Python处理CSV教程:csv模块使用详解
golang学习网今天将给大家带来《Python处理CSV文件教程:csv模块实战指南》,感兴趣的朋友请继续看下去吧!以下内容将会涉及到等等知识点,如果你是正在学习文章或者已经是大佬级别了,都非常欢迎也希望大家都能给我建议评论哈~希望能帮助到大家!
Python处理CSV文件最高效的方式是使用内置csv模块。1. 读取CSV文件可使用csv.reader将每行解析为列表,或使用csv.DictReader将每行转为字典,便于通过字段名访问数据;2. 写入CSV文件可使用csv.writer写入列表数据,或使用csv.DictWriter写入字典数据,并支持自动写入表头;3. 处理大型CSV文件时应逐行迭代,避免一次性加载全部数据至内存;4. 编码问题可通过open()函数指定encoding参数解决,读取时需匹配文件实际编码,写入时推荐使用utf-8-sig防止乱码;5. csv模块支持自定义分隔符(delimiter)、引用字符(quotechar)、引用策略(quoting)、双引号转义(doublequote)及跳过空格(skipinitialspace),以适应非标准格式的CSV文件。

Python处理CSV文件,最直接且高效的方式就是利用其内置的csv模块。这个模块提供了一套完善的工具集,能够轻松应对CSV文件的读写操作,无论是简单的文本数据还是需要特殊处理的复杂结构,它都能很好地胜任,避免了手动解析逗号、引号等繁琐细节。

解决方案
使用Python的csv模块处理CSV文件,核心在于理解其reader和writer对象,以及更便捷的DictReader和DictWriter。

1. 读取CSV文件
最基础的读取方式是使用csv.reader。它会把CSV文件的每一行解析成一个列表(list),列表中的每个元素对应一个字段。

import csv
# 假设有一个名为 'data.csv' 的文件
# content of data.csv:
# name,age,city
# Alice,30,New York
# Bob,24,London
# Charlie,35,Paris
try:
with open('data.csv', 'r', newline='', encoding='utf-8') as csvfile:
csv_reader = csv.reader(csvfile)
header = next(csv_reader) # 通常第一行是表头,可以单独读取
print(f"表头: {header}")
for row in csv_reader:
print(f"数据行: {row}")
except FileNotFoundError:
print("文件 'data.csv' 未找到。")
except Exception as e:
print(f"读取文件时发生错误: {e}")
# 我个人更偏爱使用 DictReader,因为它能把每一行数据变成一个字典,
# 用列名(即表头)作为键访问数据,比通过索引数字要直观和健壮得多。
print("\n--- 使用 DictReader 读取 ---")
try:
with open('data.csv', 'r', newline='', encoding='utf-8') as csvfile:
csv_dict_reader = csv.DictReader(csvfile)
# DictReader 会自动将第一行识别为字段名
print(f"字段名: {csv_dict_reader.fieldnames}")
for row_dict in csv_dict_reader:
print(f"姓名: {row_dict['name']}, 年龄: {row_dict['age']}, 城市: {row_dict['city']}")
except FileNotFoundError:
print("文件 'data.csv' 未找到。")
except Exception as e:
print(f"使用 DictReader 读取文件时发生错误: {e}")2. 写入CSV文件
写入操作与读取类似,使用csv.writer或csv.DictWriter。
import csv
# 写入操作时,通常需要指定 'w' 模式,并且 newline='' 是非常重要的,
# 它能防止在Windows系统上写入空行。
data_to_write = [
['Product', 'Price', 'Quantity'],
['Laptop', 1200, 50],
['Mouse', 25, 200],
['Keyboard', 75, 150]
]
try:
with open('products.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerows(data_to_write) # writerows 可以一次写入多行
print("\n'products.csv' 文件写入成功。")
except Exception as e:
print(f"写入文件时发生错误: {e}")
# 使用 DictWriter 写入,需要先定义好字段名(fieldnames),它会作为CSV的表头。
dict_data_to_write = [
{'name': 'David', 'age': 28, 'city': 'Berlin'},
{'name': 'Eve', 'age': 32, 'city': 'Rome'}
]
fieldnames = ['name', 'age', 'city'] # 字段顺序也很重要
try:
with open('new_users.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_dict_writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
csv_dict_writer.writeheader() # 写入表头
csv_dict_writer.writerows(dict_data_to_write) # 写入多行字典数据
print("'new_users.csv' 文件写入成功。")
except Exception as e:
print(f"使用 DictWriter 写入文件时发生错误: {e}")
在实际项目中,我发现DictReader和DictWriter用起来更顺手,因为它们直接映射了Python字典的数据结构,与我们处理数据时的思维模式更贴合。当然,如果数据量非常大,或者对内存占用有极致要求,csv.reader逐行迭代的特性可能会更受欢迎。
如何高效读取大型CSV文件,避免内存溢出?
