SpringBoot入门实战详解教程
大家好,今天本人给大家带来文章《Spring Boot 入门与实战详解(最易懂教程)》,文中内容主要涉及到,如果你对文章方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
Spring Boot通过自动化配置、内嵌服务器、Starter POMs和生产就绪特性极大简化了Java开发。1. 自动化配置根据引入的依赖自动完成大部分配置工作,减少手动编写配置文件的需要;2. 内嵌服务器将Tomcat等Web容器集成到应用中,实现jar包一键运行;3. Starter POMs统一管理相关依赖及其版本,避免依赖冲突;4. 提供健康检查、度量等生产级功能,提升运维效率。通过Spring Initializr可快速生成项目骨架,结合Spring Data JPA能高效完成数据库操作,使开发者专注于业务逻辑,显著提高开发效率。

Spring Boot,简单来说,就是一套能让你用Java快速开发应用的“脚手架”和“加速器”。它极大地简化了Spring应用的搭建和开发过程,让我们这些开发者能更专注于业务逻辑,而不是繁琐的配置。如果你想快速上手一个项目,或者对Spring框架感到头疼,Spring Boot绝对是你值得一试的选择,它能让你在短时间内跑起来一个功能完备的应用,简直是开发效率的“神助攻”。

解决方案
要真正理解Spring Boot为什么能做到“快速入门与项目实战”,得从它几个核心设计理念说起。它不是一个全新的框架,而是对Spring生态系统的一次巧妙整合和优化。想想看,以前我们用Spring开发,是不是总要写一大堆XML配置,或者Java配置类也少不了?依赖管理也是个头疼事,版本冲突时有发生。Spring Boot就是来解决这些痛点的。
它引入了“约定优于配置”的思想,很多东西你不用管,它自己就帮你配好了。比如,你引入了Web依赖,它就默认帮你启动一个内嵌的Tomcat服务器,你写个Controller就能直接跑起来。还有“Starter POMs”,这玩意儿简直是依赖管理的救星,一个spring-boot-starter-web就把所有Web开发需要的依赖都拉进来了,还帮你管理好了版本,再也不用担心“依赖地狱”了。

所以,我们的解决方案就是:拥抱Spring Boot的这些自动化和简化特性,从一个最基础的Web应用开始,逐步深入到数据库集成、API开发,你会发现整个过程比想象中顺畅得多。它把很多幕后的复杂性都隐藏了,让你能更快地看到成果,这对于学习和项目初期验证来说,太重要了。
Spring Boot真的能让开发变得更简单吗?它的核心优势体现在哪里?
说实话,我第一次接触Spring Boot的时候,简直是惊呆了。那时候还在为Spring MVC的XML配置头疼,突然发现Spring Boot一个注解、一个依赖就能搞定,那种感觉就像从“石器时代”一下子跳到了“信息时代”。它确实让Java开发,特别是Web应用开发,变得异常简单和高效。

它的核心优势,我觉得主要体现在几个方面:
首先是自动化配置(Auto-Configuration)。这个是Spring Boot的灵魂。它会根据你项目里引入的jar包,自动帮你配置Spring应用。比如,你加了spring-boot-starter-data-jpa,它就会自动检测你有没有数据源配置,然后帮你配置好DataSource、EntityManagerFactory等等。这种“智能”让我省去了大量原本需要手动编写的配置代码,极大地减少了出错的可能性,也提高了开发效率。我只需要关心业务逻辑,底层那些繁琐的配置,Spring Boot都替我搞定了。
接着是内嵌服务器(Embedded Servers)。以前部署Java Web应用,你得先装个Tomcat、Jetty或者Undertow,然后把你的war包扔进去。现在Spring Boot直接把这些服务器内嵌到你的应用里,一个jar包就能独立运行,直接java -jar your-app.jar就完事儿了。这对于开发、测试和部署来说,简直是革命性的便利。想想看,一套代码,一个包,哪里都能跑,多省心!
