JavaLambda与Stream使用详解
本篇文章向大家介绍《Java Lambda 与 Stream API 简明教程》,主要包括,具有一定的参考价值,需要的朋友可以参考一下。
Java Lambda 表达式和 Stream API 提升开发效率的核心在于简化代码、增强可读性和实现声明式编程。1. Lambda 表达式通过匿名函数形式减少冗余代码,特别是在使用函数式接口时显著提升代码简洁性;2. Stream API 提供了流式数据处理能力,支持过滤、映射、排序、归约等操作,并可通过链式调用清晰表达数据处理流程;3. 两者结合使得集合操作更直观高效,减少了手动编写循环和中间变量的需求;4. 常见操作模式包括过滤-映射-收集、分组-聚合和归约操作;5. 在性能方面需注意懒惰求值机制、并行流适用场景、原始类型 Stream 的使用以及保持无状态操作;6. 最佳实践包括合理使用链式调用、避免过度设计、采用 peek() 调试 Stream 管道,确保代码的可维护性和高效性。

Java Lambda 表达式和 Stream API 的出现,彻底改变了我们编写数据处理代码的方式。它们让代码更简洁、更具可读性,并且能够以一种声明式的方式表达复杂的逻辑,尤其在处理集合数据时,那种“写循环”的繁琐感一去不复返。说实话,刚接触时可能觉得有点抽象,但一旦上手,你会发现这简直是生产力工具的飞跃。

解决方案
Lambda 表达式本质上就是匿名函数,它提供了一种非常简洁的方式来表示一个方法。当你需要将一段行为作为参数传递时,比如给一个按钮添加点击事件,或者给一个列表排序,Lambda 就派上用场了。它最常见的应用场景是配合那些只有一个抽象方法的接口(我们称之为函数式接口)。

// 传统方式:匿名内部类实现 Runnable
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello from traditional thread!");
}
}).start();
// Lambda 方式:简洁地实现 Runnable
new Thread(() -> System.out.println("Hello from Lambda thread!")).start();
// 另一个例子:排序
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
List names = Arrays.asList("Alice", "Bob", "Charlie");
// 传统排序
Collections.sort(names, new Comparator() {
@Override
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});
System.out.println("Traditional sort: " + names);
// Lambda 排序
Collections.sort(names, (s1, s2) -> s1.compareTo(s2));
System.out.println("Lambda sort: " + names); Stream API 则是处理集合数据的利器。它提供了一套流式操作,允许你对集合进行过滤、映射、排序、归约等操作,而且这些操作可以像管道一样串联起来,形成一个清晰的数据处理流程。一个 Stream 通常包含三个阶段:
- 数据源(Source):可以是集合、数组、I/O 通道等。通过
collection.stream()或Arrays.stream()获取。 - 中间操作(Intermediate Operations):这些操作会返回一个新的 Stream,可以链式调用。它们是“懒惰的”,只有当终端操作被调用时才真正执行。常见的有
filter()(过滤)、map()(映射)、sorted()(排序)、distinct()(去重)、limit()(限制数量)、skip()(跳过)。 - 终端操作(Terminal Operations):这些操作会消耗 Stream,产生一个最终结果或副作用。Stream 在终端操作之后就不能再使用了。常见的有
forEach()(遍历)、collect()(收集到集合)、reduce()(归约)、count()(计数)、min()/max()/sum()/average()(统计)、anyMatch()/allMatch()/noneMatch()(匹配)。
Lambda 表达式和 Stream API 常常是配合使用的。Lambda 为 Stream 的中间操作和终端操作提供了简洁的函数体。

import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
class User {
String name;
int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() { return name; }
public int getAge() { return age; }
@Override
public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + '}'; }
}
// 实际应用:过滤、映射、收集
List users = Arrays.asList(
new User("Anna", 28),
new User("Ben", 35),
new User("Clara", 22),
new User("David", 30)
);
// 找出所有年龄小于30岁的用户名字,并按字母顺序排序
List youngUserNames = users.stream()
.filter(u -> u.getAge() < 30) // 过滤:年龄小于30
.map(User::getName) // 映射:提取名字 (这里用了方法引用,是Lambda的简写)
.sorted() // 排序:按名字字母顺序
.collect(Collectors.toList()); // 收集:将结果收集到List中
System.out.println("Young user names: " + youngUserNames); // 输出: [Anna, Clara]
// 计算所有用户的平均年龄
double averageAge = users.stream()
.mapToInt(User::getAge) // 转换为 IntStream,避免自动装箱拆箱,更高效
.average() // 计算平均值
.orElse(0.0); // 如果流为空,则返回0.0
System.out.println("Average age: " + averageAge); // 输出: 28.75 为什么 Lambda 表达式和 Stream API 能提升开发效率?它们解决了什么痛点?
讲真,在 Lambda 和 Stream API 出现之前,Java 在处理集合数据时,代码往往显得非常冗长和命令式。你需要手动编写循环(for、while),手动创建临时变量来存储中间结果,代码的意图被大量的样板代码所掩盖。这不仅增加了代码量,也让代码的可读性和维护性大打折扣。
Lambda 表达式的出现,首先解决了匿名内部类的“啰嗦”问题。想想看,一个简单的事件监听器,以前要写好几行代码,现在一行 Lambda 就能搞定。它让代码更聚焦于“做什么”,而不是“怎么做”,这是一种思维上的转变,从命令式编程向函数式编程迈进了一大步。
Stream API 则更像是为数据处理量身定制的“瑞士军刀”。它把数据处理的逻辑从具体的迭代细节中抽象出来,以一种声明式的方式来描述。你不再关心数据是如何一步步被遍历的,而是直接告诉 Stream 你想要什么:过滤掉哪些、转换成什么、最终收集成什么形式。这种链式调用让整个数据处理流程一目了然,极大地提升了代码的表达力。比如,以前你需要好几个循环才能完成的过滤、转换、排序操作,现在通过 Stream 的几个中间操作就能流畅地串联起来。这种高阶抽象,不仅减少了出错的可能性,也让代码更易于理解和重构。
Stream API 中常见的操作模式有哪些?如何选择合适的终端操作?
