技术分享 | 控制mysqldump导出的SQL文件的事务大小
哈喽!今天心血来潮给大家带来了《技术分享 | 控制mysqldump导出的SQL文件的事务大小》,想必大家应该对数据库都不陌生吧,那么阅读本文就都不会很困难,以下内容主要涉及到MySQL、数据库,若是你正在学习数据库,千万别错过这篇文章~希望能帮助到你!
作者:陈俊聪
背景
有人问mysqldump出来的insert语句,是否可以按每 10 row 一条insert语句的形式组织。
思考1:参数--extended-insert
回忆过去所学:
我只知道有一对参数
--extended-insert(默认值)
表示使用长 INSERT ,多 row 在合并一起批量 INSERT,提高导入效率
--skip-extended-insert
一行一个的短INSERT
均不满足群友需求,无法控制按每 10 row 一条 insert 语句的形式组织。
思考2:“避免大事务”
之前一直没有考虑过这个问题。这个问题的提出,相信主要是为了“避免大事务”。所以满足 insert 均为小事务即可。
下面,我们来探讨一下以下问题:
- 什么是大事务?
- 那么 mysqldump 出来的 insert 语句可能是大事务吗?
什么是大事务?
- 定义:运行时间比较长,操作的数据比较多的事务我们称之为大事务。
- 大事务风险:
∘ 锁定太多的数据,造成大量的阻塞和锁超时,回滚所需要的时间比较长。
∘ 执行时间长,容易造成主从延迟。
∘ undo log膨胀
- 避免大事务:我这里按公司实际场景,规定了,每次操作/获取数据量应该少于5000条,结果集应该小于2M
mysqldump出来的SQL文件有大事务吗?
前提,MySQL 默认是自提交的,所以如果没有明确地开启事务,一条 SQL 语句就是一条事务。在 mysqldump 里,就是一条 SQL 语句为一条事务。
按照我的“避免大事务”自定义规定,答案是没有的。
原来,mysqldump 会按照参数--net-buffer-length,来自动切分 SQL 语句。默认值是 1M。按照我们前面定义的标准,没有达到我们的 2M 的大事务标准。
--net-buffer-length 最大可设置为 16777216,人手设置大于这个值,会自动调整为 16777216,即 16M。设置 16M,可以提升导出导入性能。如果为了避免大事务,那就不建议调整这个参数,使用默认值即可。
[root@192-168-199-198 ~]# mysqldump --net-buffer-length=104652800 -uroot -proot -P3306 -h192.168.199.198 test t >16M.sql mysqldump: [Warning] option 'net_buffer_length': unsigned value 104652800 adjusted to 16777216
设置大于16M,参数被自动调整为16M
注意,指的是 mysqldump 的参数,而不是 mysqld 的参数。官方文档提到: If you increase this variable, ensure that the MySQL server net_buffer_length system variable has a value at least this large.
