ELK日志系统与Java集成配置详解
**ELK日志系统与Java集成配置全攻略:打造高效运维监控平台** 在Java应用开发中,日志管理至关重要。本文深入解析如何将Java应用与ELK日志系统(Elasticsearch、Logstash、Kibana)高效集成,实现日志的集中查询、快速故障定位和趋势分析。首先,选择Logback或Log4j2等日志框架,并配置JSON格式输出,通过异步方式发送至Logstash。其次,利用Filebeat采集文件日志,提升数据传输稳定性。Logstash负责解析、转换和优化日志字段,Elasticsearch存储数据并配置索引模板,最后通过Kibana创建索引模式,实现日志的可视化与分析。掌握这些步骤,助您构建强大的日志管理平台,提升DevOps效率,规避常见配置陷阱,并深入挖掘ELK在异常堆栈解析、业务指标埋点与可视化等方面的潜力,结合APM实现全面监控。
Java应用集成ELK的核心在于结构化日志处理与集中管理,具体步骤如下:1.选择Logback或Log4j2作为日志框架,并引入Logstash Appender;2.配置JSON格式输出,通过异步方式发送至Logstash;3.使用Filebeat采集文件日志并传输,提升稳定性;4.Logstash接收日志后进行解析、转换和字段优化;5.Elasticsearch存储日志数据并配置索引模板以确保字段准确性;6.Kibana创建索引模式并实现日志可视化与分析。ELK带来的优势包括日志集中查询、快速故障定位、趋势分析、DevOps效率提升及可扩展性;常见陷阱如网络阻塞、非结构化日志、时区不一致等可通过异步Appender、结构化日志、统一时间标准等方式优化;ELK还可深入支持异常堆栈合并与解析、业务指标埋点与可视化,并结合APM实现全面监控。

这事儿吧,说白了就是把你Java程序里那些散落在文件里的日志,想办法汇集到一个地方,还能方便地查、看、分析。ELK这套组合拳,也就是Elasticsearch、Logstash和Kibana的组合,就是干这活儿的。它能帮你把日志集中起来,让你能像在搜索引擎里搜东西一样去搜日志,还能画图、做报表,方便得不得了。

解决方案
把Java应用的日志搞进ELK,通常有几种做法,我个人觉得,最核心的理念是“结构化”。日志这东西,你光打出来没用,得能被机器读懂,被搜索到,被分析。所以从Java应用端开始,就得有意识地把日志搞成JSON格式,或者至少是Logstash能轻松解析的格式。
Java应用端配置:

- 选择合适的日志框架: 大多数Java项目用Logback或Log4j2。它们都有很好的扩展性。
- 引入Logstash Appender: 最直接的方式是使用专门为Logstash设计的Appender,比如
logstash-logback-encoder(Logback)或logstash-logging-log4j2(Log4j2)。 - 配置日志输出为JSON: 这是关键一步。通过这些Appender,你可以直接把日志事件序列化成JSON格式,然后通过TCP或UDP发送到Logstash。JSON格式的日志天然带有字段,Logstash处理起来非常省心,Elasticsearch索引起来也更准确。
logback.xml示例(片段):%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n your-logstash-host:5044 {"app_name":"my-java-app"} true 512 0 false - 另一种更稳妥的方式:Filebeat + 文件日志: Java应用依然把日志打到本地文件,但使用JSON格式。然后部署Filebeat(Elastic Stack的轻量级数据采集器)去监控这些日志文件,并把它们发送到Logstash或直接发送到Elasticsearch。这种方式更健壮,Filebeat有断点续传、背压机制,对应用本身的性能影响更小。
Logstash配置: Logstash是日志处理的“瑞士军刀”,它负责接收日志、解析、转换、丰富,最后再发送给Elasticsearch。

logstash.conf示例:input { # 接收来自Java应用直接发送的TCP日志 tcp { port => 5044 codec => json_lines # 如果Java应用直接发送JSON行 } # 或者接收来自Filebeat的日志 beats { port => 5044 # Filebeat默认端口 } } filter { # 如果日志已经是JSON格式,直接解析 json { source => "message" # 假设日志内容在message字段 target => "log_data" # 解析后的JSON放入log_data字段 remove_field => ["message"] # 移除原始message字段 } # 如果有非JSON的字段,可能需要Grok等进一步解析 # grok { # match => { "message" => "%{COMBINEDAPACHELOG}" } # } # 添加或修改字段 mutate { add_field => { "env" => "production" } copy => { "[log_data][level]" => "loglevel" } # 复制一个字段 remove_field => ["host"] # 移除不必要的字段 } # 日期解析,确保Elasticsearch能正确识别时间戳 date { match => [ "[log_data][timestamp]", "ISO8601", "yyyy-MM-dd HH:mm:ss.SSS" ] target => "@timestamp" # 确保解析后的时间戳存入@timestamp字段 } } output { elasticsearch { hosts => ["your-elasticsearch-host:9200"] index => "java-app-logs-%{+YYYY.MM.dd}" # 按日期生成索引,方便管理 # user => "elastic" # 如果Elasticsearch开启了安全认证 # password => "changeme" } # 调试时可以输出到控制台 # stdout { codec => rubydebug } }Elasticsearch配置: Elasticsearch主要负责存储和索引日志数据。你不需要为Java日志做太多额外配置,只要确保它在运行,并且Logstash有权限写入数据就行。不过,我强烈建议你为日志数据配置索引模板 (Index Template)。这能保证你的日志字段类型正确,避免Elasticsearch自动推断错误,导致查询困难。比如,
