PythonNLP应用及常用库推荐
Python凭借简洁性和强大的社区支持,成为自然语言处理(NLP)的首选语言,广泛应用于从文本处理到深度学习模型等诸多任务。本文将介绍Python在NLP领域的常用库,包括NLTK(适用于教育和研究,擅长文本分词和词性标注)、spaCy(工业级应用,高效的实体识别和依赖解析)、Gensim(主题建模和文档相似度分析,处理大规模数据)以及Transformers(利用预训练模型如BERT进行情感分析等)。 我们将探讨这些库的应用场景及示例代码,帮助读者快速入门Python NLP。
Python在NLP领域广泛应用,提供了多种功能强大的库。1.NLTK适合文本分词和词性标注,适用于教育和研究。2.spaCy专注于工业级NLP任务,提供高效的实体识别和依赖解析。3.Gensim用于主题建模和文档相似度分析,处理大规模文本数据。4.Transformers库利用预训练模型如BERT进行情感分析等任务。

在自然语言处理(NLP)领域,Python的应用真是无处不在,从简单的文本处理到复杂的深度学习模型,Python都表现得游刃有余。让我们来深入探讨一下Python在NLP中的应用,以及那些让开发者们爱不释手的库。
自然语言处理是一个令人兴奋的领域,而Python凭借其简洁性和强大的社区支持,成为了NLP领域的首选语言。无论你是想进行文本分类、情感分析,还是构建聊天机器人,Python都能为你提供强大的工具和库。
让我们从一些基础知识开始吧。NLP涉及到文本的处理和理解,包括但不限于分词、词性标注、命名实体识别、文本分类、情感分析等。这些任务需要我们对文本进行预处理,然后利用各种算法和模型来进行分析和理解。
在Python中,最常用的NLP库包括:
NLTK(Natural Language Toolkit):NLTK是NLP入门者的好朋友,它提供了丰富的文本处理和分析工具,适合用于教育和研究。NLTK的优势在于其易用性和丰富的文档,但在大规模数据处理上可能略显不足。
spaCy:如果你需要更快的处理速度和更好的性能,spaCy是你不二之选。spaCy专注于工业级的NLP任务,提供了高效的语法和语义分析工具。它的API设计得非常简洁,适合用于生产环境。
Gensim:当你需要进行主题建模和文档相似度分析时,Gensim是你最好的选择。Gensim以其高效的算法和易于使用的接口而闻名,特别适合处理大规模文本数据。
Transformers(Hugging Face):如果你想利用最新的深度学习模型进行NLP任务,Hugging Face的Transformers库绝对是你的首选。它提供了预训练的模型,如BERT、RoBERTa、GPT等,可以轻松地用于各种NLP任务。
现在,让我们来看看这些库的具体应用和使用示例。
NLTK的应用:NLTK可以用于简单的文本分词和词性标注。以下是一个简单的示例:
import nltk from nltk.tokenize import word_tokenize from nltk import pos_tag下载必要的资源
nltk.download('punkt') nltk.download('averaged_perceptron_tagger')
text = "Python is an amazing language for NLP." tokens = word_tokenize(text) tagged = pos_tag(tokens)
print(tagged)
这个代码示例展示了如何使用NLTK进行文本分词和词性标注。通过这个简单的操作,我们可以看到Python在处理文本时的便捷性。
spaCy的应用:spaCy在处理实体识别和依赖解析方面表现出色。让我们看一个示例:
import spacynlp = spacy.load("en_core_web_sm") text = "Apple is looking at buying U.K. startup for $1 billion"
doc = nlp(text) for ent in doc.ents: print(ent.text, ent.label_)
在这个示例中,我们使用spaCy识别出文本中的实体,并打印出它们的类型和标签。spaCy的速度和准确性在处理大规模文本数据时非常有用。
Gensim的应用:Gensim在主题建模方面表现得非常出色。让我们看一个简单的示例:
