JS获取元素文本内容的几种方法
在JavaScript中,获取元素文本内容的方法主要有三种:`textContent`、`innerText` 和 `innerHTML`。`textContent` 属性是获取元素及其后代纯文本的首选方法,它不受CSS样式影响,性能优越且符合W3C标准,能获取包括隐藏元素在内的所有文本。`innerText` 则返回用户可见的文本,会受CSS样式影响,性能稍逊。`innerHTML` 则返回包含HTML标签的完整字符串,适用于需要操作HTML结构的场景,但需注意XSS安全风险。开发者应根据具体需求,在性能、功能和安全之间权衡,优先选择 `textContent` 以确保最佳性能和安全性,仅在需要考虑可见性或处理HTML时选用其他方法,并注意防范安全漏洞和空元素访问错误。
在JavaScript中获取元素文本内容最推荐的方法是使用textContent属性,1. 使用element.textContent可获取元素及其后代的所有纯文本内容,不受CSS样式影响,性能高且符合W3C标准;2. 使用element.innerText则返回用户可见的文本,受CSS样式(如display: none)影响,会触发布局重算,性能较低;3. 使用element.innerHTML会返回包含HTML标签的字符串,适用于需要操作HTML结构的场景,但存在XSS风险。应优先选择textContent以确保性能和安全性,仅在需要考虑可见性或处理HTML时选用innerText或innerHTML,并注意防范安全漏洞和空元素访问错误,最终根据具体需求在性能、功能与安全之间取得平衡。

在JavaScript中,要获取元素的文本内容,最直接且推荐的方式是使用textContent属性。它能获取到元素及其所有后代节点的文本内容,不包括任何HTML标签,并且不受CSS样式(如display: none)的影响,效率通常也更高。如果你需要获取用户在浏览器中实际能看到的文本,innerText也是一个选择,但它会考虑CSS样式,性能上可能略逊一筹。而innerHTML则会返回元素的全部内容,包括HTML标签本身,这通常用于获取或设置包含HTML结构的内容。
解决方案
在JavaScript中获取元素的文本内容,主要有以下几种方法:
element.textContent: 这是获取元素纯文本内容的首选方法。它返回指定元素及其所有子孙节点的文本内容,包括
test.textContent会得到 "Hello Worldconsole.log('script');"test.innerText会得到 "Hello" (因为World被隐藏了,script内容被忽略)test.innerHTML会得到 "Hello "
选择哪一个,很大程度上取决于你对“文本内容”的具体定义:是所有节点下的原始文本,还是用户实际能看到的文本,亦或是包含HTML结构的完整内容。
在实际开发中,我应该优先选择哪种方法?
在我看来,在绝大多数需要获取元素纯文本内容的场景下,textContent是你的首选。理由很简单也很实际:
- 性能优势:
textContent不需要浏览器执行复杂的布局计算,因此在处理大量DOM元素或性能敏感的应用中,它的效率更高。这在现代前端框架中,尤其在需要频繁读取DOM内容时,显得尤为重要。 - 行为一致性:它不受CSS样式的影响,这意味着无论元素是否被隐藏,你都能获取到它内部的所有文本内容。这让你的代码逻辑更清晰,不易出现因为样式变化而导致的意外行为。
- 标准推荐:作为W3C DOM标准的一部分,
textContent在不同浏览器中的行为更加一致和可预测。
那么,什么时候会考虑其他方法呢?
- 当你确实需要获取用户“可见”的文本时,可以考虑
innerText。比如,你可能在做一个文本选择工具,或者需要复制用户屏幕上实际显示的文本。但即便如此,我也建议你先评估其性能影响,尤其是在循环或大量操作中。如果性能成为瓶颈,你可能需要寻找其他优化方案,比如在获取前先判断元素的display样式。 - 当你需要获取或设置包含HTML标签的完整内容时,
innerHTML是唯一的选择。例如,你从服务器获取了一段HTML片段,需要将其插入到页面中;或者你需要获取用户在富文本编辑器中输入的内容(通常包含HTML格式)。然而,使用innerHTML来设置内容时,务必警惕XSS(跨站脚本攻击)风险。如果内容来源于用户输入或不可信的外部数据,一定要进行严格的净化(sanitization),避免恶意脚本注入。一个常见的错误就是直接将用户输入赋值给innerHTML,这可能导致严重的安全漏洞。
总的来说,我的建议是:默认使用textContent获取纯文本;只有当你明确需要考虑CSS可见性或处理HTML结构时,才考虑innerText或innerHTML,并对后者保持高度的安全警惕。 这种选择策略能让你在性能、功能和安全性之间取得一个很好的平衡。
获取文本内容时可能遇到的常见陷阱和注意事项有哪些?