当你面对一个动辄几百兆甚至上G的CSV文件时,直接一股脑儿地把它全读进内存,那基本上就是自寻烦恼,程序多半会直接崩溃或者卡死。Python的csv模块在设计上就考虑到了这一点,它的reader和DictReader对象都是迭代器。这意味着它们并不会一次性把所有数据都加载到内存里,而是当你需要一行数据时,它就读取一行,处理完再读取下一行。
所以,高效读取大型CSV文件的关键就在于利用这种迭代特性,逐行处理数据。你看到的for row in csv_reader:或者for row_dict in csv_dict_reader:这种循环模式,就是最典型的内存友好型处理方式。我们不应该尝试将整个CSV文件转换成一个列表的列表(list(csv_reader)),除非你确定文件很小,或者你的机器内存足够充裕。
例如,如果你只想统计某个字段的总和,完全没必要把所有数据都存起来:
import csv
# 假设 'sales_data.csv' 有大量销售数据,其中包含 'amount' 字段
# product,amount,date
# A,100.5,2023-01-01
# B,200.0,2023-01-02
# ... (millions of rows)
total_sales = 0.0
try:
with open('sales_data.csv', 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
# 确保 'amount' 字段存在
if 'amount' not in reader.fieldnames:
print("错误: CSV文件中缺少 'amount' 字段。")
else:
for row in reader:
try:
total_sales += float(row['amount'])
except ValueError:
# 处理非数字的 'amount' 值,比如跳过或者记录日志
print(f"警告: 无法将 '{row['amount']}' 转换为数字,跳过此行。")
print(f"\n总销售额: {total_sales:.2f}")
except FileNotFoundError:
print("文件 'sales_data.csv' 未找到。")
except Exception as e:
print(f"处理销售数据时发生错误: {e}")这种逐行处理的模式,无论是对内存还是CPU,压力都小得多,是处理大数据文件的不二法门。
处理CSV时常见的编码问题与解决方案是什么?
遇到乱码,十有八九是编码没对上。CSV文件本质上是纯文本,它的内容是用某种字符编码(比如UTF-8、GBK、Latin-1等)保存的。如果你用错误的编码去读取它,就会出现UnicodeDecodeError,或者更隐蔽的——读出来的是一堆“问号”或“方框”。同样,写入时如果编码不当,别人打开你的CSV文件也可能看到乱码。
常见问题及解决方案:
UnicodeDecodeError: 这是最直接的错误提示,意味着你尝试用一种编码去解码不属于它的字节序列。原因: 最常见的是CSV文件是GBK编码(尤其是国内很多老旧系统导出的),但你用默认的UTF-8去读。
解决方案: 在
open()函数中明确指定encoding参数。# 尝试用GBK编码读取 try: with open('some_gbk_encoded.csv', 'r', newline='', encoding='gbk') as f: reader = csv.reader(f) for row in reader: print(row) except UnicodeDecodeError: print("尝试GBK编码失败,可能是其他编码。") except FileNotFoundError: print("文件未找到。")如何确定编码? 有时你需要一些工具来帮助判断,比如Notepad++打开文件后看右下角的编码显示,或者使用Python的
chardet库来猜测文件的编码。# pip install chardet import chardet def detect_encoding(file_path): with open(file_path, 'rb') as f: # 以二进制模式读取,因为要检测原始字节 raw_data = f.read(100000) # 读取文件前100KB来猜测 result = chardet.detect(raw_data) return result['encoding'], result['confidence'] # encoding, confidence = detect_encoding('unknown_encoding.csv') # print(f"检测到编码: {encoding}, 置信度: {confidence}") # 然后再用检测到的编码去打开文件
写入时乱码: 你写入的CSV文件,别人打开是乱码。
- 原因: 你可能使用了UTF-8编码写入,但对方的软件(比如Excel)默认以GBK或ANSI(Windows-1252)编码打开。
- 解决方案:
- 最稳妥的是始终使用
encoding='utf-8-sig'。utf-8-sig会在文件开头添加一个BOM(Byte Order Mark),很多软件(包括Excel)会识别这个BOM,从而正确地以UTF-8编码打开文件。with open('output_for_excel.csv', 'w', newline='', encoding='utf-8-sig') as f: writer = csv.writer(f) writer.writerow(['姓名', '城市']) writer.writerow(['张三', '北京']) - 如果明确知道对方只支持GBK,那就直接用
encoding='gbk'写入。
- 最稳妥的是始终使用
总而言之,处理CSV编码问题,核心就是明确地、正确地指定open()函数中的encoding参数。
除了基本的读写,csv模块还能实现哪些高级操作?
