Python爬取影评数据与情感分析教程
学习知识要善于思考,思考,再思考!今天golang学习网小编就给大家带来《Python爬取影评数据与情感分析系统搭建》,以下内容主要包含等知识点,如果你正在学习或准备学习文章,就都不要错过本文啦~让我们一起来看看吧,能帮助到你就更好了!
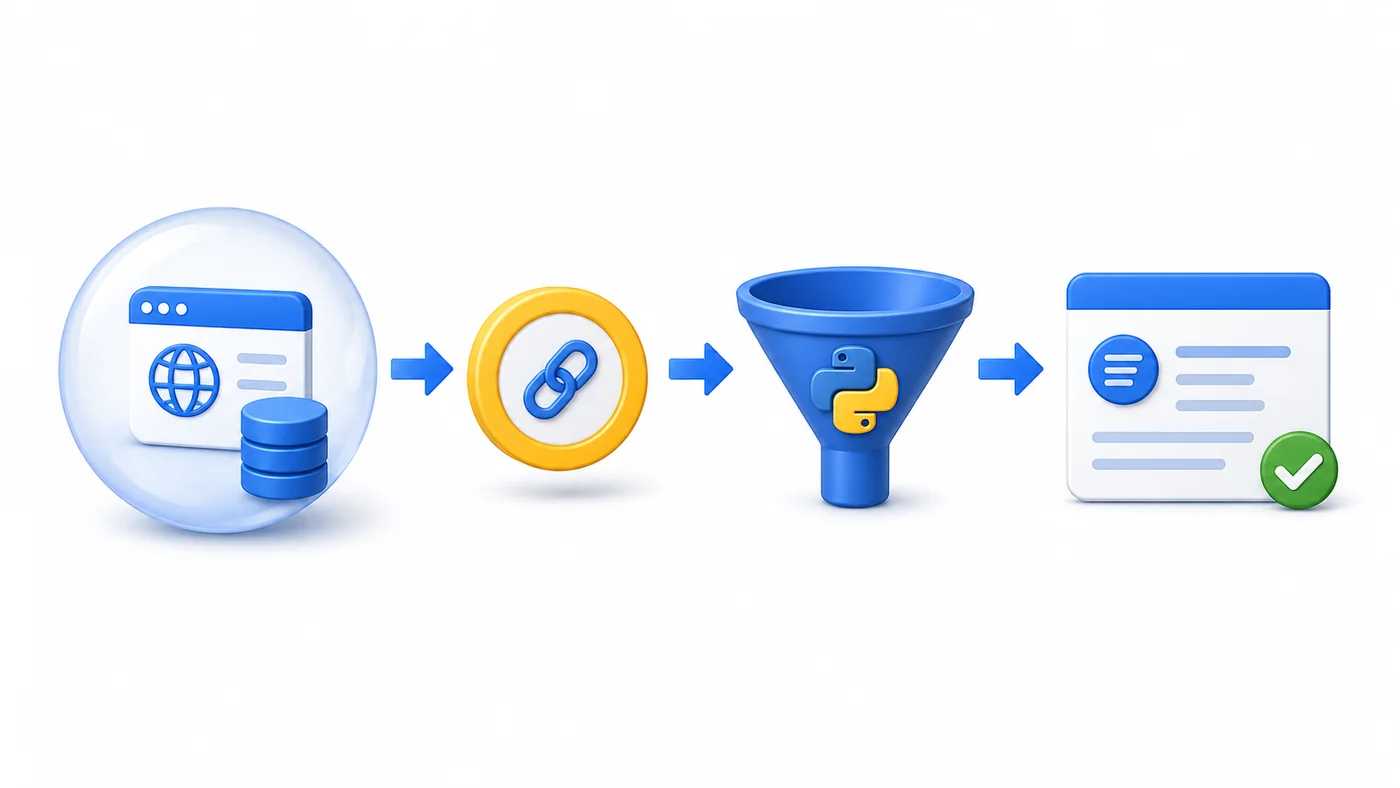
要使用Python爬取影评并构建情感分析系统,首先需明确目标网站与数据结构,利用requests或Selenium爬取数据,清洗并存储为结构化格式,再通过分词、特征提取、选择情感词典或预训练模型进行情感分析。1.确定目标网站,分析HTML结构并提取影评、评分等字段;2.编写爬虫脚本,静态网页用requests+BeautifulSoup,动态网页用Selenium;3.将数据存储为CSV/JSON或数据库;4.数据预处理包括去噪、分词、去除停用词、处理否定词;5.选择情感分析方法:基于词典(如SnowNLP、知网词典)、机器学习(TF-IDF+分类模型)、深度学习(BERT、ERNIE等预训练模型微调);6.评估模型性能并优化策略。常见反爬应对方法包括设置User-Agent、使用代理IP、控制请求频率、处理验证码和模拟登录。情感词典适合小数据、低资源场景,预训练模型适合高准确度需求。预处理关键步骤包括清除HTML、标准化、分词、停用词过滤、否定词与程度副词处理。

用Python源码爬取影视影评数据并构建情感分析系统,这本质上是数据采集与自然语言处理(NLP)的结合。你可以通过编写脚本从影评网站抓取文本内容,然后利用各种NLP技术对这些文本进行清洗、特征提取,最终训练或应用模型来判断影评的情感倾向(积极、消极或中性)。这套流程听起来复杂,但拆解开来,每一步都有成熟的工具和方法支持。

对于爬取影评数据,通常会用到requests库来发送HTTP请求获取网页内容,再结合BeautifulSoup或lxml来解析HTML,提取出影评文本、评分、用户ID等信息。如果目标网站有较强的反爬机制或者内容是动态加载的,可能就需要Selenium来模拟浏览器行为。数据到手后,构建情感分析系统则更像是进入了NLP的深水区,从简单的词典匹配到复杂的深度学习模型,选择很多,关键在于你的数据量、语言特性(中文影评尤其要注意分词)以及对准确度的要求。
解决方案
第一步:确定目标网站与数据结构 选择一个或几个提供影评的网站,例如豆瓣电影、IMDb等。使用浏览器的开发者工具(F12)检查网页的HTML结构,找出影评文本、用户ID、时间、评分等元素对应的HTML标签和CSS选择器。这一步至关重要,它决定了你后续解析数据的逻辑。

第二步:编写爬虫脚本
对于静态网页,可以采用requests库发送GET请求获取页面内容,然后使用BeautifulSoup解析。例如:
import requests
from bs4 import BeautifulSoup
