python-自动判断数据类型,并将数据导入到MySQL中
来源:SegmentFault
2023-02-24 21:13:05
0浏览
收藏
小伙伴们有没有觉得学习数据库很有意思?有意思就对了!今天就给大家带来《python-自动判断数据类型,并将数据导入到MySQL中》,以下内容将会涉及到MySQL、python、pymysql,若是在学习中对其中部分知识点有疑问,或许看了本文就能帮到你!
前言:最近写了一个自动导入mysql中数据表的脚本,后来发现有一个to_sql()函数也可以实现类似的功能,测试了该函数后发现,无法实现对数据类型的自动准确判断。(有可能是我没理解到位,有经验的朋友请指出)不罗嗦,直接放示例文件和代码。
示例文件:

# -*- coding: utf-8 -*-
"""
Created on Tue Jun 23 11:39:34 2020
@author: Ray
"""
import re
import sys
import pymysql
import logging
import argparse
import numpy as np
import pandas as pd
from warnings import filterwarnings
#--------------------------------------------------------------------------报错日志-----------------------------------------------------------------------------------------------#
logging.basicConfig(filename = 'load.log', level=logging.DEBUG, format = "%(levelname)s %(asctime)s:%(name)s:%(message)s", datefmt = '%Y-%m-%d', filemode = 'w')
filterwarnings("error", category = pymysql.Warning) # 捕获mysql错误信息。
#--------------------------------------------------------------------------参数设置-----------------------------------------------------------------------------------------------#
parser = argparse.ArgumentParser(description = 'Inofrmation of database table.')
parser.add_argument('-data', action = 'store', help = 'Path of data source.', required = True) # 指定数据源或数据地址
parser.add_argument('-database', help = 'Database name.', required = True) # 指定存储得库名
parser.add_argument('-tablename', help = 'Table name.', required = True) # 指定存储的表名
parser.add_argument('-droptable', help = 'If exists table, drop table', required = False, default = False, type = bool) # 如果建表时存在相同表名是否删除
parser.add_argument('-primaryKey', nargs = '+', help = 'PrimaryKey column.(Example format: ID or ID Pos)', required = False, default = None) # 设定的主键
parser.add_argument('-index', nargs = '+', help = 'Index column.(Example format: MAF or MAF Pos)', required = False, default = None) # 指定索引字段(默认为空)
parser.add_argument('-index_union', help = 'Pass index_union dictionary.(Example format: MAF-Pos or MAF-Pos,Chrom-Gene)', required = False, default = None) # 指定索引字段(默认为空)
parser.add_argument('-host', help = 'Host name.', required = True) # 主机名或IP地址
parser.add_argument('-user', help = 'User name.', required = True) # 用户名
parser.add_argument('-password', help = 'Password', required = True) # 密码
args = parser.parse_args()
wide_connect = None
wide_cursor = None
typeList = [] # 建表语句
priDict = dict() # 定义主键()
#--------------------------------------------------------------------------数据导入-----------------------------------------------------------------------------------------------#
# 判断原始数据是否含有重复名
with open(args.data, 'r') as data:
for line in data:
li = line.strip().split('\t')
break
set_lst = set(li)
if len(set_lst) == len(li):
pass
else:
logging.warning("Duplicate column names.")
sys.exit()
data = pd.read_table(args.data, sep = '\t')
if len(data.columsn) 0.5:
logging.error("MAF must be less than 0.5")
sys.exit()
if set(['Gene']).issubset(data.columns): # 如果用户数据有Gene列,判断其格式
for i ,j in zip(data['Gene'], range(len(data['Gene']))):
if re.search(':', i) != None:
logging.error("The bug in the {} line of Gene column".format(j + 1))
sys.exit()
else:
continue
#--------------------------------------------------------------------------MySQL链接----------------------------------------------------------------------------------------------#
wide_connect = pymysql.connect(host = args.host,
user = args.user,
password = args.password,
port = 3306, charset = 'utf8',
local_infile = True) # ***loacl_infile允许导入本地文件***
wide_cursor = wide_connect.cursor()
#--------------------------------------------------------------------------数据类型-----------------------------------------------------------------------------------------------#
# 针对整数型数值定义其格式-----------------------------------------------------------------------------------------------------------------------------------------------------------
int_fun = lambda x: 'TINYINT({})'.format(len(str(x))) if -128 = 2]) # 整数位最大长度
d = min([len(i[1]) for i in flo if len(i) >= 2]) # 小数位最大长度
return 'FLOAT ({m}, {d})'.format(m = m + d + 2, d = d + 2)
#--------------------------------------------------------------------------建表语句-----------------------------------------------------------------------------------------------#
typeList = []
for column in data.columns:
# 如果字段是整数型
if data[column].dtypes in [np.dtype('int16'), np.dtype('int32'), np.dtype('int64'), np.dtype('uint16'), np.dtype('uint32'), np.dtype('uint64')]:
if -1 in np.sign(data[column]):
int_max = data[column].max() # 整数长度