Stream API 的操作模式非常丰富,但归纳起来,最核心的几个是:
过滤-映射-收集(Filter-Map-Collect):这是最常见、最基础的模式。你先根据某个条件过滤掉不符合要求的数据,然后将剩余的数据转换成你想要的另一种形式,最后把结果收集到一个新的集合中。
// 过滤出偶数,然后乘以2,最后收集 List
numbers = Arrays.asList(1, 2, 3, 4, 5, 6); List processedNumbers = numbers.stream() .filter(n -> n % 2 == 0) // 过滤偶数 .map(n -> n * 2) // 每个偶数乘以2 .collect(Collectors.toList()); // 收集到List System.out.println("Processed numbers: " + processedNumbers); // 输出: [4, 8, 12] 分组-聚合(Grouping-Aggregating):当你需要根据某个属性对数据进行分类,并对每个分类进行统计或聚合操作时,
Collectors.groupingBy()是你的最佳选择。// 假设有用户列表,按年龄分组 List
users = Arrays.asList(new User("A", 20), new User("B", 25), new User("C", 20)); Map 归约(Reduction):当你想把 Stream 中的所有元素合并成一个单一的结果时,
reduce()操作就非常有用。它需要一个初始值(可选)、一个累加器函数和一个组合器函数(用于并行流)。// 计算所有数字的和 List
nums = Arrays.asList(1, 2, 3, 4, 5); int sum = nums.stream().reduce(0, (a, b) -> a + b); // 初始值0,累加器相加 System.out.println("Sum: " + sum); // 输出: 15
如何选择合适的终端操作?
选择终端操作取决于你最终想要什么:
collect(): 这是最常用、最灵活的终端操作,当你需要将 Stream 的结果收集到各种集合(toList(),toSet(),toMap(),toCollection(Supplier))、字符串(joining())、或者进行复杂的聚合(groupingBy(),partitioningBy(),counting(),summingInt()等)时,都用它。它就像一个多功能瑞士军刀,几乎能满足所有收集需求。forEach(): 当你只是想对 Stream 中的每个元素执行一个副作用操作(比如打印、更新数据库)而不需要返回任何结果时,用它。注意,它没有返回值,所以不能链式调用其他 Stream 操作。reduce(): 当你需要将所有元素“折叠”成一个单一的值时,比如求和、求积、连接字符串等。它比sum()、min()等更通用。count(): 简单地计算 Stream 中元素的数量。min()/max()/average()/sum(): 用于对数值型 Stream(如IntStream,LongStream,DoubleStream)进行统计计算。anyMatch()/allMatch()/noneMatch(): 用于检查 Stream 中的元素是否符合某个条件。它们会短路,一旦找到匹配或不匹配,就会立即返回。findFirst()/findAny(): 用于从 Stream 中查找一个元素。findFirst()保证返回第一个元素(在有序 Stream 中),findAny()则不保证顺序,在并行 Stream 中可能更快。它们都返回Optional类型,以处理流为空的情况。
如果你只是想简单地迭代并执行一些操作,forEach 可能最直接。但如果需要将结果转换成新的数据结构,collect 几乎是你的首选。需要聚合数据,reduce 是强大的通用工具,而特定统计则有更方便的 sum 等。
使用 Lambda 和 Stream API 时有哪些性能考量和最佳实践?
虽然 Lambda 和 Stream API 带来了极大的便利和可读性,但在实际使用中,我们仍然需要考虑一些性能和最佳实践问题,避免踩坑。
性能考量:
懒惰求值(Lazy Evaluation):Stream 的中间操作是“懒惰的”,它们并不会立即执行。只有当终端操作被调用时,整个 Stream 管道才会真正开始执行。这意味着如果你定义了一个很长的 Stream 链,但最终没有调用终端操作,那么中间的计算根本不会发生。这个特性非常重要,因为它允许 Stream 管道进行优化,例如短路操作(
limit(),anyMatch()等)可以在找到结果后立即停止处理,从而节省大量计算资源。// 这个filter和map操作不会执行,因为没有终端操作 Stream.of(1, 2, 3, 4, 5).filter(n -> { System.out.println("filtering: " + n); return n % 2 == 0; }).map(n -> { System.out.println("mapping: " + n); return n * 10; }); // 如果加上 .forEach(System.out::println); 就会看到输出并行流(Parallel Streams):Stream API 提供了
parallelStream()方法,可以方便地将串行流转换为并行流,从而利用多核 CPU 进行并行处理。听起来很美,但并非总是更快。并行流的性能提升取决于数据量、操作类型以及硬件。对于小数据集,并行化的开销(线程管理、数据分片合并)可能大于收益,反而变慢。此外,如果 Stream 操作中包含有状态或非线程安全的代码,并行流可能会导致意想不到的错误。一般来说,只有当数据量非常大,且操作是 CPU 密集型时,才考虑使用并行流,并且要确保操作是无状态的。原始类型 Stream(Primitive Streams):Java 为
int,long,double提供了专门的 Stream 版本:IntStream,LongStream,DoubleStream。使用它们可以避免自动装箱和拆箱的性能开销。当你处理大量原始数值数据时,优先使用这些特化 Stream。List
integers = Arrays.asList(1, 2, 3); // 避免装箱拆箱 int sum = integers.stream().mapToInt(Integer::intValue).sum();
最佳实践:
保持操作的无状态性(Stateless Operations):Stream 的中间操作应该是无状态的,即它们的执行不依赖于任何外部可变状态,也不应该修改外部状态。这对于并行流尤其重要,否则可能导致非预期结果。例如,在
filter或map中修改一个外部计数器是危险的。// 错误示例:有状态的Lambda List
numbers = Arrays.asList(1, 2, 3, 4); int[] sum = {0}; // 外部可变状态 numbers.stream().forEach(n -> sum[0] += n); // 修改外部状态 System.out.println(sum[0]); // 在并行流中可能不准确 正确做法是使用
reduce或collect来聚合。链式调用,清晰表达意图:Stream API 的优势在于其链式调用能力。将一系列操作清晰地串联起来,可以非常直观地表达数据处理的逻辑。但也要注意,不要过度链式调用导致一行代码过长,适当分行可以提高可读性。
适度使用,避免过度设计:并非所有的循环都必须转换为 Stream。对于非常简单的循环,例如仅仅遍历打印,传统的
for-each循环可能更直观、更易于理解。Stream 适用于复杂的、多步骤的数据转换和聚合。在追求“时髦”的同时,不要牺牲代码的直观性和可维护性。调试技巧:Stream 管道的调试可能比传统循环更复杂,因为它是惰性求值的。可以使用
peek()中间操作来在 Stream 管道的特定点插入一个副作用操作(比如打印),以观察数据流经该点时的状态。List
names = Arrays.asList("a", "b", "c"); names.stream() .filter(s -> { System.out.println("filtering: " + s); return true; }) .peek(s -> System.out.println("after filter: " + s)) // 观察过滤后的数据 .map(String::toUpperCase) .peek(s -> System.out.println("after map: " + s)) // 观察映射后的数据 .collect(Collectors.toList());
总之,Lambda 表达式和 Stream API 是现代 Java 开发中不可或缺的工具。掌握它们不仅能让你的代码更优雅,也能显著提升开发效率。在实践中多思考、多尝试,很快就能体会到它们带来的便利。
好了,本文到此结束,带大家了解了《JavaLambda与Stream使用详解》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多文章知识!
