Java小白也能看懂!手把手教你用代码爬取网页数据
还在为网页数据抓取烦恼吗?本文将手把手教你使用Java实现网络爬虫,轻松抓取网页数据!文章深入解析了Java爬虫的核心技术,即模拟浏览器行为,通过发送HTTP请求、接收响应并解析HTML内容来提取信息。从选择合适的爬虫框架(Jsoup、WebMagic、Nutch等),到应对反爬机制(User-Agent伪装、代理IP、验证码处理),再到高效的数据存储方案(文件、数据库、NoSQL),本文都提供了详细的指导和示例代码。掌握这些要点,你就能构建高效稳定的Java网络爬虫系统,快速获取所需数据,为你的项目赋能!
Java中抓取网页的核心在于模拟浏览器行为,通过发送HTTP请求、接收响应并解析HTML内容来提取信息。1.选择合适的框架是关键:小型项目可用Jsoup+HttpClient组合,中型项目推荐WebMagic,大型项目则适合Nutch;2.应对反爬机制需设置User-Agent伪装浏览器、使用代理IP防止封禁、处理验证码或动态加载内容;3.数据存储方面可根据结构和规模选择文件、数据库或NoSQL方式,如用MySQL存储结构化商品信息。掌握这些要点即可高效构建Java网络爬虫系统。

Java中抓取网页,核心在于模拟浏览器行为,发送HTTP请求,接收响应,解析HTML内容,提取所需信息。这并非难事,但细节颇多,需要考虑编码、反爬、性能等问题。

网络爬虫的实现,本质上就是与服务器“对话”,然后“阅读”服务器返回的“故事”。

如何选择合适的Java爬虫框架?
选择爬虫框架,就像挑选趁手的兵器。Java生态里选择很多,Jsoup、HttpClient、WebMagic、Nutch等各有千秋。

Jsoup轻量级,擅长解析HTML,如果你只需要简单抓取和解析,Jsoup足矣。HttpClient则更底层,提供了更多控制HTTP请求的选项,适合需要定制请求头的场景。WebMagic封装度更高,提供了更完善的爬虫流程管理,适合构建复杂的爬虫应用。Nutch则是重量级选手,适合大规模数据抓取,但学习成本也较高。
我的建议是:根据项目规模和需求选择。小型项目,Jsoup+HttpClient足以应对;中型项目,WebMagic可以简化开发;大型项目,Nutch可能更适合。别忘了,没有最好的框架,只有最合适的框架。
举个例子,如果我们要抓取某个电商网站的商品价格,使用Jsoup可以这样:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class PriceFetcher {
public static void main(String[] args) throws IOException {
String url = "https://www.example.com/product/123"; // 替换为实际URL
Document doc = Jsoup.connect(url).get();
Element priceElement = doc.select(".price").first(); // 假设价格在class为price的元素中
if (priceElement != null) {
String price = priceElement.text();
System.out.println("商品价格:" + price);
} else {
System.out.println("未找到商品价格");
}
}
}这段代码简洁明了,展示了Jsoup的强大之处。但别忘了,实际情况可能更复杂,需要处理异常、编码问题等。
如何应对常见的反爬机制?
反爬机制是爬虫工程师的宿敌。常见的反爬手段包括:User-Agent限制、IP封禁、验证码、动态加载等。
应对User-Agent限制,可以伪装成浏览器,设置请求头。IP封禁,可以使用代理IP。验证码,可以尝试OCR识别或接入第三方验证码服务。动态加载,可以使用Selenium模拟浏览器行为,或者分析Ajax请求,直接请求API接口。
代理IP是个好东西,但免费的代理IP往往不稳定,付费的代理IP则需要成本。所以,需要根据实际情况权衡。
例如,我们可以使用HttpClient设置User-Agent:
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class UserAgentExample {
public static void main(String[] args) throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("https://www.example.com"); // 替换为实际URL
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(httpGet);
try {
System.out.println(EntityUtils.toString(response.getEntity()));
} finally {
response.close();
}
}
}这段代码将User-Agent设置为Chrome浏览器的User-Agent,可以绕过一些简单的User-Agent限制。
如何高效地存储抓取到的数据?