在获取元素文本内容时,虽然看起来很简单,但确实存在一些容易被忽视的细节和“坑”,理解它们能帮助你写出更健壮、更高效的代码。
空值(Null)或未定义(Undefined)的元素: 这是最常见的错误之一。如果你尝试获取一个不存在的元素的
textContent、innerText或innerHTML,JavaScript会抛出TypeError,因为你试图在一个null或undefined值上访问属性。const nonExistentElement = document.getElementById('nonExistent'); // console.log(nonExistentElement.textContent); // 这会报错! if (nonExistentElement) { console.log(nonExistentElement.textContent); // 安全的做法 }在操作DOM元素之前,总是要确保你已经成功获取到了该元素。
性能考量,特别是
innerText: 前面提过,innerText的性能开销可能较大。这是因为它在获取文本时需要计算元素的最终渲染样式和布局。如果你在一个循环中频繁地读取大量元素的innerText,这可能会导致页面卡顿或响应变慢。textContent在这方面表现更优,因为它直接从DOM树中提取文本,不涉及渲染引擎。空白字符的处理差异:
textContent会保留元素内部的所有空白字符(包括换行符、空格、制表符),而innerText在某些情况下会进行标准化处理,例如会移除元素开头和结尾的空白,并且将连续的空白字符折叠成一个空格,类似于浏览器渲染HTML时处理空白的方式。Hello World!const div = document.getElementById('whitespaceDiv'); console.log(div.textContent); // " // Hello // World! // " (保留了换行和缩进) console.log(div.innerText); // "Hello World!" (标准化了空白)这个差异在处理用户输入或需要精确保留文本格式时尤其重要。
安全风险与
innerHTML: 当使用innerHTML来设置元素内容时,如果内容来源于用户输入或不可信的第三方数据,就可能导致XSS漏洞。恶意用户可以注入myDiv.innerHTML = userInput; // 极度危险!安全的做法是使用
textContent来设置纯文本内容,或者对innerHTML的内容进行严格的净化处理,例如使用DOMPurify这样的库。Node与Element的区别:textContent是Node接口的属性,这意味着它不仅可以在HTMLElement上使用,也可以在Text节点、Comment节点等所有Node类型的对象上使用。而innerText和innerHTML是HTMLElement接口的属性,只能在HTML元素节点上使用。虽然在日常开发中你通常操作的都是HTMLElement,但了解这个底层差异能帮助你更好地理解DOM API。动态内容更新的时机: 如果你在JavaScript中动态修改了DOM,例如通过
appendChild或removeChild,那么在这些操作之后立即获取文本内容,你会得到最新的值。但如果你是在一个异步操作(如setTimeout或fetch回调)中修改DOM,并希望获取修改后的文本,确保你在DOM更新完成后再进行获取。
理解这些细节,能让你在处理DOM文本内容时更加游刃有余,避免一些不必要的麻烦。选择合适的API,并警惕潜在的问题,是写出高质量前端代码的关键。
终于介绍完啦!小伙伴们,这篇关于《JS获取元素文本内容的几种方法》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布文章相关知识,快来关注吧!
