sqlalchemy 配置多连接读写库后的relationship设置
对于一个数据库开发者来说,牢固扎实的基础是十分重要的,golang学习网就来带大家一点点的掌握基础知识点。今天本篇文章带大家了解《sqlalchemy 配置多连接读写库后的relationship设置》,主要介绍了MySQL、python、tornado、flask,希望对大家的知识积累有所帮助,快点收藏起来吧,否则需要时就找不到了!
如果这样解决的话,也就不用看下面的配置了,下面是使用SQLALCHEMY_BINDS配置多个多个数据库并使用relationship.(个人建议最好不用relationship,很容易发生各种报错...)
# -*- coding:utf-8 -*-
__doc__ = "使用SQLALCHEMY_BINDS 就必须双份Model各自配置__bind_key__ ,同名库的读写分离与relationship配置的示例"
import flask
from flask_sqlalchemy import SQLAlchemy # Flask-SQLAlchemy 2.3.2
from datetime import datetime
from sqlalchemy.orm import backref, foreign # SQLAlchemy 1.3.1
db_name = 'db_name'
SQLALCHEMY_DATABASE_URL_READ = 'mysql://toto:toto123@111.111.111.111:3306/%s?charset=utf8' % db_name
SQLALCHEMY_DATABASE_URL_WRITE = 'mysql://toto1:toto123@222.222.222.222:3306/%s?charset=utf8' % db_name
app = flask.Flask(__name__)
app.config['DEBUG'] = True
app.config['SQLALCHEMY_BINDS'] = {
'read_db': SQLALCHEMY_DATABASE_URI_READ,
'write_db': SQLALCHEMY_DATABASE_URL_WRITE,
}
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
class RDriver(db.Model):
__bind_key__ = 'read_db'
__tablename__ = 'driver'
# __table_args__ = {'schema': db_name} # __tablename__ 相同的,读库写库至少有一个要加,此示例是读库都不加,写库必须加
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
fk_user_id = db.Column(db.Integer, db.ForeignKey("user.id"))
create_at = db.Column(db.TIMESTAMP, default=datetime.now)
class RUser(db.Model):
__bind_key__ = 'read_db'
__tablename__ = 'user'
# __table_args__ = {'schema': db_name}
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(32), index=True, unique=True)
email = db.Column(db.String(32))
create_time = db.Column(db.TIMESTAMP, default=datetime.now)
update_time = db.Column(db.TIMESTAMP, default=datetime.now)
# 如下的五种方式都是可以的
# driver_fk = db.relationship("RDriver", foreign_keys='RDriver.fk_user_id')
# driver_fk = db.relationship("RDriver", primaryjoin=lambda: RDriver.fk_user_id == RUser.id, viewonly=True)
# driver_fk = db.relationship("RDriver", primaryjoin=RDriver.fk_user_id == id)
fk_driver = db.relationship("RDriver", primaryjoin='RDriver.fk_user_id == RUser.id')
# driver_fk = db.relationship("RDriver", backref=db.backref('user', lazy=True),
# primaryjoin=lambda: RDriver.fk_user_id == RUser.id, viewonly=True)
####################################################上面为同名读库,下面为同名写库###########################################
class WDriver(db.Model):
