async/await简化异步代码的使用方式
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《JS 中 async/await 的作用与使用场景》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
async/await 是 ES2017 引入的语法糖,核心作用是让异步代码写起来像同步代码,提升可读性和维护性;2. 使用场景包括网络请求、数据库操作、文件读写等需等待异步结果的场合;3. 注意错误必须用 try...catch 捕获,避免未处理的 Promise 拒绝;4. 多个不依赖的异步任务应使用 Promise.all() 并行执行,避免串行性能损耗;5. async 函数始终返回 Promise,可被 .then() 处理或在其他 async 函数中 await,完整支持 Promise 生态。

async/await 在 JavaScript 中,主要是为了让异步代码的编写和阅读变得更像同步代码,极大地提升了处理 Promise 的体验,让原本复杂的异步流程变得直观且易于维护。它的核心作用就是将基于回调或 .then() 链式的异步操作,转化为一种看起来是阻塞式、顺序执行的风格,但实际上仍然是非阻塞的。至于使用场景,凡是涉及到需要等待某个异步操作结果才能进行下一步处理的地方,它都能派上用场,比如网络请求、文件读写或者数据库操作等等。

解决方案
async/await 是 ES2017 引入的语法糖,构建在 Promise 之上。理解它,得从两个关键词说起:
首先是 async 关键字,它用来定义一个函数。任何被 async 修饰的函数,都会自动返回一个 Promise 对象。即便你函数内部没有显式返回 Promise,它也会帮你包一层。比如:

async function greet() {
return "Hello, world!";
}
greet().then(message => console.log(message)); // 输出: Hello, world!这个 Promise 会在 async 函数执行完毕时被解决(resolve),其解决值就是函数返回的值。如果函数内部抛出错误,Promise 就会被拒绝(reject)。
接着是 await 关键字,它只能在 async 函数内部使用。await 的作用是暂停 async 函数的执行,直到它等待的 Promise 状态变为已解决(resolved)或已拒绝(rejected)。一旦 Promise 解决,await 就会返回 Promise 的解决值;如果 Promise 拒绝,await 就会抛出一个错误。

比如,我们有个模拟异步操作的函数:
function fetchData() {
return new Promise(resolve => {
setTimeout(() => {
resolve("Data fetched successfully!");
}, 2000);
});
}
async function processData() {
console.log("Starting data fetch...");
try {
const data = await fetchData(); // 暂停这里,等待 fetchData 的 Promise 解决
console.log(data); // 2秒后输出: Data fetched successfully!
console.log("Data processing complete.");
} catch (error) {
console.error("Error fetching data:", error);
}
}
processData();
console.log("This line executes immediately, not waiting for processData to finish.");在这个例子里,processData 函数虽然看起来是顺序执行的,但在 await fetchData() 那一行,processData 会“暂停”,让出执行权,直到 fetchData 返回的 Promise 完成。这使得异步流程的控制变得异常直观,避免了层层嵌套的 .then() 回调。
async/await 如何让异步代码更易读和维护?
说实话,我个人觉得 async/await 简直是 JavaScript 异步编程的救星。在此之前,我们处理异步通常是回调函数或者 Promise 的 .then() 链。回调地狱(Callback Hell)就不用说了,那简直是噩梦。Promise .then() 链虽然好一些,但当逻辑复杂,比如需要多次依赖上一个 Promise 的结果,或者有条件分支时,链条就会变得很长,阅读起来还是有点费劲,尤其是错误处理,得在每个 .then() 后面加 .catch() 或者在链的末尾统一处理,有时候总感觉不够“自然”。
async/await 的出现,直接把这种“自然”的感觉带回来了。它让你的异步代码看起来就像是同步代码一样,从上到下,一步一步执行。这极大地提升了代码的可读性。你不再需要费力去追踪那些散落在各处的 .then() 回调,代码流清晰明了,一眼就能看出逻辑顺序。
更重要的是错误处理。在 async 函数内部,你可以直接使用我们熟悉的 try...catch 语句来捕获 await 表达式可能抛出的错误。这和处理同步代码的错误方式完全一致,大大降低了心智负担。比如,你有一个请求用户信息的 fetchUser 和请求用户订单的 fetchOrders 两个异步操作,并且 fetchOrders 依赖 fetchUser 的结果:
async function getUserAndOrders(userId) {
try {
const user = await fetchUser(userId); // 假设 fetchUser 返回 Promise
console.log(`Fetched user: ${user.name}`);
// 如果 fetchUser 失败,这里就不会执行
const orders = await fetchOrders(user.id); // 假设 fetchOrders 依赖 user.id
console.log(`Fetched orders for ${user.name}:`, orders);
return { user, orders };
} catch (error) {
// 任何一个 await 失败,都会被这里捕获
console.error("Failed to get user or orders:", error.message);
// 可以在这里做一些错误恢复或者返回默认值
throw new Error("Operation failed due to an internal error."); // 重新抛出错误
}
}
// 调用示例
getUserAndOrders(123)
.then(data => console.log("Success:", data))
.catch(err => console.error("Outer catch:", err.message));
// 模拟函数
function fetchUser(id) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (id === 123) {
resolve({ id: 123, name: "Alice" });
} else {
reject(new Error("User not found!"));
}
}, 500);
});
}
function fetchOrders(userId) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (userId === 123) {
resolve([{ orderId: "A001" }, { orderId: "A002" }]);
} else {
reject(new Error("No orders for this user!"));
}
}, 700);
});
}这种 try...catch 的模式,让异步代码的错误处理变得和同步代码一样直观,维护起来自然也更轻松。
async/await 在实际开发中有哪些常见的应用场景?