然后是Starter POMs。这东西简直是依赖管理的“救世主”。以前,为了引入一个功能,我可能要找好几个依赖,还得小心翼翼地匹配版本,稍微不注意就冲突了。Spring Boot的Starter就是把一系列相关的依赖打包在一起,比如spring-boot-starter-web包含了Tomcat、Spring MVC等所有Web开发所需的依赖,并且版本都是兼容的。这大大简化了项目构建的复杂度,让开发者能更快地搭建起一个功能完备的项目骨架。
最后,不得不提的是生产就绪特性。Spring Boot不仅仅是开发阶段的利器,它还为生产环境提供了很多开箱即用的功能,比如健康检查、度量、外部化配置等。通过Spring Boot Actuator,我们可以轻松监控和管理运行中的应用。这些特性让我们的应用从开发到部署再到运维,整个生命周期都变得更加顺畅和可控。
总而言之,Spring Boot的这些特性,就像给Java开发者装上了“翅膀”,让我们可以更快速、更优雅地构建和部署应用。它不是简单地把复杂性隐藏起来,而是通过一套智能的约定和自动化机制,让复杂性变得可管理,最终达到“让开发更简单”的目标。
从零开始:如何搭建一个Spring Boot项目并运行第一个应用?
搭建一个Spring Boot项目,现在简直是“傻瓜式”操作,你甚至不需要自己敲一行配置。最常用的方法就是通过Spring Initializr。
访问Spring Initializr: 打开浏览器,输入
start.spring.io。这是一个由Spring官方提供的项目生成器。选择项目配置:
- Project: 我通常选Maven Project,因为习惯了,当然Gradle也行。
- Language: Java。
- Spring Boot: 选择一个稳定的最新版本,比如3.2.x或者2.7.x。
- Project Metadata:
- Group: 比如
com.example - Artifact: 比如
demo(这将是你的项目名) - Name: 默认和Artifact一样。
- Package name: 默认和Group+Artifact组合。
- Packaging: Jar (因为我们用内嵌服务器,不需要war包)。
- Java: 选择你本地JDK的版本,比如17或21。
- Group: 比如
- Dependencies: 这是关键!点击“Add Dependencies...”,搜索并添加:
Spring Web: 用于构建Web应用和RESTful API。Spring Boot DevTools: 这个是开发利器,可以实现热部署,修改代码后自动重启应用,非常方便。
生成并下载项目: 配置好后,点击“Generate”按钮,你会得到一个zip文件。解压它。
导入到IDE: 打开你喜欢的IDE(比如IntelliJ IDEA、Eclipse),选择“Import Project”或“Open”,然后指向你解压后的项目根目录。IDE会自动识别这是一个Maven或Gradle项目,并帮你导入所有依赖。
编写你的第一个应用: 找到
src/main/java/com/example/demo(或者你自己的包名)下的主应用类,通常是DemoApplication.java。在这个类的同级目录下,新建一个Java类,比如
HelloController.java:package com.example.demo; // 确保包名正确 import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController // 这是一个REST控制器 public class HelloController { @GetMapping("/hello") // 映射到 /hello 路径的GET请求 public String hello() { return "Hello, Spring Boot! 这是我的第一个应用。"; } }一个小提示:
@RestController其实是@Controller和@ResponseBody的组合,意味着这个类的所有方法都会直接返回数据(比如字符串、JSON),而不是视图。运行应用: 在IDE里,找到主应用类(
DemoApplication.java),右键点击,选择“Run 'DemoApplication.main()'”。或者你也可以在命令行进入项目根目录,运行mvn spring-boot:run(如果是Maven项目)。你会看到控制台输出Spring Boot的启动日志,最后会显示类似“Started DemoApplication in X.XXX seconds (JVM running for Y.YYY)”的信息,并且提示Tomcat在某个端口(默认8080)启动。
验证: 打开浏览器,访问
http://localhost:8080/hello。如果一切顺利,你将看到“Hello, Spring Boot! 这是我的第一个应用。”这句话。
恭喜你!你已经成功搭建并运行了你的第一个Spring Boot应用。从这里开始,你可以尝试修改HelloController的代码,比如添加一个带参数的接口,或者返回一个JSON对象,DevTools的魔力就会显现,你改完代码保存后,应用会自动重启,刷新浏览器就能看到效果。这种即时反馈的开发体验,是Spring Boot让人爱不释手的原因之一。
Spring Boot项目实战:如何集成数据库与构建一个简单的CRUD应用?