 AI剪辑到生成,内容创作新时代来临
AI剪辑到生成,内容创作新时代来临
- 上一篇
- AI剪辑到生成,内容创作新时代来临

- 下一篇
- Golang实现CQRS:命令查询分离教程
-
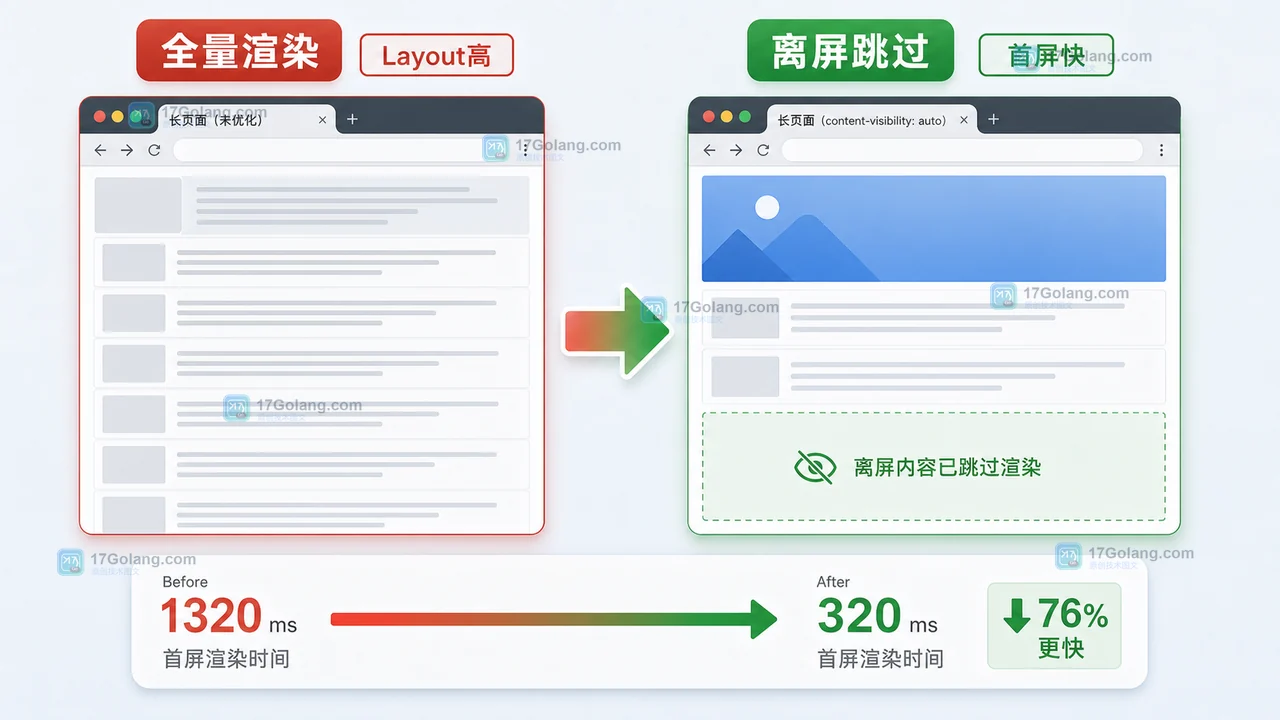
- 文章 · 前端 | 4天前 | 前端 · 性能优化 · css · Core Web Vitals · 渲染性能 · 前端 渲染性能 CSS性能 CLS content-visibility contain-intrinsic-size Layout