实际项目中,async/await 的身影几乎无处不在,只要你和“等待”打交道,它就特别好用。
最最常见的,那肯定是 API 网络请求了。无论是前端的 fetch API 还是 Node.js 后端的 axios、node-fetch,它们返回的都是 Promise。用 async/await 来封装这些请求,代码简直清晰得不得了。比如:
async function fetchProductDetails(productId) {
try {
const response = await fetch(`/api/products/${productId}`);
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data;
} catch (error) {
console.error("Failed to fetch product details:", error);
// 可以返回一个默认值或者重新抛出错误
return null;
}
}
// 调用
fetchProductDetails(456).then(product => {
if (product) {
console.log("Product:", product.name);
}
});其次,数据库操作也是 async/await 的重度使用者。无论你用的是 Mongoose(MongoDB),Sequelize(SQL),还是其他 ORM/ODM 库,它们的方法大多都返回 Promise。在 Node.js 后端服务中,处理用户请求、查询数据库、更新数据等一系列操作,用 async/await 串联起来,业务逻辑一目了然。
// 假设这是在 Node.js 后端,使用 Mongoose
async function createUserAndProfile(userData, profileData) {
const session = await mongoose.startSession(); // 开启事务
session.startTransaction();
try {
const newUser = await User.create([userData], { session });