message字段应该设为text,level设为keyword,数字字段设为long或double。Kibana配置: Kibana是日志的可视化界面。
- 创建索引模式 (Index Pattern): 在Kibana里,根据你Elasticsearch里的索引名称(比如
java-app-logs-*)创建索引模式。 - 探索与可视化: 创建完索引模式,你就可以在Discover页面查看日志了。然后,你可以在Visualize和Dashboard页面构建各种图表和仪表盘,比如按日志级别统计、查看特定接口的响应时间分布、追踪某个用户ID的所有操作轨迹等等。
- 创建索引模式 (Index Pattern): 在Kibana里,根据你Elasticsearch里的索引名称(比如
ELK日志集成对Java开发有哪些实际好处?
说句大实话,以前没ELK的时候,排查线上问题那真是要命。一台一台服务器上去grep,眼睛都看花了。有了ELK,你输入个traceId,或者一个关键词,所有相关的日志就都出来了,效率提升不是一点半点。
- 集中化管理与查询: 这是最直接的好处。无论你的Java应用部署在多少台服务器上,日志都汇集到ELK,你只需要一个Kibana界面就能搜索和查看所有日志,告别SSH地狱。
- 快速故障定位与排查: 当系统出现问题时,你可以迅速通过关键词、时间范围、日志级别等条件过滤日志,快速定位到异常发生的代码位置、请求链路,甚至关联到其他微服务的日志。
- 可视化与趋势分析: Kibana强大的可视化能力,能让你把日志数据变成各种图表,比如错误日志趋势图、接口调用量、响应时间分布等。这不仅有助于日常监控,还能发现潜在的性能瓶颈或业务异常。
- 提升DevOps效率: 开发、运维团队可以共享一个日志平台,沟通成本降低,问题解决速度加快。日志的结构化也为自动化分析和告警奠定了基础。
- 可扩展性: ELK栈本身是为大数据量设计的,可以随着业务增长横向扩展,应对不断增长的日志量。
Java应用日志集成ELK时常见的配置陷阱与优化策略是什么?
我踩过最大的坑,就是一开始图省事,直接用Logback的SocketAppender往Logstash扔日志。结果网络一抖,应用直接卡死。后来才明白,日志这东西,不能影响主业务。所以异步、或者加个Filebeat做中间层,太重要了。
常见陷阱:
- 直接TCP/UDP发送日志阻塞应用: 如果Java应用直接通过TCP或UDP向Logstash发送日志,一旦Logstash处理不过来或者网络出现问题,可能会阻塞Java应用的日志线程,甚至影响主业务。
- 日志格式不统一或非结构化: 如果日志是纯文本,Logstash需要耗费大量CPU资源去解析(比如用Grok),而且解析结果可能不准确,导致查询困难。
- 时区问题: Java应用、Logstash、Elasticsearch、Kibana之间的时区不一致,导致日志时间显示混乱。
- Elasticsearch索引膨胀或映射错误: 不合理的索引策略(比如一天一个索引,但日志量巨大)或者字段映射不正确,会导致Elasticsearch性能下降,甚至存储空间耗尽。
- Logstash成为瓶颈: Logstash配置不当(如Filter过于复杂、Worker数量不足),在高并发日志下成为瓶颈。
优化策略:
- 使用异步Appender或Filebeat:
- 异步Appender: 在Java应用端配置异步日志Appender(如Logback的
AsyncAppender或Logstash Appender自带的asynchronousSending),将日志事件放入队列,由单独的线程发送,避免阻塞主业务。 - Filebeat: 强烈推荐使用Filebeat。它是一个轻量级的日志采集器,部署在应用服务器上,监控日志文件并将数据发送到Logstash或Elasticsearch。Filebeat有内置的背压机制、断点续传、资源占用低等优点,是生产环境的首选。
- 异步Appender: 在Java应用端配置异步日志Appender(如Logback的
- 强制结构化日志(JSON): 从Java应用端就将日志输出为JSON格式。这能极大地简化Logstash的Filter配置,提高处理效率,并确保日志字段的准确性。
- 统一时区: 确保所有组件(Java应用JVM、操作系统、Logstash、Elasticsearch)都使用UTC时间或统一的时区设置。Logstash在处理时间戳时,默认会将所有时间转换为UTC。
- 合理规划Elasticsearch索引与使用索引模板:
- 按日期滚动索引: 比如每天一个索引 (
java-app-logs-YYYY.MM.dd)。 - 使用索引生命周期管理(ILM): 自动管理索引的创建、滚动、冻结、删除,节约存储空间和管理成本。
- 预定义索引模板: 在Elasticsearch中创建索引模板,为日志字段定义正确的映射类型(
keyword、text、long等),避免Elasticsearch自动推断错误。
- 按日期滚动索引: 比如每天一个索引 (
- 优化Logstash配置:
- 增加Worker数量: 根据服务器CPU核心数调整Logstash的
pipeline.workers参数。 - 简化Filter: 尽量减少复杂的Grok解析,如果日志已结构化,
jsonfilter效率最高。 - 使用持久化队列: 开启Logstash的持久化队列,即使Logstash崩溃也能恢复未处理的日志。
- 增加Worker数量: 根据服务器CPU核心数调整Logstash的
ELK如何助力Java应用进行更深层次的监控与故障诊断?