意思是 mysqldump 增大这个值,mysqld 也得增大这个值,测试结论是不需要的。怀疑官方文档有误。
不过,在导入的时候,受到服务器参数 max_allowed_packet 影响,它控制了服务器能接受的数据包的最大大小,默认值是 4194304,即 4M。所以导入数据库时需要调整参数 max_allowed_packet 的值。
set global max_allowed_packet=16*1024*1024*1024;
不调整的话,会出现以下报错:
[root@192-168-199-198 ~]# mysql -uroot -proot -P3306 -h192.168.199.198 test
相关测试
最后,我放出我的相关测试步骤
mysql> select version(); +------------+ | version() | +------------+ | 5.7.26-log | +------------+ 1 row in set (0.00 sec)
造100万行数据
create database test; use test; CREATE TABLE `t` ( `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into t values (1,1,'abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyztuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz'); insert into t select * from t; #重复执行20次 # 直到出现Records: 524288 Duplicates: 0 Warnings: 0 # 说明数据量达到100多万条了。 mysql> select count(*) from t; +----------+ | count(*) | +----------+ | 1048576 | +----------+ 1 row in set (1.04 sec)
数据大小如下,有 284MB
[root@192-168-199-198 test]# pwd /data/mysql/mysql3306/data/test [root@192-168-199-198 test]# du -sh t.ibd 284M t.ibd --net-buffer-length=1M [root@192-168-199-198 ~]# mysqldump -uroot -proot -S /tmp/mysql3306.sock test t >1M.sql [root@192-168-199-198 ~]# du -sh 1M.sql 225M 1M.sql [root@192-168-199-198 ~]# cat 1M.sql |grep -i insert |wc -l 226
默认 --net-buffer-length=1M 的情况下,225M 的SQL文件里有 226 条 insert ,平均下来确实就是每条 insert 的 SQL 大小为 1M。