url = "https://movie.douban.com/subject/XXXXXX/comments?start=0&limit=20&status=P&sort=new_score" # 示例URL,需替换
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 假设影评在标签内
comments = soup.find_all('p', class_='comment-content')
for comment in comments:
print(comment.get_text(strip=True))
如果网站内容是JavaScript动态加载的,或者有较强的反爬措施(如复杂的验证码、IP封禁),你可能需要引入Selenium来模拟真实用户操作,或者考虑使用Scrapy框架来构建更健壮、可扩展的爬虫。处理翻页是常见需求,通常通过修改URL参数(如start或page)或点击“下一页”按钮来实现。

第三步:数据存储 将爬取到的数据结构化存储,常见的格式有CSV、JSON,或者直接存入数据库(SQLite、MySQL、MongoDB)。JSON格式对于非结构化或半结构化数据比较友好,而CSV则方便后续直接导入到数据分析工具中。
第四步:构建情感分析系统 这部分是核心。
- 数据预处理: 原始影评文本通常包含大量噪音。你需要进行:
- 去除HTML标签、特殊符号、数字和URL。
- 中文分词: 使用
jieba库对中文影评进行分词,这是中文NLP的基础。 - 去除停用词: 移除“的”、“是”、“了”等无意义的常用词。
- 处理否定词: 否定词(如“不”、“没有”)对情感极性影响巨大,需要特殊处理,比如将“不 好看”合并为“不好看”或在“好看”前加一个否定标记。
- 情感分析方法选择:
- 基于情感词典: 最简单直接的方式。加载一个预先构建好的情感词典(如知网情感词典、大连理工情感词典),对影评中的词语进行匹配,根据词语的情感极性(积极、消极、中性)和强度计算总得分。例如,
SnowNLP就是针对中文的轻量级情感分析库。 - 基于机器学习:
- 特征提取: 将文本转换为模型可理解的数值特征。常用的有TF-IDF(词频-逆文档频率)、Word2Vec、GloVe等词向量模型。
- 模型训练: 使用标注好的影评数据(人工标注积极、消极、中性)来训练分类模型,如朴素贝叶斯(Naive Bayes)、支持向量机(SVM)、逻辑回归(Logistic Regression)或随机森林等。
scikit-learn是Python中实现这些模型的强大工具。
- 基于深度学习/预训练模型:
- 模型选择: 这是当前最先进的方法。利用预训练的Transformer模型(如BERT、ERNIE、RoBERTa等)进行微调(fine-tuning)。这些模型在海量文本数据上预训练过,能捕捉更深层次的语义信息。
- 实现: 使用
Hugging Face Transformers库可以非常方便地加载各种预训练模型,并进行微调。这通常能达到最高的准确率,但需要更多的计算资源和标注数据。
