Java事件溯源与CQRS架构解析
文章小白一枚,正在不断学习积累知识,现将学习到的知识记录一下,也是将我的所得分享给大家!而今天这篇文章《Java事件溯源CQRS架构设计详解》带大家来了解一下##content_title##,希望对大家的知识积累有所帮助,从而弥补自己的不足,助力实战开发!
基于Java的事件溯源与CQRS架构通过命令与查询分离、事件流作为唯一事实来源,提升系统灵活性与可扩展性。1. 核心组件包括命令模型(命令、命令处理器、聚合、事件存储)、事件总线及查询模型(事件处理器、查询数据库、查询服务)。2. 优势在于完整审计、调试便利、业务洞察、多视图支持、性能优化、复杂性管理、独立扩展与系统演进性。3. Java实现选型包括Axon Framework、Spring Boot、关系型或专用事件存储、Kafka等消息队列及NoSQL或Elasticsearch查询数据库。4. 常见挑战涉及事件版本化、快照管理、最终一致性处理、可观测性设计与聚合边界识别。5. 数据一致性策略包括UI反馈、幂等处理、乐观锁与补偿机制;可观测性依赖分布式追踪、结构化日志、指标监控与事件可视化工具。

设计基于Java的事件溯源(Event Sourcing)与CQRS(Command Query Responsibility Segregation)架构,核心在于将系统的写操作(命令)与读操作(查询)彻底分离,并通过不可变的事件流作为唯一的事实来源来构建应用状态。这使得系统在处理复杂业务逻辑、审计追踪、以及应对高并发读写场景时,具备了极高的灵活性和可扩展性。简单来说,你不再直接修改数据,而是记录所有“发生了什么”的事件,然后根据这些事件来构建你的数据视图。

解决方案
在Java中实现事件溯源与CQRS,我们通常会围绕以下几个核心组件来构建:

命令模型(Command Model / Write Side):
- 命令(Commands): 封装了意图的指令,例如
PlaceOrderCommand、UpdateProductPriceCommand。它们是纯粹的数据结构,不包含业务逻辑。 - 命令处理器(Command Handlers): 接收命令,加载相应的聚合(Aggregate),执行业务逻辑,然后生成一个或多个事件。
- 聚合(Aggregates): 领域驱动设计中的概念,是业务逻辑和状态的最小一致性单元。它们负责验证命令、应用业务规则,并通过内部方法(如
apply方法)生成并发布事件。聚合只通过事件来改变自身状态,事件是其内部状态变化的唯一记录。 - 事件(Events): 描述了系统内部“发生了什么”的过去式事实,例如
OrderPlacedEvent、ProductPriceUpdatedEvent。事件是不可变的,一旦发生就不能更改。 - 事件存储(Event Store): 持久化所有事件的地方。它是一个只追加(append-only)的日志,所有聚合的状态都可以通过重放其所有事件来重建。这可以是关系型数据库中的一张事件表,也可以是专门的事件存储系统(如EventStoreDB、Kafka作为事件日志)。
- 命令(Commands): 封装了意图的指令,例如
事件总线/发布订阅机制(Event Bus / Pub-Sub):

- 事件一旦被聚合生成并存储,就会通过事件总线发布出去。这可以是内存中的简单发布器,也可以是消息队列(如Kafka、RabbitMQ)用于跨服务通信。
查询模型(Query Model / Read Side):
- 事件处理器/投影(Event Handlers / Projectors): 监听事件总线上的事件。当收到事件时,它们会将事件数据转换并存储到为查询优化过的数据库视图中。这些视图通常是去范式的,以满足特定查询需求。
- 查询数据库(Query Database): 存储查询模型的数据。这可以是关系型数据库、NoSQL数据库(MongoDB、Elasticsearch),甚至是内存数据库,具体取决于查询需求。
- 查询服务(Query Service): 暴露查询接口,供客户端调用以获取数据。它直接从查询数据库中读取数据,不涉及任何复杂的业务逻辑。
实现流程简述:
- 客户端发送一个
Command到命令服务。 - 命令服务通过
Command Bus将命令路由到对应的Command Handler。 Command Handler加载相关Aggregate(可能从事件存储中重放事件来重建)。Aggregate执行业务逻辑,生成Event。Event被持久化到Event Store。Event通过Event Bus发布。Event Handler/Projector监听事件,更新Query Database中的查询模型。- 客户端通过
Query Service从Query Database获取数据。
为什么选择事件溯源和CQRS组合?它们能解决哪些痛点?
