BOM语音识别实现方法全解析
今天golang学习网给大家带来了《BOM实现语音识别方法详解》,其中涉及到的知识点包括等等,无论你是小白还是老手,都适合看一看哦~有好的建议也欢迎大家在评论留言,若是看完有所收获,也希望大家能多多点赞支持呀!一起加油学习~
要实现浏览器页面语音识别,主要依赖Web Speech API的SpeechRecognition接口。1.检查浏览器兼容性并创建SpeechRecognition对象;2.设置语言、连续识别等参数;3.绑定按钮事件控制开始与停止识别;4.监听onresult事件获取识别结果;5.通过onerror和onend处理错误与结束状态;6.提供用户提示与降级方案。兼容性方面,Chrome及Chromium系浏览器支持最好,Firefox部分支持,Safari支持有限,移动端Android Chrome与iOS Safari支持情况不一。提升准确性需实时反馈、权限引导、超时提示、合理使用连续识别并提供备选输入方式。此外,Web Speech API还支持语音合成(SpeechSynthesis),可结合使用构建完整语音交互体验。

要在浏览器页面实现语音识别,我们主要依赖的是浏览器内置的 Web Speech API,尤其是其中的 SpeechRecognition 接口。这个API允许网页直接访问用户的麦克风,将语音转换为文本,而不需要服务器端的介入,这在很多场景下都非常方便,比如语音搜索、语音指令输入或者无障碍辅助功能。

解决方案
实现页面的语音识别,核心是实例化 SpeechRecognition 对象,并监听其提供的各种事件。下面是一个基础的实现思路:
// 检查浏览器是否支持Web Speech API
// 注意:不同浏览器可能需要不同的前缀,或者根本不支持
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
if (!SpeechRecognition) {
console.warn('抱歉,您的浏览器不支持Web Speech API,无法进行语音识别。');
alert('您的浏览器不支持语音识别功能。建议使用Chrome浏览器。');
// 这里可以提供一个优雅降级方案,比如显示一个文本输入框
} else {
const recognition = new SpeechRecognition();
recognition.lang = 'zh-CN'; // 设置识别语言,例如中文普通话
recognition.continuous = false; // 设为true可以持续识别,直到手动停止
recognition.interimResults = false; // 是否返回临时结果,true可以实时显示识别中的文本
// 获取DOM元素,用于显示识别结果和控制按钮
const startBtn = document.getElementById('startVoiceBtn');
const stopBtn = document.getElementById('stopVoiceBtn');
const resultDisplay = document.getElementById('voiceResult');
if (startBtn) {
startBtn.onclick = () => {
resultDisplay.textContent = '请开始说话...';
startBtn.disabled = true;
stopBtn.disabled = false;
try {
recognition.start();
} catch (e) {
console.error('语音识别启动失败:', e);
resultDisplay.textContent = '启动失败,请检查麦克风权限或稍后再试。';
startBtn.disabled = false;
stopBtn.disabled = true;
}
};
}
if (stopBtn) {
stopBtn.onclick = () => {
recognition.stop();
startBtn.disabled = false;
stopBtn.disabled = true;
resultDisplay.textContent = '识别已停止。';
};
}
// 识别到结果时触发
recognition.onresult = (event) => {
let finalTranscript = '';
// 遍历所有识别结果
for (let i = event.resultIndex; i < event.results.length; ++i) {
const transcript = event.results[i][0].transcript;
if (event.results[i].isFinal) {
finalTranscript += transcript;
}
}
resultDisplay.textContent = finalTranscript;
console.log('识别到的文本:', finalTranscript);
};
// 识别结束时触发 (无论是成功还是失败)
recognition.onend = () => {
console.log('语音识别服务已断开。');
startBtn.disabled = false;
stopBtn.disabled = true;
// 如果不是手动停止,可能是识别超时或无声音
if (resultDisplay.textContent === '请开始说话...') {
resultDisplay.textContent = '没有检测到语音,请重试。';
}
};
// 识别错误时触发
recognition.onerror = (event) => {
console.error('语音识别错误:', event.error);
let errorMessage = '发生未知错误。';
switch (event.error) {
case 'no-speech':
errorMessage = '没有检测到语音。';
break;
case 'not-allowed':
errorMessage = '麦克风权限被拒绝。请检查浏览器设置。';
break;
case 'aborted':
errorMessage = '识别被用户或系统中断。';
break;
case 'network':
errorMessage = '网络错误导致识别失败。';
break;
case 'bad-grammar':
errorMessage = '语法错误。'; // 比较少见
break;
case 'language-not-supported':
errorMessage = '不支持当前语言。';
break;
default:
errorMessage = `识别错误:${event.error}`;
}
resultDisplay.textContent = `错误: ${errorMessage}`;
startBtn.disabled = false;
stopBtn.disabled = true;
};
}配套的HTML结构可能长这样:

识别结果:
这段代码基本上涵盖了语音识别的启动、结果处理和错误捕获。我觉得最关键的一点是,你得告诉用户,麦克风权限是必须的,否则一切都是白搭。
Web Speech API在不同浏览器中的兼容性表现如何?
