Docker部署PHPAPI服务教程
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《Docker部署PHP API服务容器方案详解》,聊聊,我们一起来看看吧!
用Docker部署PHP API接口服务的核心在于容器化封装PHP环境、Web服务器和数据库,实现环境隔离与快速部署。1. 使用Dockerfile构建PHP应用镜像,定义PHP版本、扩展、代码目录及启动命令;2. 通过docker-compose.yml编排服务栈,包含PHP-FPM、Nginx和数据库服务,并配置网络、卷挂载和依赖关系;3. 编写Nginx配置文件实现请求转发;4. 执行docker-compose up -d启动服务。Docker部署提升了环境一致性、服务隔离性和部署效率,相比传统方式更适合现代开发流程。性能优化包括调整PHP-FPM参数、启用OPcache、优化Nginx配置、合理使用数据卷及资源限制。环境配置和敏感数据通过环境变量、配置文件挂载、Docker Secrets或云服务安全管理实现,避免硬编码和泄露风险。

用Docker部署PHP API接口服务,核心在于通过容器化技术,将PHP运行环境、Web服务器(如Nginx)和数据库(如果需要)等组件独立封装,实现环境隔离与快速部署。这让你的API服务在任何支持Docker的环境中都能以一致的方式运行,极大简化了开发、测试和生产环境的配置管理。

解决方案
要用Docker部署PHP API服务,通常我们会用到docker-compose来编排多个服务。一个典型的PHP API栈会包含PHP-FPM、Nginx(作为Web服务器反向代理到PHP-FPM),以及可能用到的数据库服务,比如MySQL或PostgreSQL。
首先,你需要一个Dockerfile来构建你的PHP应用镜像。这个文件定义了PHP运行环境以及你的API代码如何被放置到容器中。

Dockerfile 示例(放在你的API项目根目录):
FROM php:8.2-fpm-alpine # 安装必要的扩展,比如mysqli或pdo_mysql,根据你的API需求调整 RUN docker-php-ext-install pdo_mysql opcache # 设置工作目录 WORKDIR /var/www/html # 复制你的API代码到容器中 COPY . /var/www/html # 安装Composer依赖(如果你的项目使用Composer) # COPY --from=composer:latest /usr/bin/composer /usr/local/bin/composer # RUN composer install --no-dev --optimize-autoloader # 暴露PHP-FPM端口 EXPOSE 9000 CMD ["php-fpm"]
接着,创建一个docker-compose.yml文件,用于定义和运行你的服务栈。

docker-compose.yml 示例:
version: '3.8'
services:
# PHP-FPM服务
app:
build:
context: . # Dockerfile所在的目录
dockerfile: Dockerfile
restart: always
volumes:
- .:/var/www/html # 将当前目录挂载到容器的/var/www/html,方便开发时代码同步
- php-fpm-sock:/var/run/php-fpm # 用于Nginx与PHP-FPM通信的socket
environment:
# 这里可以定义一些环境变量,比如数据库连接信息等
APP_ENV: production
DATABASE_HOST: db
DATABASE_NAME: my_api_db
DATABASE_USER: user
DATABASE_PASSWORD: password
networks:
- app-network
# Nginx服务
nginx:
image: nginx:alpine
restart: always
ports:
- "80:80" # 将宿主机的80端口映射到容器的80端口
volumes:
- .:/var/www/html # 同样挂载代码目录
- ./nginx/nginx.conf:/etc/nginx/conf.d/default.conf # 挂载Nginx配置文件
- php-fpm-sock:/var/run/php-fpm # 用于Nginx与PHP-FPM通信的socket
depends_on:
- app # 确保app服务先启动
networks:
- app-network
# 数据库服务 (以MySQL为例)
db:
image: mysql:8.0
restart: always
environment:
MYSQL_ROOT_PASSWORD: root_password
MYSQL_DATABASE: my_api_db
MYSQL_USER: user
MYSQL_PASSWORD: password
volumes:
- db-data:/var/lib/mysql # 持久化数据库数据
networks:
- app-network
volumes:
db-data:
php-fpm-sock: # 命名卷,用于PHP-FPM和Nginx之间的socket通信
networks:
app-network:
driver: bridge最后,你需要一个Nginx的配置文件来正确地将请求转发给PHP-FPM。在项目根目录下创建nginx目录,并在其中创建nginx.conf:
nginx/nginx.conf 示例:
server {
listen 80;
index index.php index.html;
error_log /var/log/nginx/error.log;
access_log /var/log/nginx/access.log;
root /var/www/html/public; # 假设你的API入口在public目录下,比如Laravel或Symfony
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ \.php$ {
try_files $uri =404;
# 通过Unix socket连接PHP-FPM
fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
}完成这些文件后,在你的项目根目录执行:
docker-compose up -d
这会构建并启动所有服务,你的PHP API服务就运行起来了。
为什么选择Docker来部署PHP API?它真的比传统方式好吗?