数据存储是爬虫的最后一环,也是至关重要的一环。常见的数据存储方式包括:文件存储、数据库存储、NoSQL存储。
文件存储简单粗暴,适合存储少量数据。数据库存储则更规范,适合存储结构化数据。NoSQL存储则适合存储半结构化或非结构化数据。
选择哪种存储方式,取决于数据的规模、结构和用途。如果数据量不大,且结构简单,可以选择文件存储。如果数据量较大,且需要进行复杂的查询和分析,可以选择数据库存储。如果数据结构不固定,或者需要存储大量文本数据,可以选择NoSQL存储。
例如,我们可以使用MySQL存储抓取到的商品信息:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class DataStorageExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/crawler_db"; // 替换为实际数据库URL
String user = "root"; // 替换为数据库用户名
String password = "password"; // 替换为数据库密码
try (Connection connection = DriverManager.getConnection(url, user, password)) {
String sql = "INSERT INTO products (name, price, url) VALUES (?, ?, ?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, "商品名称"); // 替换为实际商品名称
preparedStatement.setDouble(2, 99.99); // 替换为实际商品价格
preparedStatement.setString(3, "https://www.example.com/product/123"); // 替换为实际商品URL
preparedStatement.executeUpdate();
System.out.println("数据存储成功");
} catch (SQLException e) {
e.printStackTrace();
}
}
}这段代码将商品名称、价格和URL存储到MySQL数据库中。需要注意的是,需要先创建数据库和表,并配置好数据库连接。
总而言之,Java爬虫是一个充满挑战和乐趣的领域。掌握了这些技巧,你就可以轻松地从网络上获取所需的信息,并构建强大的数据应用。
今天关于《Java小白也能看懂!手把手教你用代码爬取网页数据》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于Http请求,数据存储,网络爬虫,Java爬虫,反爬机制的内容请关注golang学习网公众号!