光是跑个“Hello World”当然不够,Spring Boot的强大在于它能让你快速构建真实世界的应用。集成数据库是绝大多数应用绕不开的话题,下面我们就以一个简单的用户管理(CRUD:创建、读取、更新、删除)为例,看看如何用Spring Boot和Spring Data JPA来搞定数据库操作。
这里我们选用H2数据库,因为它是一个内存数据库,非常适合开发和测试,不需要额外安装,启动应用时会自动创建数据库和表。当然,换成MySQL、PostgreSQL也只是改几个配置和依赖的事儿。
添加数据库相关依赖: 回到
start.spring.io或者直接修改你项目里的pom.xml(如果是Maven)。在org.springframework.boot spring-boot-starter-data-jpa com.h2database h2 runtime 小提醒: 如果是Spring Boot 3.x,MySQL连接器可能需要
mysql-connector-j。配置数据源: 在
src/main/resources目录下的application.properties(或者application.yml)文件中添加数据库配置。# H2 Database Configuration spring.datasource.url=jdbc:h2:mem:testdb spring.datasource.driverClassName=org.h2.Driver spring.datasource.username=sa spring.datasource.password= spring.h2.console.enabled=true # 开启H2控制台,方便查看数据 spring.h2.console.path=/h2-console # H2控制台访问路径 # JPA Configuration (可选,但推荐) spring.jpa.hibernate.ddl-auto=update # 启动时自动更新数据库表结构 spring.jpa.show-sql=true # 在控制台打印SQL语句 spring.jpa.properties.hibernate.format_sql=true # 格式化SQL语句
ddl-auto=update在开发阶段很方便,它会自动根据你的实体类创建或更新表结构。但在生产环境,通常会设置为none或validate,配合Flyway/Liquibase等工具进行数据库版本管理。创建实体(Entity): 新建一个Java类,比如
User.java,表示数据库中的一张表。package com.example.demo.model; // 建议放在model包下 import jakarta.persistence.Entity; import jakarta.persistence.GeneratedValue; import jakarta.persistence.GenerationType; import jakarta.persistence.Id; @Entity // 标记这是一个JPA实体 public class User { @Id // 标记为主键 @GeneratedValue(strategy = GenerationType.IDENTITY) // 自增ID private Long id; private String name; private String email; // 构造函数 (JPA需要无参构造函数) public User() {} public User(String name, String email) { this.name = name; this.email = email; } // Getter和Setter方法 public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } @Override public String toString() { return "User{" + "id=" + id + ", name='" + name + '\'' + ", email='" + email + '\'' + '}'; } }一个小的思考: 为什么需要
@Entity和@Id这些注解?它们是JPA规范的一部分,告诉Hibernate(Spring Data JPA底层默认的ORM框架)如何将Java对象映射到数据库表。创建Repository接口: 新建一个接口,比如
UserRepository.java,继承JpaRepository。package com.example.demo.repository; // 建议放在repository包下 import com.example.demo.model.User; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; @Repository // 标记这是一个Spring管理的组件 public interface UserRepository extends JpaRepository
JpaRepository的User实体,并且它的主键类型是Long。Spring Data JPA的强大之处在于,你不需要写任何实现类,它会自动为你生成这些方法的实现!这简直是开发者的福音,省去了大量样板代码。创建控制器(Controller)处理API请求: 修改或新建一个控制器,比如