__bind_key__ = 'write_db'
__tablename__ = 'driver'
__table_args__ = {'schema': db_name, 'extend_existing': True} # 这个配置很关键,同名写库都要配置
# __table_args__ = {'extend_existing': True}
# 这样配置的话会报错: sqlalchemy.exc.ArgumentError: Could not locate any relevant foreign
# key columns for primary join condition 'driver.fk_user_id = "user".id' on relationship RUser.fk_driver.
# Ensure that referencing columns are associated with a ForeignKey or ForeignKeyConstraint,
# or are annotated in the join condition with the foreign() annotation.
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
fk_user_id = db.Column(db.Integer, db.ForeignKey("%s.user.id" % db_name)) # db_name.user.id很关键,必须指定用的数据库名
create_at = db.Column(db.TIMESTAMP, default=datetime.now)
class WUser(db.Model):
__bind_key__ = 'write_db'
__tablename__ = 'user'
__table_args__ = {'schema': db_name, 'extend_existing': True} # 这个配置很关键,同名写库都要配置
# __table_args__ = {'extend_existing': True} # 这个配置很关键,同名写库都要配置
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(32), index=True, unique=True)
email = db.Column(db.String(32))
create_time = db.Column(db.TIMESTAMP, default=datetime.now)
update_time = db.Column(db.TIMESTAMP, default=datetime.now)
# 以下五种方式都是可以的
# fk_driver = db.relationship("WDriver", foreign_keys='WDriver.fk_user_id', uselist=False)
# fk_driver = db.relationship("WDriver", primaryjoin=lambda: WDriver.fk_user_id == WUser.id)
fk_driver = db.relationship("WDriver", primaryjoin=WDriver.fk_user_id == id)
# fk_driver = db.relationship("WDriver", primaryjoin='WDriver.fk_user_id == WUser.id')
# fk_driver = db.relationship("WDriver", backref=db.backref('test.user', lazy=True),
# primaryjoin=lambda: WDriver.fk_user_id == WUser.id)
r_user_obj = RUser.query.filter_by().first()
print("r_user_obj:", r_user_obj)
print("r_user_obj.driver_fk:", r_user_obj.fk_driver)
""" 打印出来的sql
SELECT user.id AS user_id, user.username AS user_username, user.email AS user_email, user.create_time AS user_create_time, user.update_time AS user_update_time
FROM user
LIMIT 1
SELECT driver.id AS driver_id, driver.fk_user_id AS driver_fk_user_id, driver.create_at AS driver_create_at
FROM driver
WHERE driver.fk_user_id = %s
"""
w_user_obj = WUser.query.filter_by(id=2188).first()
print("w_user_obj:", w_user_obj)
print("w_user_obj.driver_fk:", w_user_obj.fk_driver)
""" 打印出来的sql,可以看出多了数据库名
SELECT db_name.user.id AS db_name_user_id, db_name.user.username AS db_name_user_username, db_name.user.email AS db_name_user_email, db_name.user.create_time AS db_name_user_create_time, db_name.user.update_time AS db_name_user_update_time
FROM db_name.user
WHERE db_name.user.id = %s
LIMIT %s
SELECT db_name.driver.id AS db_name_driver_id, db_name.driver.fk_user_id AS db_name_driver_fk_user_id, db_name.driver.create_at AS db_name_driver_create_at
FROM db_name.driver
WHERE db_name.driver.fk_user_id = %s
"""
参考文档:
* https://docs.sqlalchemy.org/en/13/orm/relationship_api.html # 值得细看 * https://www.osgeo.cn/sqlalchemy/orm/relationship_api.html # 同上,中文 * https://www.cnblogs.com/srd945/p/9851227.html * extend_existing: (False)当表已经存在于元数据中时,如果元数据中存在与column_list中的列同名的列,column_list中同名的列会替换掉元数据中已经有的列 * useexisting已被废弃, 新版本使用extend_existing
总结
关系配置参数真的很多,如下,很容易就会出错,需要多读读官方文档,还有就是建立modle时候尽量简洁,风格统一,不要在数据库层建立外键.