 CSSflex/grid排序技巧详解
CSSflex/grid排序技巧详解
- 上一篇
- CSSflex/grid排序技巧详解

- 下一篇
- Golang集成Prose实现NLP处理方法
-
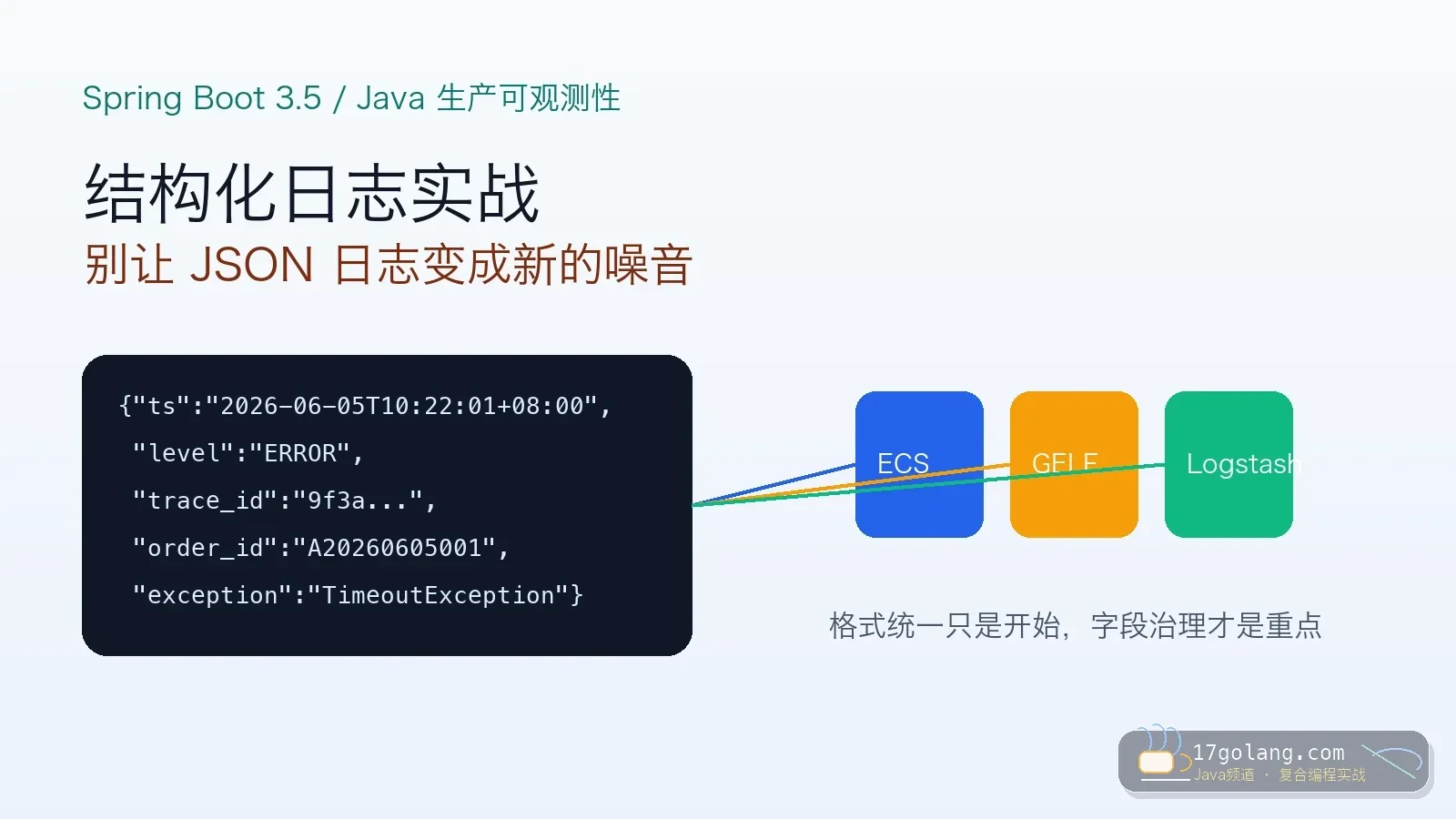
- 文章 · java教程 | 21小时前 | 日志 · Spring Boot · 生产实践 · 可观测性 · Java教程 · java 可观测性 MDC 结构化日志 Spring Boot 3.5
- Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
- 332浏览 收藏
-
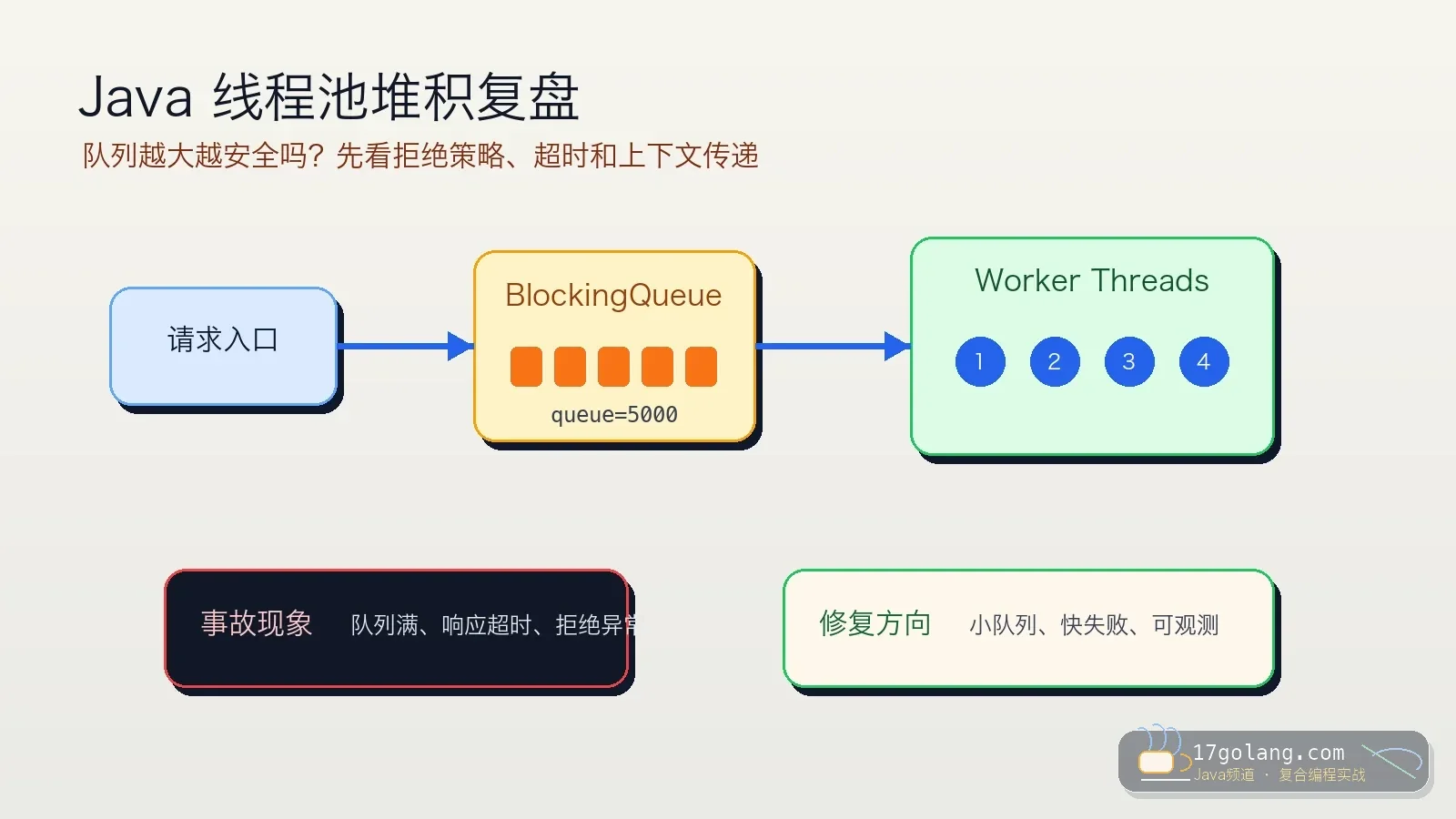
