msyql笔记 - 子查询
你在学习数据库相关的知识吗?本文《msyql笔记 - 子查询》,主要介绍的内容就涉及到MySQL,如果你想提升自己的开发能力,就不要错过这篇文章,大家要知道编程理论基础和实战操作都是不可或缺的哦!
msyql笔记 - 子查询
子查询比较好理解
子查询是比较容易出问题的写法
5.6以前子查询的性能不好
子查询的写法,通常来说只会用IN子查询,ANY,SOME,ALL几乎不用,只在某些场景下会用
operand comparison_operator ANY (subquery) operand IN (subquery) operand comparison_operator SOME (subquery) operand comparison_operator ALL (subquery)
子查询的使用
ANY关键词的意思是“对于在子查询返回的列中的任一数值,如果比较结果为TRUE的话,则返回TRUE
select s1 from t1 where s1 > any (select s1 from t2); SOME = ANY IN equals = ANY select s1 from t1 where s1 = any (select s1 from t2);
使用子查询和内连join的一些区别
insert into b select 2; select x from a where x in (select y from b); select x from a,b where a.x = b.y;
IN语句在取出数据之后会对取出的数据进行一次去重(1,2,2) ->(1,2),然后会判断是不是在(1,2)里而不会问是不是在(1,2,2)里,所以要看b中的y是不是唯一的,如果是唯一的用join问题不大,如果不是唯一的就会出现问题

select x from a where x in (select y from b); +------+ | x | +------+ | 1 | | 2 | +------+ select x from a,b where a.x = b.y; +------+ | x | +------+ | 1 | | 2 | +------+ insert into b select 2; Query OK, 1 row affected (0.05 sec) Records: 1 Duplicates: 0 Warnings: 0 select x from a where x in (select y from b); +------+ | x | +------+ | 1 | | 2 | +------+ select x from a,b where a.x = b.y; +------+ | x | +------+ | 1 | | 2 | | 2 | +------+
使用派生表解决这个join的问题,先通过一个子查询的结果产生派生表c,其中使用distinct关键词进行去重,最后再join
select * from a,(select distinct y from b) c where a.x = c.y; insert into b select NULL; select * from a where a.x not in (select y from b); Empty set (0.00 sec) -- b中插入null值的时候,a表中3这个结果没有了 delete from b where y is NULL; select * from a where a.x not in (select y from b); +------+ | x | +------+ | 3 | +------+ select a.x from a left join (select distinct y from b) c on a.x = c.y where c.y is null; -- 取出在a表中但是不在b表中的值,哪怕此时b表中包含了1,2,2,NULL这样的值 +------+ | x | +------+ | 3 | +------+ select * from a where a.x not in (select y from b where y is not null); +------+ | x | +------+ | 3 | +------+
所以在建表的时候默认值为null的话可能会有一些潜在的坑,比如
select 3 not in (1,2,2,NULL); -- 返回NULL值,也就是上面的not in语句为什么不返回数据的原因 select 3 not in (1,2,3); -- 返回1也就是TRUE
EXISTS谓词
仅返回TRUE, FALSE
UNKNOWN返回FALSE
不会返回NULL值,not in则返回0和NULL值
SELECT customerid, companyname
FROM customers AS A
WHERE country = 'Spain'
AND EXISTS
(SELECT * FROM orders AS B
WHERE A.customerid = B.customerid)
EXISTS => IN 写法
SELECT customerid, companyname FROM customers AS A WHERE country = 'Spain' AND customerid IN (SELECT customerid FROM orders); select * from a where a.x in (select y from b); => select * from a where exists (select * from b where a.x = b.y); +------+ | x | +------+ | 1 | | 2 | +------+
子查询最大的一个优势是易于理解,另外需要理解的一个重点
select * from a where exists (select 1 from b where a.x = b.y); select * from a where exists (select NULL from b where a.x = b.y); 返回的结果集还是一样的 +------+ | x | +------+ | 1 | | 2 | +------+
因为exists表示的是这条语句取出来有没有结果,但是这个结果值是1还是有多个列组成还是这个结果只是返回一个NULL值都没有关系,都表示的是返回了一行记录,表示的是有没有一行记录返回,因为如果这个条件不匹配的话是任何一条记录也不返回的。哪怕是null也会返回一行null的结果集,所以使用null也是成立的,主要是根据判断条件来进行判断,结果集只要有就可以了,另外exists里的语句依旧不推荐使用select *
NOT EXISTS
NOT EXISTS 同样也只返回0和1
select * from b; +------+ | y | +------+ | 1 | | 2 | | 2 | | NULL | +------+ select * from a where a.x not in (select y from b); Empty set (0.01 sec) select * from a where not exists (select * from b where a.x = b.y); +------+ | x | +------+ | 3 | +------+
in和exists,not in和not exists基本上是一样的,但是带了NULL值后就不一样了,这是两者之间的差别

