Redis缓存与Java集成教程详解
## Redis 缓存与 Java 集成实战教程:提升系统性能的关键策略 还在为 Java 应用响应速度慢、数据库压力大而烦恼?本教程深入解析 Redis 缓存与 Java 集成的核心技术,助你构建高性能应用。我们将重点介绍如何通过 Spring Data Redis 实现 Cache-Aside 模式,并详细对比 Jedis 和 Lettuce 两种主流 Redis 客户端的优劣,帮你选择最适合的方案。同时,针对缓存穿透、雪崩、击穿等常见问题,提供缓存空值、布隆过滤器、互斥锁、多级缓存等实用解决方案。掌握这些技巧,让你的 Java 应用如虎添翼,轻松应对高并发场景!
Redis 缓存与 Java 应用集成的核心目的是提升系统响应速度并减轻数据库压力。1. 最常用的方式是通过 Spring Data Redis 实现 Cache-Aside 模式,应用代码手动控制缓存读写;2. 常见的缓存策略包括 Cache-Aside(旁路缓存)、Read/Write-Through(读写穿透)、Write-Back(写回)和 Refresh-Ahead(刷新预加载),各自适用于不同业务场景;3. Java 中主流的 Redis 客户端为 Jedis 和 Lettuce,其中 Lettuce 因支持非阻塞 I/O 和响应式编程,更适合高并发新项目;4. 缓存常见问题如缓存穿透可通过缓存空值或布隆过滤器防范,缓存雪崩可通过设置随机过期时间或多级缓存应对,缓存击穿则可通过互斥锁或永不过期机制解决。

Redis 缓存与 Java 应用集成,说白了,就是为了让你的系统跑得更快,响应更及时。当用户请求一个数据时,我们希望它能瞬间出现,而不是让数据库吭哧吭哧地去查。Redis 作为一个高性能的内存数据库,正是扮演这个“加速器”的角色。它能大幅减轻后端数据库的压力,提升整体吞吐量,这在流量大的应用里几乎是标配了。

解决方案
在 Java 应用中集成 Redis 缓存,最直接也是最常用的方式就是通过 Spring Data Redis。我们以一个典型的用户数据查询场景为例,看看如何让 Redis 介入。
首先,你的 Spring Boot 项目需要引入 spring-boot-starter-data-redis 依赖。
org.springframework.boot spring-boot-starter-data-redis
接着,在 application.yml 或 application.properties 里配置 Redis 连接信息:
spring:
redis:
host: localhost # 或者你的 Redis 服务器地址
port: 6379
password: # 如果有密码
database: 0 # 默认数据库核心的集成思路是“Cache-Aside”模式,也就是我们常说的“旁路缓存”。应用程序代码自己决定何时从缓存读,何时写回缓存,以及何时更新数据库。

假设我们有一个 UserService,负责获取用户信息:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class UserService {
private final RedisTemplate redisTemplate;
private final UserRepository userRepository; // 假设你有一个用户数据的 JPA Repository
@Autowired
public UserService(RedisTemplate redisTemplate, UserRepository userRepository) {
this.redisTemplate = redisTemplate;
this.userRepository = userRepository;
}
/**
* 根据用户ID获取用户信息,优先从Redis缓存获取
*/
public User getUserById(Long userId) {
String cacheKey = "user:" + userId;
User user = (User) redisTemplate.opsForValue().get(cacheKey);
if (user != null) {
System.out.println("Cache hit for user ID: " + userId);
return user; // 缓存命中,直接返回
}
// 缓存未命中,查询数据库
System.out.println("Cache miss for user ID: " + userId + ", querying database...");
user = userRepository.findById(userId).orElse(null); // 假设通过JPA从数据库获取
if (user != null) {
// 将查询到的数据放入缓存,并设置过期时间
redisTemplate.opsForValue().set(cacheKey, user, 10, TimeUnit.MINUTES); // 缓存10分钟