光看INFO日志那点东西,真出问题了,你根本不知道发生了什么。所以,把异常堆栈完整地收上来,并且能被搜索,这才是救命稻草。Logstash那个multiline插件,虽然有点“笨”,但确实能把多行堆栈合并成一条,非常实用。再进一步,业务埋点,把关键业务流程中的数据也打到ELK里,那就能做业务监控了,比如每分钟订单量、支付成功率这些,直接在Kibana上出图,老板看了都说好。
异常堆栈的收集与解析:
- 多行合并: Java异常堆栈通常是多行的。在Logstash中,可以使用
multiline过滤器将多行堆栈合并成一个完整的日志事件。这使得在Kibana中搜索和查看异常变得非常方便。 - 示例 Logstash
multiline配置:filter { # ... 其他filter multiline { pattern => "^%{TIMESTAMP_ISO8601}" # 根据日志行开头的时间戳模式识别新行 negate => true # 如果不匹配模式,则认为是前一行的延续 what => "previous" # 合并到前一行 max_lines => 500 # 最大合并行数 max_bytes => "1MB" # 最大合并字节数 timeout_millis => 5000 # 超时时间,避免等待过久 } # 针对合并后的异常信息进行进一步解析,提取关键信息 grok { match => { "message" => "(?[a-zA-Z0-9\._$]+Exception):?.*" } # ... 更多解析规则 } } - 深度分析: 结合Kibana,你可以统计异常类型、发生频率、关联的请求ID,甚至通过堆栈信息追溯到具体代码行,大大加速故障诊断。
- 多行合并: Java异常堆栈通常是多行的。在Logstash中,可以使用
业务指标的日志化与可视化: 除了传统的系统日志,你还可以将Java应用中的关键业务指标作为结构化日志输出到ELK。
- 埋点日志: 在业务代码中,将关键事件(如用户注册、订单创建、支付成功/失败、库存扣减等)以JSON格式记录到日志中。
// 示例:记录订单创建事件 Map
- Logstash处理: Logstash可以轻松解析这些JSON日志,将其中的字段提取出来。