- 前端长页面渲染卡顿怎么排查:用 content-visibility 跳过离屏区块
- 430浏览 收藏
-
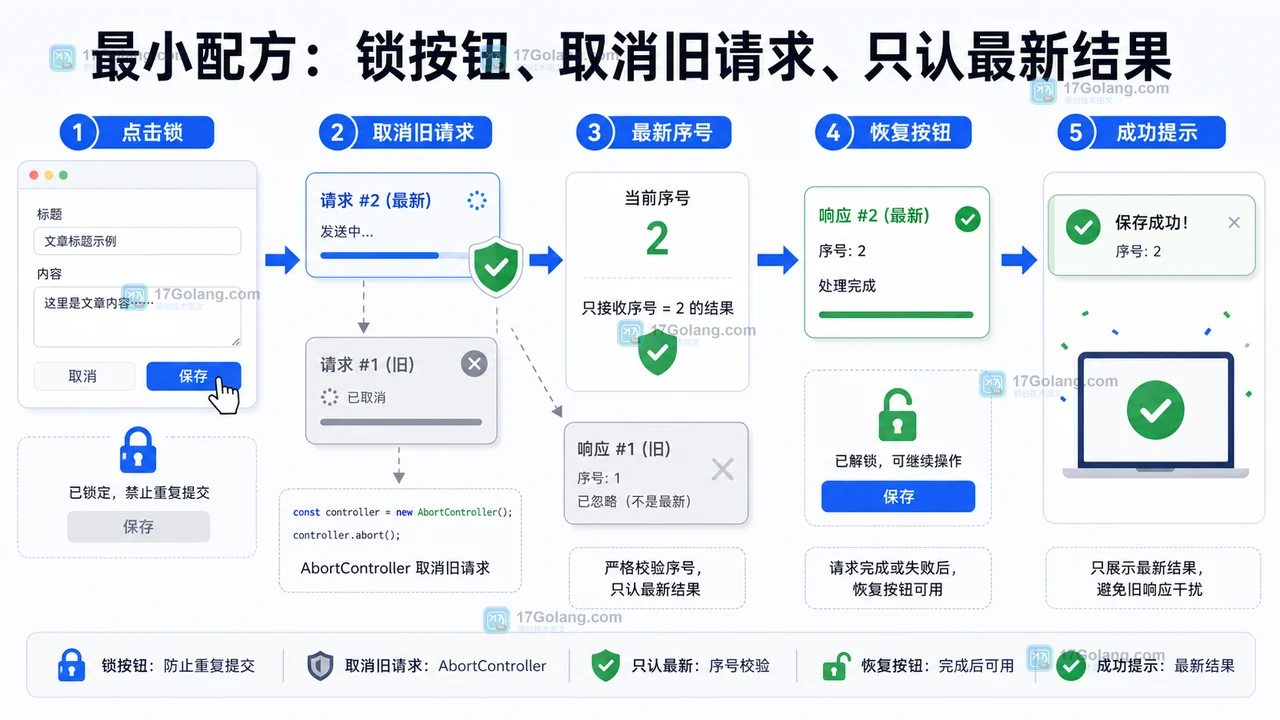
- 文章 · 前端 | 1星期前 | 前端 · javascript · AbortController · 表单提交 · AbortController 旧响应覆盖 前端重复提交 loading锁 fetch取消 按钮防抖
- 前端按钮重复提交怎么办:loading 锁和 AbortController 最小配方
- 442浏览 收藏
-