老实说,我个人觉得Docker在现代PHP API部署中几乎是“必选项”了,尤其是在团队协作和CI/CD流程中。它确实比传统的直接在宿主机上安装LAMP/LEMP栈要好太多。
首先是环境一致性。想想看,开发人员A用PHP 7.4,开发人员B用PHP 8.1,测试环境是PHP 8.0,生产环境又是PHP 7.4加一堆特定扩展,光是这些环境差异就能把人折腾死。Docker通过容器封装了完整的运行环境,从PHP版本到所有依赖的扩展,甚至操作系统层面的库,都打包在一起。这意味着“在我的机器上能跑”这句话终于能延伸到“在任何Docker环境里都能跑”了。这对于保证开发、测试和生产环境的绝对一致性至关重要,能避免很多莫名其妙的bug。
然后是隔离性。每个服务都在自己的容器里运行,相互之间不会干扰。比如,你的API服务和数据库服务是完全独立的,即使API服务挂了,数据库服务也可能还在正常运行。这种隔离性也使得资源管理更加清晰,你可以为每个容器单独分配CPU和内存。
再来是部署的便捷性与速度。一旦你的Dockerfile和docker-compose.yml配置好了,部署一个新环境或者更新服务就变得异常简单,只需要几条docker命令。这比手动配置服务器、安装软件、管理依赖要快得多,也大大降低了人为错误的风险。对于需要频繁迭代和部署的API服务来说,这是个巨大的优势。
当然,它也有学习曲线,初学者可能会觉得有点复杂。但一旦掌握,你会发现它带来的效率提升和问题减少是无价的。
在Docker容器中运行PHP API,有哪些常见的性能优化策略?
在Docker里跑PHP API,性能优化跟传统方式有点像,但也有容器特有的考量。我通常会从几个方面入手:
PHP-FPM的配置优化:这是核心。
pm.max_children、pm.start_servers、pm.min_spare_servers、pm.max_spare_servers这些参数直接决定了PHP-FPM能同时处理多少请求。如果你的API并发量高,这些值就得调大。但也不能无限大,要根据容器分配的内存和CPU来决定。如果请求处理时间长,request_terminate_timeout也得适当设置,避免长时间运行的脚本耗尽资源。我一般会从小到大慢慢调,观察CPU和内存使用情况。OPcache的启用与配置:PHP-FPM容器里,务必确保OPcache是开启的。它能缓存编译后的PHP字节码,避免每次请求都重新解析PHP文件,对性能提升非常显著。通常在
php.ini里配置,比如opcache.enable=1、opcache.memory_consumption、opcache.interned_strings_buffer、opcache.max_accelerated_files等。Nginx的优化:
- FastCGI缓存:对于一些不经常变动或可以缓存的API响应,Nginx的FastCGI缓存能显著减少对PHP-FPM的请求压力。
- Gzip压缩:开启Gzip可以减少网络传输的数据量,提高API响应速度,尤其对于文本类型的JSON响应。
- 连接优化:
worker_processes、worker_connections这些参数也需要根据服务器资源来调整,确保Nginx能高效处理大量并发连接。
数据卷挂载的性能考量:
- 在开发环境,我们通常会用
bind mount(即.:/var/www/html这种方式)来方便代码同步。但在生产环境,如果文件I/O是瓶颈,考虑使用named volumes或者在构建镜像时直接COPY代码,减少运行时文件系统的开销。尤其是在一些云服务商提供的网络文件系统上,bind mount的性能可能会受到影响。 - 如果你的API会频繁读写大量小文件,这方面要特别留意。
- 在开发环境,我们通常会用
数据库连接优化:虽然这不是Docker独有的,但在容器化环境中也同样重要。比如使用连接池、优化SQL查询、建立合适的索引等。
Docker资源限制:在
docker-compose.yml里为服务设置cpu_shares、mem_limit等,可以防止某个服务耗尽所有资源,影响其他服务的稳定性。但也要注意不要设置得太低,导致服务性能受限。
这些策略没有一劳永逸的配置,都需要根据你的API负载、服务器资源和实际监控数据进行迭代调整。
Docker部署PHP API时,如何处理环境配置和敏感数据?