说实话,Web Speech API的兼容性一直是个让人头疼的问题。你可能会发现,在Chrome浏览器里用得好好的功能,一换到Firefox或者Safari就完全失效了。这主要是因为这个API在W3C标准化的过程中进展比较慢,而且不同浏览器厂商的实现策略也不尽相同。

目前,Chrome和基于Chromium的浏览器(如Edge、Brave等)对Web Speech API的支持是最好的,也是最稳定的。它们通常不需要前缀,或者使用 webkitSpeechRecognition 作为备选。Firefox虽然也在努力支持,但其 SpeechRecognition 的实现可能不如Chrome那样成熟和功能全面,有时甚至需要用户手动开启一些实验性功能。Safari嘛,它对这个API的支持就比较有限了,很多时候根本就没法用。移动端方面,Android上的Chrome和iOS上的Safari(虽然有限)可能会支持。
在实际项目中,这会带来一些“坑点”:
- 浏览器兼容性检查: 你必须得做浏览器特性检测,不能想当然地认为所有浏览器都支持。像上面代码里那样用
window.SpeechRecognition || window.webkitSpeechRecognition是一个常见的处理方式,但它不能保证所有情况。如果不支持,你得给用户一个明确的提示,或者提供一个替代方案,比如传统的文本输入。 - 麦克风权限: 这是个大头。浏览器会弹出一个权限请求,如果用户拒绝,或者之前就拒绝了,你的语音识别就没法工作。而且,这个权限是针对域名的,用户可能不小心永久拒绝了。所以,在
onerror事件里处理not-allowed错误至关重要,你得引导用户去浏览器设置里重新开启。 - 网络依赖: 大多数浏览器内置的语音识别服务,其实是依赖于云端服务的。这意味着用户设备必须有网络连接,而且网络状况会直接影响识别的速度和准确性。如果网络不稳定,
network错误就可能跳出来。 - 识别准确率: 虽然现在的语音识别技术已经很厉害了,但它不是完美的。口音、语速、环境噪音都会影响识别结果。特别是当用户说一些专业术语或者生僻词时,误识别率会明显上升。我个人觉得,对于一些关键的指令,最好能有二次确认机制。
- 语言支持:
recognition.lang这个属性非常重要,但也不是所有语言都支持,或者说,不是所有语言的识别效果都一样好。你需要根据目标用户群体的语言来设置,并进行充分测试。
所以,在部署之前,一定要在目标用户可能使用的各种浏览器和设备上进行充分测试,并准备好优雅的降级方案和错误提示,这才能保证用户体验不至于太糟糕。
如何提升语音识别的准确性和用户体验?
提升语音识别的准确性和用户体验,这可不仅仅是代码层面的事情,更多的是一种产品设计和交互的考量。
- 明确的用户反馈: 当用户点击“开始识别”按钮后,页面应该立即给出反馈,比如按钮状态变为“正在聆听...”,或者显示一个麦克风图标并伴随动画,让用户知道系统正在等待输入。识别过程中,如果设置
interimResults = true,可以实时显示识别中的文本,虽然这些文本可能还会变动,但能大大降低用户的焦虑感。识别完成后,清晰地展示最终结果。 - 错误处理与引导: 前面提到了麦克风权限、网络问题等。当出现这些错误时,不要简单地抛出错误信息,而是要给出明确的解决方案。比如:“麦克风权限被禁用,请点击浏览器地址栏的麦克风图标启用。”或者“网络连接不稳定,请检查您的网络设置。”这种人性化的提示能让用户不至于一头雾水。
- 适当的超时机制: 如果用户长时间不说话,或者环境噪音过大导致无法识别,
onend事件会触发。这时,你可以给一个“未检测到语音”的提示,并建议用户重试。我发现,有时候用户只是不知道什么时候该说话,一个清晰的“请在听到提示音后开始说话”或者“请保持安静”的引导也很重要。 - 语言模型优化(有限): 虽然我们不能直接训练浏览器内置的语音识别模型,但可以通过提供上下文来间接“帮助”它。例如,如果你的应用是关于菜谱的,当用户说出“番茄炒蛋”时,即使发音不标准,系统也更倾向于识别成“番茄炒蛋”而不是“番茄吵蛋”。虽然
Web Speech API没有直接的“语法”或“提示词”输入,但理解用户意图和提供清晰的UI提示可以减少误解。 - 连续识别与停止:
recognition.continuous = true可以让识别持续进行,直到调用stop()。这对于需要长时间听写或多轮对话的场景很有用。但要注意,长时间的连续识别会消耗更多资源,并且可能会因为背景噪音积累而导致准确率下降。所以,在不需要时及时调用stop()是个好习惯。 - 辅助输入方式: 语音识别再好,也不是万能的。总有用户不喜欢用语音,或者在不方便说话的场合。所以,始终提供一个键盘输入或者其他传统输入方式作为备选,是提升用户体验的黄金法则。语音识别应该是一个“锦上添花”的功能,而不是唯一选项。
在我看来,用户体验的核心在于“可控性”和“透明度”。让用户知道系统在做什么,为什么会这样,以及他们可以如何操作,这比单纯追求百分百的识别准确率更重要。
除了基础的语音识别,Web Speech API还能做些什么?