sqlalchemy.orm.relationship(argument, secondary=None, primaryjoin=None, secondaryjoin=None, foreign_keys=None, uselist=None, order_by=False, backref=None, back_populates=None, post_update=False, cascade=False, extension=None, viewonly=False, lazy='select', collection_class=None, passive_deletes=False, passive_updates=True, remote_side=None, enable_typechecks=True, join_depth=None, comparator_factory=None, single_parent=False, innerjoin=False, distinct_target_key=None, doc=None, active_history=False, cascade_backrefs=True, load_on_pending=False, bake_queries=True, _local_remote_pairs=None, query_class=None, info=None, omit_join=None)
题外话
配置多连接数据库用户访问权限需要提前配置好,我就遇到个坑:
我连接了ip为111.111.111.111的数据库,使用mysql命令好都能很好的正常访问到数据,但是使用SQLALCHEMY_BINDS访问后就报错 :
OperationalError: (_mysql_exceptions.OperationalError) (1142, "SELECT command denied to user 'toto'@'125.121.34.123' for table 'user'") [SQL: u'SELECT test2.user.com_name AS test2_user_com_name, test2.user.com_no AS test2_user_com_no \nFROM test2.user \nWHERE test2.user.id = %s \n LIMIT %s'] [parameters: (3385, 1)]
其实还是自己没有检查清楚,toto用户我只给了test库的权限,而test2库的权限没给,才会造成这样的报错(125.121.34.123别被这个ip吸引了注意力,我上次遇到这样的问题是配置中SQLALCHEMY_DATABASE_URL的连接有点错误,导致前后看到的ip不一样,这次连接中的111.111.111.111和报错中的125.121.34.123不一样是因为ip不在同一网段,125.121.34.123就是111.111.111.111经过多段路由连接过来的后分配到的ip)
mysql toto@111.111.111.111:test> SELECT test2.user.username AS test_user_username, test2.user.id AS test_ship
pers_id FROM test2.user WHERE test2.user.id = 3385 LIMIT 1;
(1142, "SELECT command denied to user 'toto'@'125.121.34.123' for table 'user'")
mysql toto@111.111.111.111:test> SELECT test.user.username AS test_user_username, test.user.id AS
test_user_id FROM test.user WHERE test.user.id = 3385 LIMIT 1;
+--------------------------+-----------------------+
| test_user_username | test_user_id |
+--------------------------+-----------------------+
| XXXXXXX | 123 |
+--------------------------+-----------------------+本篇关于《sqlalchemy 配置多连接读写库后的relationship设置》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
 mysql5.7读书笔记7(查询SELECT)
mysql5.7读书笔记7(查询SELECT)
- 上一篇
- mysql5.7读书笔记7(查询SELECT)

- 下一篇
- PHP+MySQL导出大量数据(Iterator yield)
-

- 聪慧的麦片
- 细节满满,收藏了,感谢楼主的这篇技术贴,我会继续支持!
- 2023-03-20 18:03:37
-
- 等待的毛衣
- 这篇文章真是及时雨啊,细节满满,写的不错,已加入收藏夹了,关注up主了!希望up主能多写数据库相关的文章。
- 2023-03-16 11:13:16
-
- 土豪的小松鼠
- 这篇技术文章真及时,楼主加油!
- 2023-02-26 02:10:27
-
- 老实的吐司
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享技术贴!
