Python爬虫必备:基础到进阶全攻略
要成为Python爬虫高手,你需要掌握一系列关键技能和知识。首先,Python基础是不可或缺的,包括基本语法、数据结构和文件操作。其次,网络知识如HTTP协议、HTML和CSS是爬虫的核心。接着,数据解析技能必不可少,使用BeautifulSoup和lxml等库可以从网页中提取有用信息。此外,多线程和异步编程能显著提升爬虫效率,而反爬虫策略如User-Agent伪装、IP轮换和请求频率控制则能帮助你避开网站的防护措施。最后,数据存储和处理也是关键,熟练使用SQL和NoSQL数据库,并进行数据清洗和分析,才能从爬取的数据中挖掘出价值。
要成为Python爬虫高手,你需要掌握以下关键技能和知识:1. Python基础,包括基本语法、数据结构、文件操作;2. 网络知识,如HTTP协议、HTML、CSS;3. 数据解析,使用BeautifulSoup、lxml等库;4. 多线程和异步编程提升效率;5. 反爬虫策略,如User-Agent伪装、IP轮换、请求频率控制;6. 数据存储和处理,使用SQL、NoSQL数据库,并进行数据清洗和分析。

要成为一个Python爬虫高手,你需要掌握的知识可不仅仅是简单的代码敲敲。你得像探险家一样,准备好面对各种挑战和惊喜。下面就让我们来探讨一下,你需要掌握的那些关键技能和知识。
首先,Python基础是你的出发点。没有坚实的基础,你的爬虫之旅会寸步难行。你需要了解Python的基本语法、数据结构、文件操作等。别小看这些基础知识,它们是你构建复杂爬虫程序的基石。
再来说说网络知识,这可是爬虫的核心。HTTP协议、HTML、CSS,这些都是你必须熟练掌握的。想象一下,你的爬虫就像一个小侦探,需要在网络的迷宫中找到线索。了解这些协议和语言,就好比掌握了侦探的基本工具。
接着,数据解析是另一项必备技能。你需要知道如何从网页中提取有用信息。BeautifulSoup、lxml这些库是你最好的帮手。它们就像是你的数据挖掘工具,能够帮你从杂乱无章的网页中找到宝藏。
当然,爬虫的生命力在于它的自动化和效率。你得学会使用多线程、异步编程来提升爬虫的速度。试想一下,如果你的爬虫只能慢吞吞地爬行,那它可就落伍了。多线程和异步编程就像是给你的爬虫装上了火箭引擎,让它飞速前进。
还有一个不能忽视的方面是反爬虫机制。网站可不是傻瓜,它们会设置各种陷阱来阻止你的爬虫。你需要了解User-Agent伪装、IP轮换、请求频率控制等反爬虫策略。就像是打游击战,你得学会如何巧妙地避开敌人的视线。
最后,别忘了数据存储和处理。你爬取的数据需要一个家。SQL、NoSQL数据库是你可以选择的仓库。同时,你还需要学会如何对数据进行清洗和分析,这样才能从中挖掘出有价值的信息。
现在,让我们来看一个简单的爬虫示例,用来展示这些知识的应用:
import requests
from bs4 import BeautifulSoup
import time
import random
# 定义User-Agent列表,用于伪装请求
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
]
def get_html(url):
# 随机选择User-Agent
headers = {'User-Agent': random.choice(user_agents)}
# 发送请求
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
return response.text
else:
return None
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
# 提取你需要的数据,这里假设我们要提取所有的标题
titles = soup.find_all('h2')
return [title.text for title in titles]
def main():
url = 'https://example.com' # 替换为你要爬取的网址
html = get_html(url)
if html:
data = parse_html(html)
for title in data:
print(title)
# 控制请求频率,避免被反爬虫机制检测到
time.sleep(random.uniform(1, 3))
else:
print('Failed to retrieve the webpage.')
if __name__ == '__main__':
main()这个示例展示了如何使用requests库发送HTTP请求,BeautifulSoup解析HTML,以及如何通过User-Agent伪装和控制请求频率来应对反爬虫机制。
在实际应用中,你可能会遇到各种各样的问题。比如,某些网站可能会使用JavaScript动态加载内容,这时你就需要学习Selenium或Scrapy等更高级的工具。还有,爬虫的法律和道德问题也是你必须考虑的。确保你的爬虫行为符合法律法规,并且尊重网站的robots.txt文件。
总之,Python爬虫是一项充满挑战和乐趣的技能。只要你不断学习和实践,相信你一定能成为一名出色的爬虫高手。
今天关于《Python爬虫必备:基础到进阶全攻略》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
 Python手动添加环境变量配置详解
Python手动添加环境变量配置详解
- 上一篇
- Python手动添加环境变量配置详解