 MySQL删数据太慢?3种千万级数据删除方案大对比
MySQL删数据太慢?3种千万级数据删除方案大对比
- 上一篇
- MySQL删数据太慢?3种千万级数据删除方案大对比

- 下一篇
- Win10引导文件丢失?手把手教你快速修复!
-
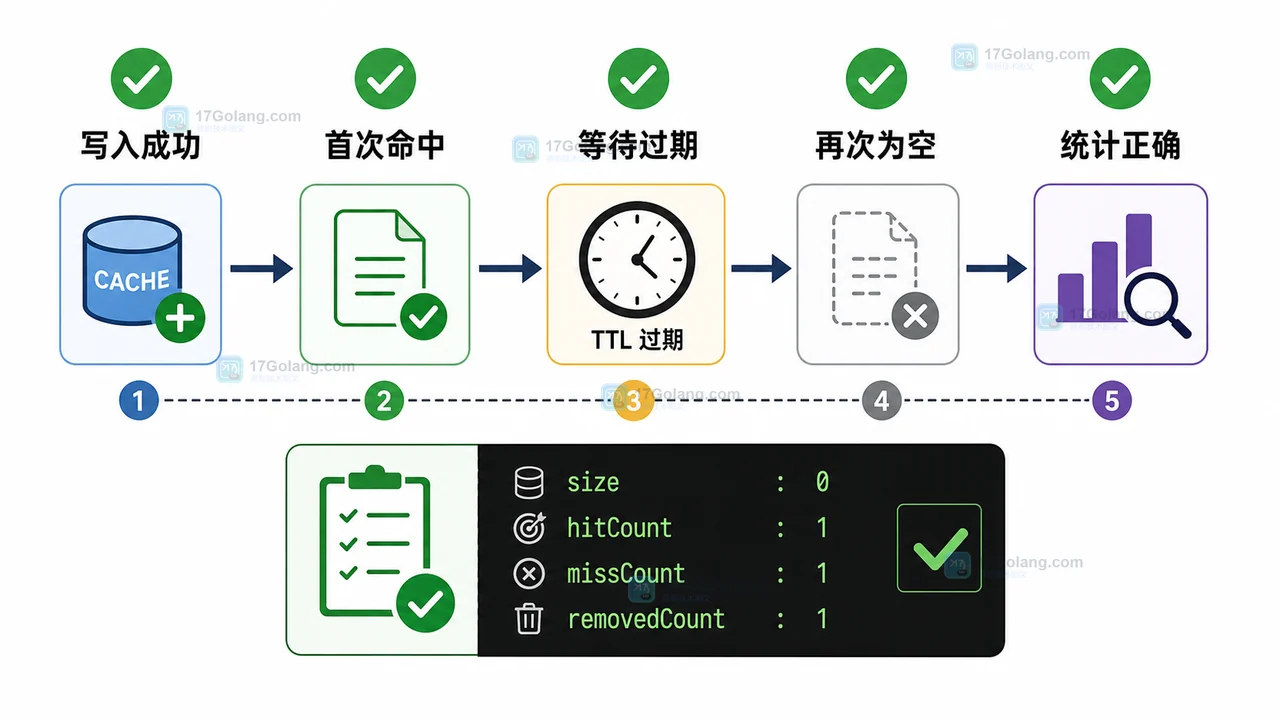
- 文章 · java教程 | 1天前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
- Java 本地 TTL 缓存小项目:用 ConcurrentHashMap 实现过期淘汰和命中统计
- 394浏览 收藏
-
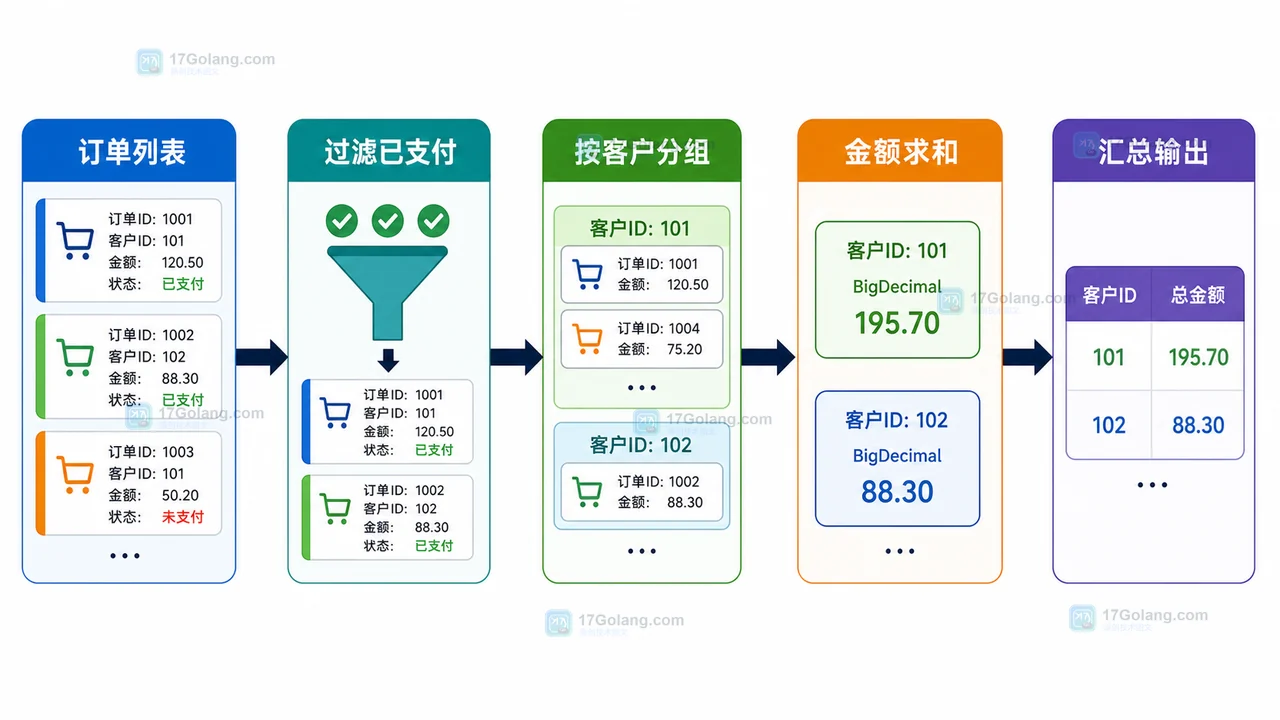
- 文章 · java教程 | 1天前 | Java · Stream · 数据处理 · 后端教程 · Java Stream bigdecimal 分组统计 Collectors 订单汇总