说实话,第一次接触事件溯源和CQRS的时候,感觉这东西挺绕的,把一个简单的CRUD搞得那么复杂。但深入进去,你就会发现它真的能解决一些传统架构下让人头疼的问题,尤其是在业务逻辑复杂、数据变动频繁、历史追溯需求强的场景下。
首先,事件溯源的核心魅力在于它提供了一个完整的、不可变的业务事实日志。想想看,你的系统不再仅仅存储数据的“当前状态”,而是记录了所有导致这个状态变化的“事件”。这就像给你的业务数据装了一个永不停止的录像机。它能解决的痛点包括:
- 完整审计与历史回溯: 任何时候,你都可以精确地知道一个实体是如何达到当前状态的,甚至可以“时光倒流”到任何一个历史时刻。这对于金融、医疗等领域,或者任何需要强审计追踪的业务来说,简直是福音。
- 调试与问题分析: 当出现问题时,你不再需要猜测数据为何变成这样,直接重放事件流就能复现问题,定位根源。
- 业务洞察: 通过分析事件流,你可以发现业务模式、用户行为,为数据分析和决策提供更丰富、更准确的原始数据。
- 多视图支持: 由于所有数据都来自事件,你可以随时创建新的读模型(Projections),以满足新的报表或分析需求,而无需修改核心业务逻辑。
再来说说CQRS。它将读写职责分离,就像是把一个既要跑得快又要装得多的大卡车,拆成了轻便的跑车(写)和载重的大货车(读)。这样一来,各自都能针对性地优化,解决的痛点就明显了:
- 性能优化: 大多数应用都是读多写少。CQRS允许你为读操作构建高度优化的、去范式化的数据模型,甚至使用不同的数据库技术,大大提升查询性能。写操作则可以专注于事务一致性和业务逻辑。
- 复杂性管理: 在一个复杂领域模型中,读写操作往往有不同的关注点。CQRS将它们分离开,降低了单个模块的复杂性,使开发和维护变得更清晰。
- 独立扩展: 读服务和写服务可以独立扩展,互不影响。当读压力大时,你可以只增加读服务的实例;写压力大时,只增加写服务的实例。
- 演进性: 读模型可以随时根据需求变化而重新生成或调整,而不会影响核心的写模型和业务逻辑。
将两者结合,你拥有了一个既能追踪历史又能高效处理查询的强大架构。比如,在电商订单系统里,下单(写)需要严格的事务一致性,而查询订单列表(读)则需要极高的并发性能和灵活的筛选条件。事件溯源记录了订单从创建到支付、发货的所有状态变更事件,CQRS则可以根据这些事件构建出各种查询视图,比如“待发货订单列表”、“用户历史订单概览”等,每个视图都针对其查询场景做了优化。
在Java中实现事件溯源,有哪些关键技术选型和常见挑战?
在Java生态里,实现事件溯源和CQRS,可选择的技术栈非常丰富,但同时也会遇到一些特定的挑战。
关键技术选型:
领域模型框架:
- Axon Framework: 这是Java世界里最成熟、最全面的事件溯源和CQRS框架之一。它提供了命令总线、事件总线、聚合、事件存储、查询模型等所有核心组件的抽象和实现,开箱即用,非常适合快速构建复杂的CQRS应用。它帮你处理了大量底层细节,比如聚合的加载、事件的发布、快照管理等。
- Spring Boot + DDD: 如果不想引入一个大而全的框架,也可以基于Spring Boot,结合领域驱动设计(DDD)的原则,自己实现CQRS的各个组件。你需要自己管理命令分发、事件持久化、事件发布订阅等。这提供了最大的灵活性,但也意味着更多的工作量和对DDD更深的理解。
事件存储:
- 关系型数据库(RDBMS,如PostgreSQL、MySQL): 最常见的方式是创建一张只追加的事件表。每行代表一个事件,包含事件ID、聚合ID、事件类型、事件数据(JSON或Protobuf)、版本号、时间戳等。优点是成熟稳定,事务支持好;缺点是对于海量事件查询效率可能不如专用事件存储。
- 专用事件存储(如EventStoreDB): 专门为事件溯源设计的数据库,提供高性能的事件追加和流式读取能力,支持事件流订阅。
- 消息队列(如Kafka): Kafka本身就是一个分布式日志,非常适合作为事件日志。你可以将事件直接写入Kafka Topic,并利用其消费者组机制实现事件的订阅和投影。优点是吞吐量高、扩展性强;缺点是需要额外的持久化层来存储事件的元数据,或者依赖Kafka的日志保留策略。
消息队列/事件总线:
- Kafka: 强大的分布式流处理平台,非常适合作为事件总线,实现事件的可靠发布和订阅。
- RabbitMQ/ActiveMQ: 传统的消息队列,也可以用于事件的发布订阅,但可能不如Kafka在事件流处理方面有优势。
- Spring Cloud Stream: 提供了统一的编程模型来构建消息驱动的微服务,可以与Kafka、RabbitMQ等集成。
查询数据库:
- 关系型数据库: 依然可以用于存储去范式化的查询视图。
- NoSQL数据库(如MongoDB、Cassandra): 对于需要灵活模式、高扩展性或特定查询模式的场景,NoSQL是很好的选择。
- Elasticsearch: 适用于全文搜索和复杂聚合查询的场景。
常见挑战:
- 事件版本化(Event Versioning): 业务需求会变,事件的结构也会变。如何处理旧事件的结构与新事件不兼容的问题?这通常需要Upcasters(或称Event Migrators),在重放旧事件时将其转换为新版本结构。这块非常考验设计功力,不然后期会很痛苦。
- 快照(Snapshotting): 随着事件数量的增长,重建一个聚合的状态可能需要重放成千上万个事件,这会非常慢。因此,需要定期对聚合的状态进行快照,将快照保存到事件存储中,下次加载聚合时可以从最近的快照开始重放,大大减少加载时间。但快照的频率和管理也是个学问。
- 最终一致性(Eventual Consistency)的理解与处理: CQRS的读写分离必然导致读模型与写模型之间存在延迟,即“最终一致性”。这可能导致用户在执行写操作后,立即查询却看不到最新结果。你需要与产品经理和用户沟通,明确这种延迟是可接受的,并在UI上给出适当的反馈(例如“您的请求已提交,数据正在更新中…”)。对于对实时性要求极高的场景,可能需要额外的机制(如WebSockets推送更新)。
- 调试与可观测性: 事件流是异步的,追踪一个请求从命令到事件再到读模型更新的全链路会变得复杂。需要引入分布式追踪(如OpenTelemetry、Zipkin)、详细的日志记录和监控,来确保系统的可观测性。
- 聚合设计: 如何正确识别和设计聚合是DDD和事件溯源的关键。聚合边界过大容易导致并发冲突和性能问题,过小则可能导致事务分散和逻辑复杂。这需要对业务领域有深入的理解和实践经验。
- 事务管理: 在事件溯源中,核心的“事务”是事件的原子性写入。确保事件被成功写入事件存储,并且聚合的状态变更与事件发布是原子性的。这通常通过乐观锁或事务日志模式来实现。
如何确保CQRS架构下的数据一致性与系统可观测性?