System.out.println("User ID: " + userId + " fetched from DB and cached.");
} else {
// 如果数据库中也不存在,为了防止缓存穿透,也可以考虑缓存一个空值(短时间)
redisTemplate.opsForValue().set(cacheKey, "null", 1, TimeUnit.MINUTES);
System.out.println("User ID: " + userId + " not found, caching 'null' to prevent penetration.");
}
return user;
}
/**
* 更新用户信息后,同步更新缓存
*/
public User updateUser(User user) {
User updatedUser = userRepository.save(user); // 更新数据库
String cacheKey = "user:" + updatedUser.getId();
redisTemplate.opsForValue().set(cacheKey, updatedUser, 10, TimeUnit.MINUTES); // 更新缓存
System.out.println("User ID: " + updatedUser.getId() + " updated in DB and cache.");
return updatedUser;
}
/**
* 删除用户信息后,删除缓存
*/
public void deleteUser(Long userId) {
userRepository.deleteById(userId); // 删除数据库数据
String cacheKey = "user:" + userId;
redisTemplate.delete(cacheKey); // 删除缓存
System.out.println("User ID: " + userId + " deleted from DB and cache.");
}
}
// 假设的User实体类和UserRepository接口
// public class User implements Serializable { ... }
// public interface UserRepository extends JpaRepository { ... } 这个例子展示了最基础的“读写缓存”逻辑。实际项目中,你可能还会用到 Spring 的 @Cacheable, @CachePut, @CacheEvict 等注解,它们能大大简化这些缓存操作,让你更专注于业务逻辑,但底层原理其实是类似的。当然,注解用起来很爽,但有时候,当缓存策略变得复杂,或者需要更精细的控制时,直接操作 RedisTemplate 也是个非常灵活的选择。
Redis 在 Java 应用中常见的缓存策略有哪些?
谈到缓存策略,这可不是一刀切的事情,不同的业务场景,对缓存的要求也千差万别。
首先,最常见的,也是上面例子里用的,是旁路缓存(Cache-Aside)。这是最灵活的一种,你的应用代码自己负责维护缓存和数据库的一致性。读取时,先查缓存,没有再查数据库,然后把数据回填到缓存。写入时,先更新数据库,再更新(或删除)缓存。这种模式控制力强,但需要开发者手动处理缓存逻辑,代码会多一些。我个人觉得,对于那些缓存更新频率不高,或者需要精确控制缓存生命周期的场景,旁路缓存是个不错的选择。
然后是读写穿透(Read-Through / Write-Through)。这个通常由缓存框架(比如 Spring Cache)来帮你实现。当应用从缓存中读取数据时,如果缓存中没有,缓存框架会负责从数据源(比如数据库)加载数据并放入缓存,再返回给应用。写入时,数据会先写入缓存,然后缓存框架再负责将数据同步到数据源。这种模式对应用代码来说更透明,你只需要声明式地配置好缓存规则就行。用 Spring Cache 的 @Cacheable、@CachePut 注解就是典型的读写穿透。它简化了开发,但一旦出了问题,排查起来可能需要深入了解框架的实现细节。
还有一种是写回(Write-Back)。这种模式下,数据会先写入缓存,然后异步地写入到数据源。它能显著提升写入性能,因为应用不需要等待数据写入数据库。但风险也很明显:如果缓存服务在数据同步到数据库之前宕机了,那么这部分数据可能就丢失了。所以,除非你的应用对数据一致性要求不高,或者有非常完善的持久化机制来弥补,否则一般不推荐在核心业务中使用。比如日志系统、消息队列的缓冲层,可能会考虑这种模式。
最后,提一下刷新预加载(Refresh-Ahead)。这是一种更高级的优化策略,尤其适用于那些热点数据。它会在缓存项即将过期之前,就提前异步地去加载最新数据并更新缓存。这样,当用户请求时,数据始终是新鲜的,避免了缓存失效时瞬间的“击穿”问题。实现起来会复杂一些,通常需要定时任务或者消息队列配合。
选择哪种策略,很大程度上取决于你对数据一致性、性能和开发复杂度的权衡。
如何选择合适的 Java Redis 客户端?Jedis 还是 Lettuce?