- Kibana可视化: 在Kibana中,你可以基于这些业务指标日志创建各种可视化图表,如:
- 每日/每小时订单量趋势图
- 支付成功率漏斗图
- 不同产品销售量柱状图
- 用户活跃度曲线图
- 业务告警: 结合Elasticsearch的Watcher或Kibana的Alerting功能,可以对这些业务指标设置阈值告警,比如订单量突然下降、支付失败率飙升时,及时通知相关人员。
- 埋点日志: 在业务代码中,将关键事件(如用户注册、订单创建、支付成功/失败、库存扣减等)以JSON格式记录到日志中。
集成APM (Application Performance Monitoring): 虽然严格意义上APM不全是“日志”,但Elastic Stack提供了APM解决方案,通过在Java应用中
今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 Linux数据库优化技巧大全
Linux数据库优化技巧大全
- 上一篇
- Linux数据库优化技巧大全

- 下一篇
- Python类与对象关系详解
-
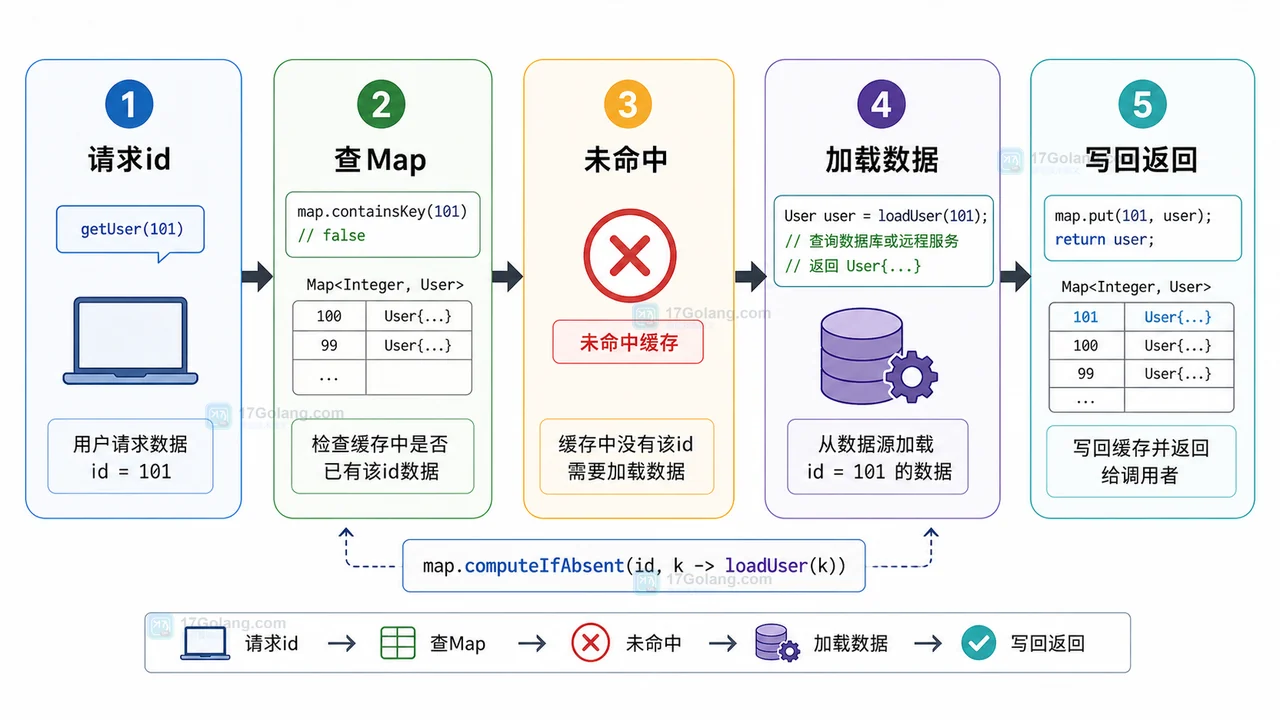