UserController.java。package com.example.demo.controller; // 建议放在controller包下 import com.example.demo.model.User; import com.example.demo.repository.UserRepository; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.*; import java.util.List; import java.util.Optional; @RestController @RequestMapping("/api/users") // 所有接口都以 /api/users 开头 public class UserController { @Autowired // 注入UserRepository private UserRepository userRepository; // 创建用户 (Create) @PostMapping public ResponseEntitycreateUser(@RequestBody User user) { User savedUser = userRepository.save(user); return new ResponseEntity<>(savedUser, HttpStatus.CREATED); } // 获取所有用户 (Read All) @GetMapping public List getAllUsers() { return userRepository.findAll(); } // 根据ID获取用户 (Read One) @GetMapping("/{id}") public ResponseEntity getUserById(@PathVariable Long id) { Optional user = userRepository.findById(id); return user.map(value -> new ResponseEntity<>(value, HttpStatus.OK)) .orElseGet(() -> new ResponseEntity<>(HttpStatus.NOT_FOUND)); } // 更新用户 (Update) @PutMapping("/{id}") public ResponseEntity updateUser(@PathVariable Long id, @RequestBody User userDetails) { Optional userOptional = userRepository.findById(id); if (userOptional.isPresent()) { User user = userOptional.get(); user.setName(userDetails.getName()); user.setEmail(userDetails.getEmail()); User updatedUser = userRepository.save(user); return new ResponseEntity<>(updatedUser, HttpStatus.OK); } else { return new ResponseEntity<>(HttpStatus.NOT_FOUND); } } // 删除用户 (Delete) @DeleteMapping("/{id}") public ResponseEntity deleteUser(@PathVariable Long id) { try { userRepository.deleteById(id); return new ResponseEntity<>(HttpStatus.NO_CONTENT); } catch (Exception e) { return new ResponseEntity<>(HttpStatus.INTERNAL_SERVER_ERROR); } } } 一些思考:
@Autowired:这是Spring的依赖注入机制,它会自动找到UserRepository的实例并注入到UserController中。@RequestBody:用于将HTTP请求体中的JSON或XML数据绑定到Java对象上。@PathVariable:用于从URL路径中提取变量。ResponseEntity:提供更灵活的HTTP响应控制,可以设置状态码、头部等。
运行和测试: 再次运行你的Spring Boot应用。
H2控制台: 访问
http://localhost:8080/h2-console。连接信息填jdbc:h2:mem:testdb,用户sa,密码空。点击Connect后,你会看到USER表已经自动创建了。API测试: 你可以使用Postman、Insomnia或者curl来测试这些API。
创建用户 (POST): URL:
http://localhost:8080/api/usersMethod:POSTHeaders:Content-Type: application/jsonBody (Raw JSON):{ "name": "张三", "email": "zhangsan@example.com" }获取所有用户 (GET): URL:
http://localhost:8080/api/usersMethod:GET获取单个用户 (GET): URL:
http://localhost:8080/api/users/1(假设ID为1) Method:GET更新用户 (PUT): URL:
http://localhost:8080/api/users/1Method:PUTHeaders:Content-Type: application/jsonBody (Raw JSON):{ "name": "张三丰", "email": "zhangsanfeng@example.com" }删除用户 (DELETE): URL:
http://localhost:8080/api/users/1Method:DELETE
通过这个例子,你会发现Spring Boot结合Spring Data JPA,让数据库操作变得非常直观和高效。你几乎不需要手写SQL,大部分操作都通过Java对象和Repository接口完成。这种“面向对象”的
今天关于《SpringBoot入门实战详解教程》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于的内容请关注golang学习网公众号!