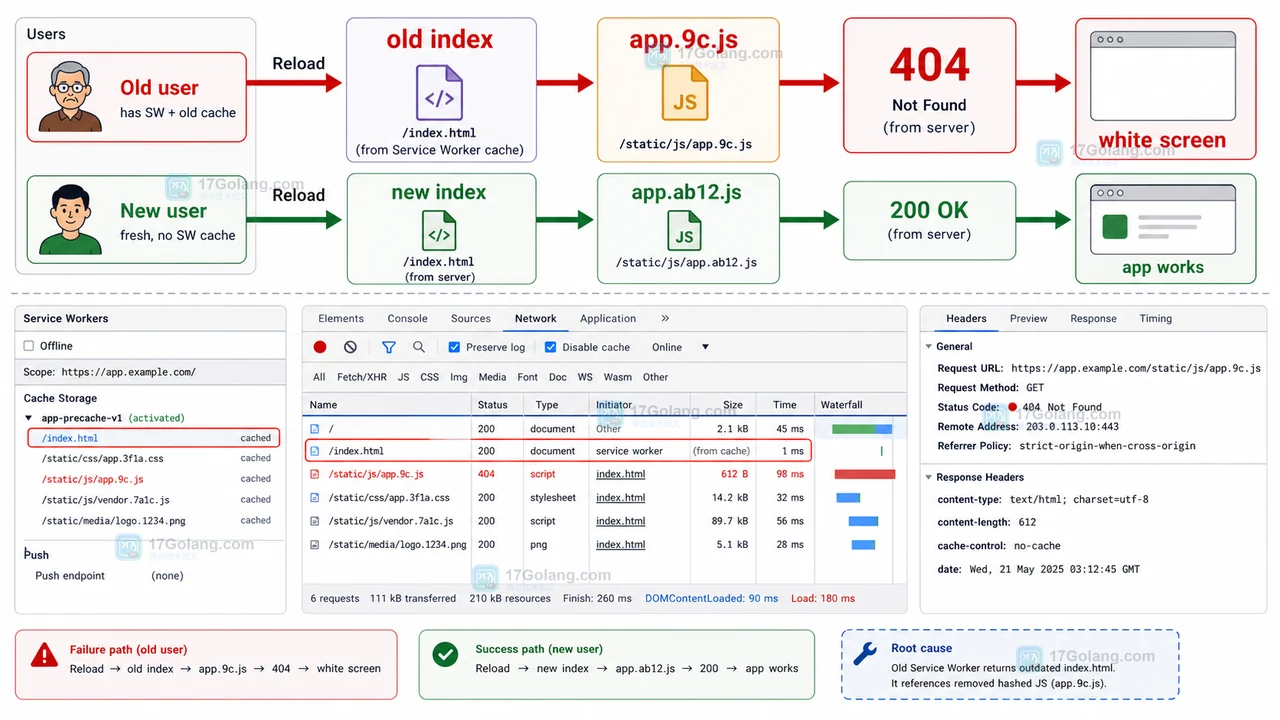
- 文章 · 前端 | 1星期前 | 前端 · 缓存 · Service Worker · 白屏 · 发布故障 · 缓存策略 前端白屏 Service Worker CacheStorage 资源404 发布回滚
- 前端发布后白屏复盘:Service Worker 缓存旧入口导致 JS 资源 404
- 469浏览 收藏
-
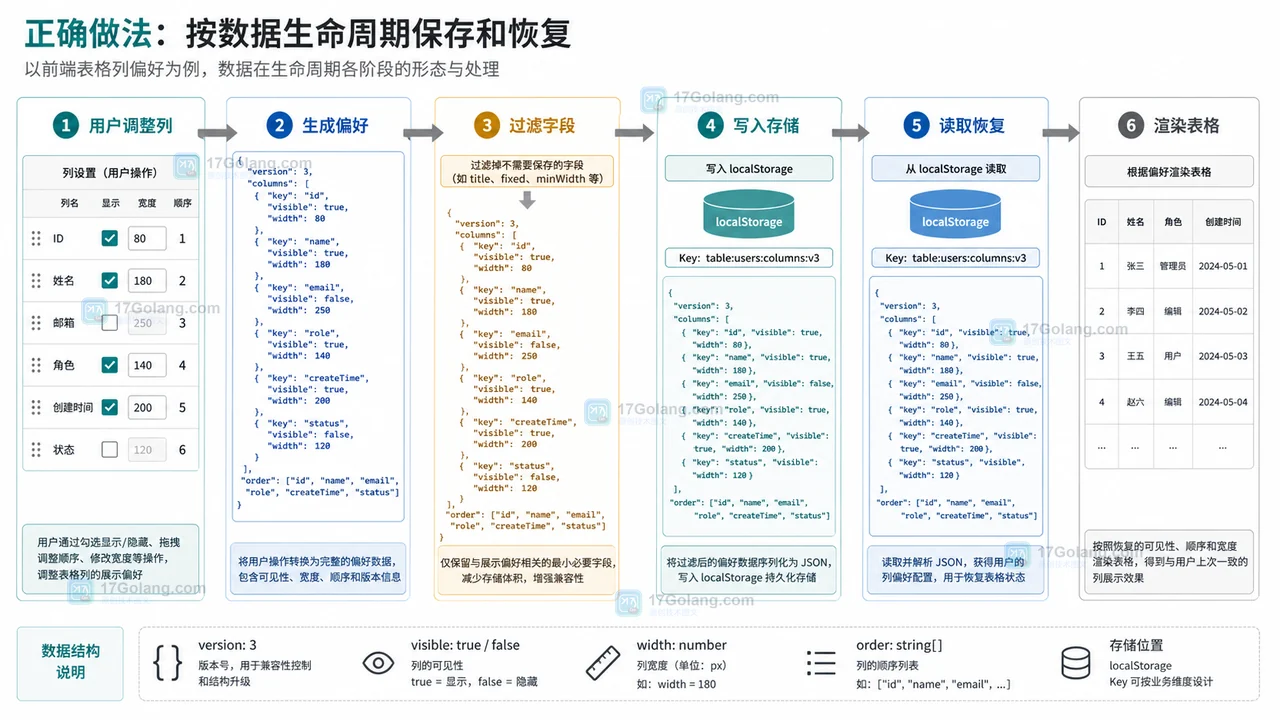