- 基于情感词典: 最简单直接的方式。加载一个预先构建好的情感词典(如知网情感词典、大连理工情感词典),对影评中的词语进行匹配,根据词语的情感极性(积极、消极、中性)和强度计算总得分。例如,
第五步:模型评估与优化 无论选择哪种方法,都需要用测试集来评估模型的性能,常用指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-Score。根据评估结果,你可以调整预处理步骤、更换模型、增加训练数据或进行超参数优化,以提升系统性能。
Python爬取影评数据时,有哪些常见的反爬策略及应对方法?
在尝试用Python爬取影评数据时,你很快就会发现,网站不是那么“友好”地让你随便拿数据的。它们会设置各种障碍,也就是我们常说的反爬策略。这就像一场猫鼠游戏,你得了解它们的招数,才能见招拆招。
最常见的就是User-Agent检测。网站会检查你的请求头,看你是不是一个正常的浏览器。如果你用默认的Python requests库,User-Agent会是“python-requests/X.Y.Z”,一看就知道是爬虫。应对方法很简单,在请求头里伪装成主流浏览器,比如Chrome或Firefox的User-Agent。
然后是IP封禁。如果你在短时间内从同一个IP地址发出大量请求,网站可能会认为你在恶意爬取,直接把你IP封掉。这时,使用代理IP池就成了必需品。你可以购买高质量的付费代理,或者自己搭建代理服务器。让每次请求都通过不同的IP地址发出,就能有效规避IP封禁。不过,免费代理往往质量不高,速度慢,还容易失效。
有些网站还会使用验证码。这可能是图形验证码、滑动验证码,甚至是点选验证码。对于简单的图形验证码,你可以尝试使用OCR(光学字符识别)库来识别,但成功率不高。更可靠的方法是接入第三方打码平台,让真人帮你识别。对于复杂的动态验证码,可能就得祭出Selenium模拟人工操作,或者深入研究其前端逻辑,找到绕过的方法。
动态加载内容也是一大挑战。很多影评网站的内容(比如评论区)并不是直接写在HTML里的,而是通过JavaScript异步加载的。这意味着你用requests直接获取到的HTML可能不包含你想要的数据。这时候,Selenium就派上用场了。它能驱动真实的浏览器,执行JavaScript,渲染出完整的页面,然后你再从渲染后的页面中提取数据。不过,Selenium的效率相对较低,因为它需要启动浏览器进程,占用资源较多。
最后,还有请求频率限制。网站会限制你在单位时间内的请求次数。如果你请求太快,就会收到429(Too Many Requests)错误。应对方法是设置合理的请求间隔,使用time.sleep()函数在每次请求之间加入随机延迟。这样既能避免被封,也能模拟人类的浏览行为,显得更自然。有时候,还会结合Cookie和Session管理,模拟登录状态,获取需要权限才能访问的数据。
说到底,反爬和爬虫是一个不断升级对抗的过程。没有一劳永逸的解决方案,你总得根据目标网站的变化来调整策略。
构建情感分析系统,如何选择合适的中文影评情感词典或预训练模型?