 Java小程序会员体系设计:分级与权益管理详解
Java小程序会员体系设计:分级与权益管理详解
- 上一篇
- Java小程序会员体系设计:分级与权益管理详解

- 下一篇
- Golang错误处理对比:error与panic性能解析
-

- 文章 · java教程 | 1星期前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95
- Java CompletableFuture 聚合接口优化:用超时兜底把 P95 从 920ms 降到 330ms
- 255浏览 收藏
-
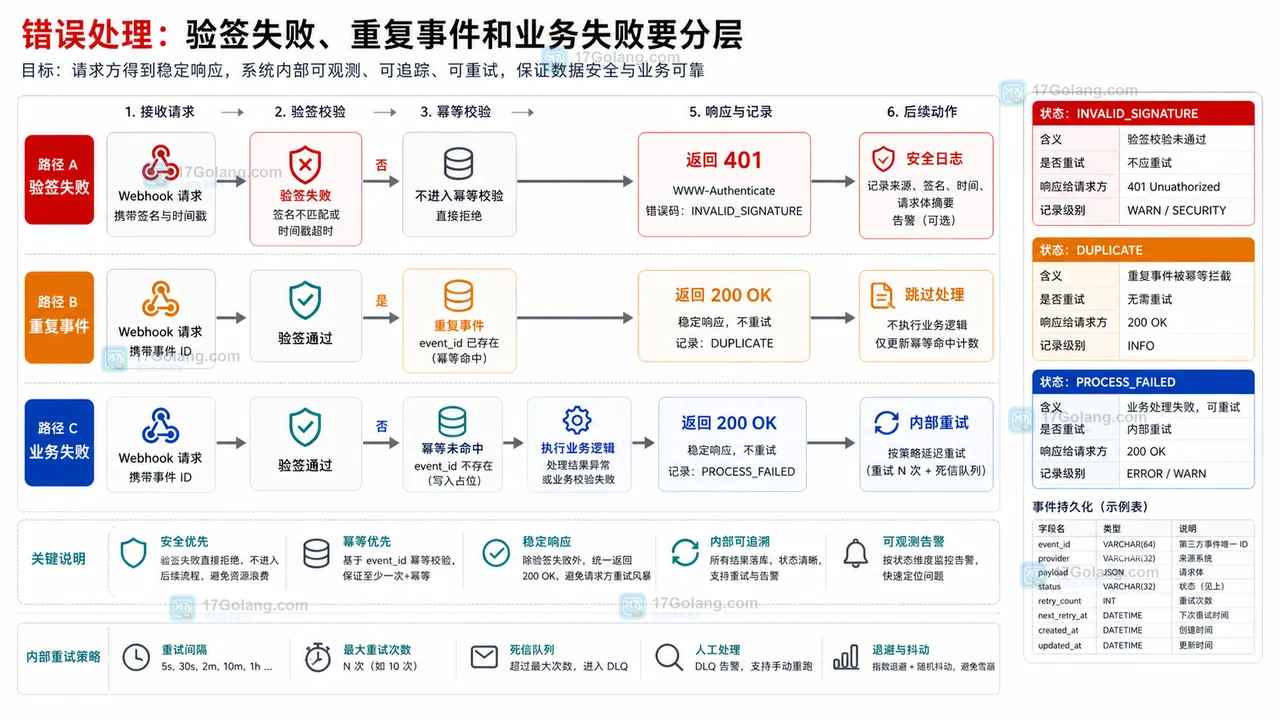