处理环境配置和敏感数据,在容器化部署中是个很重要的环节,不能马虎。我通常会采用以下几种方式,避免把敏感信息硬编码到代码或镜像里:
环境变量:这是最常用也最推荐的方式。对于像数据库连接字符串、API密钥、第三方服务凭证等,通过环境变量传递给容器。
- 在
docker-compose.yml的environment部分直接定义。 - 或者使用
.env文件,docker-compose会自动加载同目录下的.env文件,你可以在.env中定义变量,然后在docker-compose.yml中通过${VAR_NAME}引用。这种方式在开发环境中很方便,但.env文件不应该被提交到版本控制。 - 最佳实践:在生产环境,我更倾向于使用容器编排工具(如Kubernetes的Secrets、Docker Swarm的Secrets)或云服务提供商的秘密管理服务(如AWS Secrets Manager、Azure Key Vault)。这些工具能更安全地存储和注入敏感数据,避免它们以明文形式出现在配置文件或环境变量中。
- 在
Docker Secrets:这是Docker Swarm模式下提供的一种安全管理敏感数据的方式。它将敏感数据加密存储在Swarm集群中,并只在需要时以内存文件系统的方式挂载到容器中,容器重启后这些数据就会消失,降低了泄露风险。虽然在单机
docker-compose中不常用,但在生产级的Swarm部署中非常推荐。配置文件挂载:对于一些非敏感但又需要根据环境调整的配置文件(比如Nginx的
nginx.conf、PHP的php.ini),可以通过volume将宿主机上的配置文件挂载到容器内部的相应路径。这样做的好处是,你可以在不重新构建镜像的情况下修改配置,并实时生效(通过重启容器或重新加载服务)。运行时注入:在CI/CD流程中,构建镜像时避免将敏感数据打包进去。而是在容器启动时,通过脚本或ENTRYPOINT命令,从安全存储(如Vault)中拉取敏感数据并写入临时文件或设置为环境变量。
要特别注意的几点:
- 永远不要将敏感数据硬编码到
Dockerfile或应用程序代码中。 这会导致你的镜像或代码一旦泄露,敏感信息也随之暴露。 - 版本控制忽略敏感文件。 确保
.env文件、包含敏感信息的docker-compose.override.yml等被.gitignore忽略。 - 最小权限原则。 容器运行时,只赋予它完成任务所需的最小权限。
通过这些方法,我们可以比较安全地在Docker环境中管理PHP API服务的各种配置和敏感信息。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
