆栈信息,帮助你快速定位问题。避免日志敏感数据: 在日志输出前对敏感信息进行脱敏或加密处理。可以自定义日志格式或使用MDC(Mapped Diagnostic Context)进行过滤。
配置合理的Appender和RollingPolicy:
- ConsoleAppender: 仅用于开发调试。
- RollingFileAppender: 生产环境必备,根据时间(
TimeBasedRollingPolicy)或大小(SizeBasedRollingPolicy)滚动日志文件,防止文件过大。 - AsyncAppender: 在高并发场景下,使用异步Appender可以显著提高应用性能,因为日志写入操作会放到单独的线程中执行,避免阻塞主业务线程。
- MaxHistory / MaxFileSize: 合理设置日志文件的保留数量或总大小,避免磁盘空间被日志撑爆。
利用MDC(Mapped Diagnostic Context)增加日志上下文: MDC允许你在当前线程中存储键值对,这些键值对会自动附加到该线程产生的每条日志中。这对于追踪一个请求在整个系统中的流转路径非常有用,例如记录请求ID、用户ID等。
// 在请求开始时设置MDC MDC.put("requestId", UUID.randomUUID().toString()); MDC.put("userId", "user123"); // ... 业务逻辑 ... logger.info("Processing step A."); // ... 业务逻辑 ... logger.debug("Intermediate calculation: {}", result); // 在请求结束时清除MDC MDC.clear();然后在