在构建中文影评情感分析系统时,选择合适的情感词典或预训练模型是决定系统性能的关键一步。这不像英语,中文的词汇、语法和表达习惯都非常独特,所以不能直接套用英文的工具。
如果你追求简单、快速且对准确度要求不是特别高,或者你的数据量相对较小,那么基于情感词典的方法是一个不错的起点。中文领域有一些开源的情感词典,比如知网(HowNet)情感词典和大连理工大学情感词典。这些词典通常包含了大量词语的情感极性(积极、消极)和强度。你可以通过分词后,匹配影评中的词语,然后根据词典中的极性和强度进行加权求和,从而得到整篇影评的情感得分。SnowNLP是一个轻量级的Python库,它内部也包含了基于词典和机器学习的混合方法,对于一些基础的中文情感分析任务,它能很快给出结果,上手门槛低。但这种方法的局限性在于,它很难理解复杂的语义、反讽、双关语等,也无法处理词典中没有的新词。
但如果你的目标是高准确率、能够理解复杂语义,并且有一定的数据量和计算资源,那么基于预训练模型(尤其是深度学习模型)无疑是更好的选择。这是当前NLP领域的主流方向。
对于中文情感分析,你可以考虑以下几种预训练模型:
- BERT及其变体: 谷歌的BERT模型开启了NLP的新纪元。针对中文,有很多优秀的BERT变体,例如:
- ERNIE (百度飞桨): 在中文语料上进行了大量预训练,对中文语义理解能力很强。
- RoBERTa-wwm-ext (哈工大讯飞): 针对中文的RoBERTa模型,效果通常非常出色。
- MacBERT: 同样是针对中文的BERT优化模型。
- Chinese-BERT-wwm: 这是基于全词覆盖(whole word masking)策略训练的中文BERT模型,在中文任务上表现优异。
这些模型通常可以在Hugging Face Transformers库中找到并直接加载。使用它们的方法是进行微调(fine-tuning):你用自己收集并标注的影评情感数据集(比如标注为积极、消极、中性)在这些预训练模型的基础上进行训练。模型会根据你的特定任务(影评情感分类)来调整其内部参数,从而达到最佳效果。
如何选择?
- 数据量和标注成本: 如果你只有少量标注数据,或者根本没有,那么词典方法是唯一的选择。但如果能投入资源进行数据标注,预训练模型的效果会远超词典方法。
- 计算资源: 运行和微调大型预训练模型需要GPU支持,而词典方法几乎不需要额外计算资源。
- 对准确度的要求: 如果对准确度要求很高,例如要区分细微的情感差异、理解反讽,那么毫无疑问应该选择预训练模型。
- 领域适应性: 影评领域有其独特的词汇和表达习惯。如果能找到在影评领域预训练过的模型(虽然比较少见),那效果会更好。否则,选择通用领域表现优秀的中文预训练模型,然后用你的影评数据进行微调,是最佳实践。
我的经验是,对于中文情感分析,如果条件允许,直接上预训练模型进行微调,能省去很多特征工程的麻烦,并且效果通常会好很多。但如果资源有限,从词典方法或SnowNLP开始,也是一个快速验证思路的途径。
从原始影评文本到情感标签,数据预处理有哪些关键步骤和技巧?