- 文章 · java教程 | 1天前 | 线程池 · Spring Boot · 生产实践 · Java教程 · ThreadPoolExecutor · java 性能优化 线程池 spring boot threadpoolexecutor
- Java 线程池队列堆积复盘:别让无界队列把慢故障藏起来
- 326浏览 收藏
-
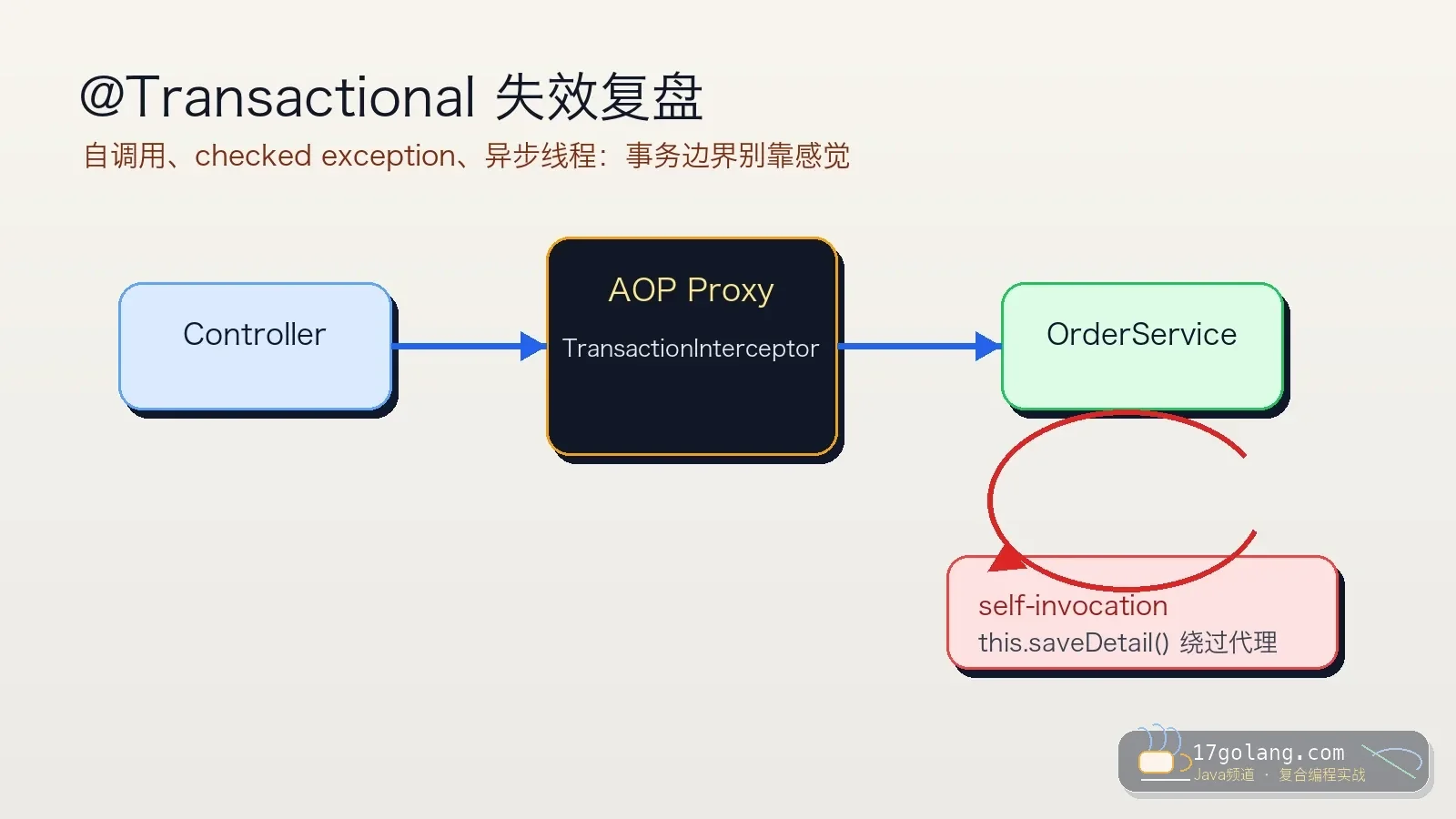
- 文章 · java教程 | 1天前 | Spring Boot · 事务管理 · 生产实践 · Java教程 · Transactional · java 事务管理 spring boot 生产实践 Transactional
- @Transactional 失效复盘:自调用、异常回滚和异步线程别再踩坑
- 259浏览 收藏
-
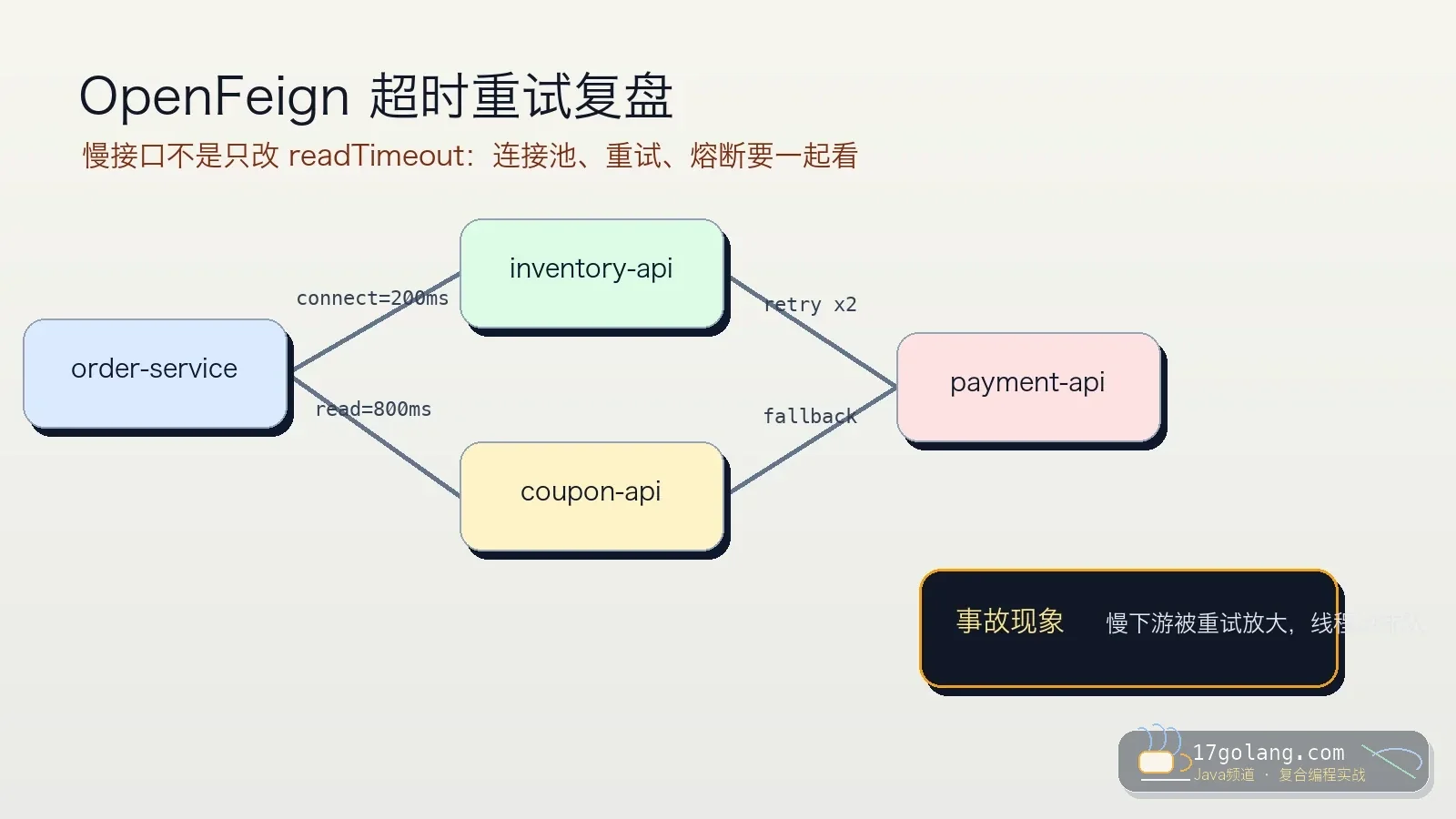