在CQRS架构下,数据一致性(尤其是最终一致性)和系统的可观测性是两个需要特别关注的方面。它们不再像传统CRUD那样直观,需要更精细的设计和工具支持。
数据一致性:
这里主要讨论的是“最终一致性”下的挑战和应对策略,因为这是CQRS的固有特性。
- 理解和沟通最终一致性: 最重要的是,团队和业务方要充分理解最终一致性意味着什么。它不是“不一致”,而是“需要时间才能达到一致”。对于大多数业务场景,几百毫秒甚至几秒的延迟是可以接受的。关键在于,你要知道哪些业务流程对实时性要求极高,哪些可以接受延迟。
- UI反馈与用户体验:
- 当用户执行一个写操作后,立即在UI上显示一个“操作已提交,正在处理中”或“数据正在更新”的提示,而不是直接刷新显示“新数据”。
- 对于需要实时反馈的场景,可以考虑使用WebSocket或SSE(Server-Sent Events)从读模型服务推送更新到客户端,一旦读模型更新完成,客户端立即刷新。
- 在某些极端需要强一致性的场景,可以考虑在命令处理完成后,直接返回部分必要数据(比如操作成功ID),并提示用户稍后刷新查看详情。
- 幂等性处理: 事件处理器在更新读模型时必须是幂等的。这意味着同一个事件被处理多次(例如由于网络重试或消费者重启)不会导致数据错误。事件处理器应该检查是否已经处理过该事件,或者设计更新逻辑使其天然幂等(如“设置某个值”而不是“增加某个值”)。
- 版本控制与乐观锁: 在写端(命令模型),确保聚合状态的并发修改不会导致数据丢失。通常通过在聚合上维护一个版本号,并在事件写入时进行乐观锁检查。如果版本不匹配,说明有并发修改,命令应该被拒绝并重试。