csv模块虽然看起来简单,但它提供了一些参数,可以帮助我们处理那些不那么“规矩”的CSV文件,或者在特定场景下提供更细粒度的控制。
自定义分隔符(
delimiter): 有时CSV文件并不那么“规矩”,比如它可能用分号(;)而不是逗号(,)做分隔符,或者用制表符(\t)分隔(这种文件通常被称为TSV,Tab-Separated Values)。delimiter参数就是用来指定这个分隔符的。# 假设 'semicolon_data.csv' 是用分号分隔的 # name;age;city # Alice;30;New York import csv with open('semicolon_data.csv', 'r', newline='', encoding='utf-8') as f: reader = csv.reader(f, delimiter=';') # 指定分号为分隔符 for row in reader: print(f"分号分隔数据: {row}") # 写入时也可以指定 data = [['A', 'B'], ['C', 'D']] with open('tab_separated.tsv', 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f, delimiter='\t') # 指定制表符 writer.writerows(data) print("\n'tab_separated.tsv' 已写入,使用制表符分隔。")自定义引用字符与引用方式(
quotechar,quoting): 当字段内容本身包含分隔符(比如一个描述文本里有逗号),或者包含换行符时,CSV标准会用一个引用字符(通常是双引号")把整个字段括起来。csv模块可以自动处理这些情况,但你也可以自定义。quotechar:指定用于引用字段的字符,默认为"。quoting:指定何时进行引用。这是个枚举类型,常用的有:csv.QUOTE_MINIMAL(默认):只引用那些包含特殊字符(分隔符、引用字符、换行符)的字段。csv.QUOTE_ALL:引用所有字段。csv.QUOTE_NONNUMERIC:引用所有非数字字段。csv.QUOTE_NONE:不引用任何字段(如果字段包含特殊字符,可能会导致解析错误)。
# 示例:写入包含逗号的字段 data_with_comma = [['Item', 'Description'], ['Book', 'A great read, highly recommended']] with open('quoted_data.csv', 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f, quoting=csv.QUOTE_MINIMAL) # 默认行为,但明确写出 writer.writerows(data_with_comma) print("\n'quoted_data.csv' 已写入,包含引用字段。") # 打开 'quoted_data.csv' 会看到 "A great read, highly recommended" 被双引号括起来 # 如果想所有字段都加引号 data_all_quoted = [['Value1', 'Value2'], ['Hello', 'World']] with open('all_quoted.csv', 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f, quoting=csv.QUOTE_ALL) writer.writerows(data_all_quoted) print("'all_quoted.csv' 已写入,所有字段都被引用。")处理双引号转义(
doublequote): 在被引用的字段中,如果引用字符本身出现,它通常会被重复两次进行转义(例如"He said ""Hello"".")。doublequote参数控制是否启用这种转义,默认为True。# 假设 CSV 包含 "He said ""Hello""." # 通过 reader 读取时,它会自动处理双引号的转义 # 写入时,如果字段内容是 'He said "Hello".',writer 会自动将其转义为 '"He said ""Hello""."''