profileData.userId = newUser[0]._id; // 关联用户ID
await Profile.create([profileData], { session });
await session.commitTransaction(); // 提交事务
console.log("User and profile created successfully.");
return newUser[0];
} catch (error) {
await session.abortTransaction(); // 回滚事务
console.error("Failed to create user or profile:", error);
throw error;
} finally {
session.endSession();
}
}再来就是 文件系统操作 (Node.js)。Node.js 的 fs.promises API 提供了 Promise 版本的异步文件操作方法,结合 async/await,读写文件变得非常顺滑:
const fs = require('fs').promises;
async function readFileAndProcess(filePath) {
try {
const content = await fs.readFile(filePath, 'utf8');
console.log("File content:", content.toUpperCase());
await fs.writeFile(`${filePath}.bak`, content); // 写入备份
console.log("Backup created.");
} catch (error) {
console.error("Error processing file:", error);
}
}
readFileAndProcess('mydata.txt');还有一些场景,比如 执行依赖于前一个异步结果的连续操作,或者 在浏览器环境中,等待一些特定事件或动画完成(通过将事件封装成 Promise)。总之,只要你的代码流程中包含“等待一个异步结果再继续”的逻辑,async/await 都是一个极佳的选择。
使用 async/await 时需要注意哪些“坑”或最佳实践?
虽然 async/await 带来了巨大的便利,但用起来还是有些地方需要留心,不然可能会踩到一些小“坑”,或者写出效率不高的代码。
首先,也是最重要的一点,是 错误处理。我见过不少人,觉得 async/await 看起来像同步代码,就忘了它本质还是 Promise,结果没有用 try...catch 包裹 await 调用。这样一来,如果 await 的 Promise 拒绝了,这个错误就会变成一个未捕获的 Promise 拒绝(Unhandled Promise Rejection),在 Node.js 环境下可能会导致进程崩溃,在浏览器里也可能只是在控制台打印个错误,但你无法优雅地处理它。所以,记住,只要有 await,就几乎总要考虑用 try...catch 包裹起来,或者确保在 async 函数的调用链末尾有一个 .catch()。
// 错误示例:可能导致 Unhandled Promise Rejection
async function fetchDataUnsafe() {
const data = await Promise.reject(new Error("Network error!"));
console.log(data); // 这行不会执行
}
fetchDataUnsafe(); // 浏览器或 Node.js 会报告未捕获的拒绝
// 正确姿势:使用 try...catch
async function fetchDataSafe() {
try {
const data = await Promise.reject(new Error("Network error!"));
console.log(data);
} catch (error) {
console.error("Caught error:", error.message);
}
}
fetchDataSafe();
// 或者在调用 async 函数的地方用 .catch()
async function fetchDataSafeOuter() {
const data = await Promise.reject(new Error("Network error!"));