除了将语音转换为文本(Speech Recognition),Web Speech API还有一个同样强大且互补的功能,那就是语音合成(Speech Synthesis),也就是我们常说的文本转语音(Text-to-Speech, TTS)。这俩兄弟加起来,就能让你的网页实现一个完整的语音交互体验。
语音合成允许你让浏览器“说话”,把一段文本读出来。这对于无障碍功能(例如为视障用户朗读网页内容)、语音助手、语言学习应用或者简单的语音提示都非常有用。
// 检查浏览器是否支持语音合成
const synth = window.speechSynthesis;
if (!synth) {
console.warn('抱歉,您的浏览器不支持Web Speech API的语音合成功能。');
} else {
// 获取可用的语音
let voices = [];
function populateVoiceList() {
voices = synth.getVoices().sort((a, b) => {
const aname = a.name.toUpperCase();
const bname = b.name.toUpperCase();
if (aname < bname) return -1;
if (aname == bname) return 0;
return +1;
});
// 可以在这里将语音列表展示给用户选择
// console.log('可用语音:', voices);
}
populateVoiceList();
if (synth.onvoiceschanged !== undefined) {
synth.onvoiceschanged = populateVoiceList;
}
const speakText = (text, lang = 'zh-CN') => {
if (synth.speaking) {
console.warn('正在说话中,请稍候...');
return;
}
if (text !== '') {
const utterance = new SpeechSynthesisUtterance(text);
utterance.lang = lang; // 设置语言
// 尝试选择一个合适的语音,例如中文普通话
const selectedVoice = voices.find(voice => voice.lang === lang && voice.name.includes('Google') || voice.name.includes('Microsoft'));
if (selectedVoice) {
utterance.voice = selectedVoice;
} else {
console.warn(`未找到适合 ${lang} 的高质量语音,将使用默认语音。`);
}
utterance.onerror = (event) => {
console.error('语音合成错误:', event);
};
synth.speak(utterance);
}
};
// 示例用法
// speakText('你好,欢迎使用语音助手。');
// speakText('How are you?', 'en-US');
}将语音识别和语音合成结合起来,你可以构建一个基本的语音助手或聊天机器人。用户说一句话,页面识别并处理后,再用语音回复。这种交互方式,比纯文本输入输出要自然得多,尤其是在一些需要解放双手的场景下,比如驾驶辅助、智能家居控制等。
当然,Web Speech API还有一些更细致的控制,比如:
SpeechRecognition.maxAlternatives: 可以获取多个识别结果的备选项,这在识别准确率不高时,可以提供给用户一个选择列表。SpeechSynthesisUtterance.pitch,rate,volume: 调整语音的音高、语速和音量,让合成的语音听起来更自然或符合特定情境。
虽然这些API在本地浏览器环境中运行,但其背后的语音模型通常是云服务提供的,所以性能和质量会受到网络和云服务提供商的影响。不过,对于很多轻量级的语音交互需求,BOM提供的这些能力已经足够强大和便捷了。在我看来,它极大地降低了实现语音交互的门槛,让更多开发者能够尝试和探索语音技术在Web应用中的潜力。
到这里,我们也就讲完了《BOM语音识别实现方法全解析》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于的知识点!