- 补偿机制: 尽管事件溯源本身提供了“重放”的能力,但在某些复杂业务流程中,如果一个命令链条中的某个步骤失败了,可能需要“补偿”之前的操作。这通常涉及到发布新的补偿命令或事件来回滚之前的效果。
系统可观测性:
由于CQRS将系统拆分为多个服务(命令服务、多个投影服务、查询服务),且数据流是异步的,因此需要更强大的可观测性工具来理解系统的行为和诊断问题。
- 分布式追踪(Distributed Tracing): 这是核心。使用OpenTelemetry、Zipkin或Jaeger等工具,跟踪一个请求从客户端发出命令,到命令服务处理,生成事件,事件被消息队列传递,再到各个投影服务处理事件并更新读模型,最后到查询服务响应查询的全链路。这样,当出现问题时,你可以清晰地看到哪个环节出了问题,以及延迟在哪里。
- 结构化日志(Structured Logging): 所有的服务都应该输出结构化日志(如JSON格式),包含请求ID、关联ID(Correlation ID,用于将命令、事件和投影操作关联起来)、时间戳、服务名称、操作类型等关键信息。这使得你可以使用ELK Stack(Elasticsearch, Logstash, Kibana)或Grafana Loki等工具进行高效的日志查询和分析。
- 业务指标与监控(Business Metrics & Monitoring):
- 命令处理延迟: 监控命令从接收到事件持久化完成的平均时间。
- 事件发布速率: 监控每秒发布的事件数量。
- 投影延迟(Projection Lag): 监控每个投影服务处理事件的最新进度与事件存储最新事件之间的差距。这是衡量最终一致性“新鲜度”的关键指标。如果这个延迟持续增加,说明投影服务可能存在瓶颈。