IN EXISTS 性能比较
5.6版本之前mysql对in子查询的优化是不完善的,所有的in会被优化重写成exists,这种查询重写效果是不好的
SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2); SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
子查询的优化,这里IN和EXISTS的性能差距是很大的
-- 每月最后实际订单日期发生的订单
SELECT
*
FROM
dbt3.orders
WHERE
o_orderdate IN (SELECT
MAX(o_orderdate)
FROM
dbt3.orders b
GROUP BY (DATE_FORMAT(o_orderdate, '%Y%M')));
-- 这里IN的GROUP BY只执行一次
-- EXISTS写法
SELECT
*
FROM
dbt3.orders a
WHERE
EXISTS( SELECT
MAX(o_orderdate)
FROM
dbt3.orders b
GROUP BY (DATE_FORMAT(o_orderdate, '%Y%M'))
HAVING MAX(o_orderdate) = a.o_orderdate);
-- 这里EXISTS的GROUP BY会执行很多次,这里的问题在于group by要执行太多次,如果有10w行记录,group by也要执行10万次,也就是100w次的数据扫描。因为后面这条exists是相关子查询,每一次执行子查询都需要跟外表中的数据去关联。
-- 派生表的IN写法
SELECT
*
FROM
dbt3.orders a,
(SELECT
MAX(o_orderdate) o_orderdate
FROM
dbt3.orders
GROUP BY (DATE_FORMAT(o_orderdate, '%Y%M'))) b
WHERE
a.o_orderdate = b.o_orderdate;
所以这里IN的性能是要比EXISTS高很多的
一些例子
求出当前employees当前员工的级别、然后titles、目前的薪资
SELECT
CONCAT(e.first_name, , e.last_name) AS name,
d.dept_name,
s.salary,
t.title
FROM
employees e
LEFT JOIN
dept_manager dm ON e.emp_no = dm.emp_no
INNER JOIN
dept_emp de ON e.emp_no = de.emp_no
INNER JOIN
departments d ON d.dept_no = de.dept_no
INNER JOIN
salaries s ON s.emp_no = e.emp_no
INNER JOIN
titles t ON e.emp_no = t.emp_no
WHERE
dm.emp_no IS NULL;
-- 这样是不正确的,因为salaries表中的数据是历史数据,每次薪资变动都会有一条记录,不同的时间区间会有不同的salary,所以产生了一对多的关系;同样的departments中的dept_name也有同样的问题
取出当前员工最大的to_date
SELECT
emp_no, title
FROM
titles
WHERE
(emp_no , to_date) IN (SELECT
emp_no, MAX(to_date)
FROM
titles
GROUP BY emp_no,to_date)
ORDER BY emp_no
LIMIT 10;
+--------+--------------------+
| emp_no | title |
+--------+--------------------+
| 10013 | Senior Staff |
| 10048 | Engineer |
| 10064 | Staff |
| 10070 | Technique Leader |
| 10363 | Assistant Engineer |
| 10364 | Senior Engineer |
| 10372 | Technique Leader |
| 10426 | Technique Leader |
| 10469 | Senior Engineer |
| 10632 | Technique Leader |
+--------+--------------------+
SELECT
emp_no, salary
FROM
salaries
WHERE
(emp_no , to_date) IN (SELECT
emp_no, MAX(to_date)
FROM
salaries
GROUP BY emp_no)
LIMIT 10;
+--------+--------+
| emp_no | salary |
+--------+--------+
| 13049 | 60266 |
| 14688 | 42041 |
| 15509 | 43807 |
| 16012 | 76142 |
| 18061 | 57737 |
| 20869 | 40000 |
| 21610 | 81589 |
| 24040 | 40000 |
| 24673 | 49838 |
| 24861 | 68066 |
+--------+--------+
完结版
SELECT
e.emp_no,
CONCAT(last_name, ' ', first_name) AS name,
t.title,
dp.dept_name,
s.salary
FROM
employees e
LEFT JOIN
dept_manager d ON e.emp_no = d.emp_no
LEFT JOIN
(SELECT
emp_no, title
FROM
titles
WHERE
(emp_no , to_date) IN (SELECT
emp_no, MAX(to_date)
FROM
titles
GROUP BY emp_no)) t ON t.emp_no = e.emp_no
LEFT JOIN
(SELECT
dept_no, emp_no, MAX(to_date)
FROM
dept_emp
GROUP BY emp_no) de ON de.emp_no = e.emp_no
LEFT JOIN
(SELECT
emp_no, salary
FROM
salaries
WHERE
(emp_no , to_date) IN (SELECT
emp_no, MAX(to_date)
FROM
salaries
GROUP BY emp_no)) s ON s.emp_no = e.emp_no
LEFT JOIN
departments dp ON dp.dept_no = de.dept_no
WHERE
d.emp_no IS NULL;
总结
IN和EXISTS,IN改写成join可能要去重
IN可能会返回NULL值
EXISTS只会返回true和false
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于数据库的相关知识,也可关注golang学习网公众号。
 mysql笔记 - SELECT 语句
mysql笔记 - SELECT 语句
- 上一篇
- mysql笔记 - SELECT 语句