logback.xml的pattern中加入%X{requestId}和%X{userId}即可。考虑集中式日志管理: 当应用部署在多台服务器上时,将日志发送到集中式日志系统(如ELK Stack、Splunk、Grafana Loki等)变得至关重要。这便于统一搜索、分析和监控日志。日志框架通常支持通过各种Appender(如SocketAppender、KafkaAppender)将日志发送到远程目的地。
处理日志框架冲突: 如果项目中存在多个日志框架,使用SLF4J提供的桥接器(bridging modules)将它们统一到SLF4J门面下,例如
log4j-over-slf4j、jcl-over-slf4j等。
遵循这些实践,能让你的日志系统真正成为应用的“千里眼”和“顺风耳”,而不是一个麻烦的负担。
今天关于《Java日志记录教程:代码使用指南》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于日志级别,logback,log4j2,slf4j,Java日志的内容请关注golang学习网公众号!
 电脑黑屏无法开机怎么办
电脑黑屏无法开机怎么办
- 上一篇
- 电脑黑屏无法开机怎么办

- 下一篇
- Python解析基因测序结构变异检测方法
-
- 文章 · java教程 | 6天前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-
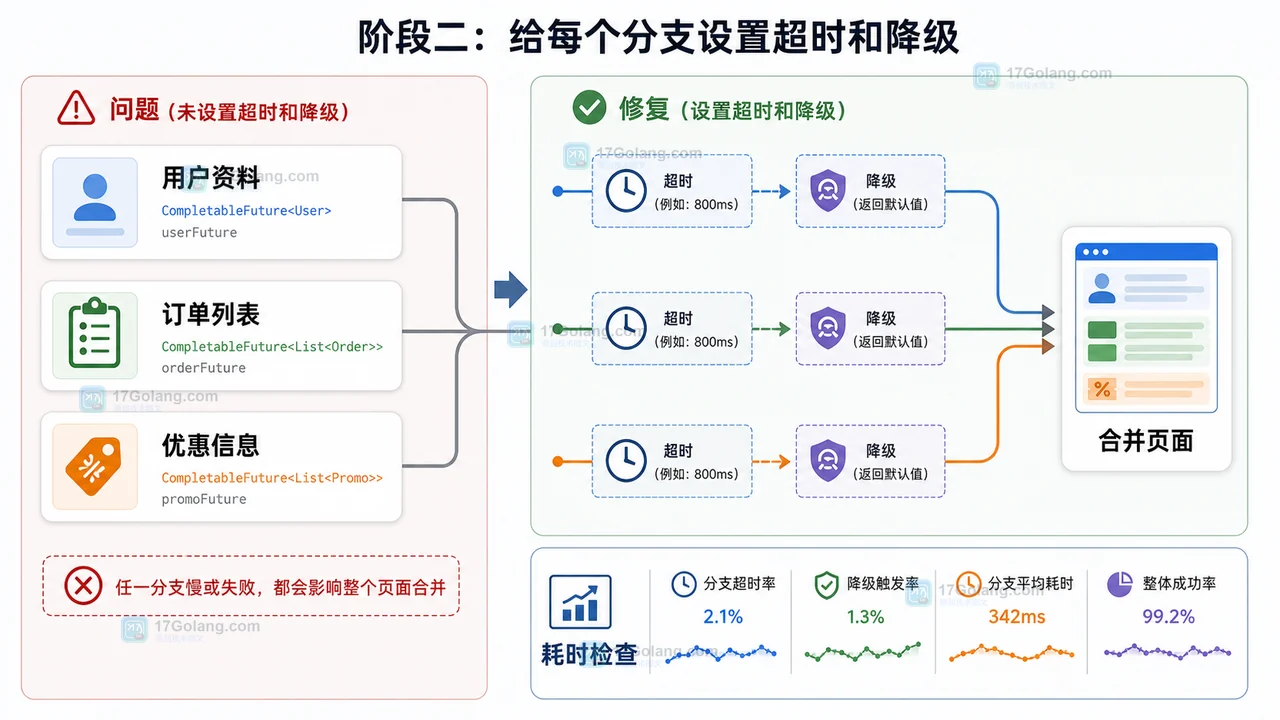
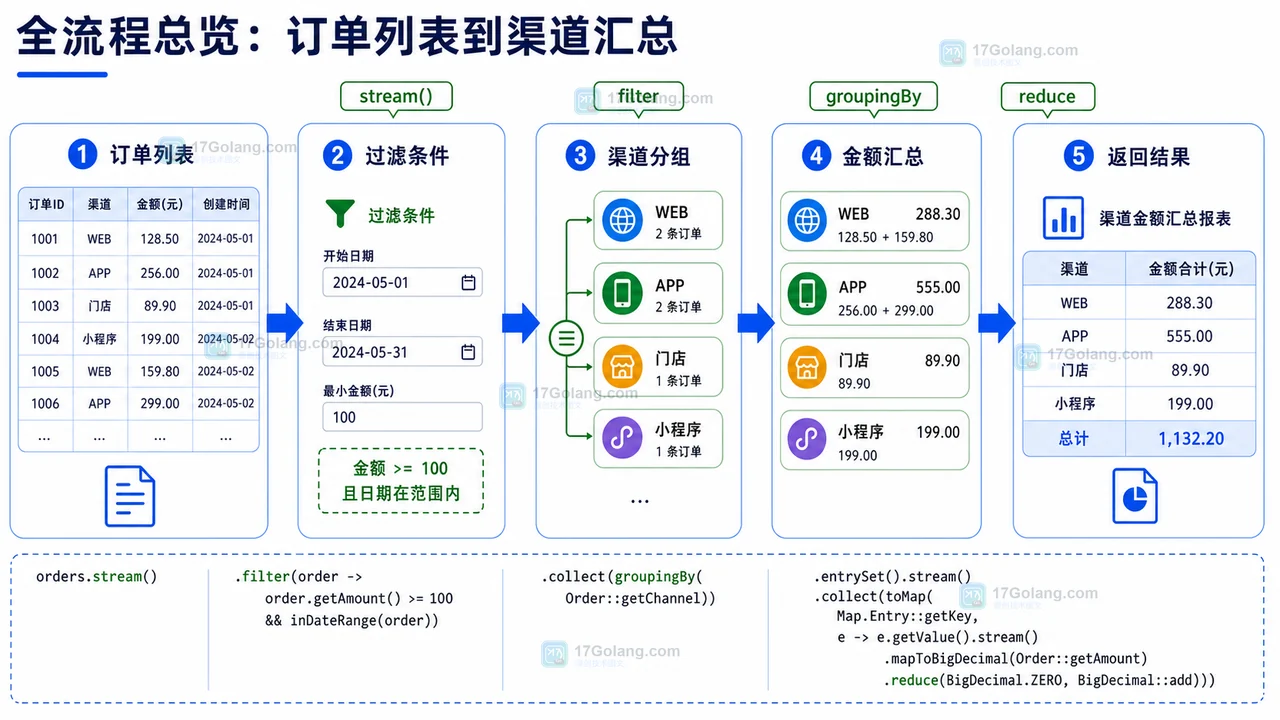
- 文章 · java教程 | 1星期前 | Java · 异步编程 · 后端开发 · CompletableFuture · 接口聚合 · java 结果合并 completablefuture 并行调用 超时兜底
- Java CompletableFuture 多接口聚合完整流程:并行调用、超时兜底和结果合并
- 428浏览 收藏
-
- 文章 · java教程 | 1星期前 | Java · 线程安全 · DateTimeFormatter · 日期处理 · 并发问题 · java 线程安全 日期格式化 threadlocal SimpleDateFormat DateTimeFormatter
- Java SimpleDateFormat 日期偶发错乱怎么办:从共享实例到线程安全一步步排查
- 481浏览 收藏
-
- 文章 · java教程 | 1星期前 | http接口 · httpclient · Java教程 · 接口调试 · 超时处理 · java 接口调用 httpclient 超时控制 状态码 响应体
- Java HttpClient 调接口实战:超时、状态码和响应体这样处理
- 224浏览 收藏
-
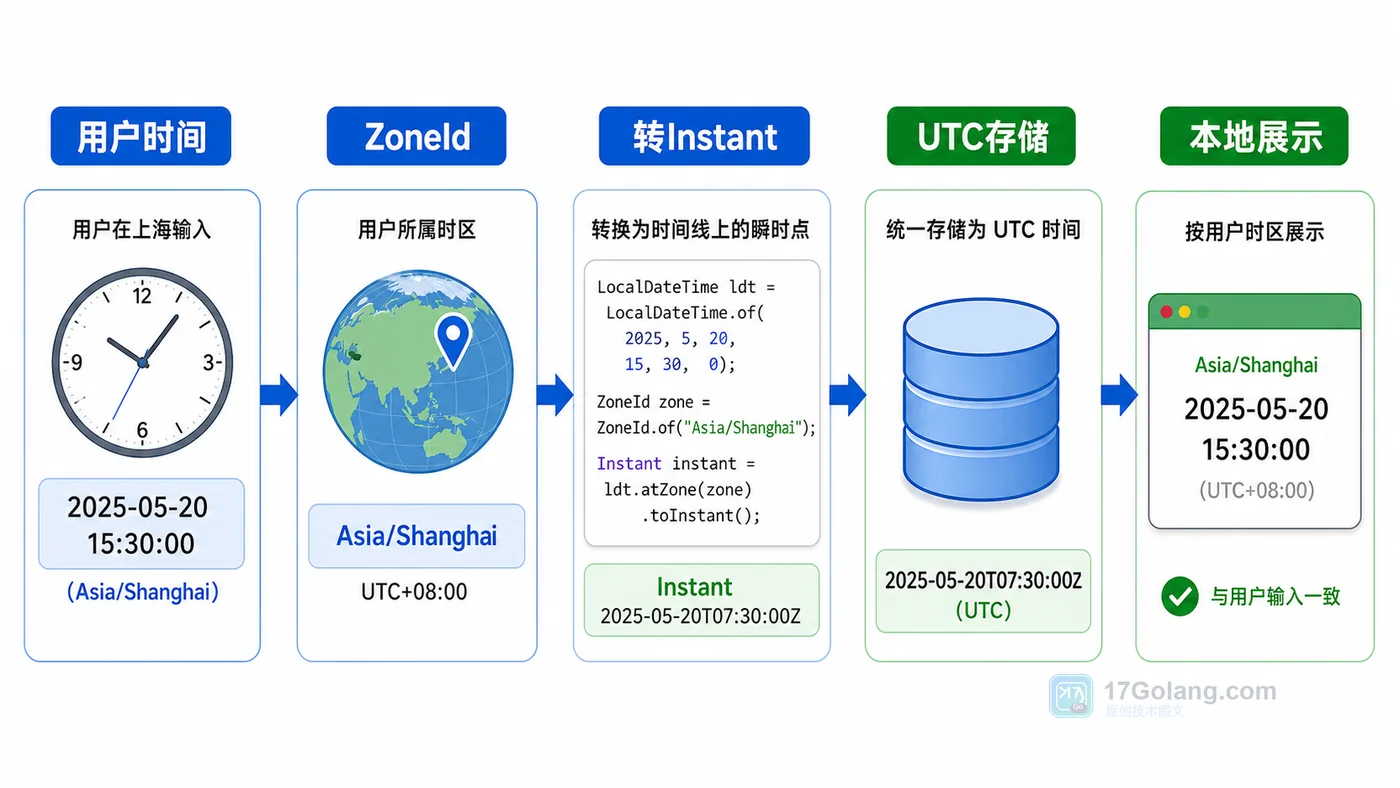