console.log(data);
}
fetchDataSafeOuter().catch(error => console.error("Caught error outside:", error.message));第二个常见的误区是 并行执行。await 会暂停当前 async 函数的执行,直到其等待的 Promise 解决。这意味着如果你有多个不相互依赖的异步操作,并且你用 await 一个接一个地去等待它们,那么它们就会串行执行,白白浪费了异步的并行能力。比如:
// 串行执行,效率较低
async function fetchAllDataSerial() {
console.time("Serial Fetch");
const users = await fetchUsers(); // 等待用户数据
const products = await fetchProducts(); // 等待产品数据,即使它不依赖用户数据
const orders = await fetchOrders(); // 等待订单数据
console.timeEnd("Serial Fetch");
return { users, products, orders };
}
// 推荐:使用 Promise.all() 或 Promise.allSettled() 进行并行执行
async function fetchAllDataParallel() {
console.time("Parallel Fetch");
// 同时发起所有请求,然后等待它们全部完成
const [users, products, orders] = await Promise.all([
fetchUsers(),
fetchProducts(),
fetchOrders()
]);
console.timeEnd("Parallel Fetch");
return { users, products, orders };
}
// 模拟异步函数
function fetchUsers() { return new Promise(r => setTimeout(() => r("Users Data"), 1000)); }