- Java Stream 分组统计实验:从订单列表到客户消费汇总
- 355浏览 收藏
-
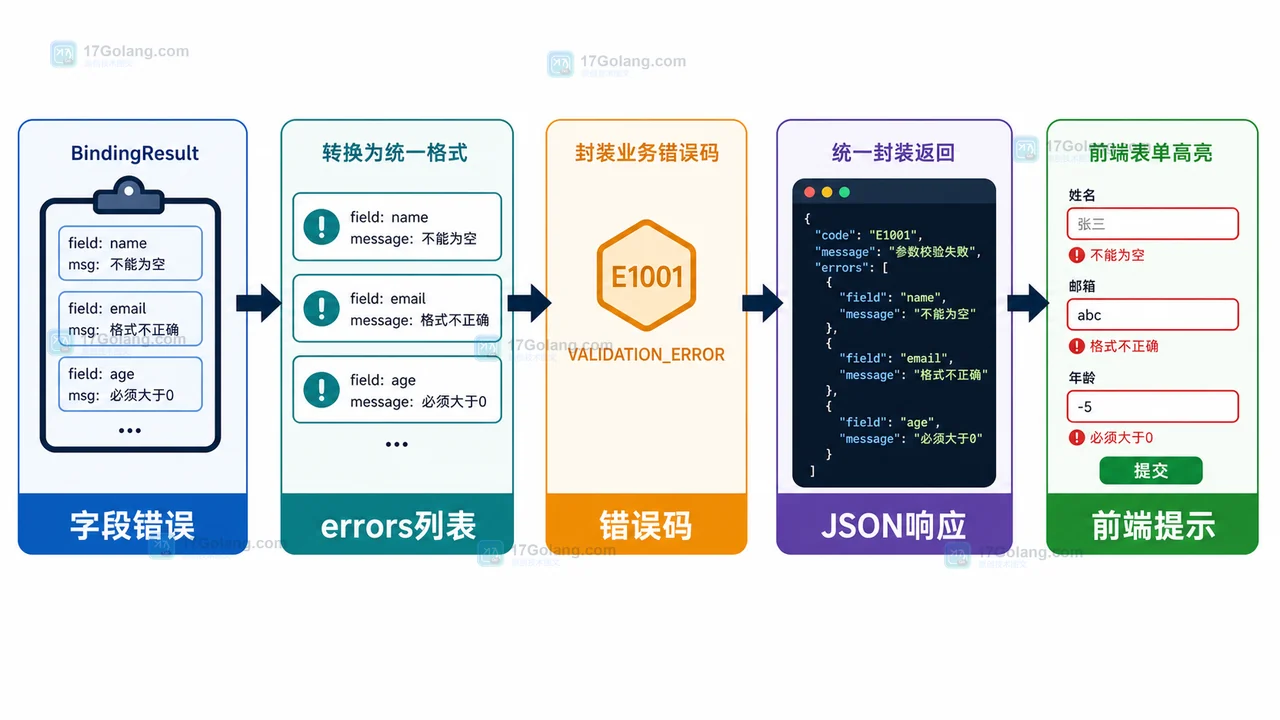
- 文章 · java教程 | 1天前 | Java · Spring Boot · 后端开发 · 接口校验 · java spring boot dto 接口设计 参数校验
- Spring Boot 参数校验工作流:DTO、注解和统一错误响应
- 495浏览 收藏
-
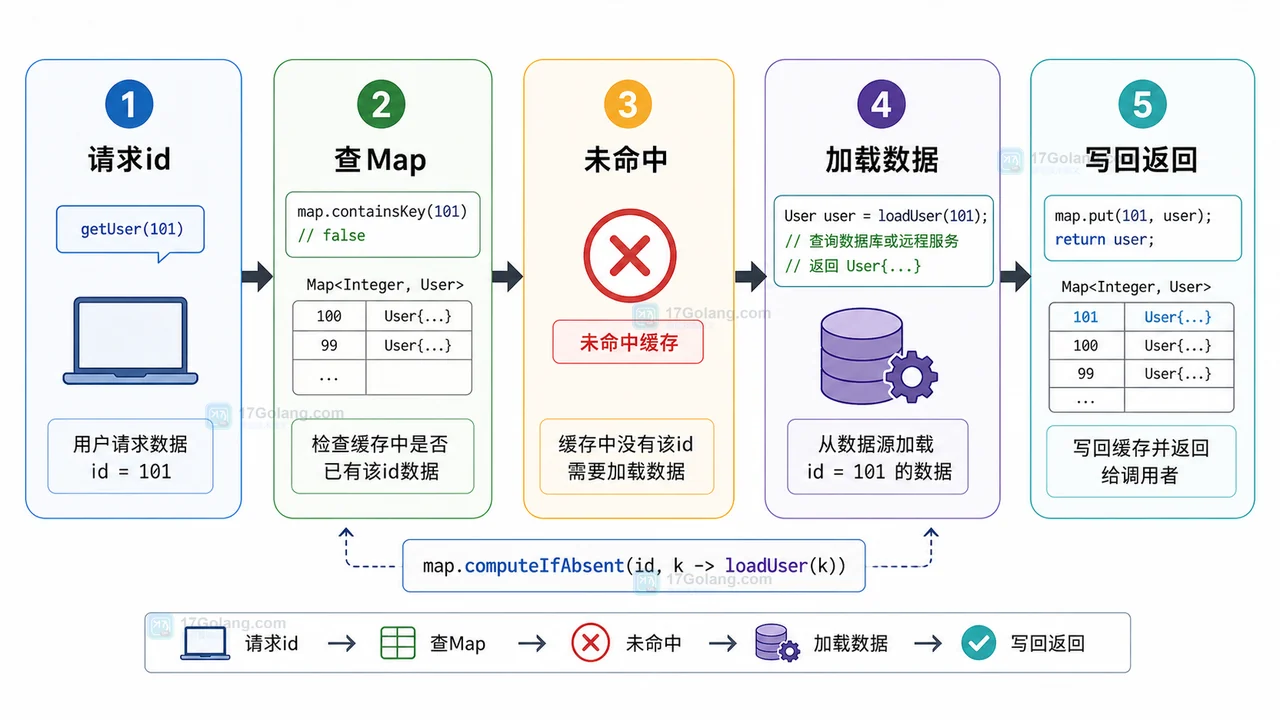
- 文章 · java教程 | 1星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-
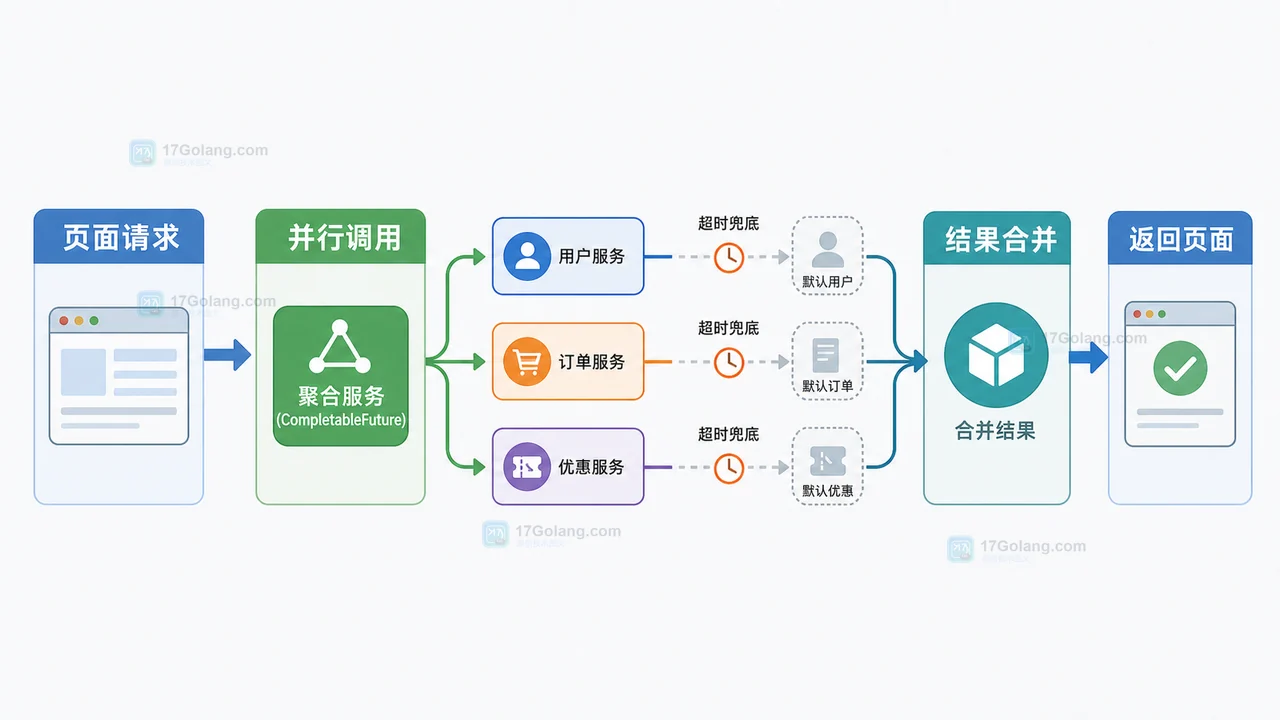