在 Java 生态里,提到 Redis 客户端,绕不开的就是 Jedis 和 Lettuce。它们都是非常优秀的库,但设计理念和适用场景却有些不同。
Jedis Jedis 是一个比较老牌、成熟的客户端。它的设计哲学比较直观,基本上是同步阻塞 I/O 的。这意味着当你执行一个 Redis 命令时,线程会等待 Redis 服务器的响应。 它的优点是:
- 简单直观: API 映射 Redis 命令,上手快,理解成本低。
- 成熟稳定: 经过长时间的考验,社区支持也很好。
- 线程安全: 通过连接池(如 Apache Commons Pool)来管理连接,保证了多线程环境下的安全使用。
但缺点也很明显:
- 阻塞 I/O: 在高并发场景下,如果连接池配置不当或者 Redis 响应慢,可能会导致线程阻塞,影响吞吐量。每个请求都需要一个独立的连接,连接数可能会成为瓶颈。
Lettuce Lettuce 是一个相对较新的客户端,它基于 Netty 框架,实现了非阻塞 I/O (NIO)。这意味着它可以在一个连接上处理多个并发请求,而不需要为每个请求都分配一个独立的线程。 它的优点是:
- 非阻塞 I/O: 性能更高,在高并发场景下表现优异,能够更好地利用系统资源。
- 响应式编程友好: 天然支持 Reactive Streams,非常适合 Spring WebFlux 这类响应式编程框架。
- 连接复用: 能够高效地复用连接,减少连接创建和销毁的开销。
- 集群支持: 对 Redis Cluster、Sentinel 等高级特性支持更好。
缺点嘛,可能就是:
- 学习曲线: 对于习惯了同步编程的开发者来说,非阻塞和响应式编程的思维方式可能需要适应。
- 配置相对复杂: 相较于 Jedis,其配置和使用可能需要更多一点的理解。
我的看法: 在绝大多数新的 Spring Boot 项目中,尤其是 Spring Boot 2.x 以后,Spring Data Redis 默认集成的就是 Lettuce。如果你正在构建一个全新的、需要处理高并发、追求极致性能的应用,或者你的技术栈偏向响应式编程,那么 Lettuce 绝对是首选。它的非阻塞特性在高吞吐量场景下能带来显著优势。
而如果你的项目是老项目,或者对性能要求没那么极致,更看重开发效率和简单性,并且已经习惯了 Jedis 的 API,那么继续使用 Jedis 也未尝不可。但即便如此,我也建议在 Jedis 上配置好连接池,避免一些不必要的坑。
总的来说,新项目我无脑推荐 Lettuce。
Redis 缓存穿透、雪崩、击穿,这些坑你踩过吗?
在实际生产环境中,光是把 Redis 集成进去远远不够,你还得知道怎么避开那些常见的“坑”。缓存这东西,用好了是神器,用不好就是定时炸弹。最典型的三个问题就是缓存穿透、雪崩和击穿。
1. 缓存穿透 (Cache Penetration)
这玩意儿,说白了就是查询一个根本不存在的数据,而且这个数据永远也不会存在。比如,你的系统被恶意攻击,或者程序有个 bug,总是去查 user:999999999 这种不存在的用户 ID。每次请求都会穿透缓存,直接打到数据库上。如果这种请求量非常大,数据库可能就扛不住了。
怎么防?
- 缓存空值: 最简单有效的方法。如果数据库查询结果为空,也把这个空结果(比如一个特定的“null”字符串或空对象)缓存起来,并设置一个很短的过期时间。这样下次再查这个不存在的数据时,就能直接从缓存返回,避免打到数据库。当然,过期时间要短,不然缓存里一堆空值也挺占内存的。
- 布隆过滤器 (Bloom Filter): 对于那种海量请求查询不存在数据的场景,布隆过滤器是个更高级的方案。它是一个空间效率极高的概率型数据结构,可以判断一个元素是否“可能存在”或“一定不存在”。请求过来,先通过布隆过滤器判断,如果过滤器说“一定不存在”,那直接返回,连 Redis 都不用查。但它有个小缺点,就是存在误判率,可能会把极少数不存在的判断为存在,然后还是会穿透到 Redis 或数据库。不过这个误判率通常可以接受。
2. 缓存雪崩 (Cache Avalanche) 想象一下,你的缓存服务器突然挂了,或者大量的缓存 key 在同一时间集中失效了。这时,所有的请求都会直接涌向数据库,就像雪崩一样,数据库瞬间被压垮。这在很多大型促销活动,或者系统上线初期,缓存策略不当的时候特别容易发生。
怎么防?
