MySQL乱码的原因和设置UTF8数据格式
来源:SegmentFault
2023-02-20 21:11:22
0浏览
收藏
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《MySQL乱码的原因和设置UTF8数据格式》,聊聊MySQL、unicode、字符集、utf-8、字符序,我们一起来看看吧!
MySQL使用时,有一件很痛苦的事情肯定是结果乱码。将编码格式都设置为UTF8可以解决这个问题,我们今天来说下为什么要这么设置,以及怎么设置。
MySQL字符格式
字符集
在编程语言中,我们为了防止中文乱码,会使用
unicode对中文字符做处理,而为了降低网络带宽和节省存储空间,我们使用UTF8进行编码。对这两者有什么不同不够了解的同学,可以参考Unicode字符集和UTF8编码编码的前世今生这篇文章。
同样在MySQL中,我们也会有这样的处理,我们可以查看当前数据库设置的编码方式(字符集):
mysql> show variables like '%char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/mysql/share/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.00 sec)
表中就是当前设置的字符集,先看不用关注的几个值:
-
character_set_filesystem | binary:
文件系统上的存储格式,默认为binary
(二进制) -
character_set_system | utf8:
系统的存储格式,默认为utf8
-
character_sets_dir | /usr/local/mysql/share/charsets/:
可以使用的字符集的文件路径
剩下的几个就是日常影响读写乱码的参数了:
- character_set_client:客户端请求数据的字符集
- character_set_connection:从客户端接收到数据,然后传输的字符集
- character_set_database:默认数据库的字符集;如果没有默认数据库,使用
character_set_server字段
- character_set_results:结果集的字符集
- character_set_server:数据库服务器的默认字符集