- 查询响应时间: 监控查询服务的API响应时间。
- 错误率: 监控命令处理失败率、事件处理失败率等。
- 使用Prometheus、Grafana等工具构建仪表盘,实时展示这些关键指标。
- 健康检查与警报: 为所有服务(命令服务、各个投影服务、查询服务)设置健康检查端点。当服务出现异常或关键指标超出阈值时,及时触发警报。
- 事件存储的可视化与管理: 能够方便地查看事件存储中的事件流,对于调试和理解系统历史非常有帮助。一些事件存储(如EventStoreDB)提供了管理界面,或者你可以自己构建一个简单的事件浏览器。
说实话,刚开始做这块,最头疼的就是数据一致性,总觉得读写分离后数据“不实时”,甚至会质疑这种架构是不是“增加了复杂性”。但慢慢你会发现,大部分业务场景其实是能接受“最终一致性”的,关键在于如何把这种状态清晰地反馈给用户,并且通过强大的可观测性工具,让你对整个数据流向和系统健康状况了如指掌。这就像你开一辆自动驾驶汽车,你不需要每时每刻都盯着方向盘,但你需要一个靠谱的仪表盘告诉你它在做什么,以及它是否一切正常。
今天带大家了解了的相关知识,希望对你有所帮助;关于文章的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 Python地理编码教程:Geopy库使用指南
Python地理编码教程:Geopy库使用指南
- 上一篇
- Python地理编码教程:Geopy库使用指南

- 下一篇
- CSS外边距设置全攻略
-