 MemoAI网页版使用教程
MemoAI网页版使用教程
- 上一篇
- MemoAI网页版使用教程

- 下一篇
- Deepseek满血版+AudacityAI,智能提升音频质量
-
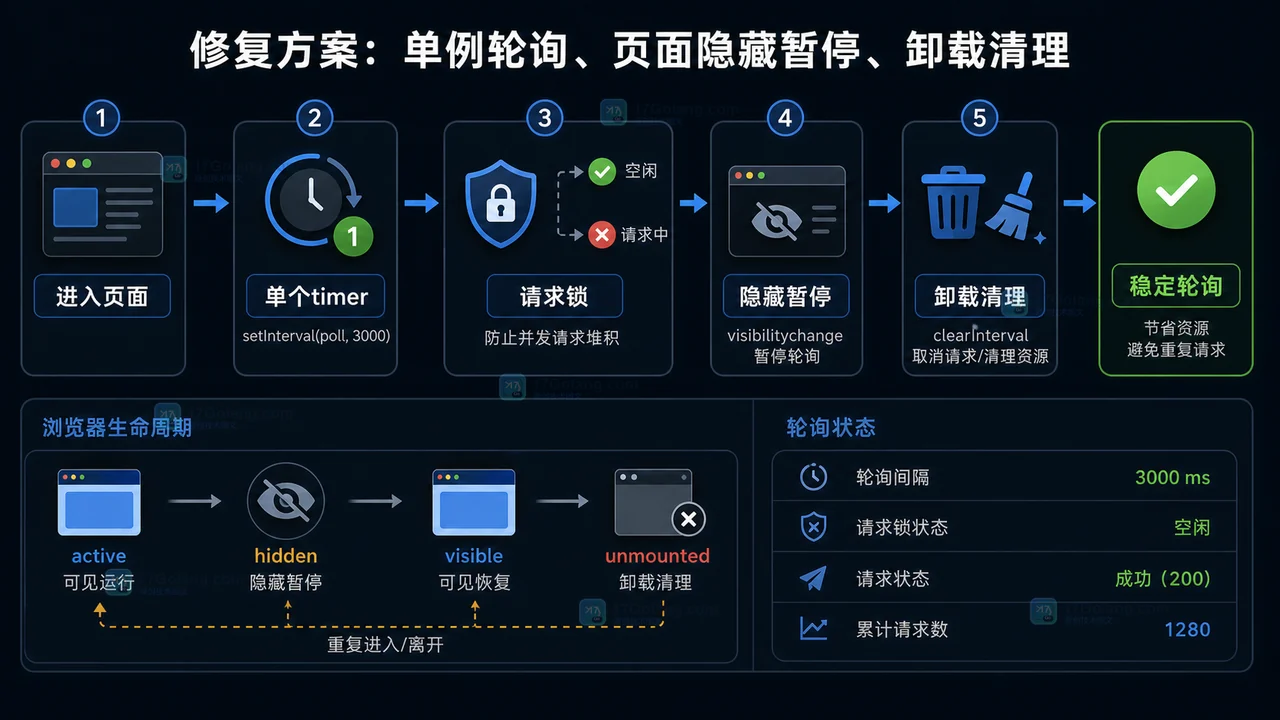
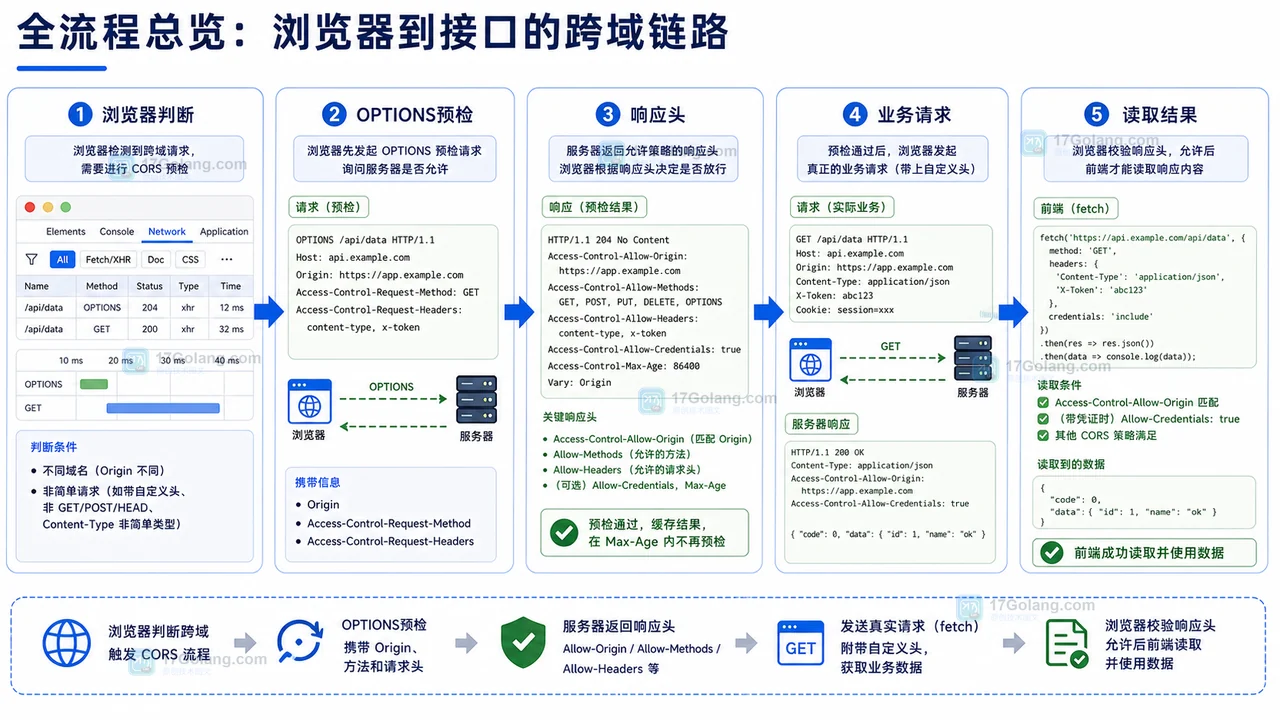
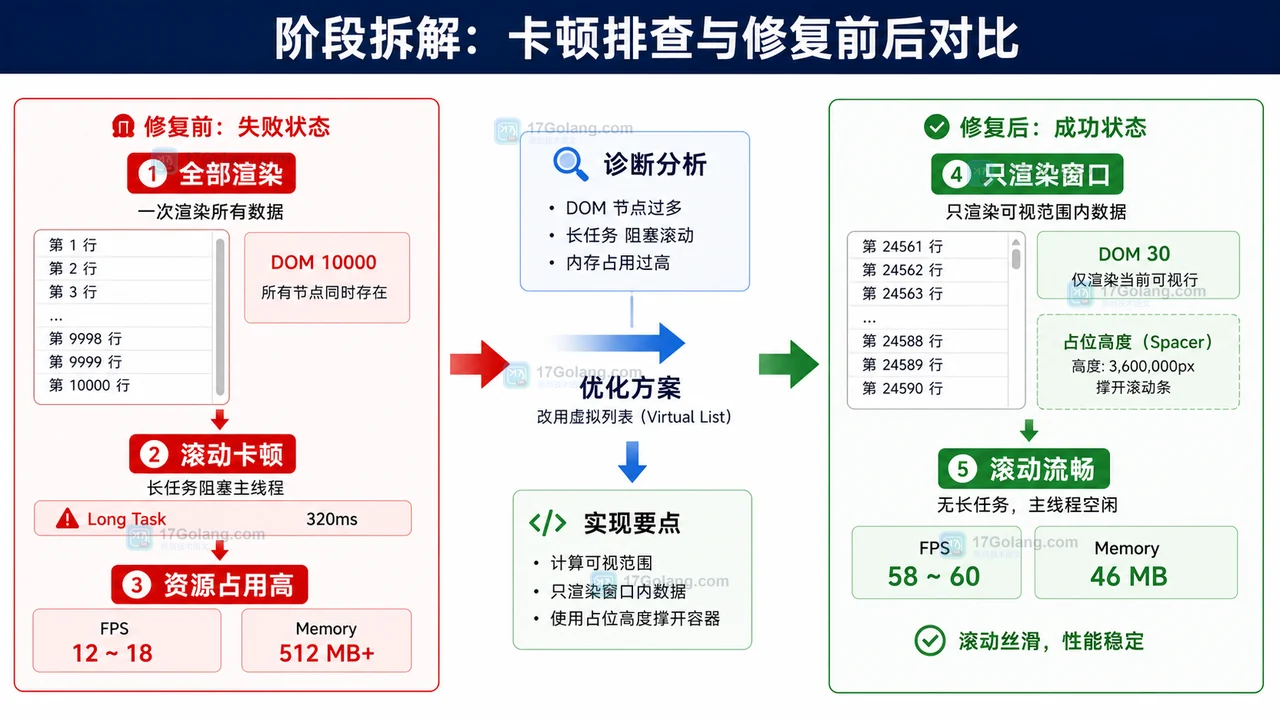
- 文章 · 前端 | 4天前 | 定时器 · 前端 · 性能排查 · 接口请求 · 轮询 · setInterval · setInterval 页面可见性 clearInterval 前端轮询 请求堆积 定时器清理