 JupyterNotebook配置Go内核与数据环境
JupyterNotebook配置Go内核与数据环境
- 上一篇
- JupyterNotebook配置Go内核与数据环境

- 下一篇
- Golang依赖包安全更新技巧
-

- 文章 · php教程 | 4天前 | WEB开发 · 登录状态 · Cookie · PHP · session · session_start · php cookie session session_start PHPSESSID 登录态丢失
- PHP Session 登录态突然丢失怎么办:从 Cookie 到 session_start 一步步排查
- 196浏览 收藏
-
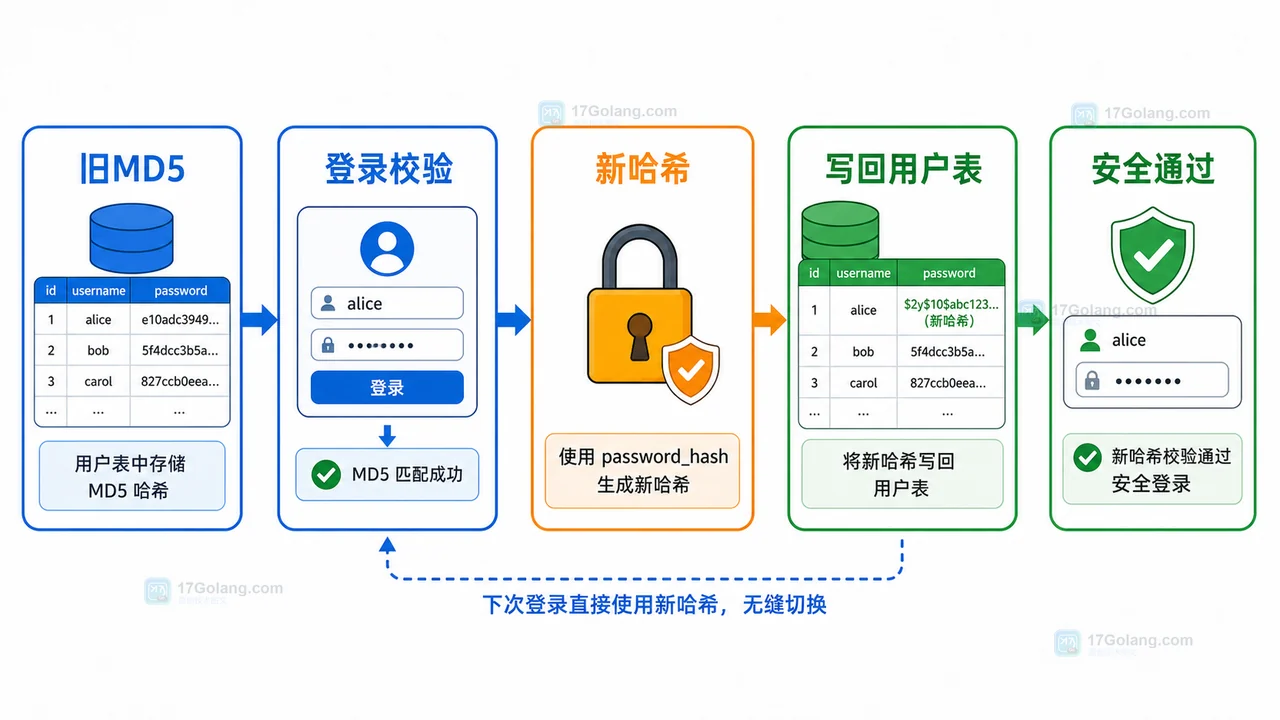
- 文章 · php教程 | 5天前 | PHP · MD5 · 登录安全 · password_hash · password_verify · password_hash password_verify 登录安全 PHP密码迁移 MD5迁移
- PHP 旧 MD5 密码如何平滑迁移到 password_hash:兼容登录与自动升级完整流程
- 174浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1315次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 1254次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1201次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1371次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1371次使用
-
- PHP技术的高薪回报与发展前景
- 2023-10-08 501浏览
-
- 基于 PHP 的商场优惠券系统开发中的常见问题解决方案
- 2023-10-05 501浏览
-
- 如何使用PHP开发简单的在线支付功能
- 2023-09-27 501浏览
-
- PHP消息队列开发指南:实现分布式缓存刷新器
- 2023-09-30 501浏览
-
- 如何在PHP微服务中实现分布式任务分配和调度
- 2023-10-04 501浏览