- 2023-01-30 14:33:05
-

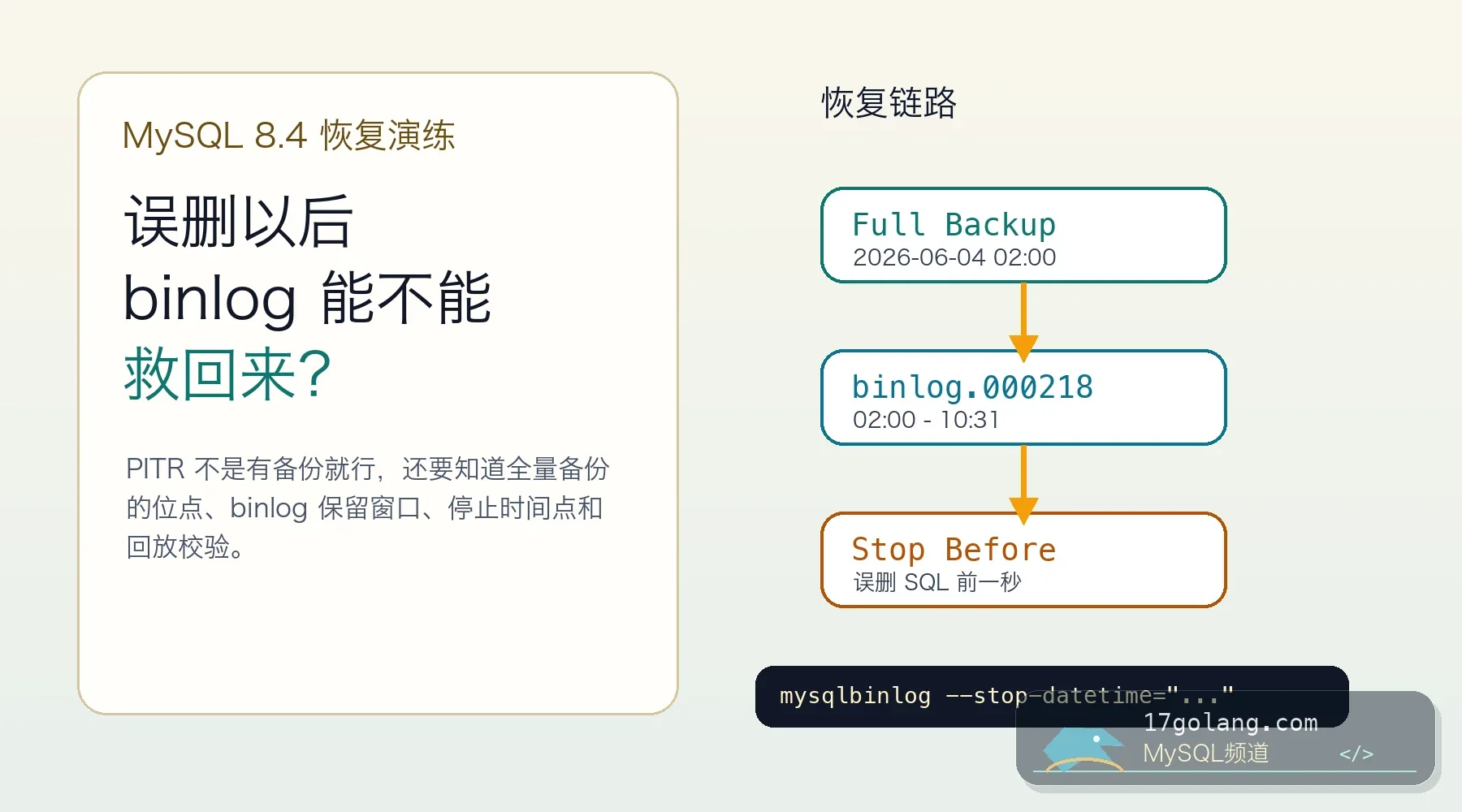
- 数据库 · MySQL | 1天前 | 性能优化 · 高并发 · InnoDB · MySQL教程 · 数据库运维 · mysql innodb AUTO_INCREMENT 高并发写入 innodb_autoinc_lock_mode
- MySQL 8.4 自增主键并发写入实战:AUTO_INCREMENT 锁模式别再凭感觉调
- 254浏览 收藏
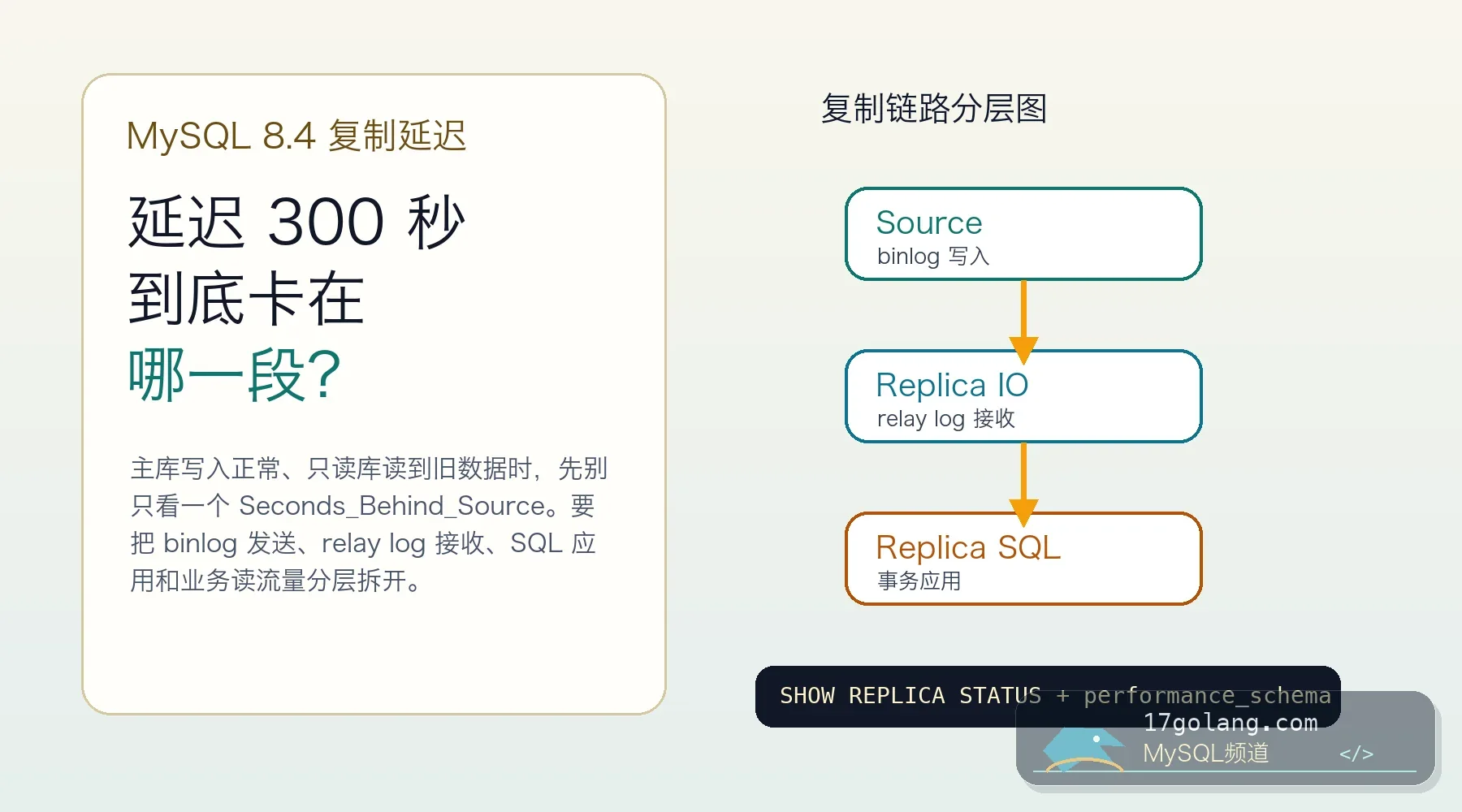
-

- 数据库 · MySQL | 1天前 | 连接池 · 高并发 · 故障排查 · MySQL教程 · 数据库运维 · mysql 高并发 连接池 max_connections Too many connections
- MySQL 8.4 连接池雪崩实战:Too many connections 不是把 max_connections 调大就完事
- 491浏览 收藏





-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 6356次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6773次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6570次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8522次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 7209次使用
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- 搞一个自娱自乐的博客(二) 架构搭建
- 2023-02-16 244浏览
-
- B-Tree、B+Tree以及B-link Tree
- 2023-01-19 235浏览
-
- mysql面试题
- 2023-01-17 157浏览
-
- MySQL数据表简单查询
- 2023-01-10 101浏览