- 前端轮询接口越打越多怎么办:从重复定时器到清理机制一步步排查
- 490浏览 收藏
-
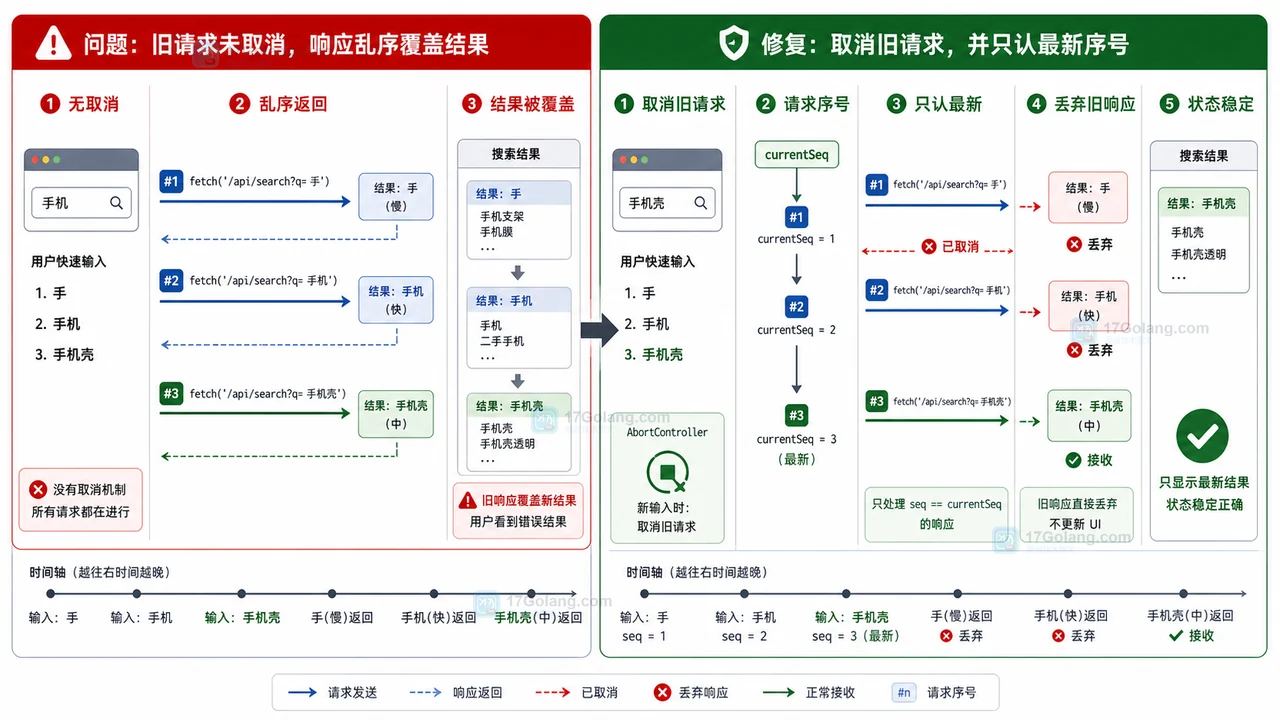
- 文章 · 前端 | 4天前 | 前端 · 搜索框 · AbortController · 接口请求 · 状态管理 · Fetch AbortController 前端搜索 请求乱序 旧响应覆盖
- 前端搜索结果倒退怎么办:AbortController 取消旧请求和序号兜底
- 295浏览 收藏
-