- 下一篇
- JavaScript轻松修改元素样式技巧
-
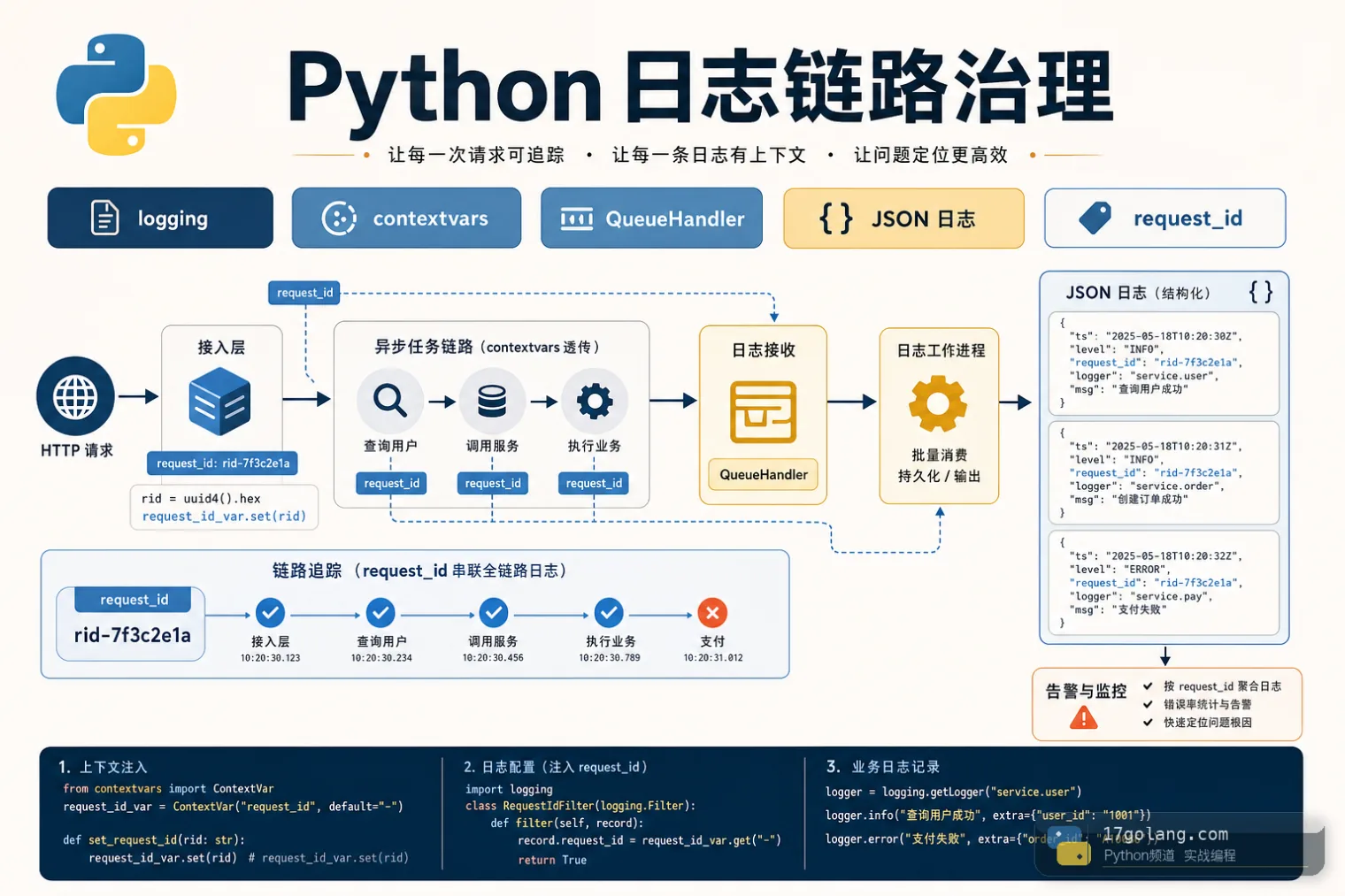
- 文章 · python教程 | 3天前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志
- Python logging 实战:用 contextvars 把 request_id 串到底
- 427浏览 收藏
-
- 文章 · python教程 | 6天前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志
- Python 日志实战:别让 request_id 在异步任务里丢了
- 189浏览 收藏
-
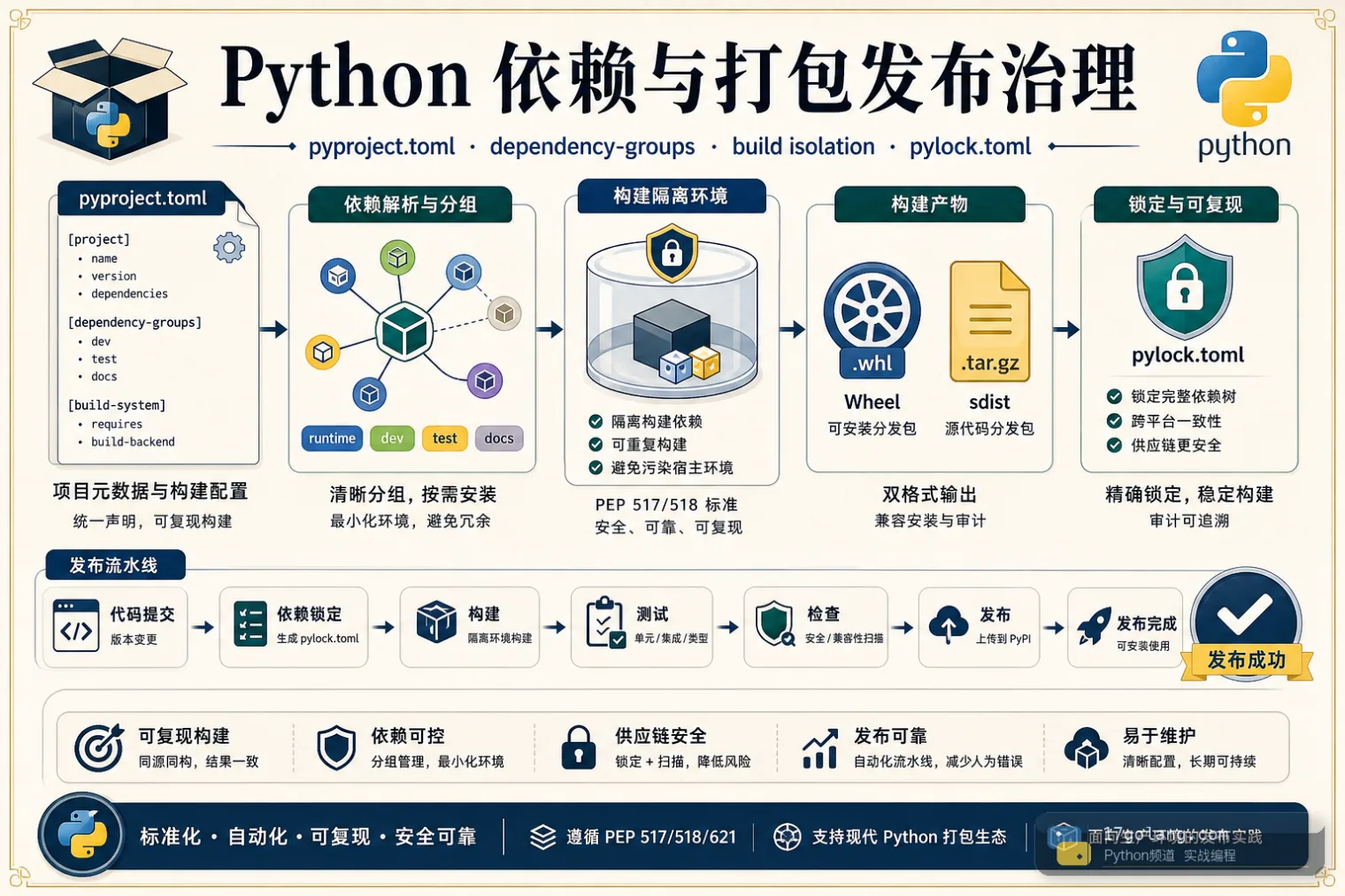
- 文章 · python教程 | 1星期前 | 依赖管理 · 工程化 · CI · 生产实践 · Python教程 · 打包发布 · Python build 依赖管理 twine wheel 打包发布 pyproject.toml dependency-groups pylock.toml sdist
- Python 打包发布实战:别把运行依赖和开发依赖混在一起
- 479浏览 收藏
-

- 文章 · python教程 | 1星期前 | sqlalchemy · 异步编程 · fastapi · 生产实践 · Python教程 · Python 连接池 FastAPI sqlalchemy asyncio AsyncSession
- Python SQLAlchemy AsyncSession 实战:别在并发任务里共享 Session
- 340浏览 收藏
-

- 文章 · python教程 | 1星期前 | 性能优化 · fastapi · 生产实践 · Python教程 · Pydantic · Python 性能优化 FastAPI Pydantic v2 TypeAdapter validate_json
- Python Pydantic v2 实战:TypeAdapter 别在请求里反复造
- 342浏览 收藏




-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7581次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8013次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 7816次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 9755次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8565次使用
-
- Flask框架安装技巧:让你的开发更高效
- 2024-01-03 501浏览
-
- Django框架中的并发处理技巧
- 2024-01-22 501浏览
-
- 提升Python包下载速度的方法——正确配置pip的国内源
- 2024-01-17 501浏览
-
- Python与C++:哪个编程语言更适合初学者?
- 2024-03-25 501浏览
-
- 品牌建设技巧
- 2024-04-06 501浏览