function fetchProducts() { return new Promise(r => setTimeout(() => r("Products Data"), 800)); }
function fetchOrders() { return new Promise(r => setTimeout(() => r("Orders Data"), 1200)); }
fetchAllDataSerial(); // 大约需要 1000 + 800 + 1200 = 3000ms
fetchAllDataParallel(); // 大约只需要 1200ms (取决于最慢的那个)如果你需要等待所有 Promise 完成,即使其中有失败的,并且你想知道每个 Promise 的状态,可以使用 Promise.allSettled()。
还有一点,顶层 await。在 ES 模块(ES Modules)中,现在可以直接在模块的顶层使用 await,而不需要将其包裹在 async 函数中。这在一些脚本或初始化逻辑中非常方便。但在非 ES 模块环境(比如 CommonJS 模块或老旧的浏览器脚本)中,你仍然需要将 await 放在 async 函数内部。
最后,记住 async 函数本身返回的是一个 Promise。这意味着当你调用一个 async 函数时,你得到的是一个 Promise,你仍然可以通过 .then() 和 .catch() 来处理它,或者在另一个 async 函数中 await 它。这是理解 async/await 如何与现有 Promise 生态系统融合的关键。
保持代码的清晰和可维护性,是 async/await 带来的最大价值。合理利用 try...catch 和 Promise.all()/Promise.allSettled(),能让你写出既高效又健壮的异步代码。
今天关于《async/await简化异步代码的使用方式》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
 winmm.dll丢失怎么修复?
winmm.dll丢失怎么修复?
- 上一篇
- winmm.dll丢失怎么修复?

- 下一篇
- DeepSeek院校分析技巧详解
-