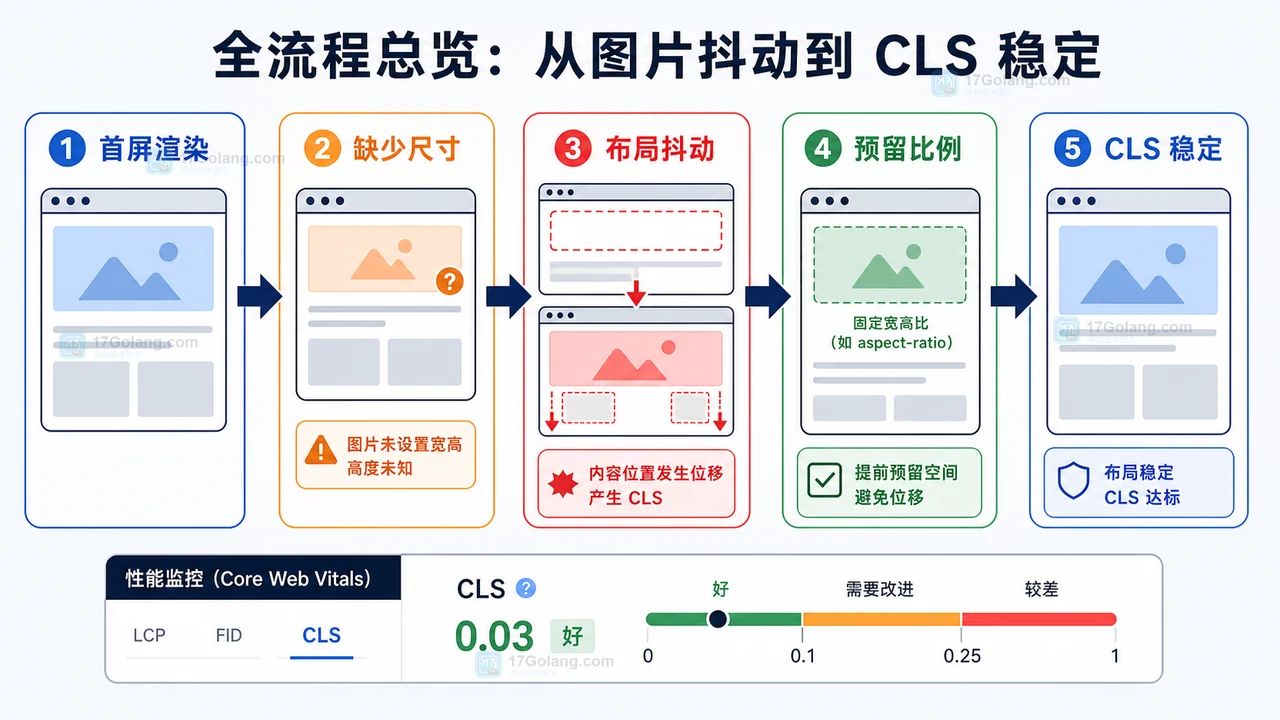
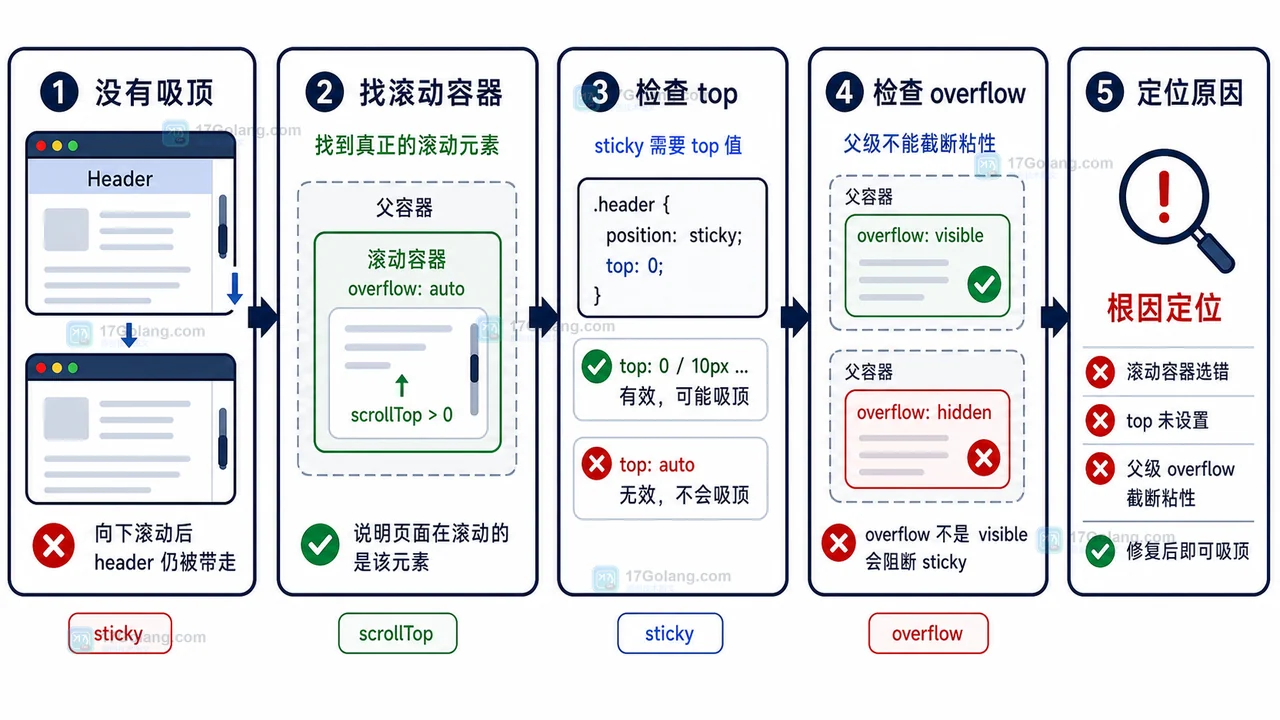
- 文章 · 前端 | 5天前 | 前端 · 性能优化 · cls · 懒加载 · Core Web Vitals · 前端 图片懒加载 IntersectionObserver CLS 布局稳定
- 前端图片懒加载布局抖动治理完整流程:占位比例、按需加载和 CLS 复查
- 128浏览 收藏
-

- 文章 · 前端 | 5天前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