- 文章 · java教程 | 1星期前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签
- Java Webhook 回调接收接口设计:验签、幂等和状态流转
- 488浏览 收藏
-
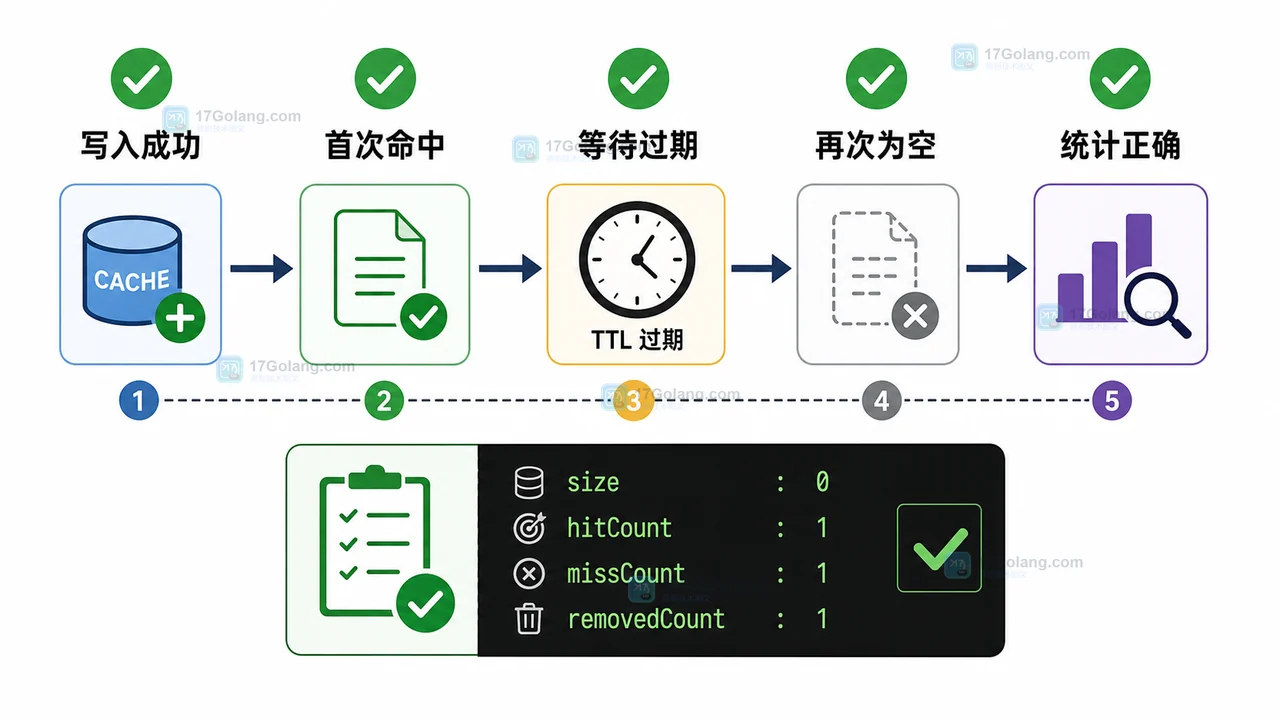
- 文章 · java教程 | 1星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
- Java 本地 TTL 缓存小项目:用 ConcurrentHashMap 实现过期淘汰和命中统计
- 394浏览 收藏
-
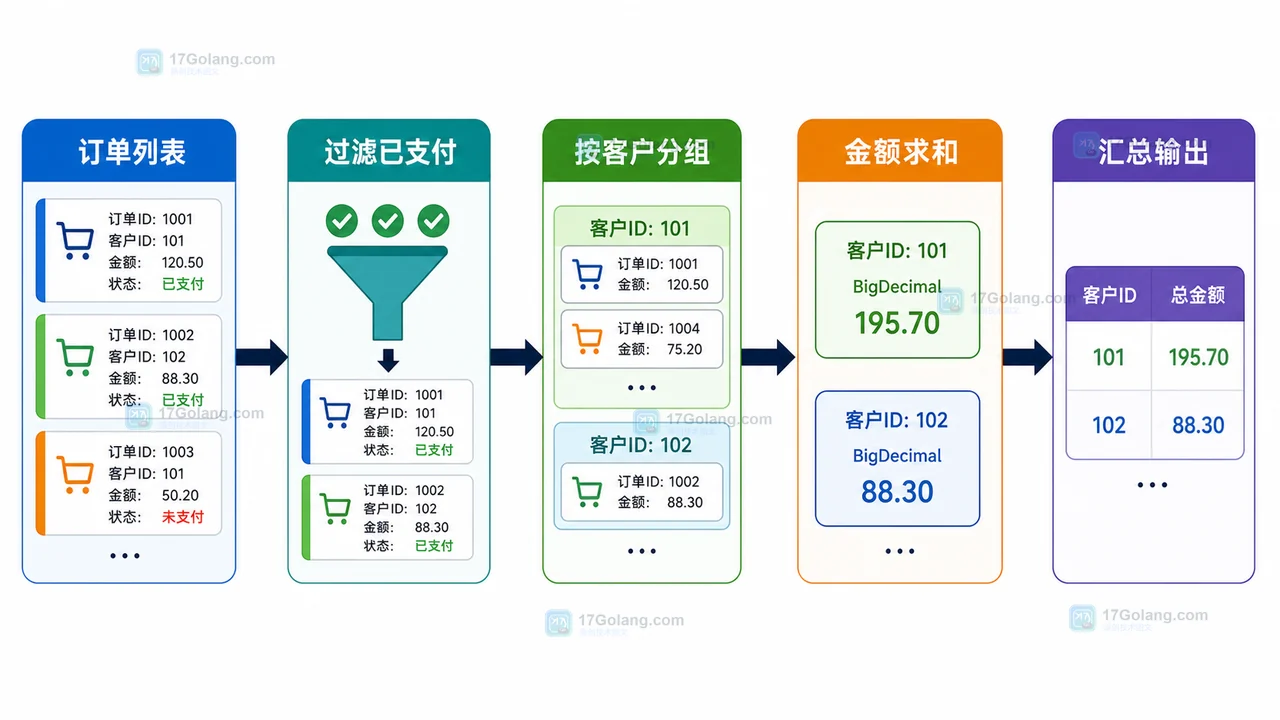