--net-buffer-length=16M
[root@192-168-199-198 ~]# mysqldump --net-buffer-length=16M -uroot -proot -S /tmp/mysql3306.sock test t >16M.sql [root@192-168-199-198 ~]# du -sh 16M.sql 225M 16M.sql [root@192-168-199-198 ~]# cat 16M.sql |grep -i insert |wc -l 15
默认--net-buffer-length=16M 的情况下,225M 的 SQL 文件里有 15 条 insert,平均下来确实就是每条 insert 的 SQL 大小为 16M。
所以,这里证明了 --net-buffer-length 确实可用于拆分 mysqldump 备份文件的SQL大小的。
性能测试
insert 次数越多,交互次数就越多,性能越低。 但鉴于上面例子的 insert 数量差距不大,只有 16 倍,性能差距不会很大(实际测试也是如此)。我们直接对比 --net-buffer-length=16K 和 --net-buffer-length=16M 的情况,他们insert次数相差了 1024 倍。
[root@192-168-199-198 ~]# time mysql -uroot -proot -S /tmp/mysql3306.sock test
结果明显。--net-buffer-length 设置越大,客户端与数据库交互次数越少,导入越快。
结论
mysqldump 默认设置下导出的备份文件,符合导入需求,不会造成大事务。性能方面也符合要求,不需要调整参数。
参考链接:
https://dev.mysql.com/doc/ref...
到这里,我们也就讲完了《技术分享 | 控制mysqldump导出的SQL文件的事务大小》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于mysql的知识点!
 做工作计划软件哪个好
做工作计划软件哪个好
- 上一篇
- 做工作计划软件哪个好

- 下一篇
- OA系统之网络硬盘,高效管理大容量网络硬盘
-

- 曾经的斑马
- 这篇博文真及时,好细啊,很棒,码住,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-25 21:54:06
-
- 隐形的黄豆
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢博主分享博文!
- 2023-02-20 09:47:53
-
- 粗犷的西装
- 这篇博文真及时,太全面了,真优秀,已加入收藏夹了,关注博主了!希望博主能多写数据库相关的文章。
- 2023-02-06 08:19:48
-
- 完美的时光
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢博主分享文章!
- 2023-02-02 01:56:10
-
- 包容的雪糕
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢老哥分享技术贴!