跳过空行(
skipinitialspace): 如果CSV文件在分隔符后面有额外的空格,skipinitialspace=True可以告诉reader自动跳过这些空格。# 假设 'spaced_data.csv' 内容是: # name, age # Alice, 30 import csv with open('spaced_data.csv', 'r', newline='', encoding='utf-8') as f: reader = csv.reader(f, skipinitialspace=True) for row in reader: print(f"跳过空格后的数据: {row}") # 30前面没有空格了
这些高级选项让csv模块在处理各种“奇形怪状”的CSV文件时,依然保持了强大的适应性和灵活性。在面对非标准格式的CSV时,我通常会先用文本编辑器打开文件,观察其分隔符和引用规则,然后相应地调整csv.reader或csv.writer的参数。
今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 Golang模板优化:预编译与缓存技巧解析
Golang模板优化:预编译与缓存技巧解析
- 上一篇
- Golang模板优化:预编译与缓存技巧解析

- 下一篇
- Java原子类原理及使用场景解析
-
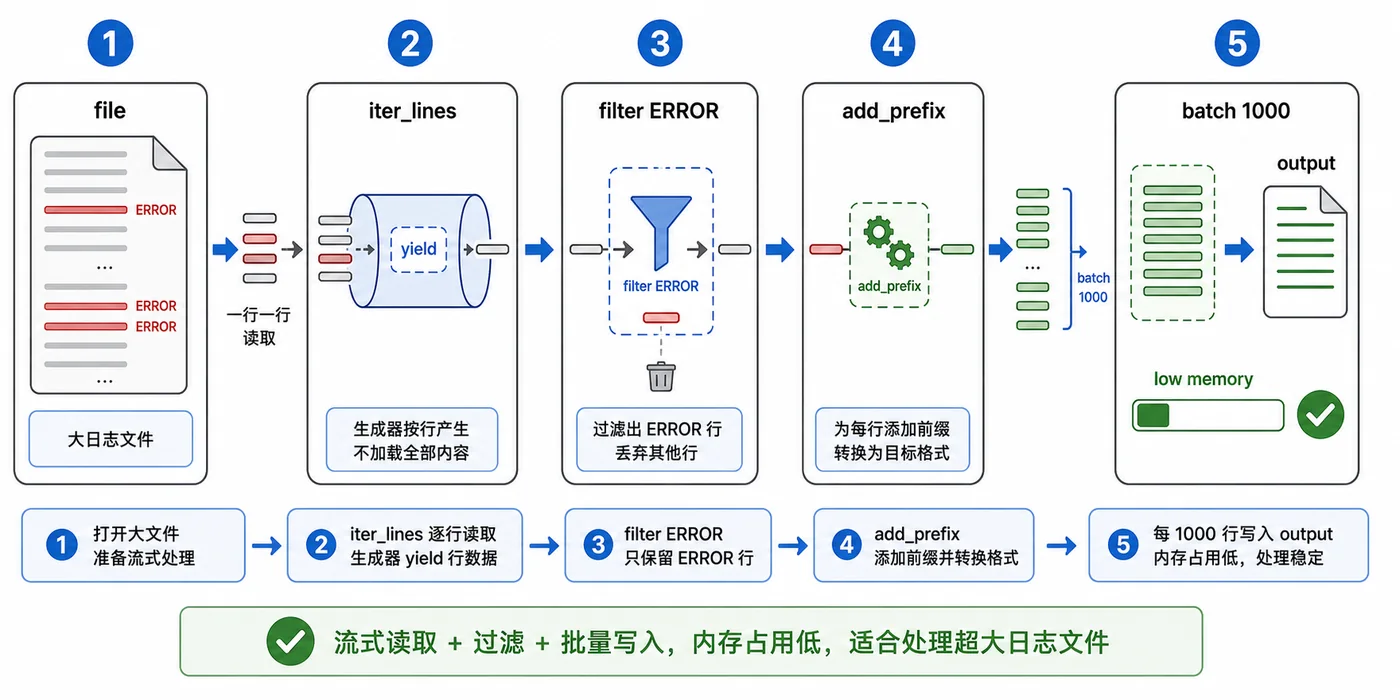
- 文章 · python教程 | 2天前 | 日志 · 链路追踪 · Python教程 · contextvars · Python logging contextvars 日志追踪 trace_id 异步上下文
- Python 日志链路追踪实战:用 contextvars 自动带上 trace_id
- 370浏览 收藏






-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8600次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9018次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8846次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10746次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9687次使用
-
- Flask框架安装技巧:让你的开发更高效
- 2024-01-03 501浏览
-
- Django框架中的并发处理技巧
- 2024-01-22 501浏览
-
- 提升Python包下载速度的方法——正确配置pip的国内源
- 2024-01-17 501浏览
-
- Python与C++:哪个编程语言更适合初学者?
- 2024-03-25 501浏览
-
- 品牌建设技巧
- 2024-04-06 501浏览