- 文章 · java教程 | 1天前 | 微服务 · 生产实践 · Java教程 · Spring Cloud · OpenFeign · java 微服务 Spring Cloud 超时重试 OpenFeign
- OpenFeign 超时重试踩坑:别把慢下游重试成全链路雪崩
- 363浏览 收藏
-
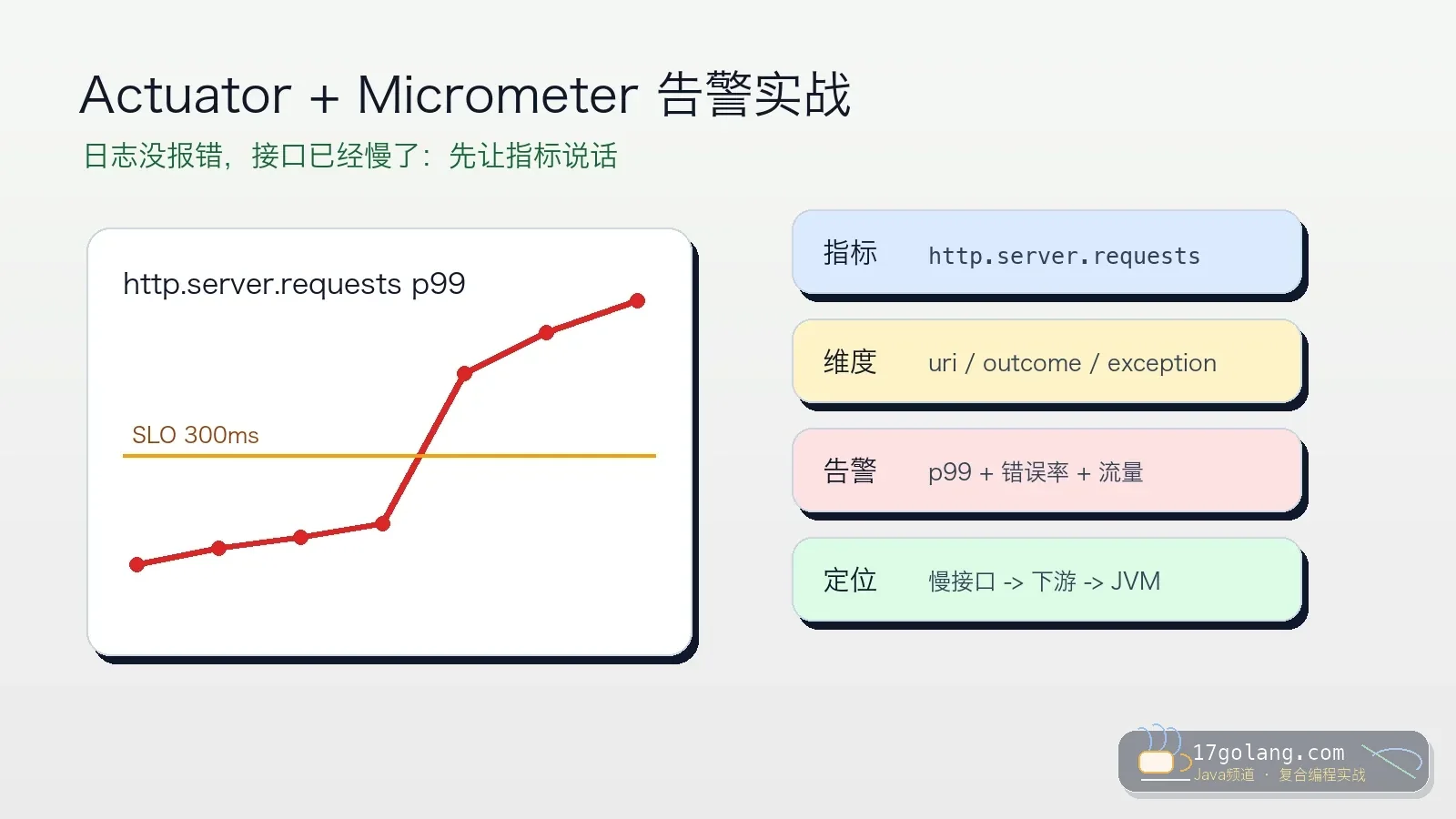
- 文章 · java教程 | 1天前 | Spring Boot · 生产实践 · Java教程 · Micrometer · Actuator · java spring boot Micrometer 可观测性 actuator
- Spring Boot 指标告警实战:Actuator + Micrometer 让慢接口先暴露
- 240浏览 收藏
-
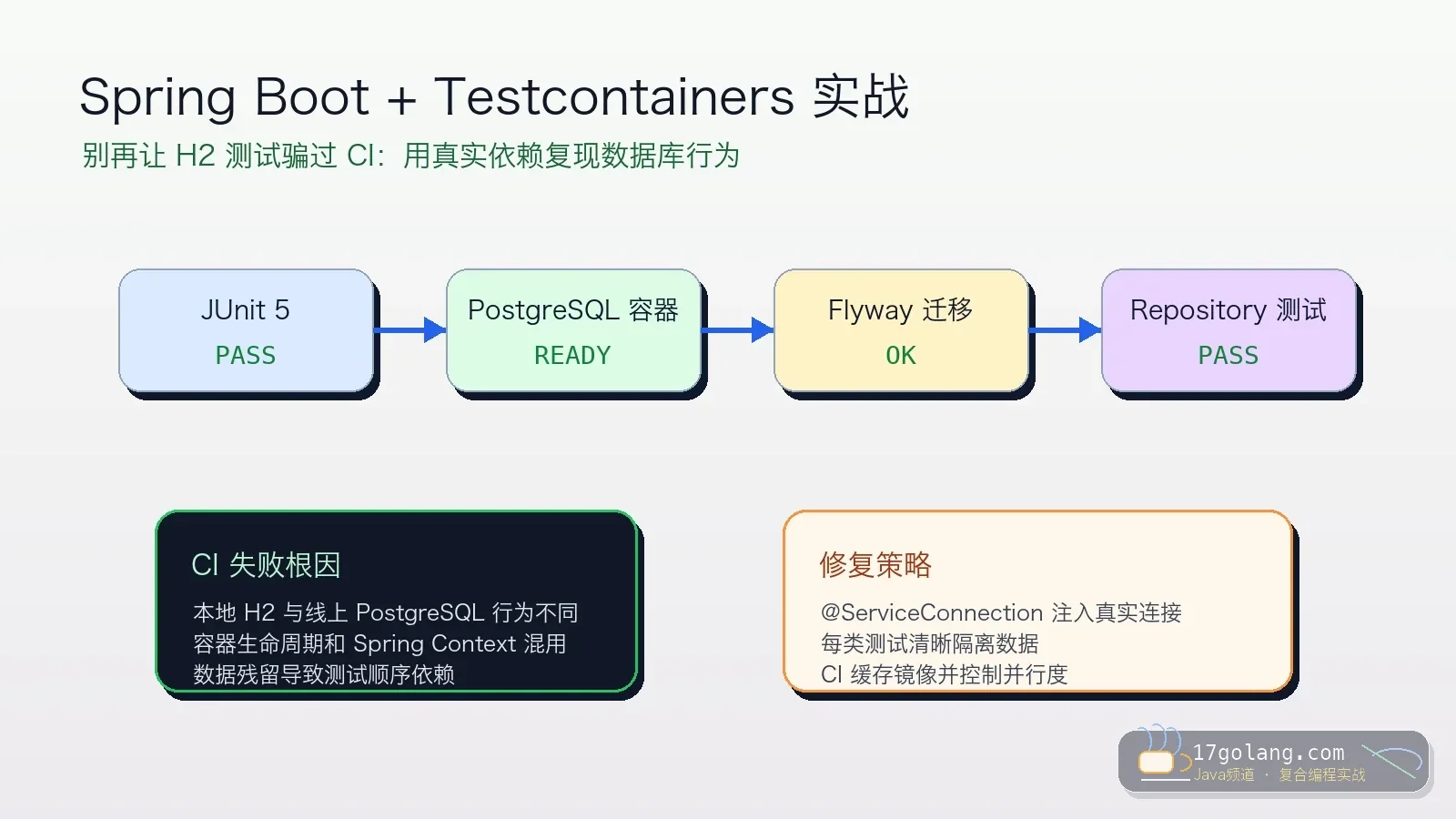