- 文章 · java教程 | 2天前 | 并发编程 · 生产实践 · Java教程 · JDK25 · 虚拟线程 · 虚拟线程 Java 25 JEP 505 Structured Concurrency StructuredTaskScope
- Java 25 Structured Concurrency 实战:别让 CompletableFuture 把超时拖散
- 443浏览 收藏
-
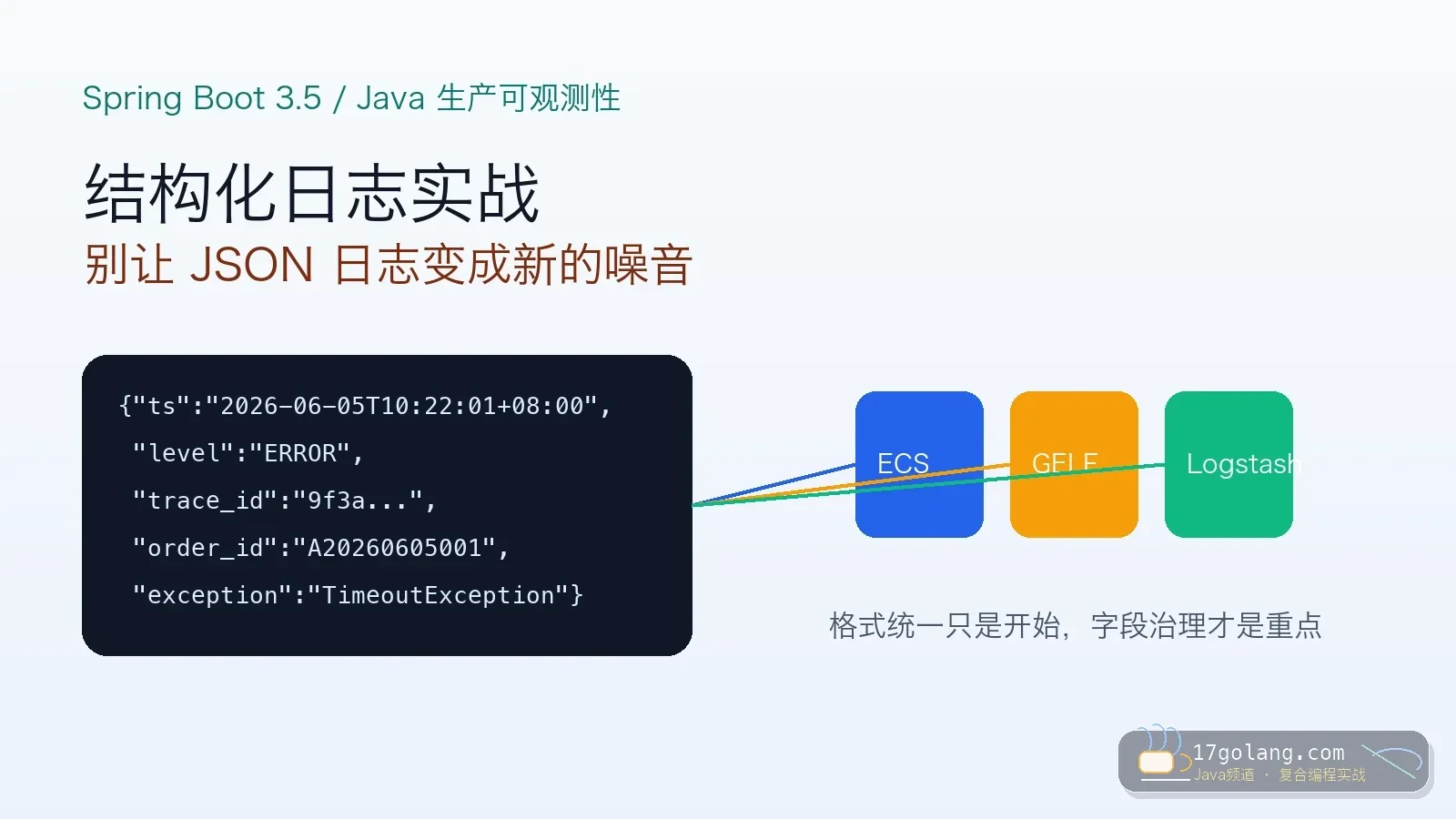
- 文章 · java教程 | 6天前 | 日志 · Spring Boot · 生产实践 · 可观测性 · Java教程 · java 可观测性 MDC 结构化日志 Spring Boot 3.5
- Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
- 332浏览 收藏
-
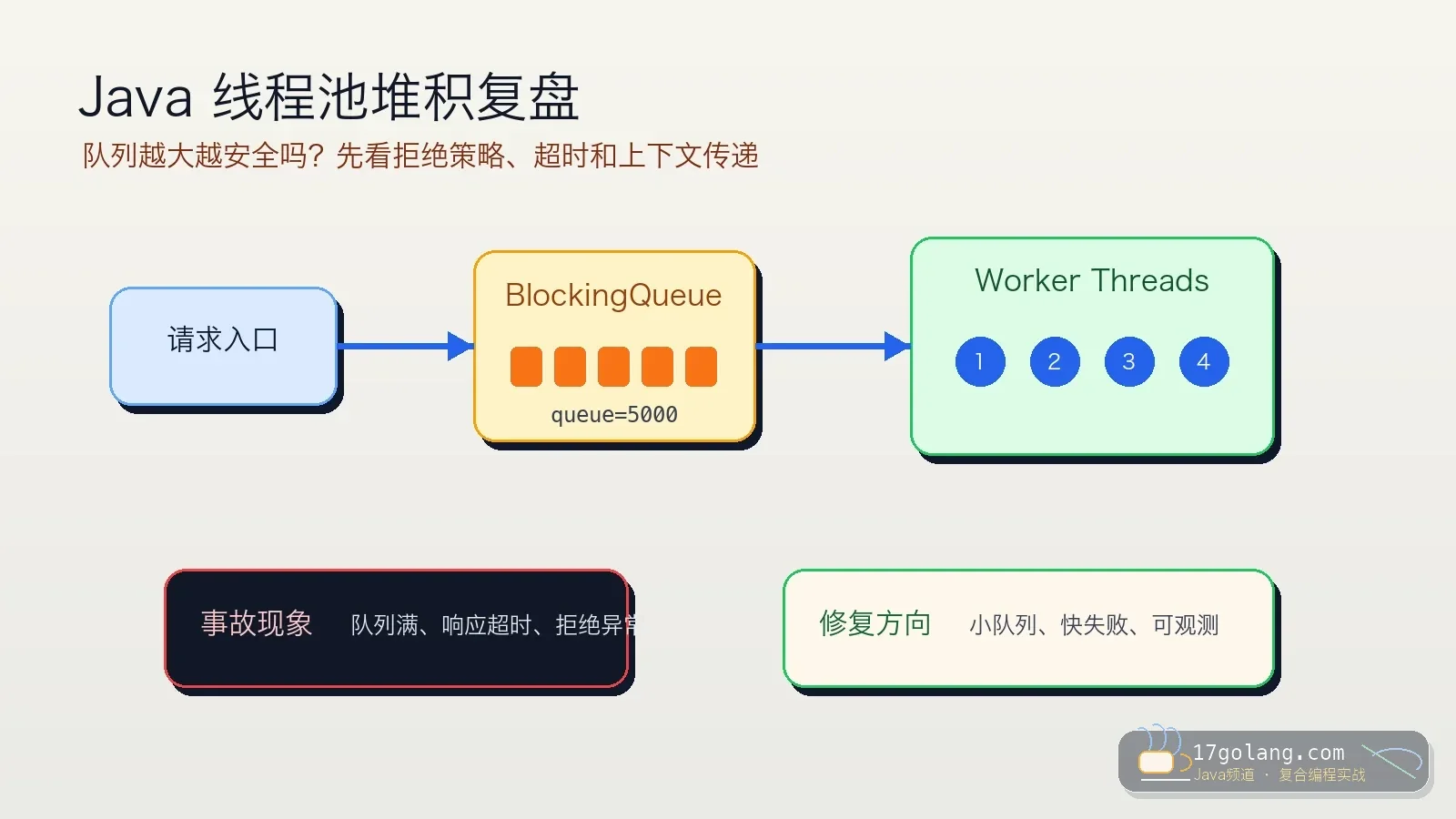
- 文章 · java教程 | 6天前 | 线程池 · Spring Boot · 生产实践 · Java教程 · ThreadPoolExecutor · java 性能优化 线程池 spring boot threadpoolexecutor
- Java 线程池队列堆积复盘:别让无界队列把慢故障藏起来
- 326浏览 收藏
-
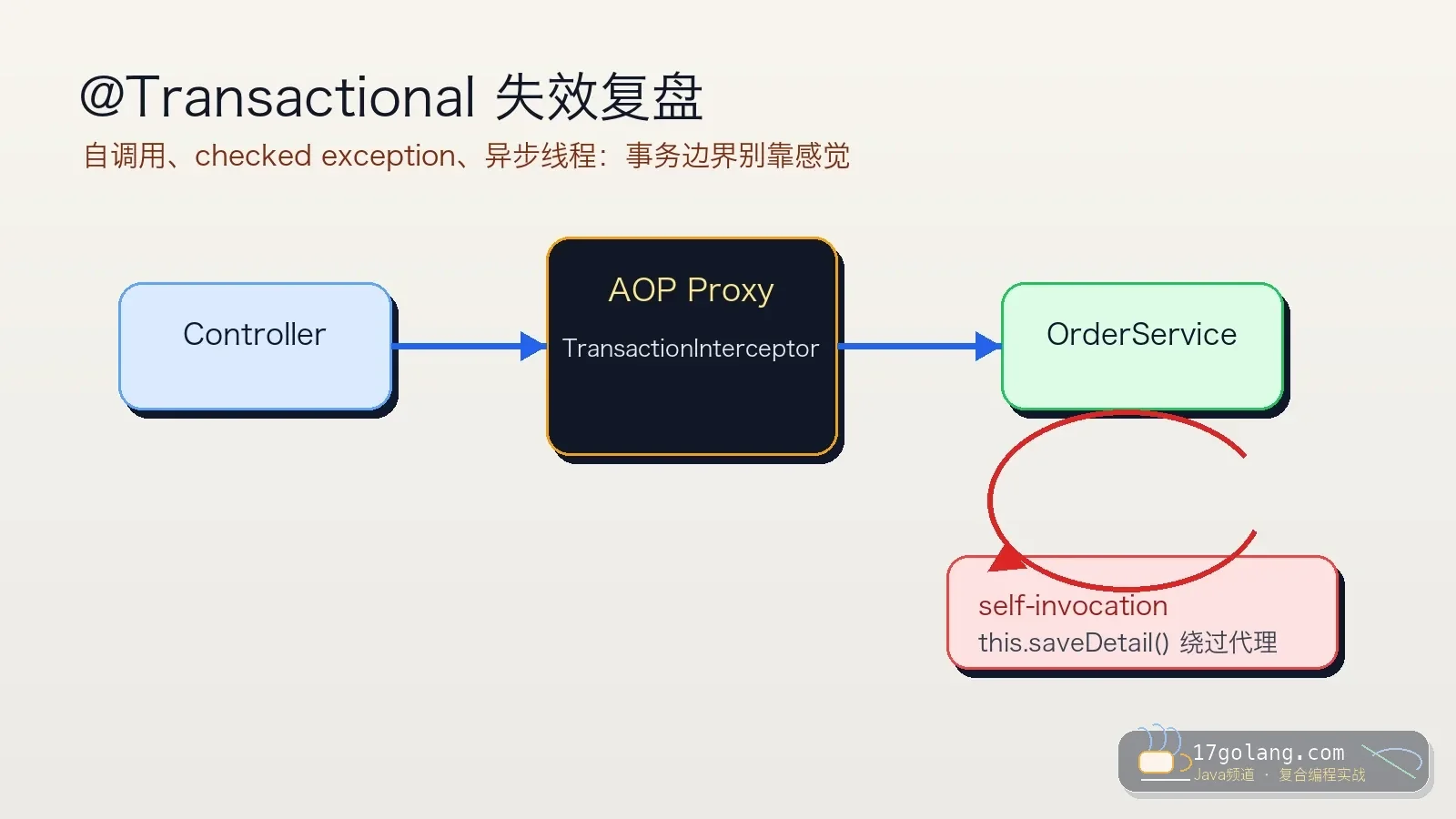
- 文章 · java教程 | 6天前 | Spring Boot · 事务管理 · 生产实践 · Java教程 · Transactional · java 事务管理 spring boot 生产实践 Transactional