- 文章 · java教程 | 1星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-
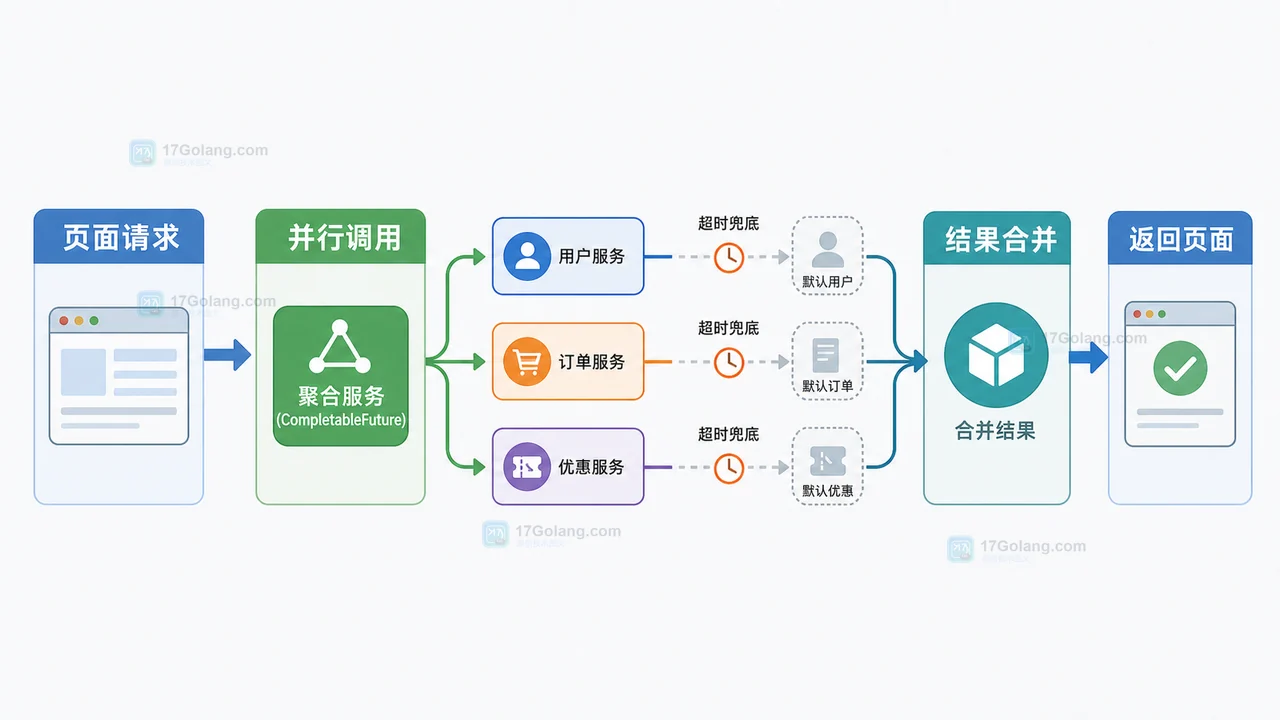
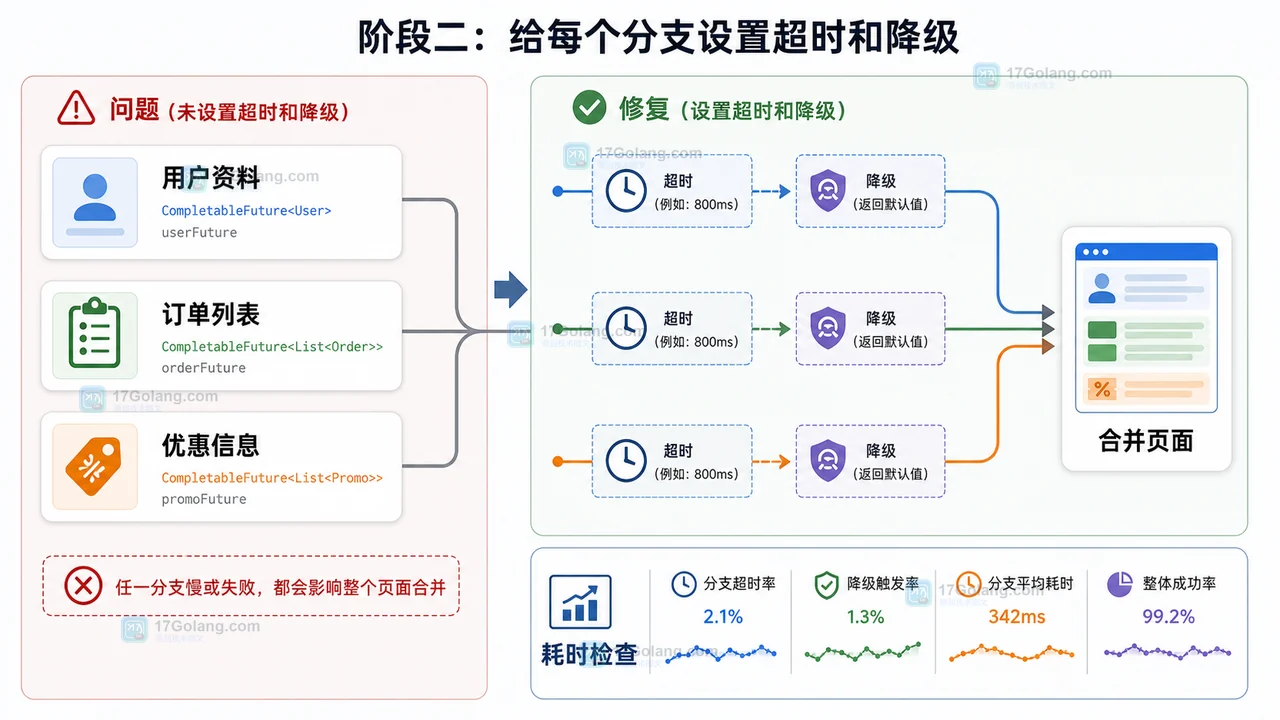
- 文章 · java教程 | 1星期前 | Java · 异步编程 · 后端开发 · CompletableFuture · 接口聚合 · java 结果合并 completablefuture 并行调用 超时兜底
- Java CompletableFuture 多接口聚合完整流程:并行调用、超时兜底和结果合并
- 428浏览 收藏
-
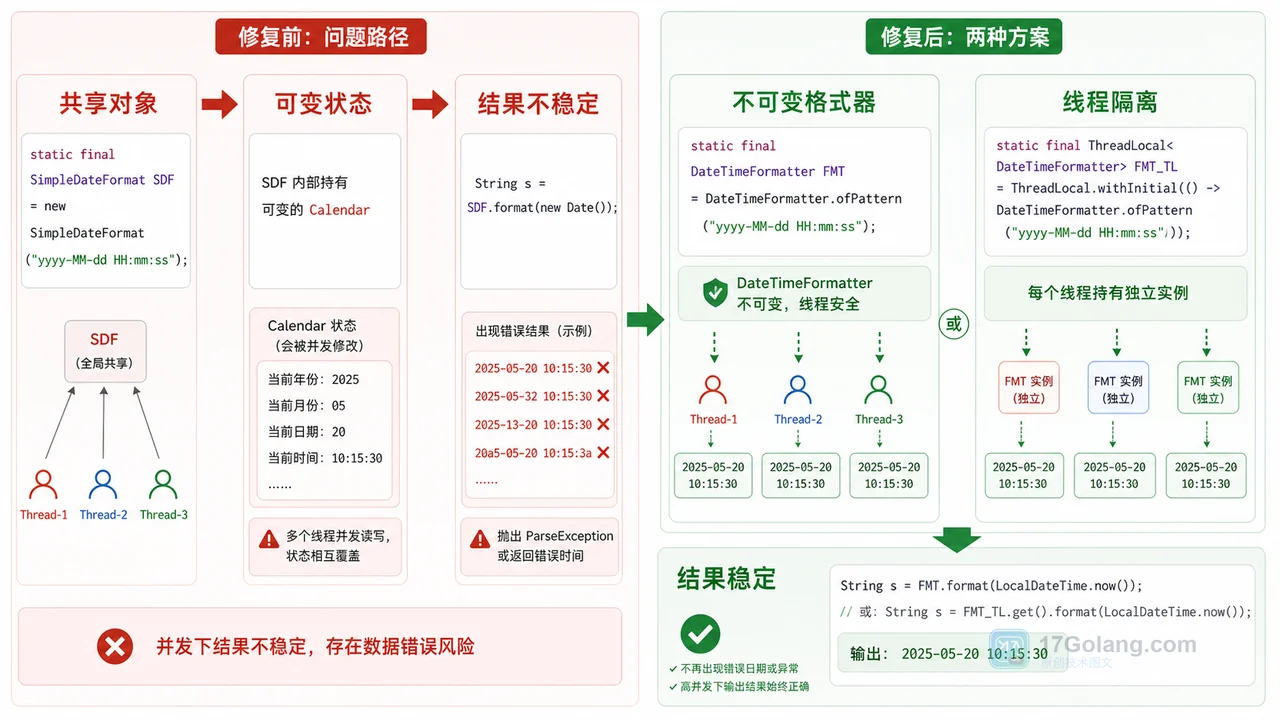
- 文章 · java教程 | 1星期前 | Java · 线程安全 · DateTimeFormatter · 日期处理 · 并发问题 · java 线程安全 日期格式化 threadlocal SimpleDateFormat DateTimeFormatter