字符集的转换流程分为
3步:
- 客户端请求数据库数据,发送的数据使用
character_set_client
字符集 -
MySQL
实例收到客户端发送的数据后,将其转换为character_set_connection
字符集 -
进行内部操作时,将数据字符集转换为内部操作字符集:
- 使用每个数据字段的
character set
设定值 - 若不存在,使用对应数据表的
default character set
设定值 - 若不存在,使用对应数据库的
default character set
设定值 - 若不存在,使用
character_set_server
设定值
- 使用每个数据字段的
- 将操作结果值从内部操作字符集转换为
character_set_results
字符序
说字符序之前,我们需要了解一点基础知识:
- 字符
(Character)
是指人类语言中最小的表义符号。例如’A’、’B’
等; - 给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码
(Encoding)
。例如,我们给字符’A’
赋予数值0
,给字符’B’
赋予数值1
,则0
就是字符’A’
的编码; - 给定一系列字符并赋予对应的编码后,所有这些字符和编码对组成的集合就是字符集
(Character Set)
。例如,给定字符列表为{‘A’,’B’}时,{‘A’=>0, ‘B’=>1}就是一个字符集; - 字符序
(Collation)
是指在同一字符集内字符之间的比较规则; - 确定字符序后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系;
- 每个字符序唯一对应一种字符集,但一个字符集可以对应多种字符序,其中有一个是默认字符序
(Default Collation)
; -
MySQL
中的字符序名称遵从命名惯例:以字符序对应的字符集名称开头;以_ci
(表示大小写不敏感,case insensitive
)、_cs
(表示大小写敏感,case sensitive
)或_bin
(表示按编码值比较,binary
)结尾。例如:在字符序“utf8_general_ci”
下,字符“a”
和“A”
是等价的;
因此字符序不同于字符集,用于数据库字段的相等或大小比较。我们查看
MySQL实例设置的字符序:
mysql> show variables like 'collation%'; +----------------------+-------------------+ | Variable_name | Value | +----------------------+-------------------+ | collation_connection | latin1_swedish_ci | | collation_database | latin1_swedish_ci | | collation_server | latin1_swedish_ci | +----------------------+-------------------+ 3 rows in set (0.00 sec)
跟utf8对应的常用字符序是:
utf8_unicode_ci/utf8_general_ci和utf8_bin等,那么他们的区别是什么呢?
-
_bin
是用二进制存储并比较,区别大小写,存储二进制内容时使用 -
utf8_general_ci
:校对速度快,但准确度稍差,使用中英文时使用 -
utf8_unicode_ci
:准确度高,但校对速度稍慢,使用德法俄等外语时使用
详细的区别可以参考 Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结。
修改字符集和字符序
如果在
MySQL连接时,出现了乱码的问题,那么基本可以确定是各个字符集/序设置不统一的原因。
MySQL默认的
latin1格式不支持中文,由于我们在中国,所以选择对中文和各语言支持都非常完善的
utf8格式。所以,我们需要将需要关注的字符集和字符序都修改为
utf8格式。
你也可以选择
utf8mb4格式,这个格式支持保存
emoji?表情。
我们需要修改Mysql的配置文件,查看配置文件的位置有两种方式:
1. $ mysql --help | grep 'my.cnf' /etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf 2. ps aux | grep mysql
在
(1)中,
/etc/my.cnf, /etc/mysql/my.cnf, ~/.my.cnf这些就是mysql默认会搜寻my.cnf的目录,优先级依次升高。可以在各个配置文件里都使用
long_query_time来测试一下。
然后,我们修改或新增下面的配置项:
# 下面注释的几行可以不设置,但如果你的没有生效,也可以试试看 [mysqld] character_set_server=utf8 collation-server=utf8_general_ci skip-character-set-client-handshake #init_connect='SET NAMES utf8' #[client] #default-character-set=utf8
这三行配置就可以解决问题,最关键的是最后一行,参考mysql文档,使用该参数会忽略客户端传递的字符集信息,而直接使用服务端的设定;再加上我们设定服务端的字符集和字符序均为
utf8,这样就保证了字符格式的统一,解决乱码的问题。
重启
mysql服务,如果提示找不到服务,请参考用service命令管理mysql启停:
$ service mysqld restart Shutting down MySQL.. [ OK ] Starting MySQL. [ OK ]
连接到
mysql,查看当前编码:
mysql> show variables like '%char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/local/mysql/share/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.01 sec) mysql> show variables like 'collation%'; +----------------------+-----------------+ | Variable_name | Value | +----------------------+-----------------+ | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8_general_ci | +----------------------+-----------------+ 3 rows in set (0.01 sec)
可以看到一切都符合预期,请求和存储的数据也不再是乱码了。
遇到的问题
unknown variable 'default-character-set=utf8'
参考官方文档,该参数自
5.5.3版本废弃,改为了
character-set-server,改为这个参数即可。
但这个是在
[mysqld]下的配置,在
[client]下的配置依然使用
default-character-set参数。
参考资料
- MySQL连接校对:utf8_general_ci与utf8_unicode_ci有什么区别呢 :https://segmentfault.com/q/10...
- Unicode 和 UTF-8 有什么区别?:https://www.zhihu.com/questio...
- 深入Mysql字符集设置:http://www.laruence.com/2008/...
- 10.4 Connection Character Sets and Collations:https://dev.mysql.com/doc/ref...
- ISO/IEC 8859-1:https://zh.wikipedia.org/wiki...
- 5.1.6 Server Command Options:https://dev.mysql.com/doc/ref...
- 用service命令管理mysql启停:https://segmentfault.com/a/11...
- Unicode字符集和UTF8编码编码的前世今生:https://segmentfault.com/a/11...
- Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结:https://www.jb51.net/article/...
以上就是《MySQL乱码的原因和设置UTF8数据格式》的详细内容,更多关于mysql的资料请关注golang学习网公众号!
版本声明
本文转载于:SegmentFault 如有侵犯,请联系study_golang@163.com删除
 你能说说你理解的数据库规范吗?
你能说说你理解的数据库规范吗?
- 上一篇
- 你能说说你理解的数据库规范吗?