- 2023-02-01 23:21:19
-
- 爱笑的汉堡
- 这篇博文出现的刚刚好,太细致了,很有用,已加入收藏夹了,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-02-01 16:16:01
-
- 儒雅的耳机
- 很详细,码住,感谢作者大大的这篇文章内容,我会继续支持!
- 2023-01-31 18:44:14
-
- 深情的犀牛
- 这篇文章出现的刚刚好,太全面了,受益颇多,已收藏,关注博主了!希望博主能多写数据库相关的文章。
- 2023-01-27 08:03:50
-
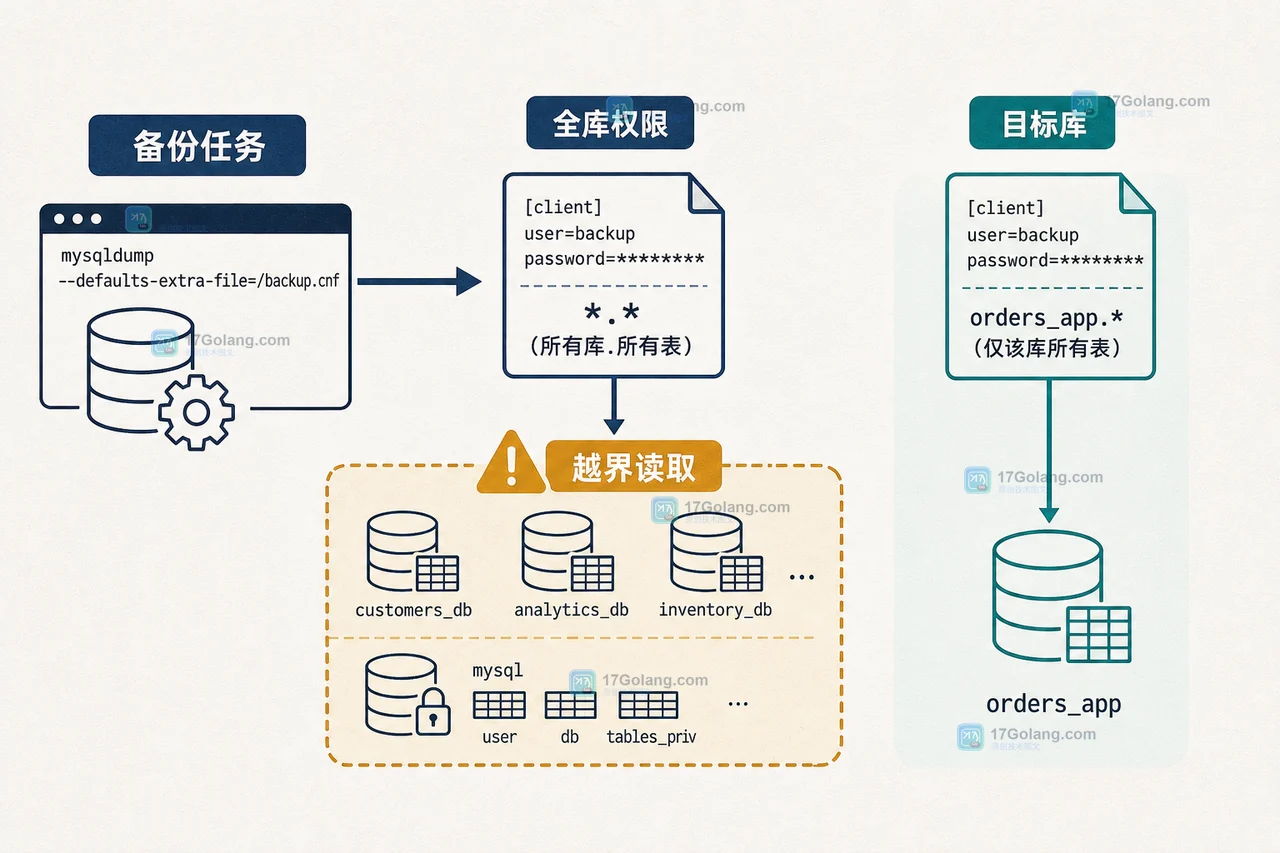
- 数据库 · MySQL | 2天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限
- mysqldump 备份账号如何避免全库越权:MySQL 角色与 partial_revokes 实战
- 413浏览 收藏
-
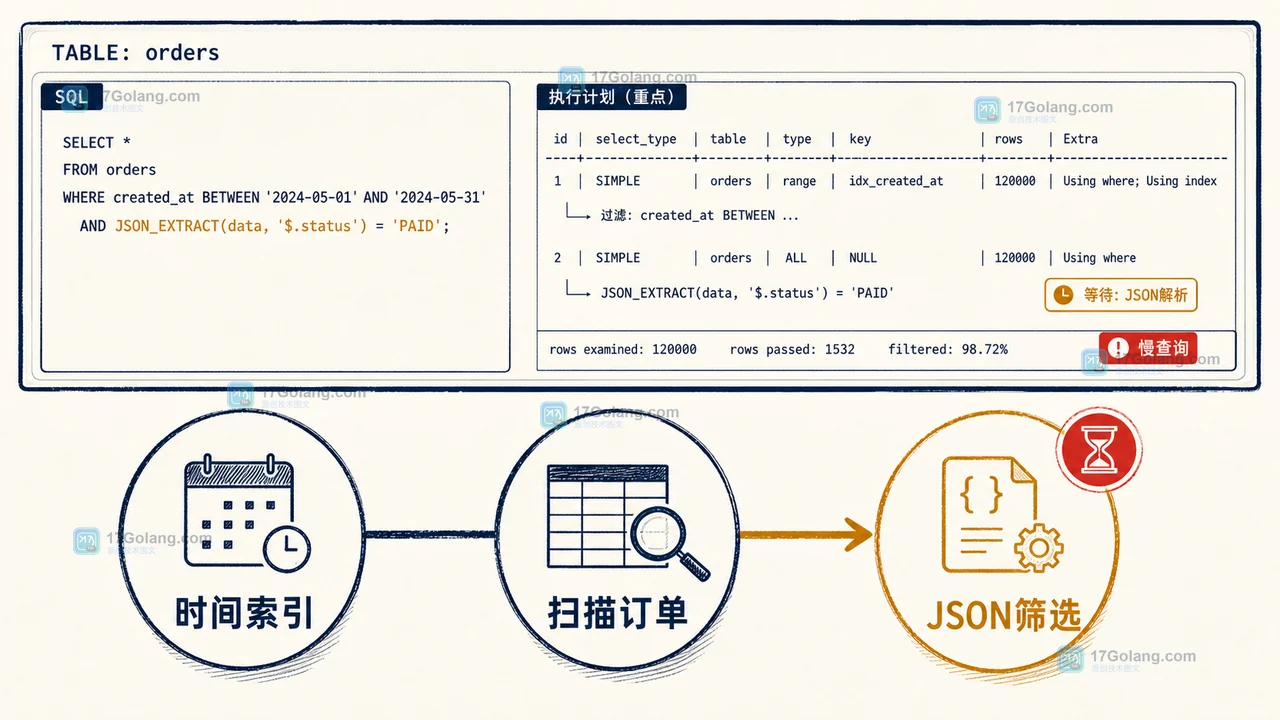
- 数据库 · MySQL | 2天前 |
- MySQL JSON_EXTRACT 查询为什么慢:用生成列索引做一次可验证优化实验
- 278浏览 收藏
-

- 数据库 · MySQL | 3天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
- MySQL JSON 字段怎么给列表筛选提速:生成列、索引与 NULL 边界
- 351浏览 收藏
-
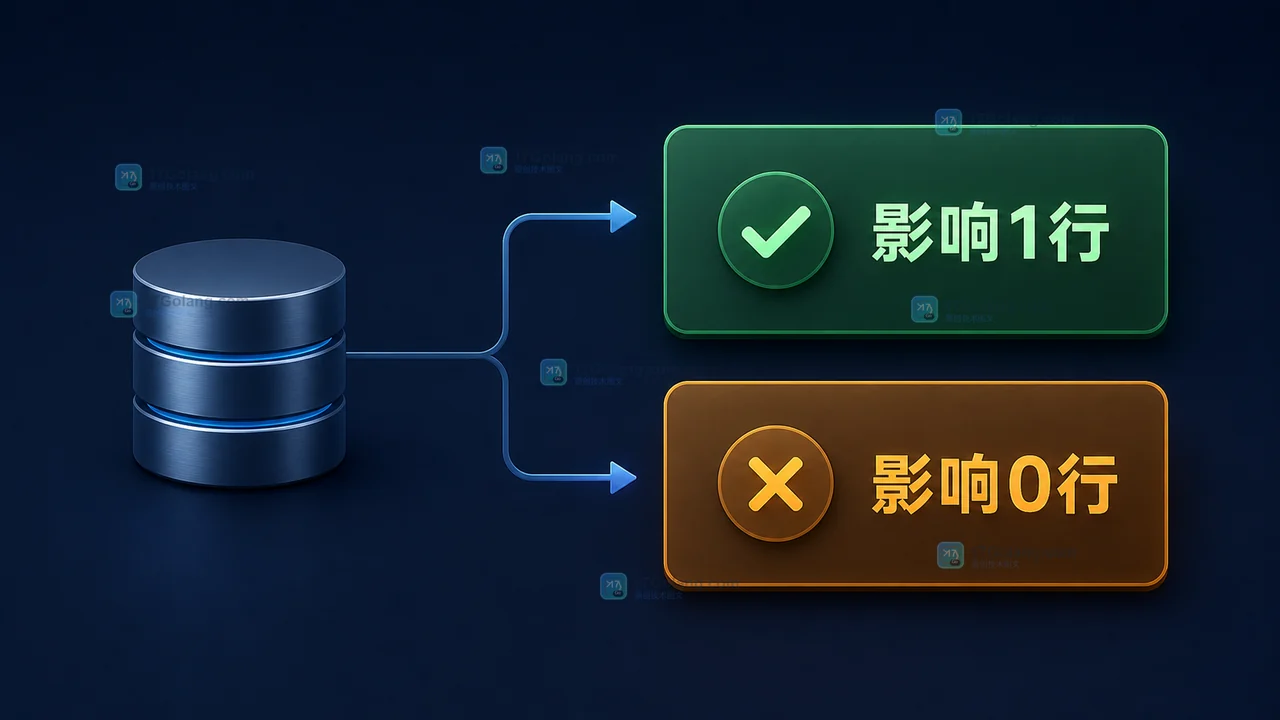
- 数据库 · MySQL | 1星期前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
- MySQL 库存怎么安全扣减?条件 UPDATE、防超卖和受影响行判断
- 470浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4661次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4273次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4230次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4449次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4411次使用
-
- MySQL 明明加了索引,为什么查询还是很慢?先查这 6 个点
- 2026-06-27 374浏览
-
- 接口返回的数据和数据库不一致怎么办?按数据生命周期排查
- 2026-06-27 398浏览
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- golang 基于 mysql 简单实现分布式读写锁
- 2023-01-07 384浏览
-
- 详解如何利用GORM实现MySQL事务
- 2023-01-07 184浏览