- 给缓存过期时间加随机值: 这是最直接有效的办法。不要让所有 key 都设置成固定的过期时间,比如 1 小时。可以在 1 小时的基础上,加上一个随机的几分钟,比如
expire = 60 * 60 + random(0, 300)秒。这样,即使大量 key 同时创建,它们也不会在同一时间点失效。 - 多级缓存: 部署多层缓存,比如本地缓存 + Redis 缓存。当 Redis 挂掉时,至少本地缓存还能顶一阵。
- 熔断和限流: 在应用层面做一些保护措施。当数据库负载过高时,可以暂时停止部分请求,或者直接返回默认值/错误信息,避免数据库彻底崩溃。
- 高可用 Redis 集群: 部署 Redis Sentinel 或 Redis Cluster,保证 Redis 服务本身的高可用性,减少宕机风险。
3. 缓存击穿 (Cache Breakdown) 和雪崩不同,击穿针对的是一个“热点 key”。当某个非常热门的 key,在它失效的瞬间,大量的并发请求同时涌入,这些请求都会穿透缓存,直接打到数据库上,导致数据库压力骤增。虽然只有一个 key,但因为它是热点,瞬间的并发量可能非常高。
怎么防?
互斥锁 (Mutex Lock): 当一个热点 key 失效时,第一个请求去查询数据库并重建缓存。这时,可以用分布式锁(比如基于 Redis 的 Redisson 锁)来保证只有一个线程去查询数据库,其他线程则等待这个线程查询并回填缓存后,再从缓存中获取数据。