- Java SimpleDateFormat 日期偶发错乱怎么办:从共享实例到线程安全一步步排查
- 481浏览 收藏
-
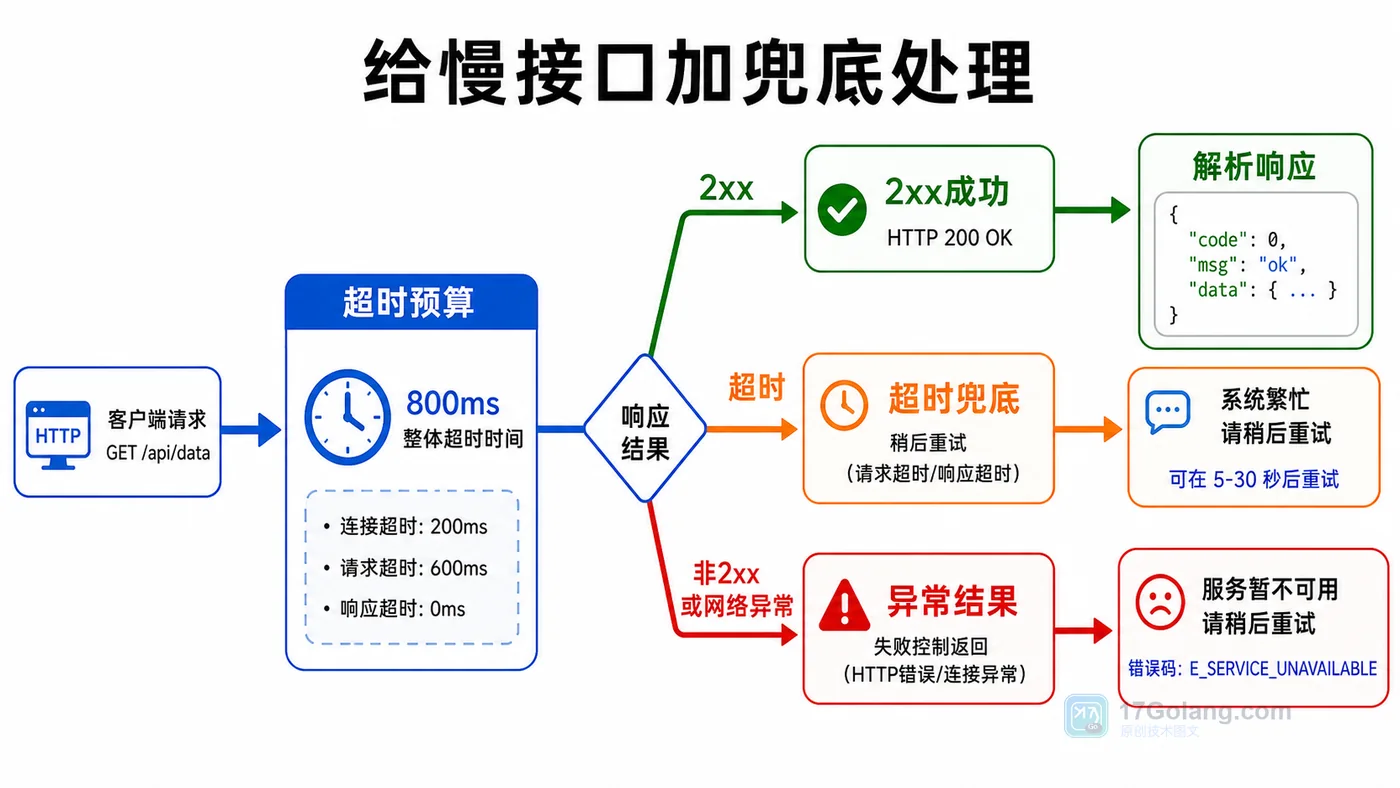
- 文章 · java教程 | 1星期前 | http接口 · httpclient · Java教程 · 接口调试 · 超时处理 · java 接口调用 httpclient 超时控制 状态码 响应体
- Java HttpClient 调接口实战:超时、状态码和响应体这样处理
- 224浏览 收藏
-
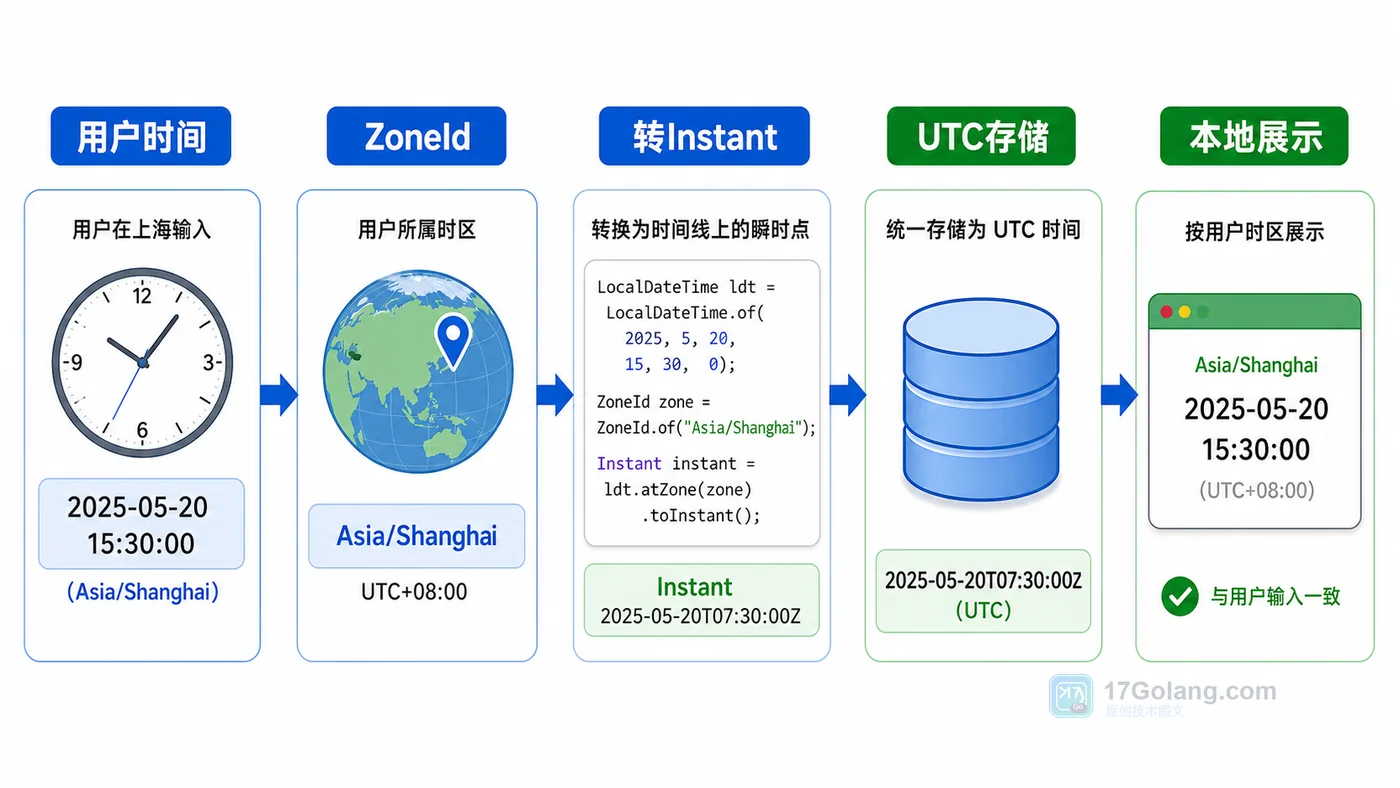
- 文章 · java教程 | 1星期前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT
- Java 时间与时区处理实战:Instant、ZoneId 和 DateTimeFormatter 怎么配
- 461浏览 收藏
-
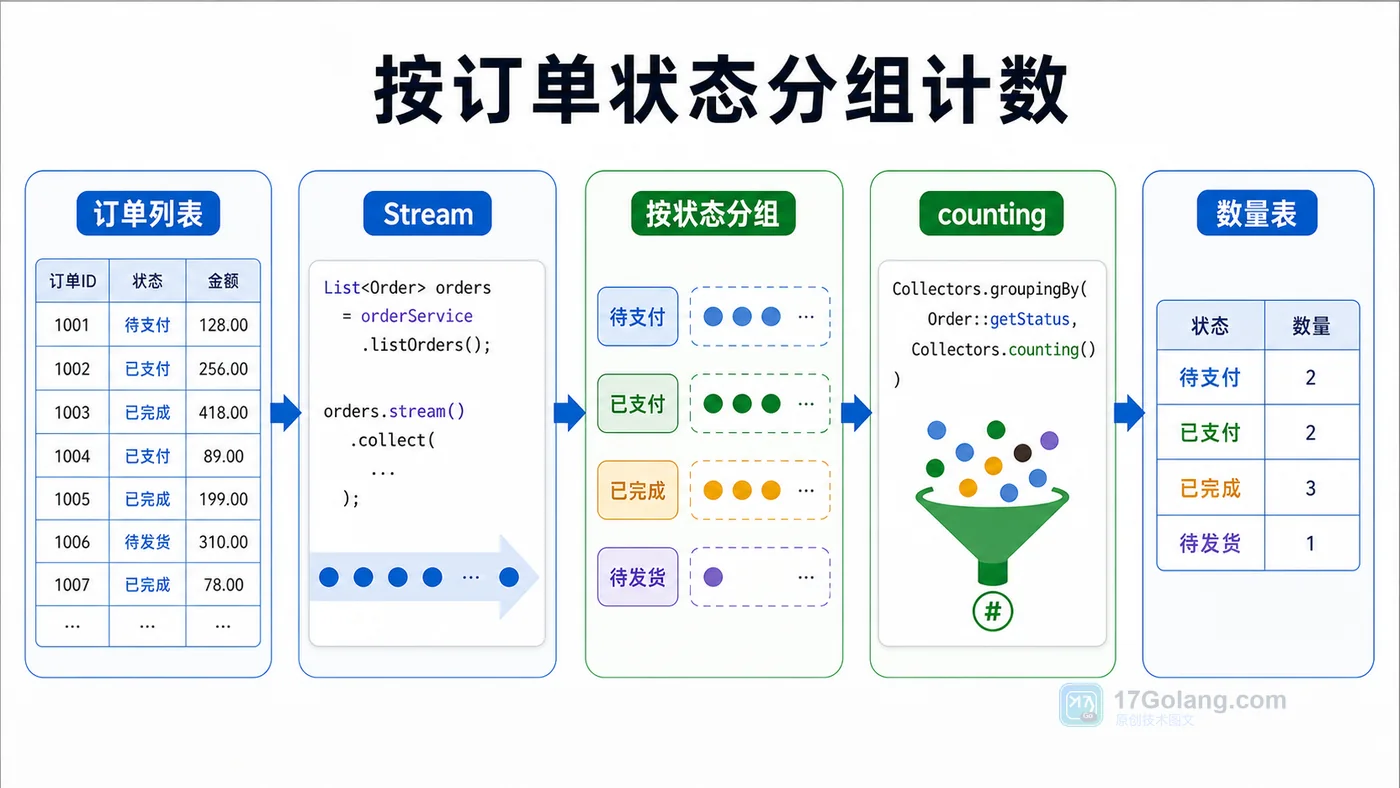
- 文章 · java教程 | 1星期前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
- Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
- 478浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2188次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2004次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1946次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2164次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2128次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