- @Transactional 失效复盘:自调用、异常回滚和异步线程别再踩坑
- 259浏览 收藏
-
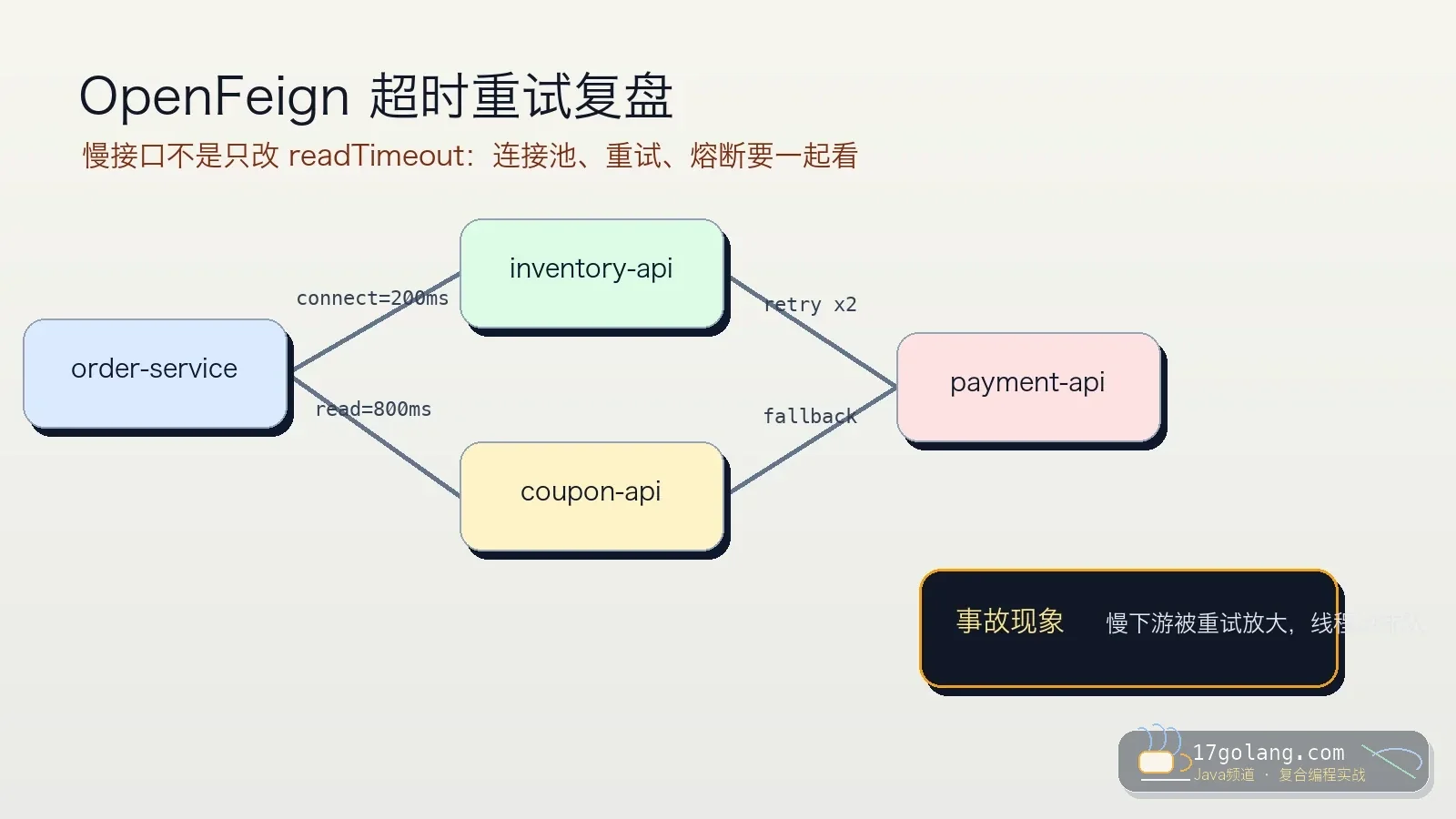
- 文章 · java教程 | 6天前 | 微服务 · 生产实践 · Java教程 · Spring Cloud · OpenFeign · java 微服务 Spring Cloud 超时重试 OpenFeign
- OpenFeign 超时重试踩坑:别把慢下游重试成全链路雪崩
- 363浏览 收藏
-
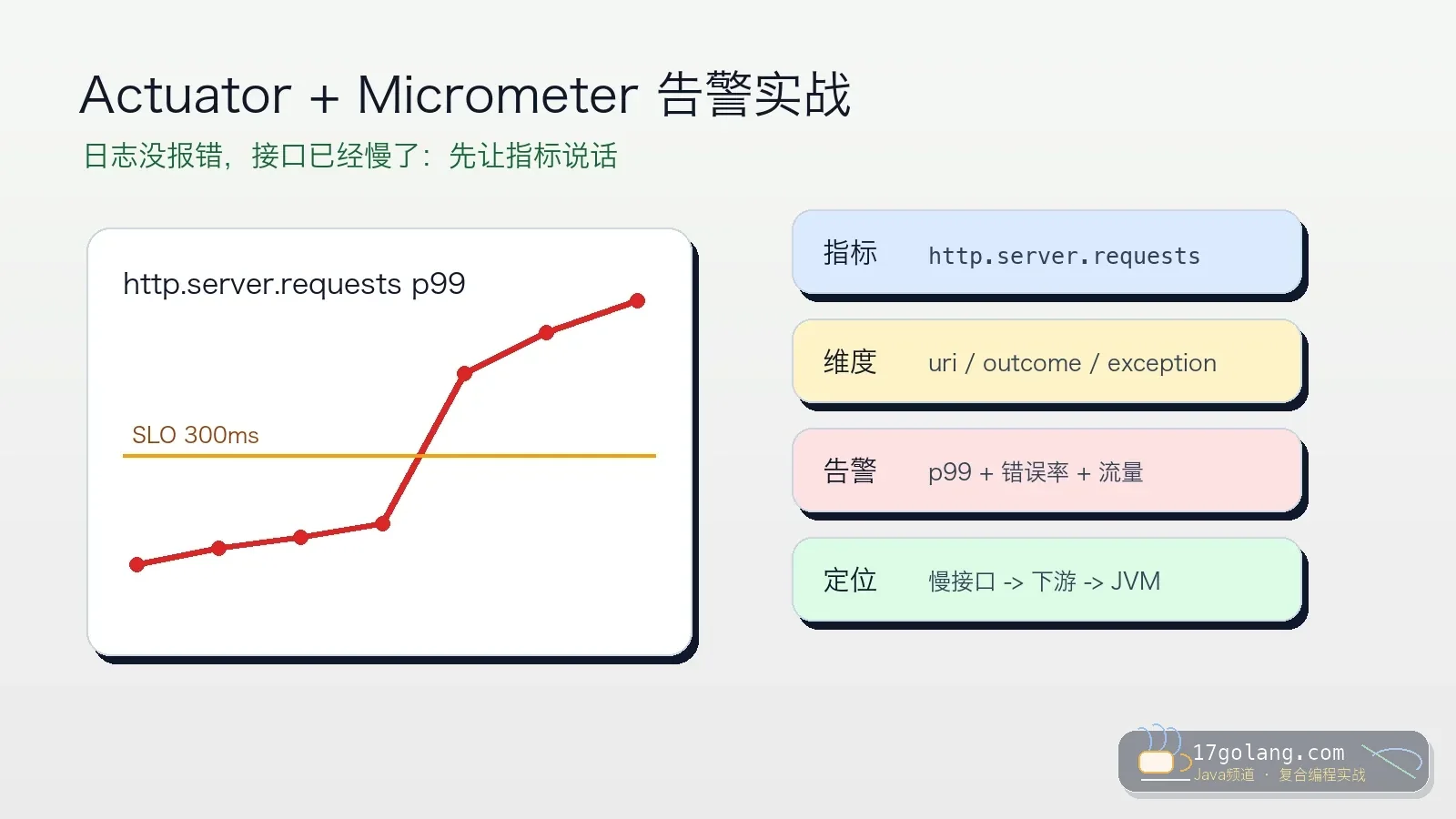
- 文章 · java教程 | 6天前 | Spring Boot · 生产实践 · Java教程 · Micrometer · Actuator · java spring boot Micrometer 可观测性 actuator
- Spring Boot 指标告警实战:Actuator + Micrometer 让慢接口先暴露
- 240浏览 收藏
-
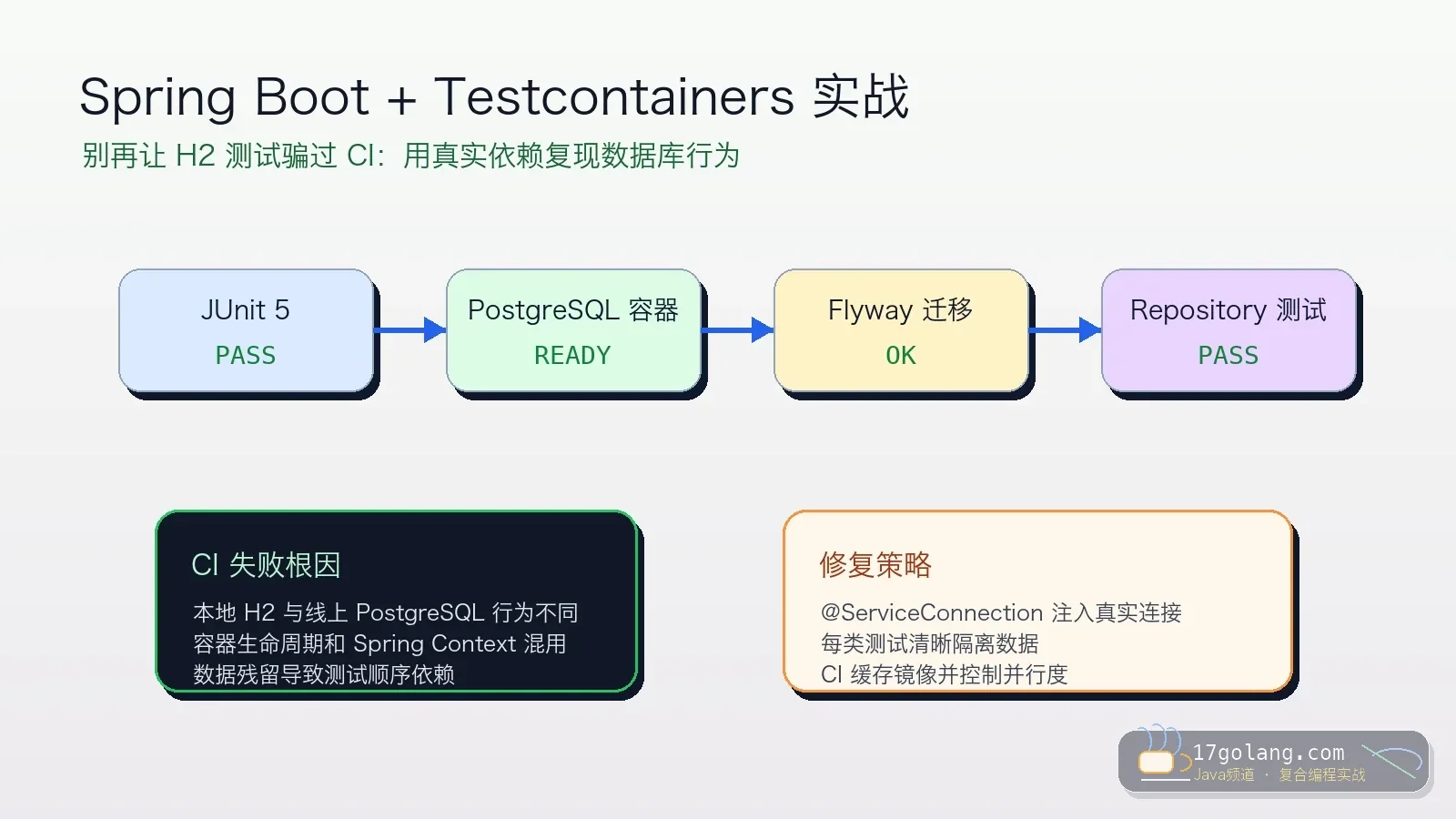
- 文章 · java教程 | 6天前 | 工程化 · Spring Boot · junit · Java教程 · Testcontainers · java 集成测试 spring boot JUnit 5 Testcontainers
- Spring Boot 集成测试别再只靠 H2:Testcontainers 落地踩坑复盘
- 154浏览 收藏
-