typeList.append("`{}`".format(column) + int_fun(int_max) + "DEFAULT NULL")
continue
else:
int_max = data[column].max() # 整数长度
typeList.append("`{}`".format(column) + int_fun_unsigned(int_max) + "DEFAULT NULL")
continue
# 如果字段是浮点型
if data[column].dtype in [np.dtype('float16'), np.dtype('float32'), np.dtype('float64')]:
typeList.append("`{}`".format(column) + float_fun(column) + "DEFAULT NULL")
# 如果字段是文本
else:
str_len = max([len(i) for i in data[column] if pd.notnull(i)])
typeList.append("`{}`".format(column) + "VARCHAR({})".format(str_len) + "DEFAULT NULL")
# 如果定义了主键,则该字段默认不为空----------------------------------------------------------------------------------------------------------------------------------------------------
for column, c in zip(data.columns, range(len(data.columns))):
if column in args.primaryKey:
typeList[c] = typeList[c].replace('DEFAULT NULL', 'NOT NULL')
priDict[column] = column
#----------------------------------------------------------------------------建表-------------------------------------------------------------------------------------------------#
# 指定主键(我们一般定义ID为主键)
if args.primaryKey != None:
if len(args.primaryKey) == 1: # 如果定义一个键是主键
primaryKey_statement = ["PRIMARY KEY (`{}`)".format(col) for col in data.columns if col in args.primaryKey][0]
else:
primaryKey_statement = "PRIMARY KEY ({})".format(','.join(['`' + col + '`'for col in data.columns if col in args.primaryKey]))
# 指定索引
if args.index != None and args.index_union != None: # 如果创建联合索引,在将args.index中的每个元素单独创建索引的同时,将args.index_union中的每一个元素创建索引
index_statement = ','.join(["KEY `{}` (`{}`)".format(col, col) for col in data.columns if col in args.index])
index_statement = index_statement + ',' + ','.join(["KEY `{}` ({})".format(index, ','.join('`' + k + '`' for k in index.split('-'))) for index in args.index_union.split(',')])
elif args.index != None and args.index_union == None: # 如果不创建联合索引,将self.key中的每个元素创建索引
index_statement = ','.join(["KEY `{}` (`{}`)".format(col, col) for col in data.columns if col in args.index])
elif args.index == None and args.index_union != None:
index_statement = ','.join(["KEY `{}` ({})".format(index, ','.join('`' + k + '`' for k in index.split('-'))) for index in args.index_union.split(',')])
# 执行建表语句----------------------------------------------------------------------------------------------------------------------------------------------------------------------
wide_cursor.execute("USE {};".format(args.database)) # 选择数据库
try:
if args.droptable: # 是否删除已经存在的表
wide_cursor.execute("DROP TABLE IF EXISTS {};".format(args.tablename))
except pymysql.Warning:
logging.debug("不存在{}表".format(args.tablename))
if 'primaryKey_statement' in dir() and 'index_statement' in dir():
wide_cursor.execute("CREATE TABLE IF NOT EXISTS `{table_}`(\
{data_demand_statement_},\
{primary_key_},\
{index_statement_}) ENGINE=MyISAM DEFAULT CHARSET=utf8;".\
format(table_ = args.tablename, # 表名
data_demand_statement_ = ','.join(typeList), # 字段格式语句
primary_key_ = primaryKey_statement, # 主键语句
index_statement_ = index_statement # 索引语句
)
)
elif 'primaryKey_statement' not in dir() and 'index_statement' in dir():
wide_cursor.execute("CREATE TABLE IF NOT EXISTS `{table_}`(\
{data_demand_statement_},\
{index_statement_}) ENGINE=MyISAM DEFAULT CHARSET=utf8;".\
format(table_ = args.tablename, # 表名
data_demand_statement_ = ','.join(typeList), # 字段格式语句
index_statement_ = index_statement # 索引语句
)
)
elif 'primaryKey_statement' in dir() and 'index_statement' not in dir():
wide_cursor.execute("CREATE TABLE IF NOT EXISTS `{table_}`(\
{data_demand_statement_},\
{primary_key_}) ENGINE=MyISAM DEFAULT CHARSET=utf8;".\
format(table_ = args.tablename, # 表名
data_demand_statement_ = ','.join(typeList), # 字段格式语句
primary_key_ = primaryKey_statement # 索引语句
)
)
else:
wide_cursor.execute("CREATE TABLE IF NOT EXISTS `{table_}`(\
{data_demand_statement_}) ENGINE=MyISAM DEFAULT CHARSET=utf8;".\
format(table_ = args.tablename, # 表名
data_demand_statement_ = ','.join(typeList), # 字段格式语句
)
)
#----------------------------------------------------------------------------存储-------------------------------------------------------------------------------------------------#
wide_cursor.execute("USE {}".format(args.database))
# 导入数据表语句------------------------------------------------------------------------------------------------------------------------------------------------------------
try:
wide_cursor.execute("LOAD DATA LOCAL INFILE '{}' INTO TABLE {}.{} FIELDS TERMINATED BY '\\t' IGNORE 1 LINES".format(args.data, args.database, args.tablename))
except pymysql.Warning:
logging.warning("Duplicate primarikey.")