// 伪代码 String lockKey = "lock:" + cacheKey; if (redisLock.tryLock(lockKey, 10, TimeUnit.SECONDS)) { // 尝试获取锁 try { // 再次检查缓存,可能在等待锁的过程中其他线程已经重建了 Object data = redisTemplate.opsForValue().get(cacheKey); if (data != null) return data; // 缓存确实没有,查询数据库并重建 data = queryFromDB(); redisTemplate.opsForValue().set(cacheKey, data, ...); return data; } finally { redisLock.unlock(lockKey); // 释放锁 } } else { // 获取锁失败,说明有其他线程正在重建,等待一小会儿重试,或者从数据库读取(降级) Thread.sleep(50); // 简单等待 return (Object) redisTemplate.opsForValue().get(cacheKey); // 再次尝试从缓存获取 }永不过期: 对于一些绝对的热点数据,可以考虑将其设置为永不过期(或设置一个非常长的过期时间),然后通过异步的方式(比如定时任务或消息队列)去更新缓存中的数据。这样,即使数据有更新,也不会出现缓存失效导致击穿的情况。
这些问题,说实话,都是我在实际项目中真真切切踩过的坑。理解它们,并在设计之初就考虑好相应的防御策略,能让你在后续的运维中省去不少麻烦。缓存虽好,但用起来也得小心翼翼。
本篇关于《Redis缓存与Java集成教程详解》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于文章的相关知识,请关注golang学习网公众号!