- 文章 · java教程 | 1星期前 | Java · 异步编程 · 后端开发 · CompletableFuture · 接口聚合 · java 结果合并 completablefuture 并行调用 超时兜底
- Java CompletableFuture 多接口聚合完整流程:并行调用、超时兜底和结果合并
- 428浏览 收藏
-
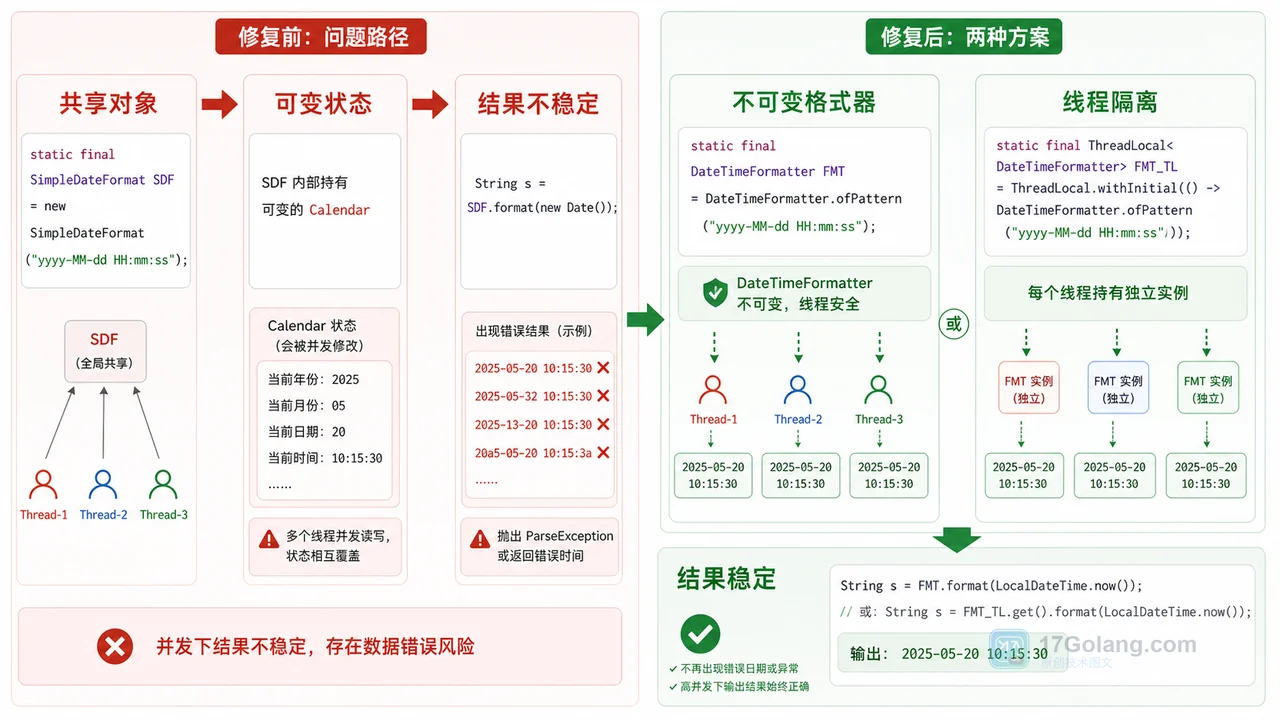
- 文章 · java教程 | 2星期前 | Java · 线程安全 · DateTimeFormatter · 日期处理 · 并发问题 · java 线程安全 日期格式化 threadlocal SimpleDateFormat DateTimeFormatter
- Java SimpleDateFormat 日期偶发错乱怎么办:从共享实例到线程安全一步步排查
- 481浏览 收藏