- 文章 · java教程 | 1天前 | 工程化 · Spring Boot · junit · Java教程 · Testcontainers · java 集成测试 spring boot JUnit 5 Testcontainers
- Spring Boot 集成测试别再只靠 H2:Testcontainers 落地踩坑复盘
- 154浏览 收藏
-
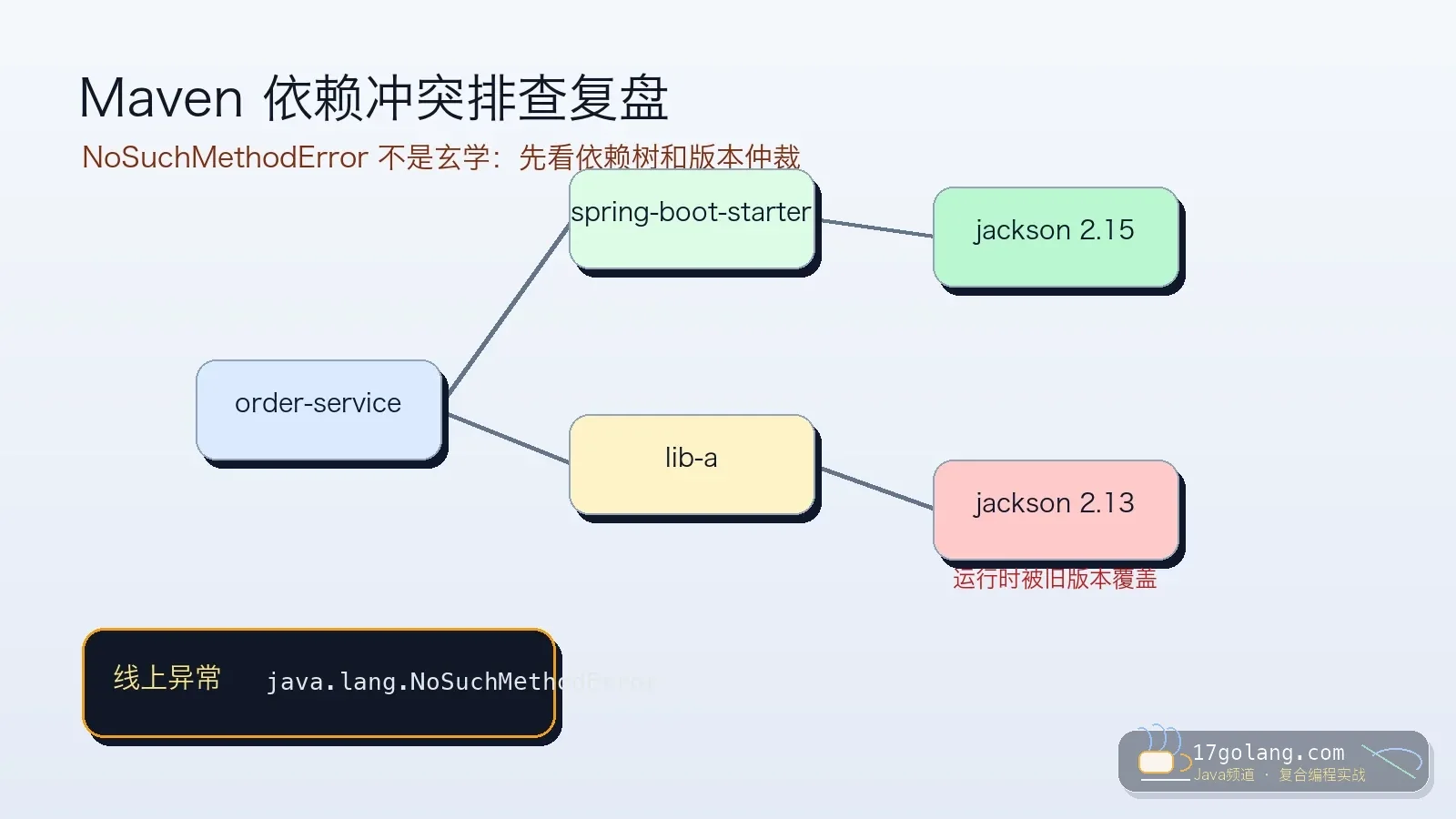
- 文章 · java教程 | 1天前 | 依赖管理 · Spring Boot · maven · 生产实践 · Java教程 · java maven spring boot 依赖冲突 工程化
- Maven 依赖冲突排查:NoSuchMethodError 不是玄学,先看依赖树
- 135浏览 收藏
-

- 文章 · java教程 | 1天前 | 数据库连接池 · Spring Boot · 生产实践 · Java教程 · HikariCP · java 性能优化 连接池 spring boot HikariCP