 BOM检测剪贴板权限技巧分享
BOM检测剪贴板权限技巧分享
- 上一篇
- BOM检测剪贴板权限技巧分享

- 下一篇
- 即梦AI高清封面制作教程详解
-
- 文章 · java教程 | 1星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-
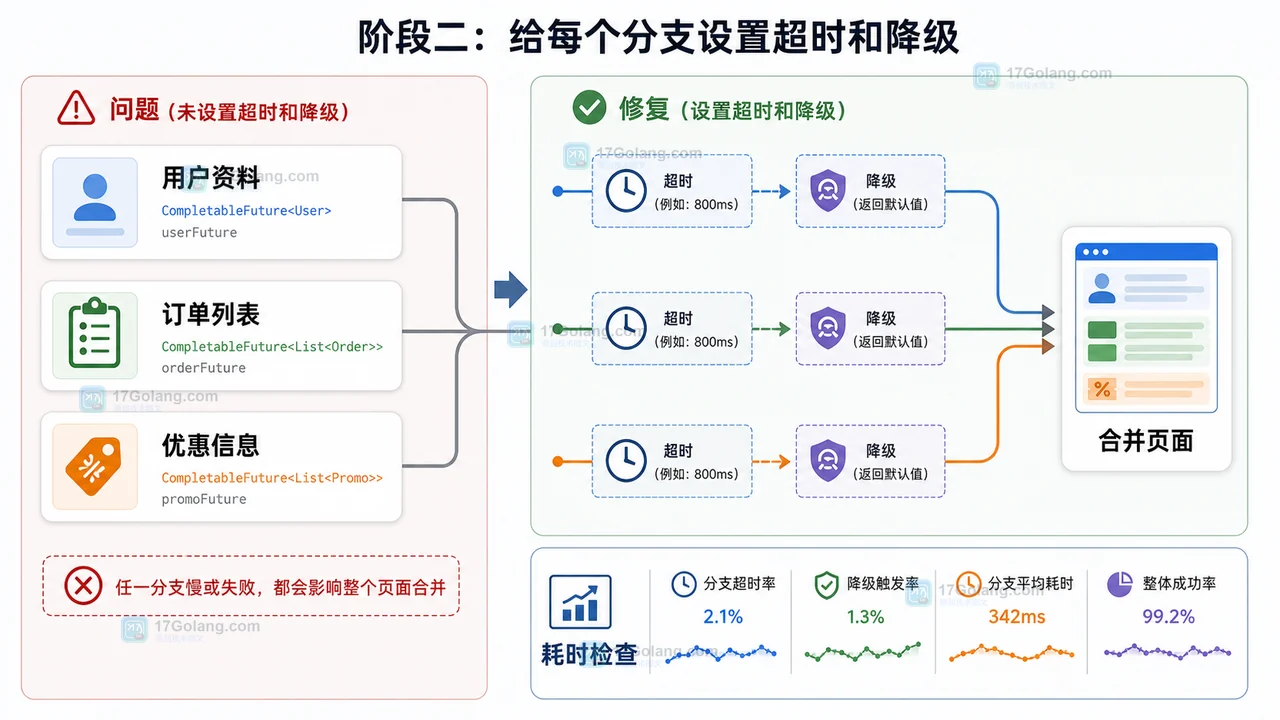
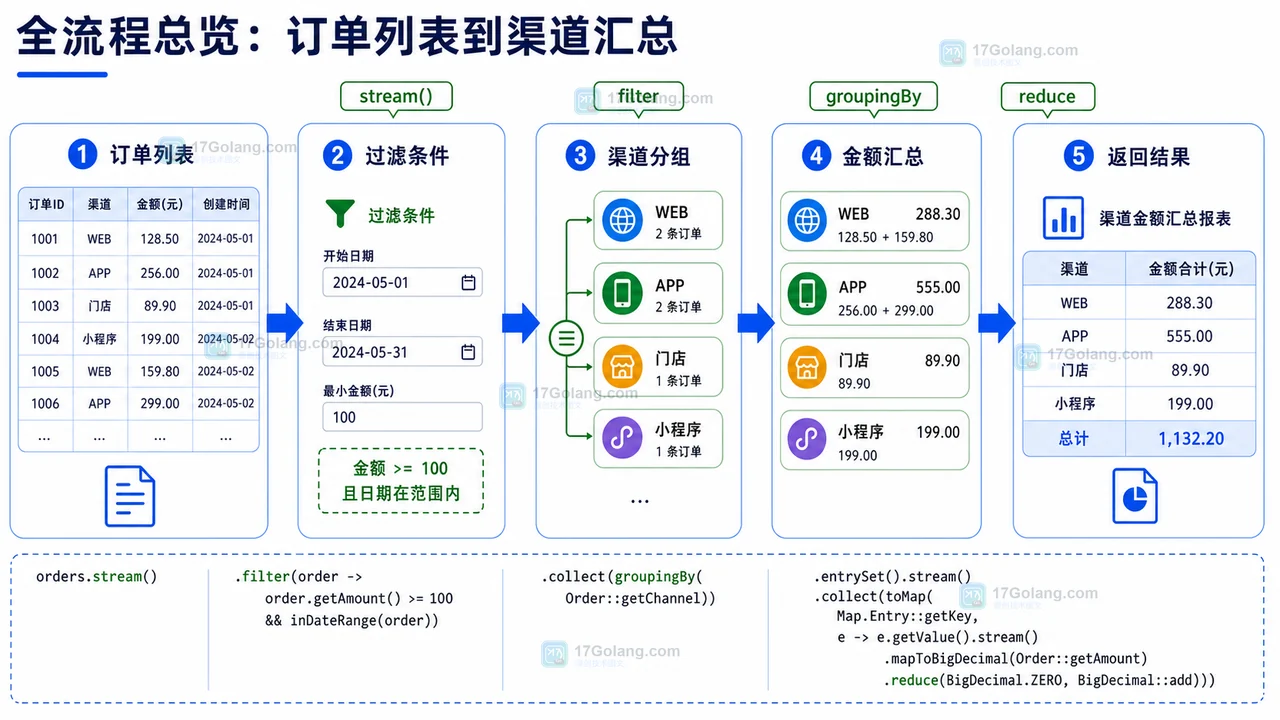
- 文章 · java教程 | 1星期前 | Java · 异步编程 · 后端开发 · CompletableFuture · 接口聚合 · java 结果合并 completablefuture 并行调用 超时兜底
- Java CompletableFuture 多接口聚合完整流程:并行调用、超时兜底和结果合并
- 428浏览 收藏
-
- 文章 · java教程 | 1星期前 | Java · 线程安全 · DateTimeFormatter · 日期处理 · 并发问题 · java 线程安全 日期格式化 threadlocal SimpleDateFormat DateTimeFormatter
- Java SimpleDateFormat 日期偶发错乱怎么办:从共享实例到线程安全一步步排查
- 481浏览 收藏
-
- 文章 · java教程 | 1星期前 | http接口 · httpclient · Java教程 · 接口调试 · 超时处理 · java 接口调用 httpclient 超时控制 状态码 响应体
- Java HttpClient 调接口实战:超时、状态码和响应体这样处理