from gensim import corpora from gensim.models import LdaModel from nltk.tokenize import word_tokenize from nltk.corpus import stopwords假设我们有一组文档
documents = ["Human machine interface for lab abc computer applications", "A survey of user opinion of computer system response time", "The EPS user interface management system", "System and human system engineering testing of EPS"]
预处理文本
texts = [[word for word in document.lower().split() if word not in stopwords.words('english')] for document in documents]
创建词袋模型
dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts]
训练LDA模型
lda_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=2, random_state=100, update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True)
打印主题
for idx, topic in lda_model.print_topics(-1): print('Topic: {} \nWords: {}'.format(idx, topic))
这个示例展示了如何使用Gensim进行主题建模,通过这个过程,我们可以从一组文档中提取出主要主题。
Transformers的应用:Transformers库使得使用预训练模型变得非常简单。让我们看一个使用BERT进行情感分析的示例:
from transformers import pipeline加载预训练的情感分析模型
classifier = pipeline('sentiment-analysis')
进行情感分析
result = classifier("I love using Python for NLP tasks!") print(result)
这个示例展示了如何使用Transformers库进行情感分析,利用BERT模型可以快速得到文本的情感倾向。
在使用这些库时,我们需要注意一些常见的错误和调试技巧。例如,在使用NLTK时,可能会遇到资源下载问题,这可以通过手动下载资源来解决。在使用spaCy时,需要确保模型的版本与代码兼容,否则可能会导致错误。在使用Gensim进行主题建模时,需要注意预处理步骤对结果的影响,确保文本数据的质量。在使用Transformers时,需要注意模型的大小和计算资源的限制,选择合适的模型和硬件配置。
性能优化和最佳实践也是我们需要关注的重点。例如,在处理大规模文本数据时,可以考虑使用多线程或分布式计算来提高处理速度。在编写代码时,保持代码的可读性和可维护性非常重要,适当的注释和文档可以帮助团队成员更好地理解和维护代码。
总的来说,Python在自然语言处理中的应用非常广泛,从简单的文本处理到复杂的深度学习模型,Python都提供了强大的工具和库。通过不断的学习和实践,我们可以更好地利用Python进行NLP任务,解决实际问题。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
 FetchDebian让你轻松搞定软件包管理
FetchDebian让你轻松搞定软件包管理
- 上一篇
- FetchDebian让你轻松搞定软件包管理
- 下一篇
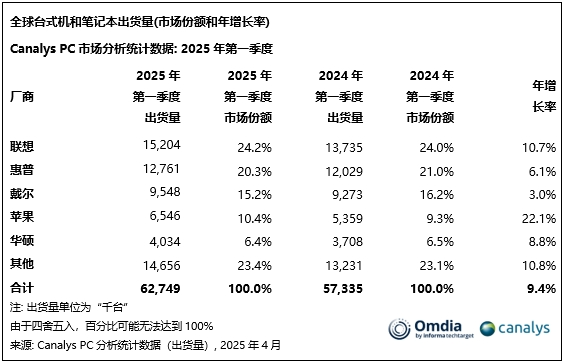
- Q1全球PC销量榜:联想、惠普、戴尔稳居前三
-
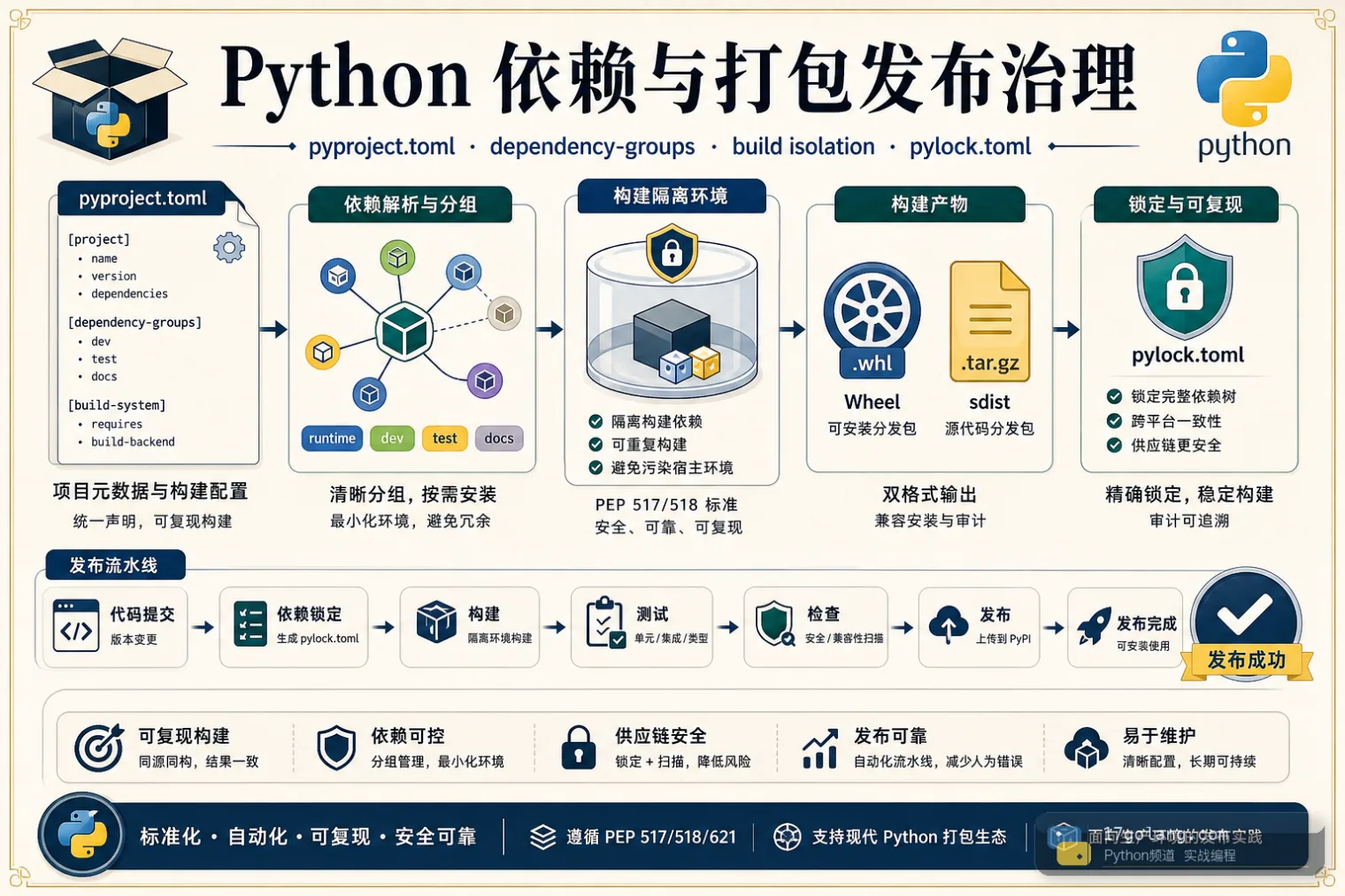
- 文章 · python教程 | 2小时前 | 依赖管理 · 工程化 · CI · 生产实践 · Python教程 · 打包发布 · Python build 依赖管理 twine wheel 打包发布 pyproject.toml dependency-groups pylock.toml sdist
- Python 打包发布实战:别把运行依赖和开发依赖混在一起
- 479浏览 收藏
-