- HikariCP 连接池耗尽排查:别一上来就把 maximumPoolSize 调大
- 206浏览 收藏
-
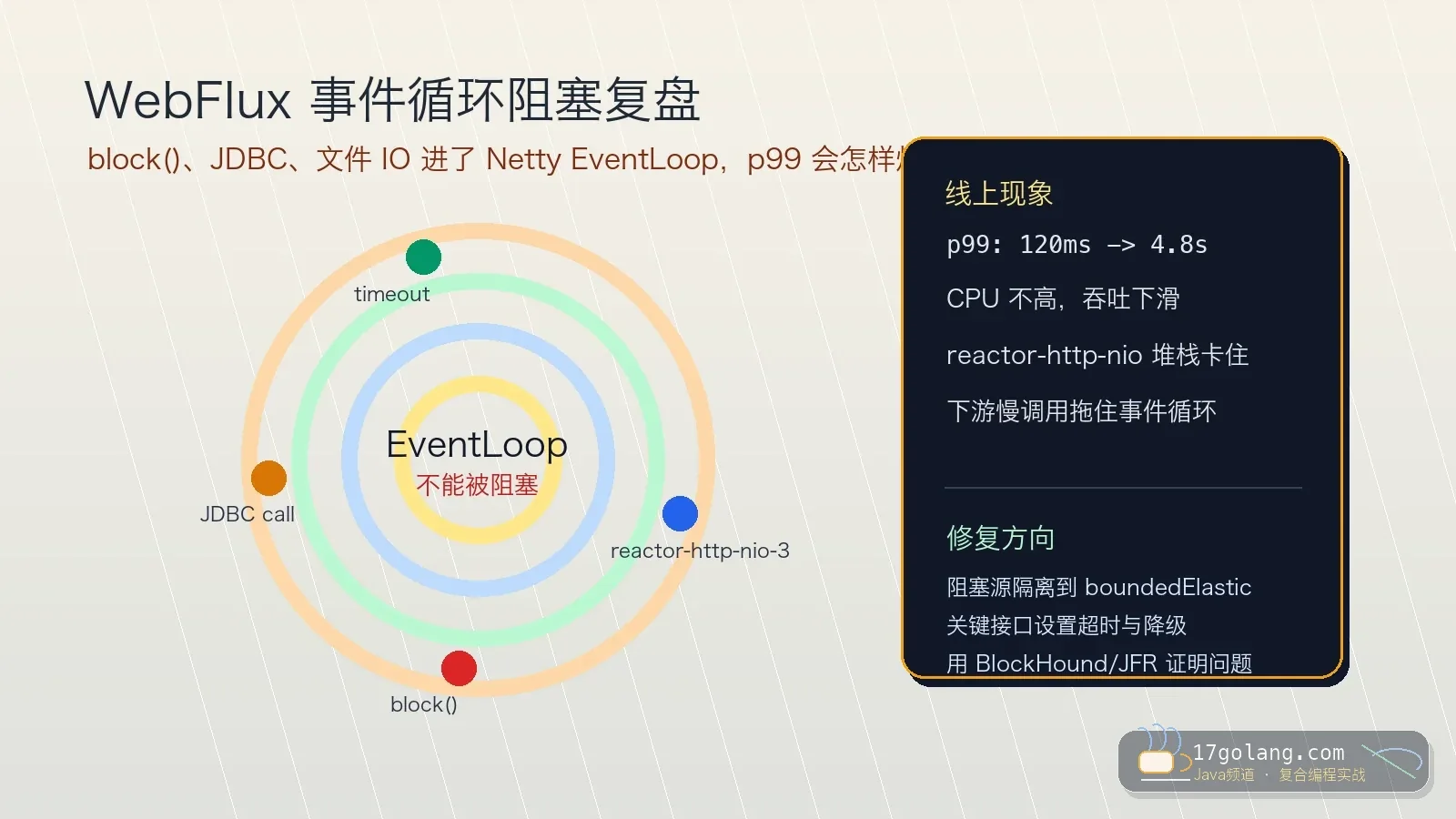
- 文章 · java教程 | 1天前 | reactor · netty · 生产实践 · Java教程 · Spring WebFlux · java 性能优化 netty reactor Spring WebFlux
- WebFlux 里 block() 卡死事件循环:一次 p99 飙升的排查复盘
- 388浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 6324次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6746次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6539次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8496次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 7170次使用
-
- 提升Java功能开发效率的有力工具:微服务架构
- 2023-10-06 501浏览
-
- 掌握Java海康SDK二次开发的必备技巧
- 2023-10-01 501浏览
-
- 如何使用java实现桶排序算法
- 2023-10-03 501浏览
-
- Java开发实战经验:如何优化开发逻辑
- 2023-10-31 501浏览
-
- 如何使用Java中的Math.max()方法比较两个数的大小?
- 2023-11-18 501浏览