- 下一篇
- MySQL 存储过程中的错误处理
-

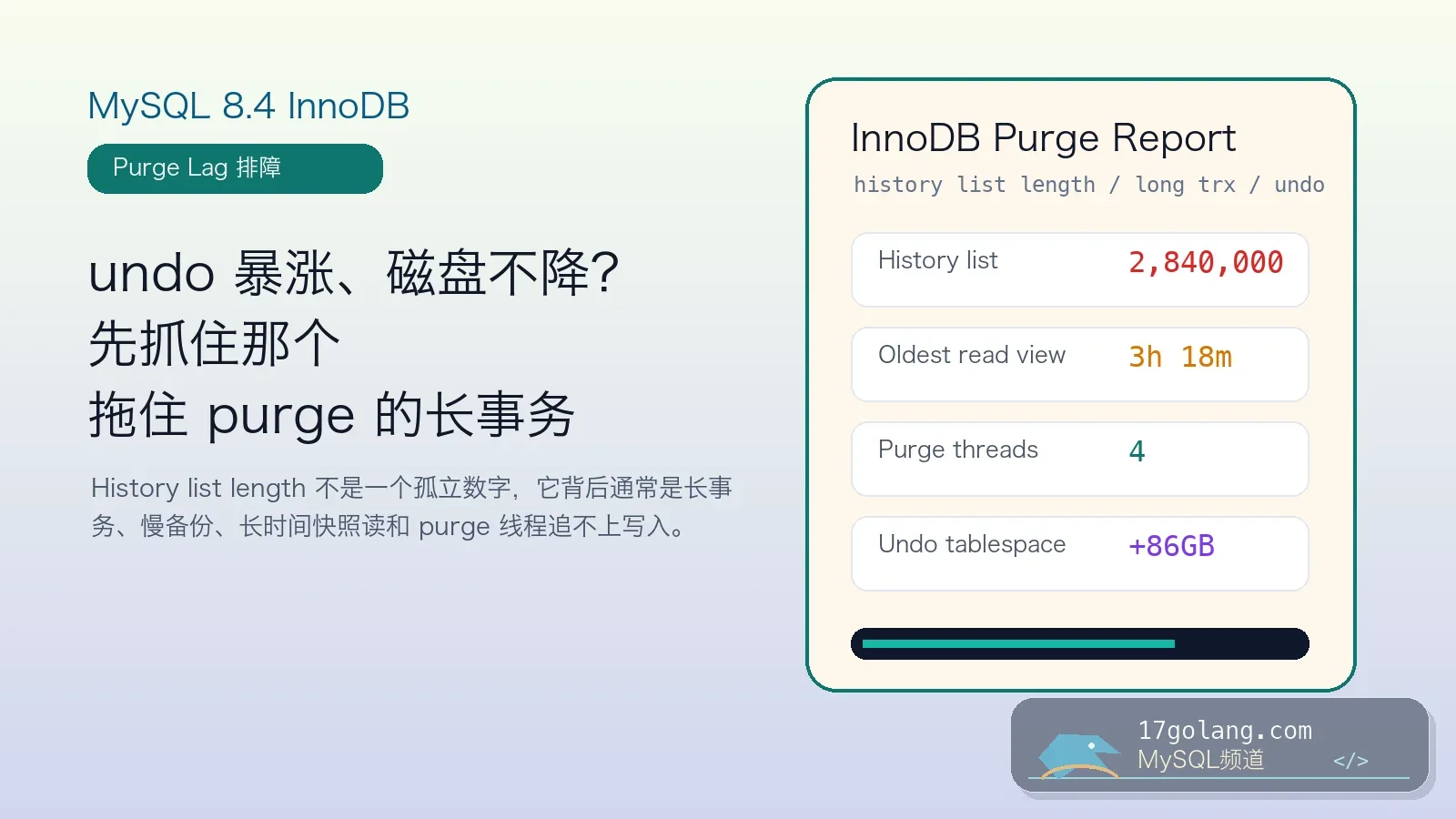
- 数据库 · MySQL | 1天前 | 性能优化 · 高并发 · InnoDB · MySQL教程 · 数据库运维 · mysql innodb AUTO_INCREMENT 高并发写入 innodb_autoinc_lock_mode
- MySQL 8.4 自增主键并发写入实战:AUTO_INCREMENT 锁模式别再凭感觉调
- 254浏览 收藏
-

- 数据库 · MySQL | 1天前 | 连接池 · 高并发 · 故障排查 · MySQL教程 · 数据库运维 · mysql 高并发 连接池 max_connections Too many connections
- MySQL 8.4 连接池雪崩实战:Too many connections 不是把 max_connections 调大就完事
- 491浏览 收藏





-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 6464次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6877次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6673次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8626次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 7315次使用
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- 搞一个自娱自乐的博客(二) 架构搭建
- 2023-02-16 244浏览
-
- B-Tree、B+Tree以及B-link Tree
- 2023-01-19 235浏览
-
- mysql面试题
- 2023-01-17 157浏览
-
- MySQL数据表简单查询
- 2023-01-10 101浏览