- 文章 · 前端 | 41分钟前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
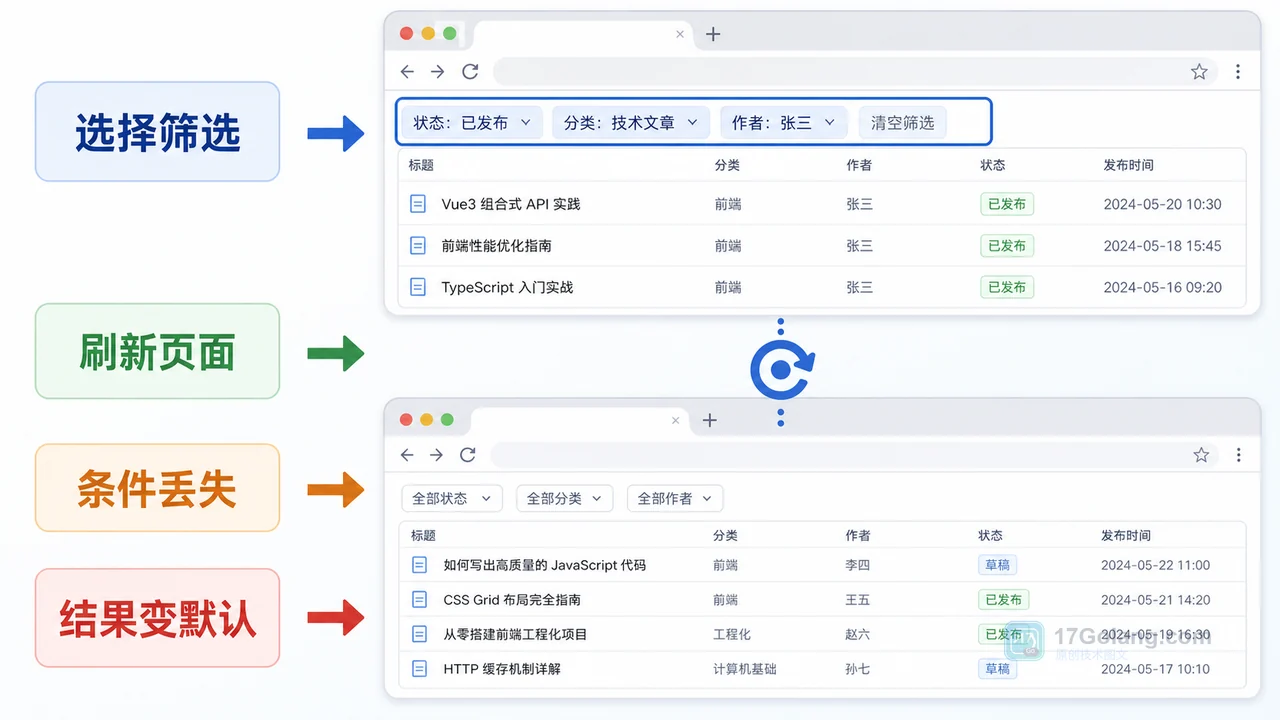
- 文章 · 前端 | 58分钟前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏
-
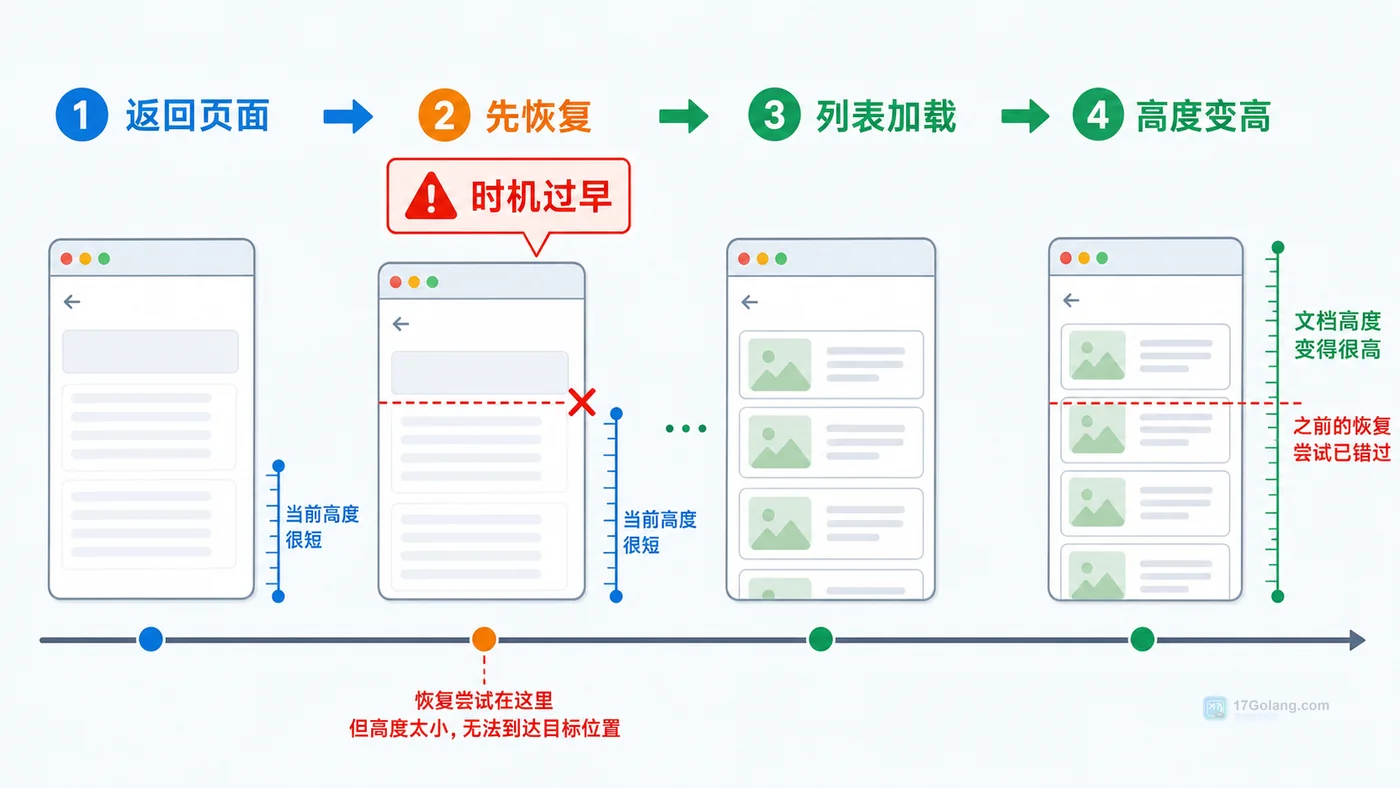
- 文章 · 前端 | 3小时前 | 前端 · 性能优化 · 路由 · javascript · 前端 用户体验 滚动位置 路由缓存 scrollRestoration
- 前端详情页返回列表丢失滚动位置怎么办:从复现到恢复一步步排查
- 458浏览 收藏
-
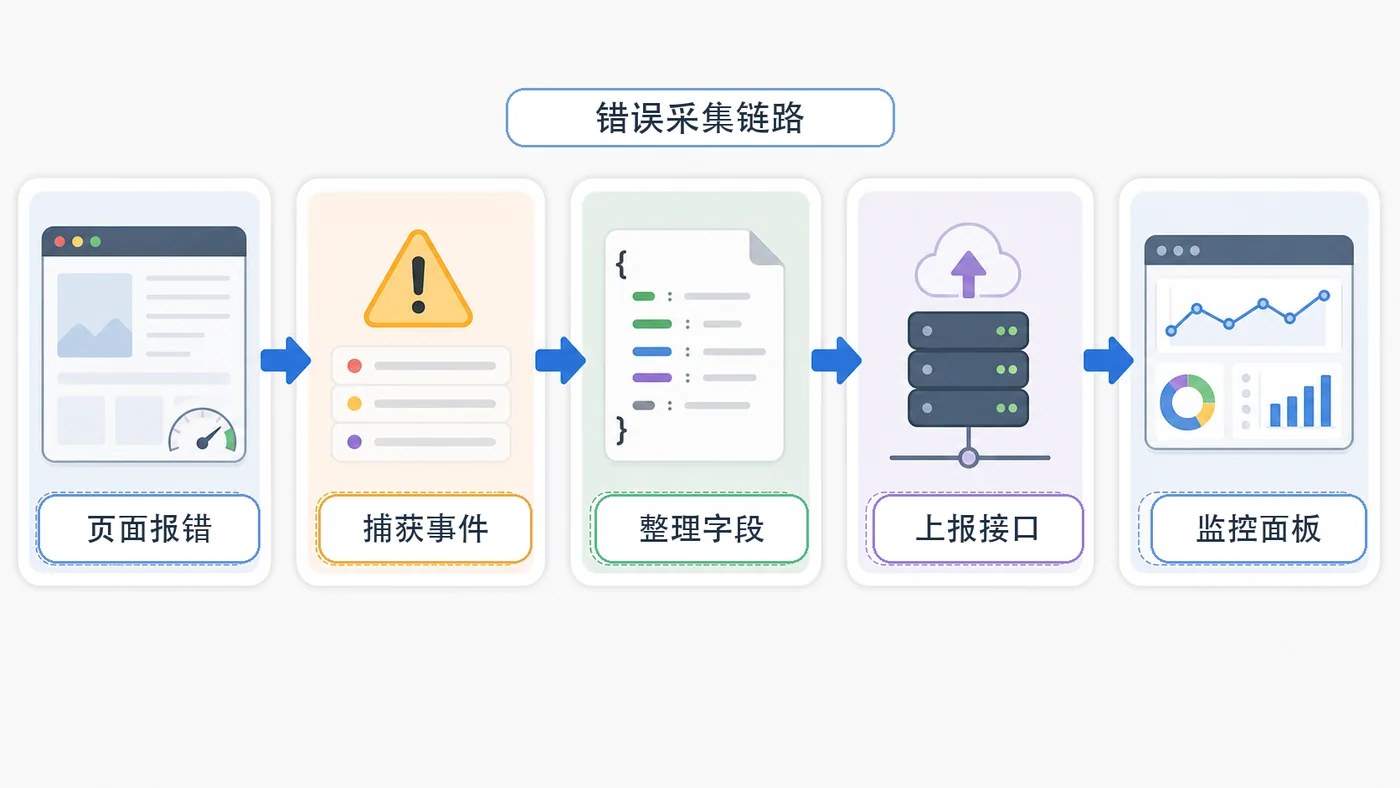
- 文章 · 前端 | 2天前 | 前端 · javascript · sourcemap · 错误监控 · 线上排查 · 前端 错误监控 告警 onerror sourcemap unhandledrejection
- 前端错误监控实战:onerror、unhandledrejection 和 sourcemap 定位问题
- 331浏览 收藏
-
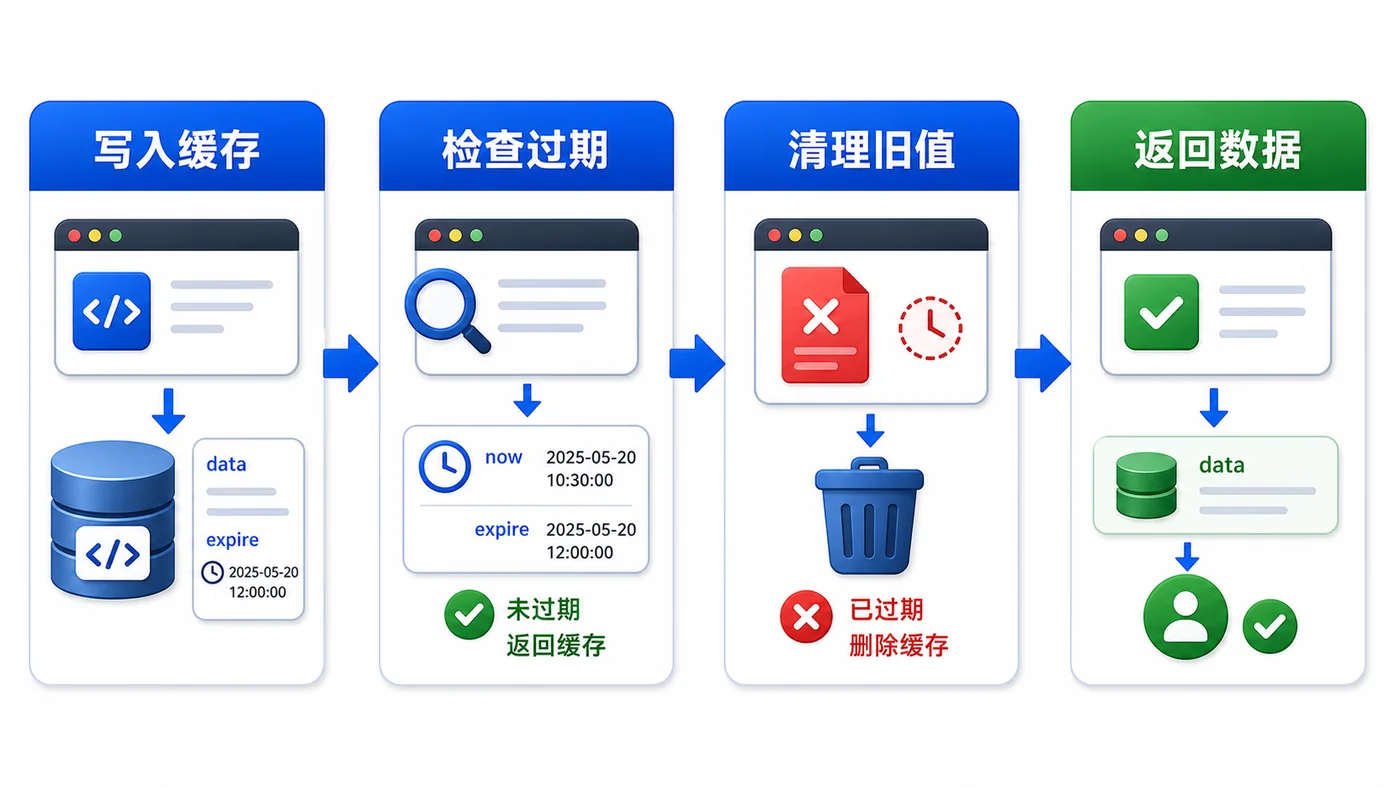
- 文章 · 前端 | 2天前 | 前端 · javascript · 缓存治理 · localStorage · Web性能 · 前端 本地缓存 localStorage 过期时间 版本迁移 异常兜底
- 前端 localStorage 缓存治理实战:过期时间、版本号和异常兜底
- 480浏览 收藏
-
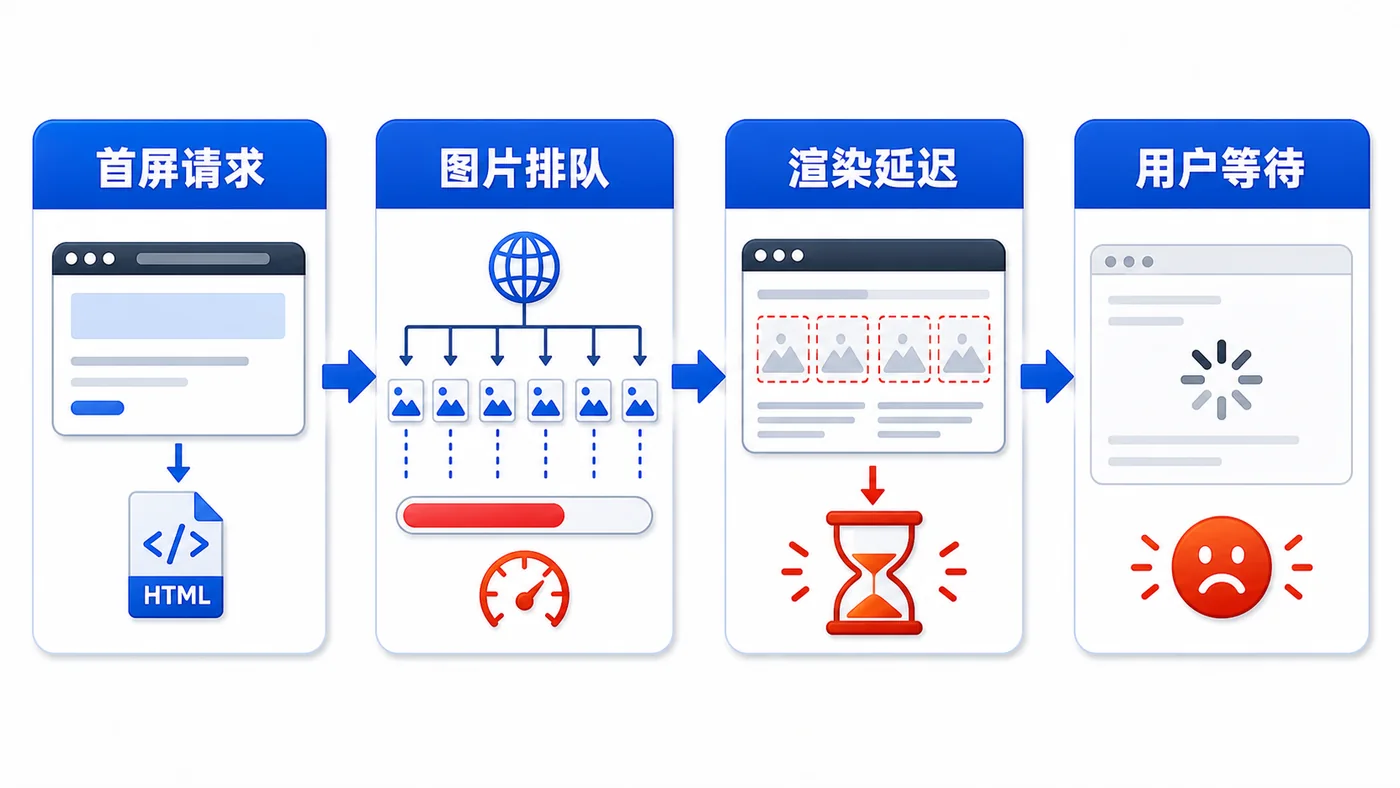
- 文章 · 前端 | 2天前 | 前端 · 性能优化 · javascript · 图片优化 · IntersectionObserver · 前端 性能优化 图片懒加载 IntersectionObserver Web性能 首屏优化
- 前端图片懒加载实战:用 IntersectionObserver 降低首屏压力
- 184浏览 收藏
-