- 文章 · python教程 | 1天前 | sqlalchemy · 异步编程 · fastapi · 生产实践 · Python教程 · Python 连接池 FastAPI sqlalchemy asyncio AsyncSession
- Python SQLAlchemy AsyncSession 实战:别在并发任务里共享 Session
- 340浏览 收藏
-

- 文章 · python教程 | 1天前 | 性能优化 · fastapi · 生产实践 · Python教程 · Pydantic · Python 性能优化 FastAPI Pydantic v2 TypeAdapter validate_json
- Python Pydantic v2 实战:TypeAdapter 别在请求里反复造
- 342浏览 收藏
-

- 文章 · python教程 | 3天前 |
- Python手写识别模型训练详解
- 447浏览 收藏
-

- 文章 · python教程 | 3天前 |
- Python递归测试:边界与深度验证指南
- 189浏览 收藏
-

- 文章 · python教程 | 3天前 |
- Python无头模式截图教程详解
- 462浏览 收藏




-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 5982次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6397次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6207次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8186次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 6790次使用
-
- Flask框架安装技巧:让你的开发更高效
- 2024-01-03 501浏览
-
- Django框架中的并发处理技巧
- 2024-01-22 501浏览
-
- 提升Python包下载速度的方法——正确配置pip的国内源
- 2024-01-17 501浏览
-
- Python与C++:哪个编程语言更适合初学者?
- 2024-03-25 501浏览
-
- 品牌建设技巧
- 2024-04-06 501浏览