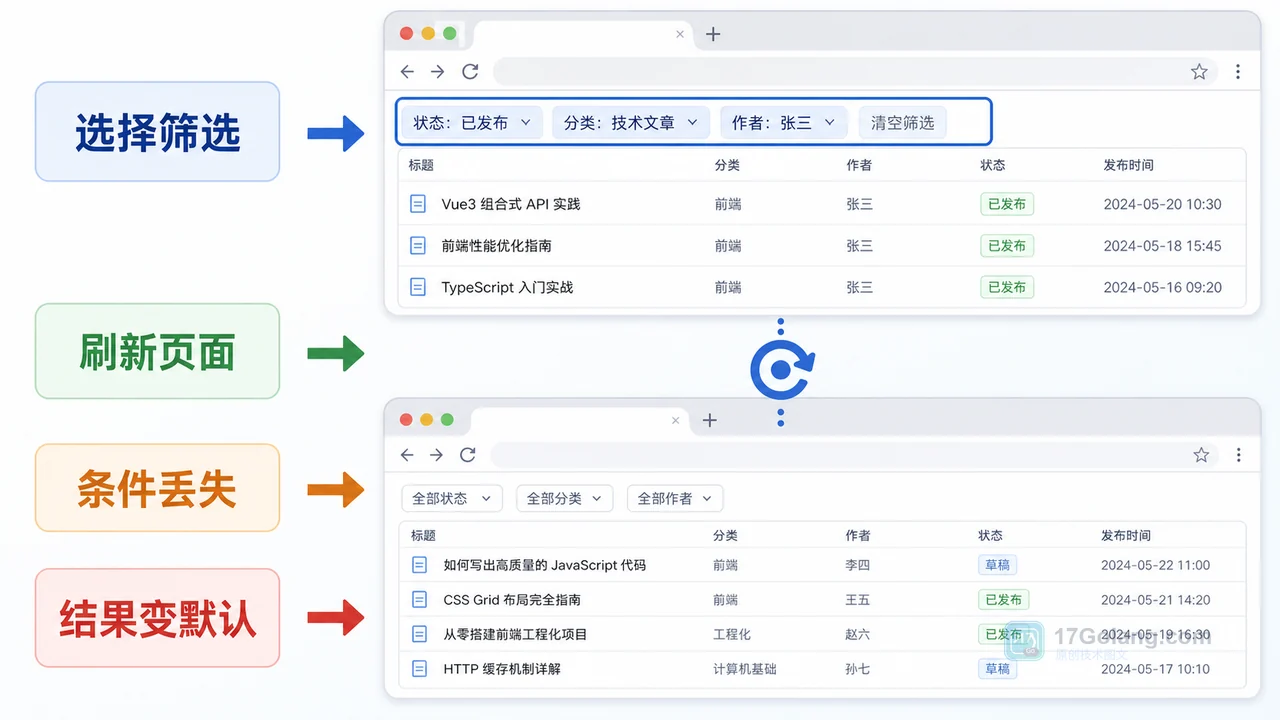
- 文章 · 前端 | 5天前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1307次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 1242次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1193次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1363次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1362次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- 优化用户界面体验的秘密武器:CSS开发项目经验大揭秘
- 2023-11-03 501浏览
-
- 使用微信小程序实现图片轮播特效
- 2023-11-21 501浏览
-
- 解析sessionStorage的存储能力与限制
- 2024-01-11 501浏览
-
- 探索冒泡活动对于团队合作的推动力
- 2024-01-13 501浏览