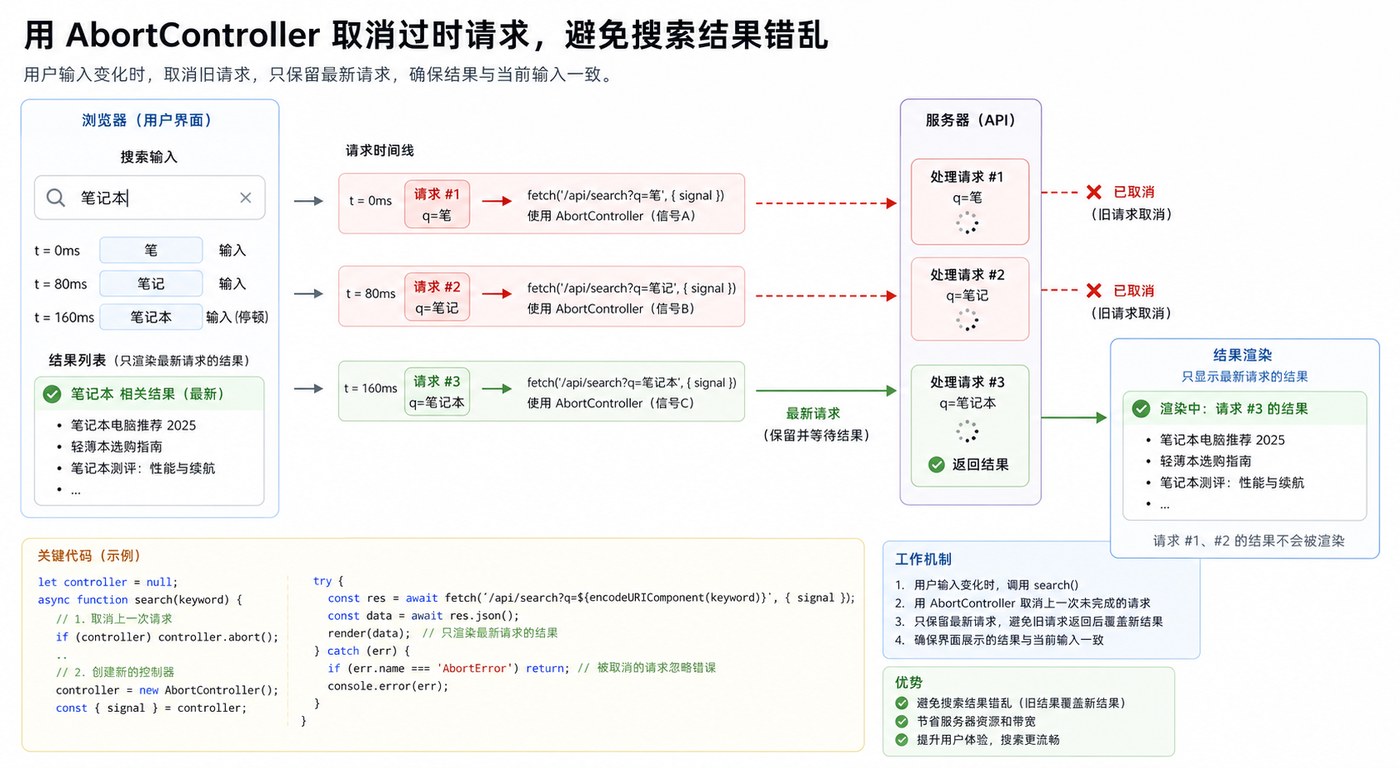
- 文章 · 前端 | 2天前 | 前端 · 性能优化 · javascript · fetch · 前端 搜索优化 Fetch AbortController 请求竞态
- 前端搜索竞态治理实战:用 AbortController 取消过期请求
- 178浏览 收藏
-
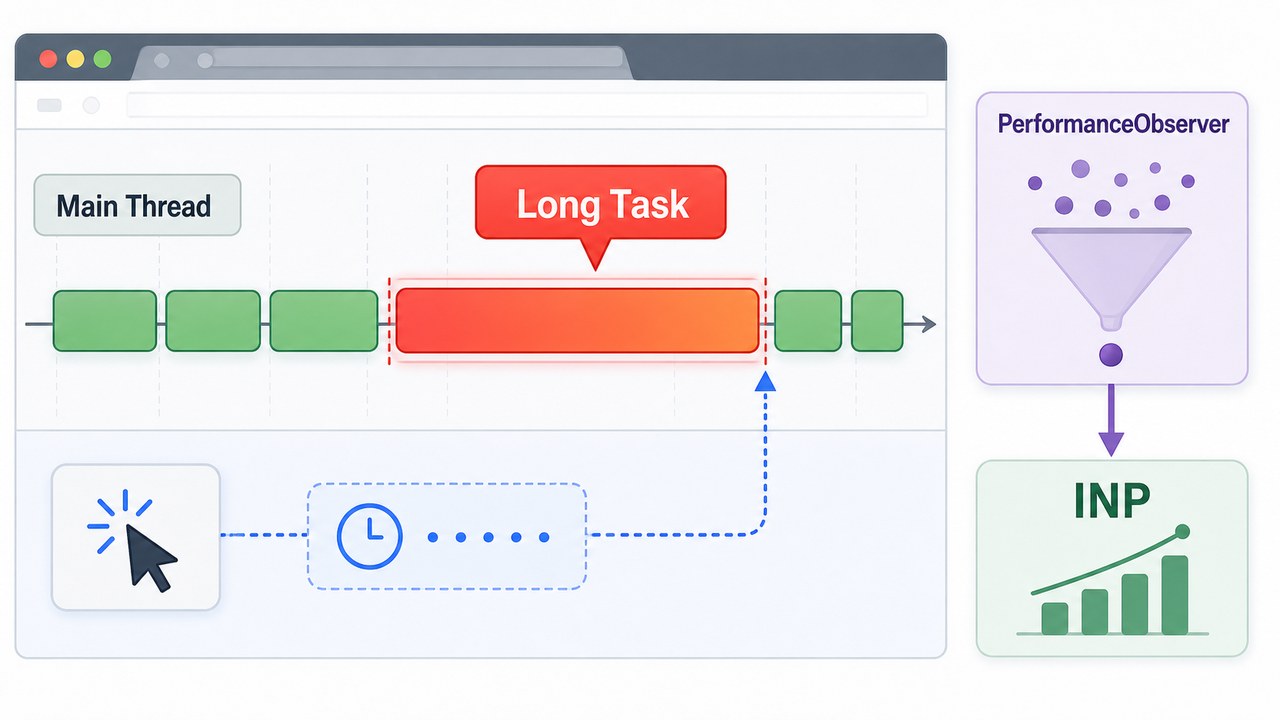
- 文章 · 前端 | 3天前 |
- 前端长任务治理实战:用 PerformanceObserver 找出页面卡顿源头
- 423浏览 收藏
-

- 文章 · 前端 | 2星期前 |
- CSS数字显示统一技巧,OpenType特性应用方法
- 209浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- MiMo Code
- MiMo Code 是小米大模型团队开源的新一代 AI 编程助手,面向开发者提供代码理解、生成与辅助开发能力,适合作为 AI 编程工具收藏和体验。
- 15次使用
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 35次使用
-

- MeloLab
- MeloLab 是一款 AI 音乐生成工具,可根据文本创意生成歌曲、人声、混音、分轨和背景音乐,适合创作者快速制作音乐素材。
- 33次使用
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8680次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9094次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- 优化用户界面体验的秘密武器:CSS开发项目经验大揭秘
- 2023-11-03 501浏览
-
- 使用微信小程序实现图片轮播特效
- 2023-11-21 501浏览
-
- 解析sessionStorage的存储能力与限制
- 2024-01-11 501浏览
-
- 探索冒泡活动对于团队合作的推动力
- 2024-01-13 501浏览