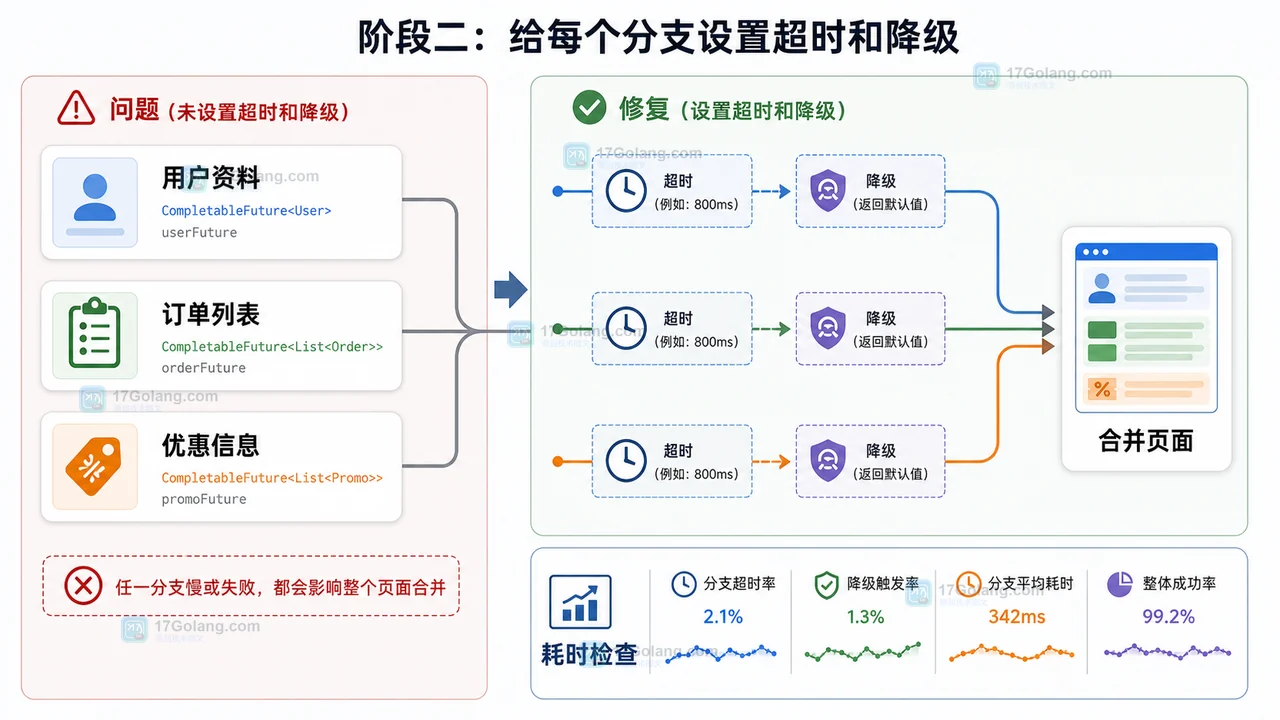
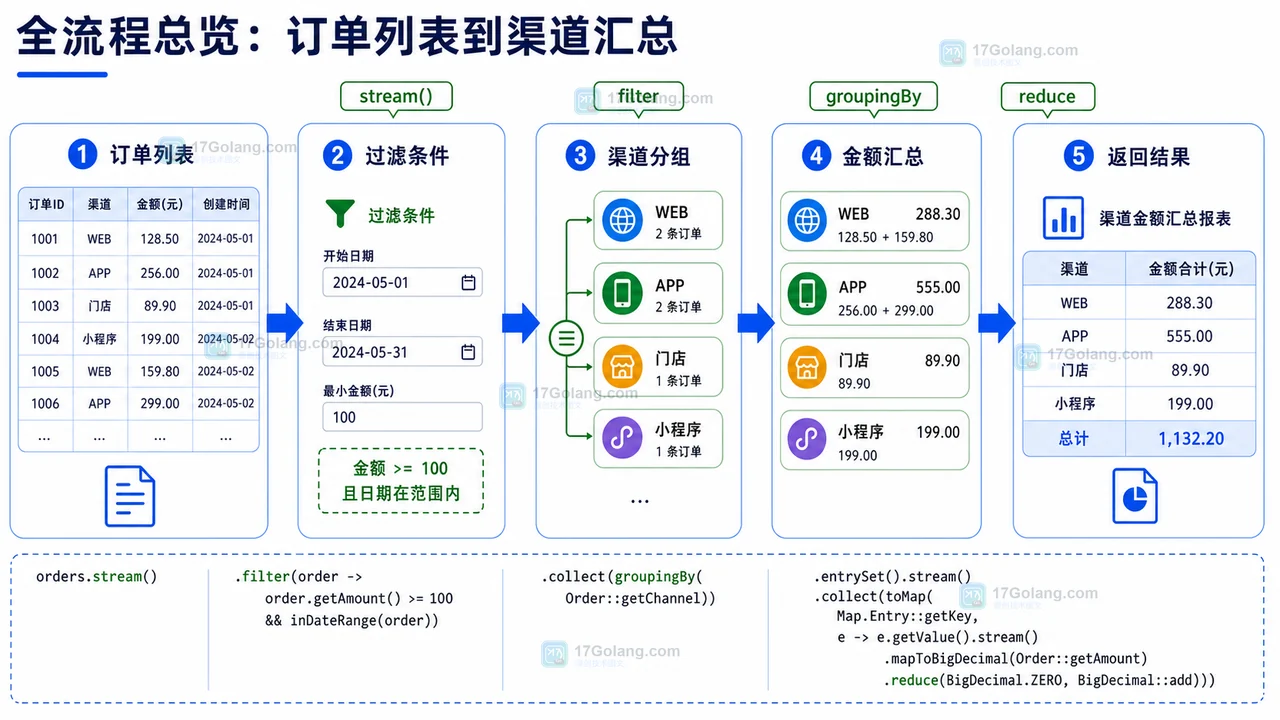
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2772次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2565次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2509次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2742次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2688次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