- 文章 · 前端 | 1星期前 | 前端开发 · localStorage · 表格配置 · 用户偏好 · 后台系统 · 用户偏好 localStorage 前端表格 列配置 可见列 列宽保存
- 前端表格列设置刷新后丢失怎么办:可见列、列宽和顺序这样保存
- 351浏览 收藏
-
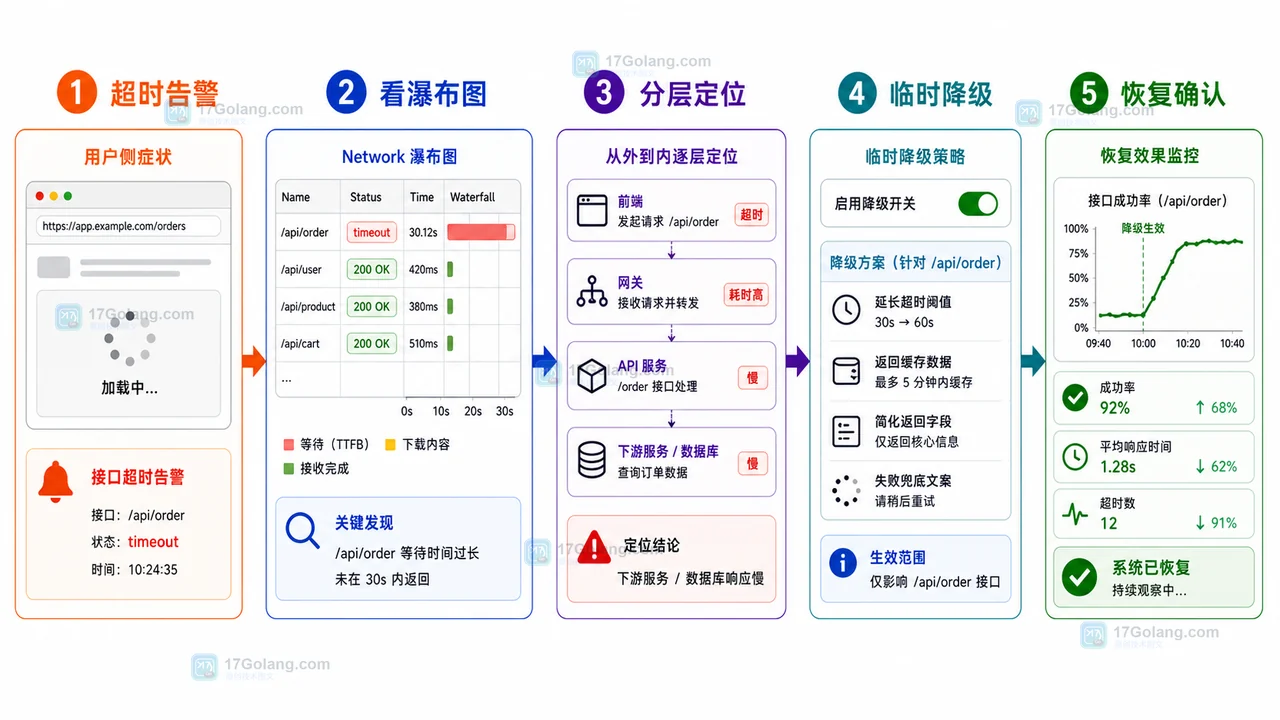
- 文章 · 前端 | 1星期前 | 前端 · 接口排查 · 运维手册 · 性能告警 · 前端 AbortController 接口超时 Network瀑布图 降级回滚 线上告警
- 前端接口超时告警运行手册:从瀑布图到降级回滚
- 287浏览 收藏