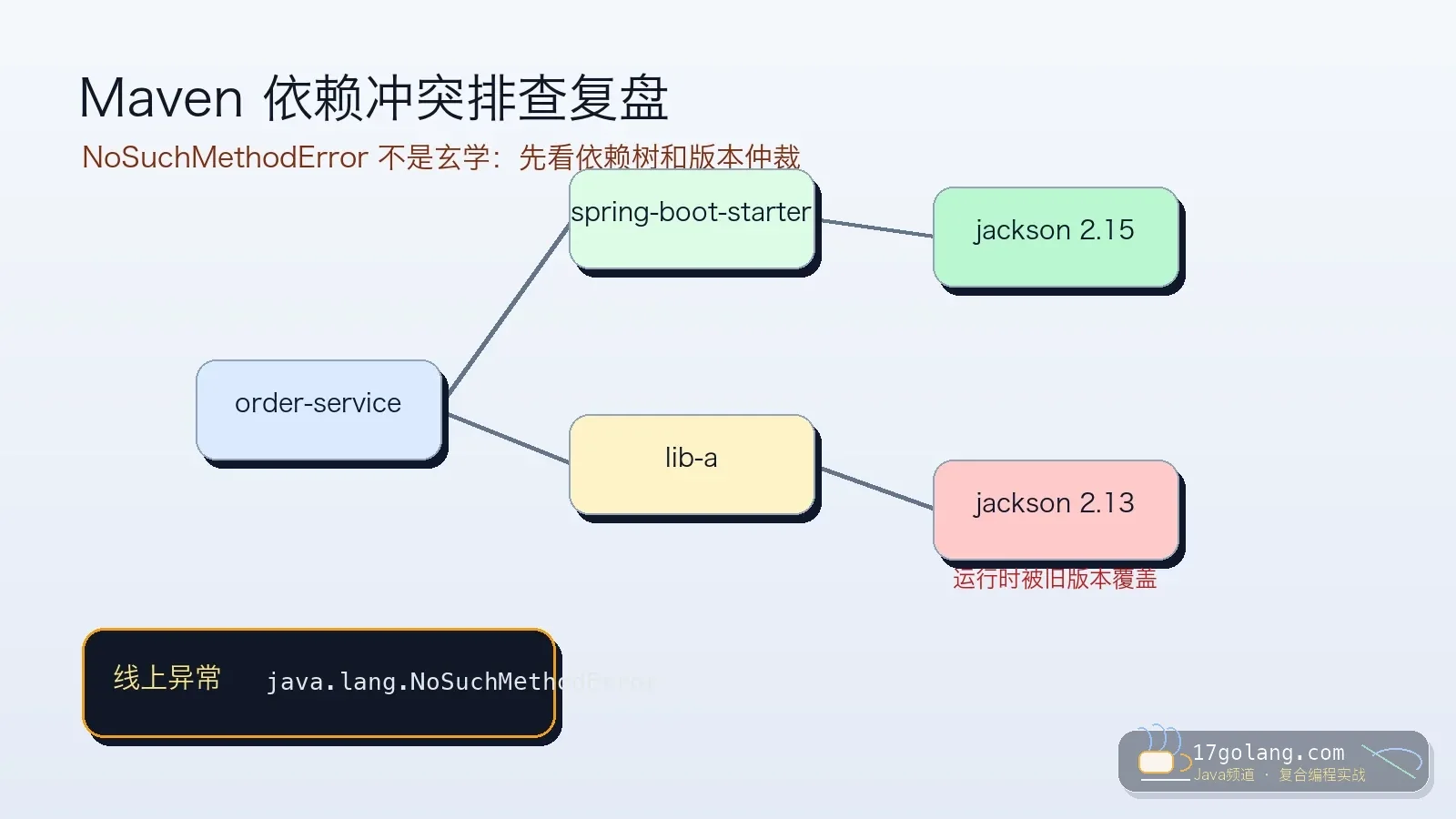
- 文章 · java教程 | 6天前 | 依赖管理 · Spring Boot · maven · 生产实践 · Java教程 · java maven spring boot 依赖冲突 工程化
- Maven 依赖冲突排查:NoSuchMethodError 不是玄学,先看依赖树
- 135浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7539次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 7968次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 7771次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 9713次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8502次使用
-
- 提升Java功能开发效率的有力工具:微服务架构
- 2023-10-06 501浏览
-
- 掌握Java海康SDK二次开发的必备技巧
- 2023-10-01 501浏览
-
- 如何使用java实现桶排序算法
- 2023-10-03 501浏览
-
- Java开发实战经验:如何优化开发逻辑
- 2023-10-31 501浏览
-
- 如何使用Java中的Math.max()方法比较两个数的大小?
- 2023-11-18 501浏览