- 文章 · java教程 | 1星期前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT
- Java 时间与时区处理实战:Instant、ZoneId 和 DateTimeFormatter 怎么配
- 461浏览 收藏
-
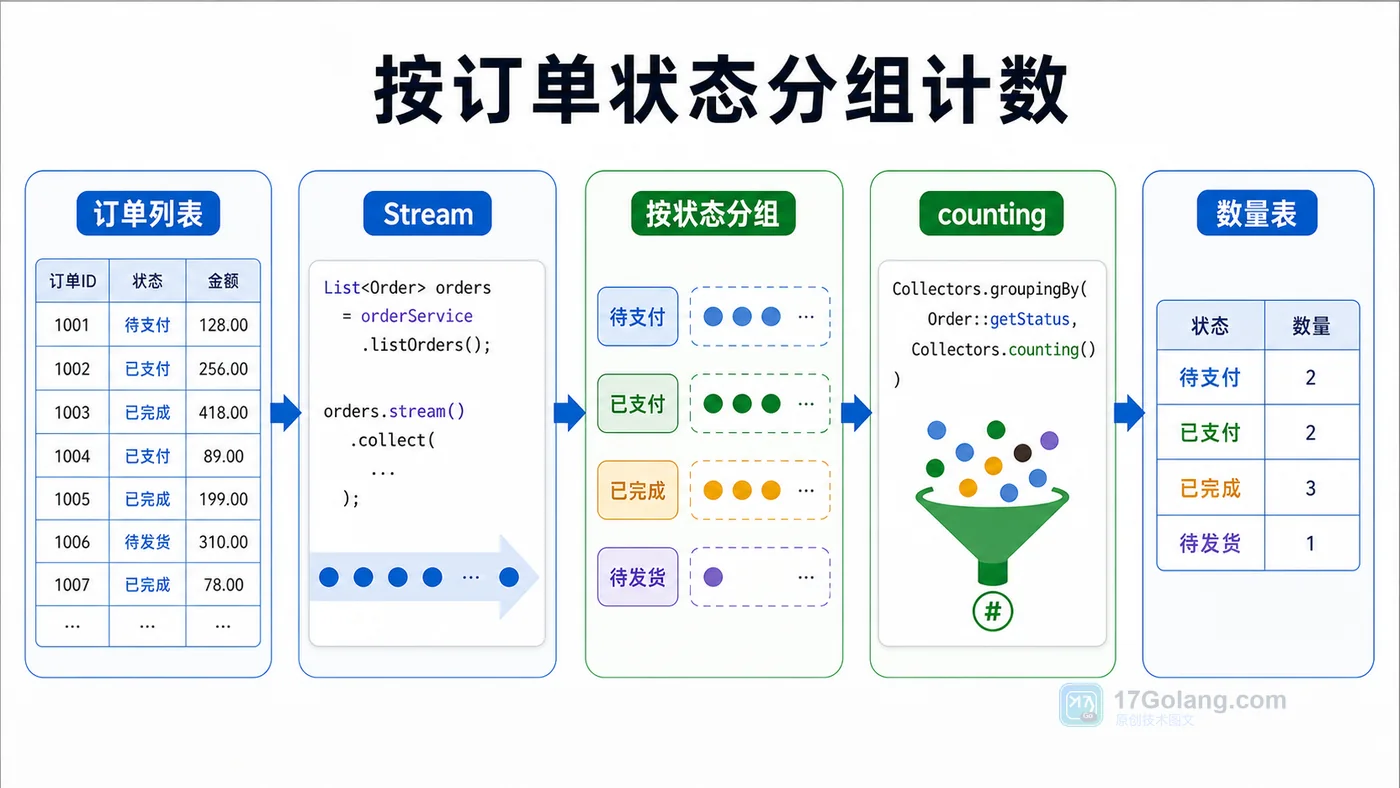
- 文章 · java教程 | 1星期前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
- Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
- 478浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1507次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 1446次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1396次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1582次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1571次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