从爬取到的原始影评文本到最终能被情感分析模型理解并打上情感标签,数据预处理是整个流程中一个非常关键且耗时的环节。它就像是给原始数据“洗澡”和“化妆”,让它们变得干净、规范,从而提升模型的学习效率和准确性。
首先,你面对的原始影评文本往往是“脏乱差”的。它们可能混杂着HTML标签、特殊符号、表情符号、URL、数字、甚至是一些乱码。第一步就是噪声清除。你需要编写正则表达式或者利用BeautifulSoup等工具,把这些与情感分析无关的内容统统去掉。比如,去除 等HTML实体,删除网址链接,决定是否保留或转换表情符号(表情符号本身可能包含情感信息)。
接下来是文本标准化。虽然中文不像英文那样有大小写之分,但你可能需要处理全角半角字符的统一,或者将一些不规范的标点符号进行转换。对于中文来说,分词是极其重要的一步。中文词语之间没有空格分隔,模型无法直接识别。jieba分词库是目前中文领域最常用也最强大的工具之一。它支持精确模式、全模式和搜索引擎模式,还能加载自定义词典来处理特定领域的专有名词或网络热词(比如电影名、演员名、流行语)。分词质量直接影响后续特征提取和模型效果。
分词之后,通常会进行停用词去除。停用词是那些在文本中出现频率很高但对文本含义和情感极性贡献很小的词,比如“的”、“是”、“了”、“一个”等等。移除它们可以减少数据维度,提高模型效率,并让模型更关注那些真正有意义的词语。你可以从网上找到现成的中文停用词表,也可以根据你的具体影评数据构建自定义的停用词表。
一个非常重要的技巧是处理否定词和程度副词。在情感分析中,“好”和“不好”是截然相反的,“非常棒”和“有点棒”程度也不同。简单地移除停用词可能会把“不”字去掉,导致“不开心”被错误地识别为“开心”。因此,在分词和停用词去除之后,或者在进行情感词典匹配之前,你需要特殊处理否定词(如“不”、“没有”、“并非”)和程度副词(如“非常”、“很”、“有点”、“几乎”)。常见的做法是将否定词与它后面的词语组合起来形成一个新词(如“不好”),或者在词语前添加一个“NEG”前缀。程度副词则可以用来调整其后面情感词的权重。
对于传统的机器学习模型,还需要进行特征工程。最基础的是词袋模型(Bag-of-Words)和TF-IDF。词袋模型只是统计词频,而TF-IDF则考虑了词语在文档中的重要性。更高级的则是词向量(Word Embeddings),如Word2Vec、GloVe等。它们将词语映射到低维向量空间中,使得语义相似的词在向量空间中距离更近。这些向量可以作为深度学习模型的输入层。
总的来说,数据预处理不是一个线性的过程,它更像是一个迭代和试错的过程。你可能需要尝试不同的分词模式、不同的停用词表、不同的噪声清除策略,甚至不同的否定词处理方式,然后通过模型效果来反向验证哪种预处理方法最适合你的数据和任务。没有一劳永逸的方案,每一步的调整都可能带来意想不到的提升或挑战。
本篇关于《Python爬取影评数据与情感分析教程》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于文章的相关知识,请关注golang学习网公众号!
 JavaScript循环优化技巧大全
JavaScript循环优化技巧大全
- 上一篇
- JavaScript循环优化技巧大全

- 下一篇
- JavaScript数组螺旋遍历技巧
-
- 文章 · python教程 | 3天前 | 日志 · 链路追踪 · Python教程 · contextvars · Python logging contextvars 日志追踪 trace_id 异步上下文
- Python 日志链路追踪实战:用 contextvars 自动带上 trace_id
- 370浏览 收藏







-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 129次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 136次使用
-

- Red Skill
- 小红书创作服务平台为小红书创作者和机构提供视频上传、数据分析、粉丝管理、创作指导等多项运营服务,助力用户解锁更多创作者专属功能,体验高效创作!
- 137次使用
-

- MiMo Code
- MiMo Code 是小米大模型团队开源的新一代 AI 编程助手,面向开发者提供代码理解、生成与辅助开发能力,适合作为 AI 编程工具收藏和体验。
- 242次使用
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 269次使用
-
- Flask框架安装技巧:让你的开发更高效
- 2024-01-03 501浏览
-
- Django框架中的并发处理技巧
- 2024-01-22 501浏览
-
- 提升Python包下载速度的方法——正确配置pip的国内源
- 2024-01-17 501浏览
-
- Python与C++:哪个编程语言更适合初学者?
- 2024-03-25 501浏览
-
- 品牌建设技巧
- 2024-04-06 501浏览