- 文章 · java教程 | 1星期前 | Java · Stream · 数据处理 · 后端教程 · Java Stream bigdecimal 分组统计 Collectors 订单汇总
- Java Stream 分组统计实验:从订单列表到客户消费汇总
- 355浏览 收藏
-
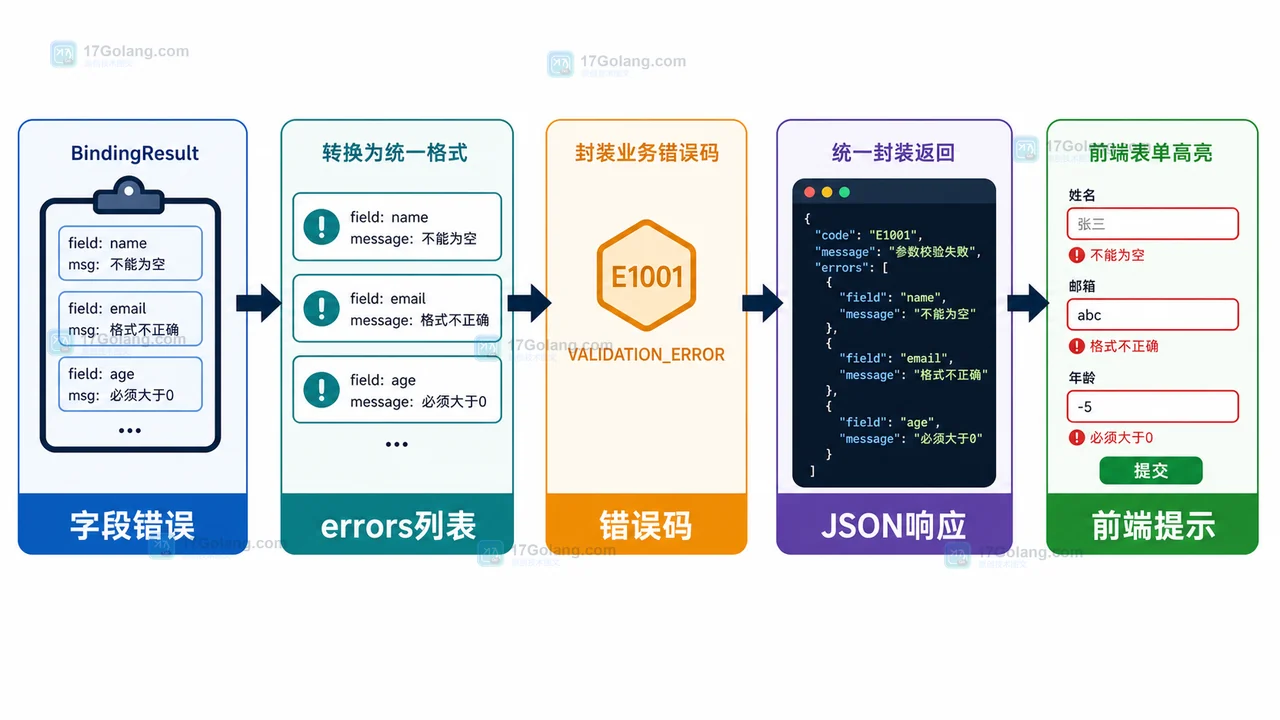
- 文章 · java教程 | 1星期前 | Java · Spring Boot · 后端开发 · 接口校验 · java spring boot dto 接口设计 参数校验
- Spring Boot 参数校验工作流:DTO、注解和统一错误响应
- 495浏览 收藏
-
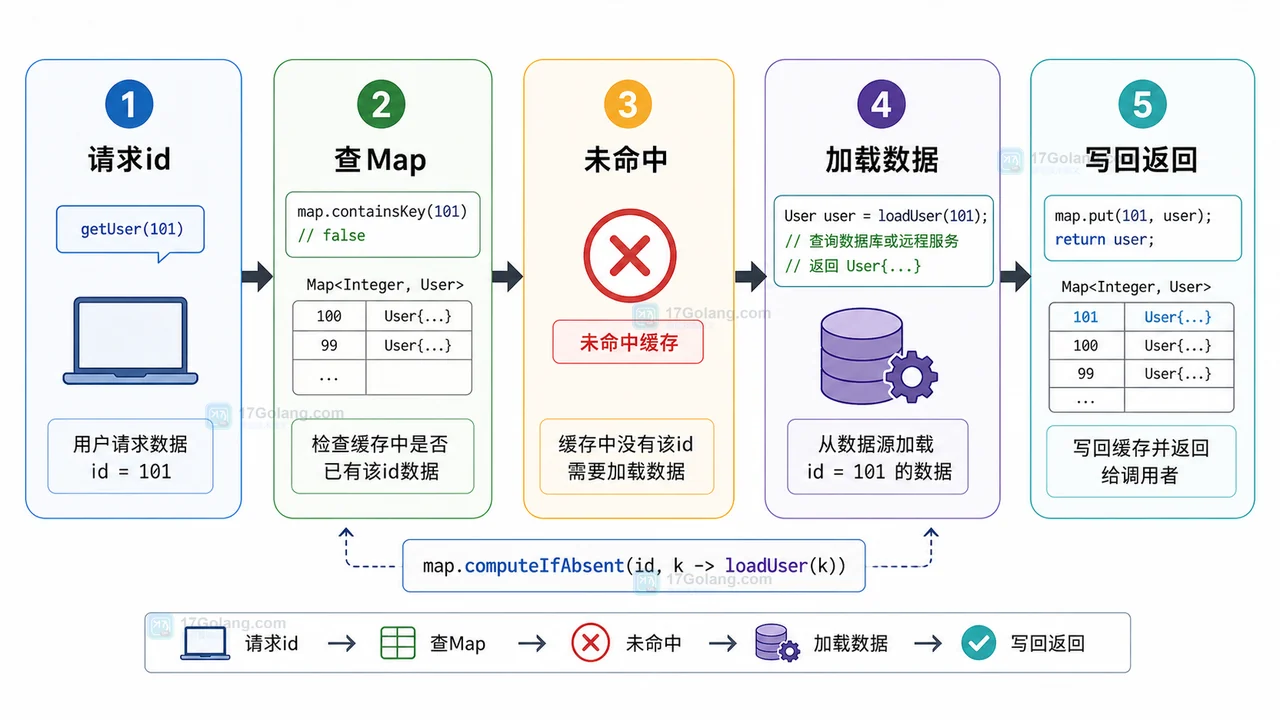
- 文章 · java教程 | 3星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4369次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4048次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4037次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4221次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4190次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