- 下一篇
- MySQL数据库的事务隔离和MVCC
评论列表
-

- 风中的画笔
- 这篇技术贴真及时,太全面了,太给力了,已加入收藏夹了,关注作者了!希望作者能多写数据库相关的文章。
- 2023-03-03 23:46:55
查看更多
最新文章
-

- 数据库 · MySQL | 18小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
- MySQL JSON 字段怎么给列表筛选提速:生成列、索引与 NULL 边界
- 351浏览 收藏
-
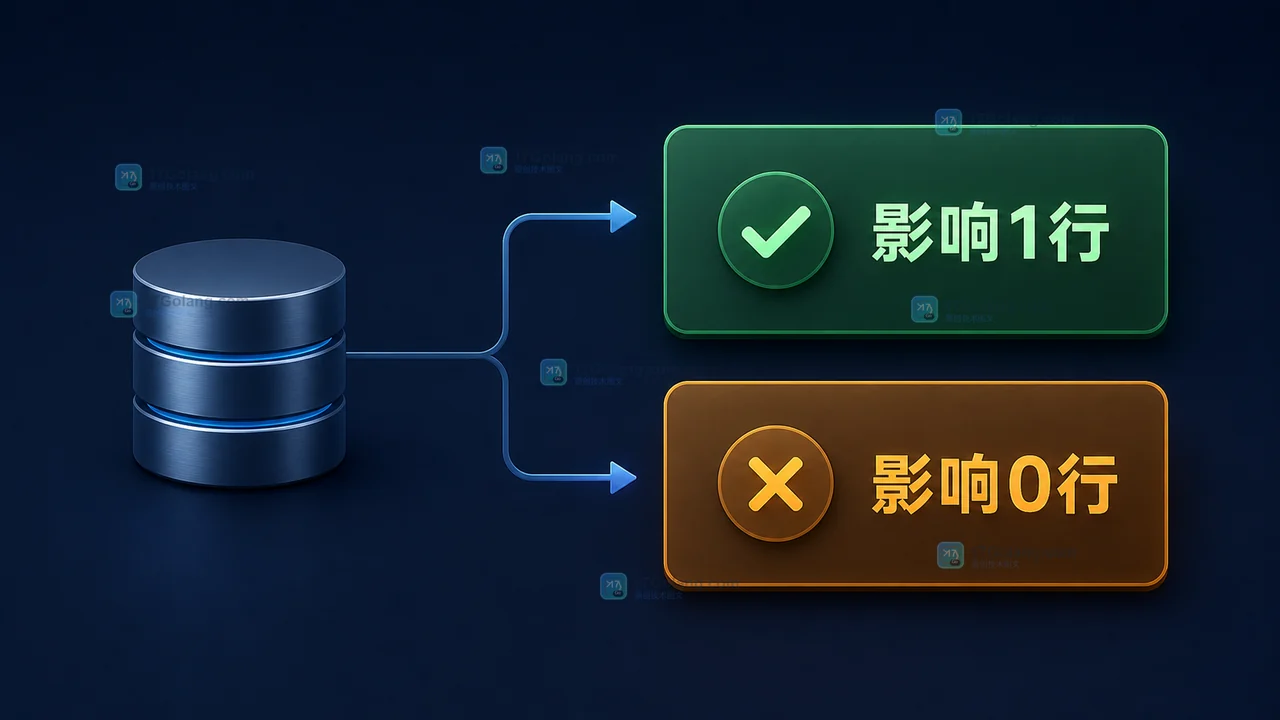
- 数据库 · MySQL | 5天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
- MySQL 库存怎么安全扣减?条件 UPDATE、防超卖和受影响行判断
- 470浏览 收藏



查看更多
课程推荐
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
查看更多
AI推荐
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4612次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4240次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4199次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4422次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4377次使用
查看更多
相关文章
-
- MySQL 明明加了索引,为什么查询还是很慢?先查这 6 个点
- 2026-06-27 374浏览
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- golang 基于 mysql 简单实现分布式读写锁
- 2023-01-07 384浏览
-
- 详解如何利用GORM实现MySQL事务
- 2023-01-07 184浏览
-
- Go语言实现操作MySQL的基础知识总结
- 2023-01-23 265浏览