- 224浏览 收藏
-
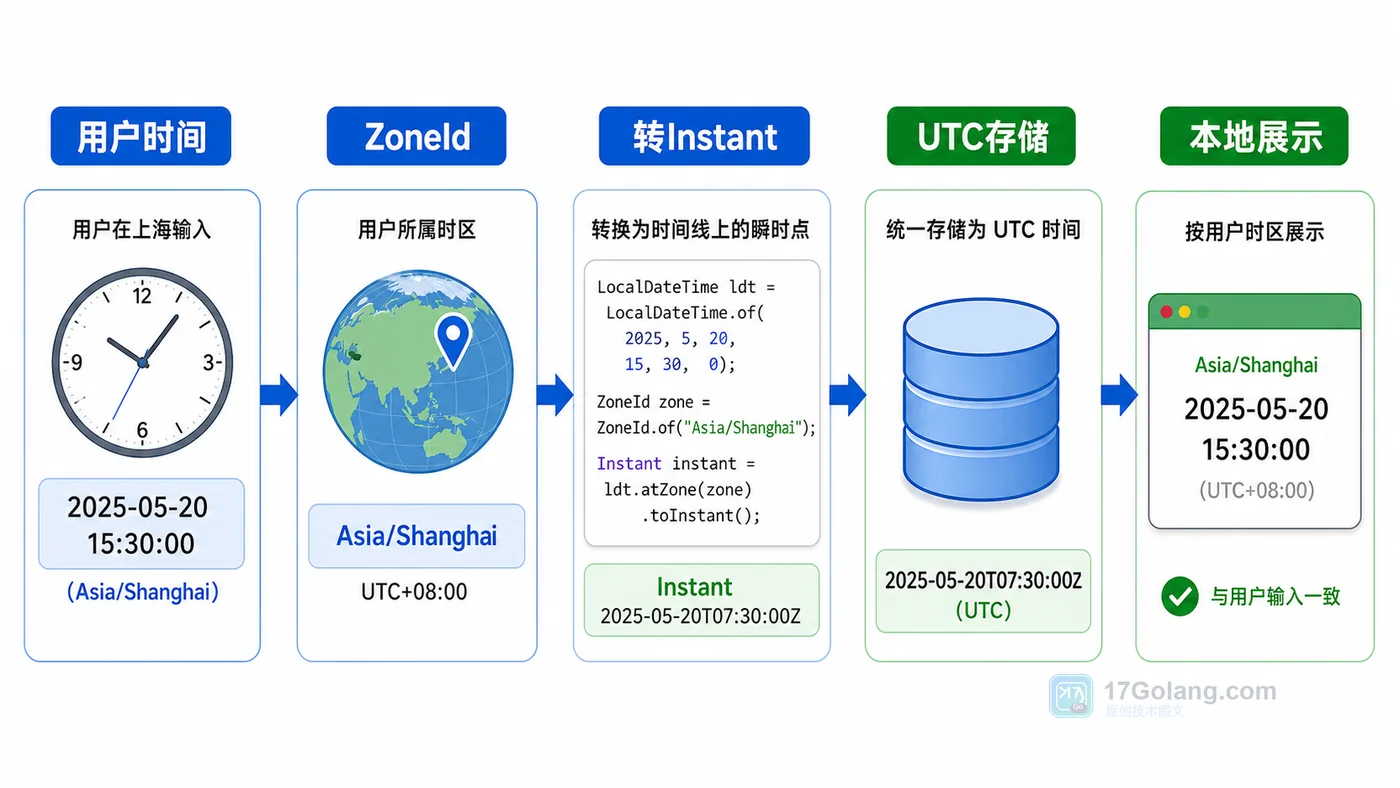
- 文章 · java教程 | 1星期前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT
- Java 时间与时区处理实战:Instant、ZoneId 和 DateTimeFormatter 怎么配
- 461浏览 收藏
-
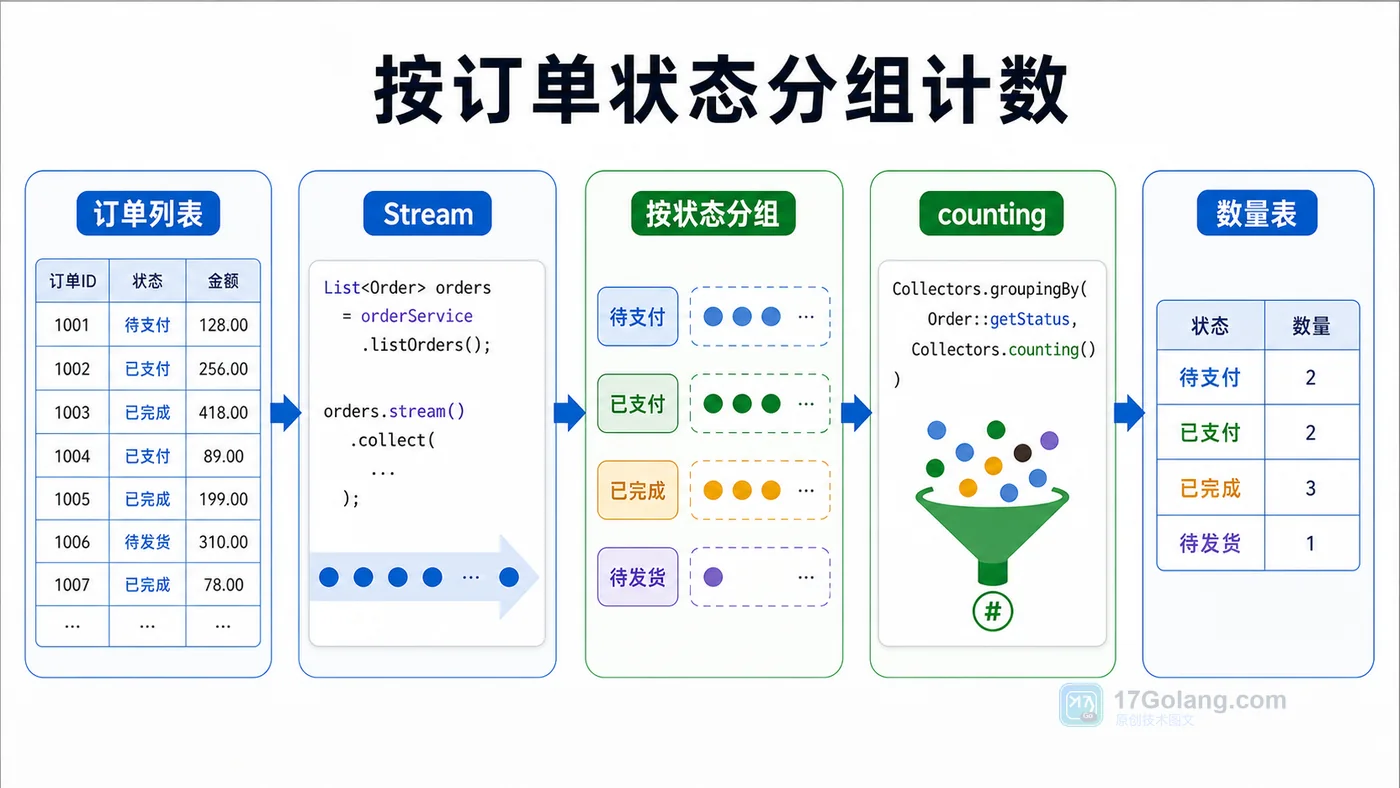
- 文章 · java教程 | 1星期前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
- Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
- 478浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2384次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2194次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2148次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2356次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2318次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