wide_cursor.execute("drop table {}".format(args.tablename))
wide_connect.commit() # 数据提交
wide_cursor.close() # 关闭链接
代码有很多不成熟的地方,大家在使用过程中发现有错误请指出。
在学习的过程中借鉴了这篇文章。(https://blog.csdn.net/weixin_38153458/article/details/85289433?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase)
终于介绍完啦!小伙伴们,这篇关于《python-自动判断数据类型,并将数据导入到MySQL中》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布数据库相关知识,快来关注吧!
版本声明
本文转载于:SegmentFault 如有侵犯,请联系study_golang@163.com删除
 数据库-MySQL中for update的作用和用法
数据库-MySQL中for update的作用和用法
- 上一篇
- 数据库-MySQL中for update的作用和用法

- 下一篇
- win 10下mysql 5.6 升级到mysql 8.0
查看更多
最新文章
-

- 数据库 · MySQL | 16小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
- MySQL JSON 字段怎么给列表筛选提速:生成列、索引与 NULL 边界
- 351浏览 收藏
-
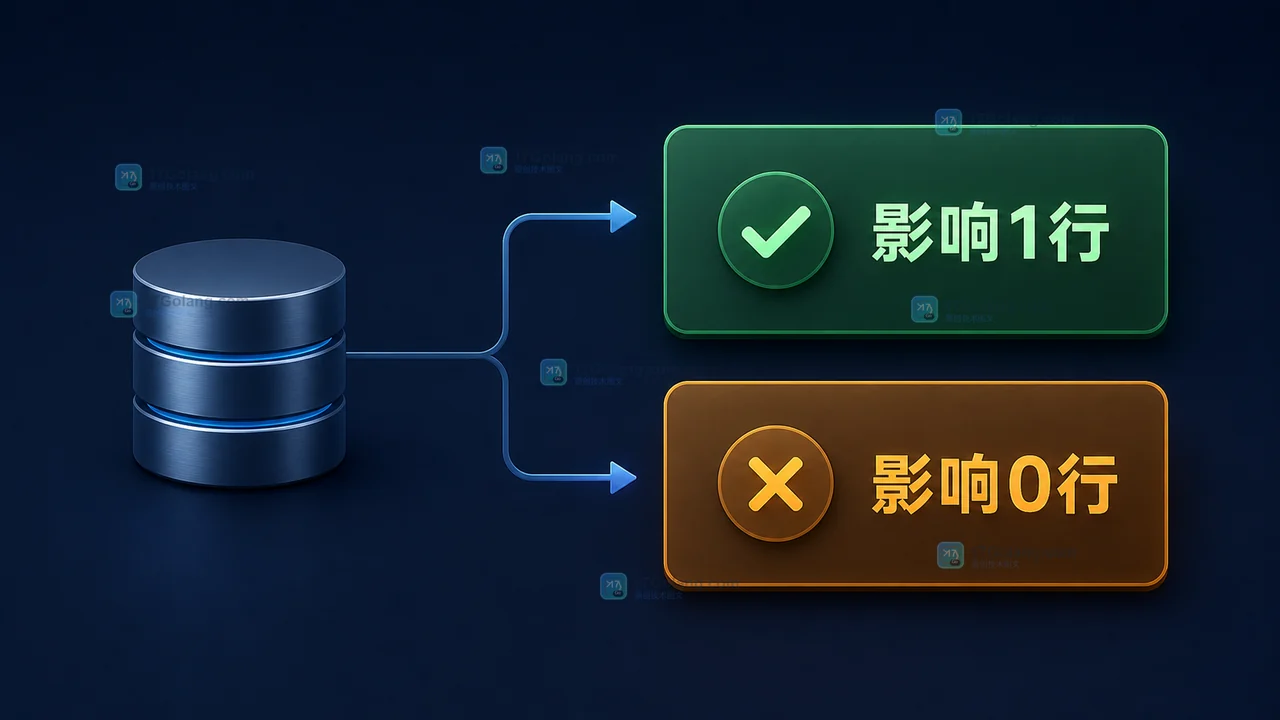
- 数据库 · MySQL | 5天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
- MySQL 库存怎么安全扣减?条件 UPDATE、防超卖和受影响行判断
- 470浏览 收藏



查看更多
课程推荐
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
查看更多
AI推荐
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4609次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4240次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4197次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4421次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4377次使用
查看更多
相关文章
-
- MySQL 明明加了索引,为什么查询还是很慢?先查这 6 个点
- 2026-06-27 374浏览
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- golang 基于 mysql 简单实现分布式读写锁
- 2023-01-07 384浏览
-
- 详解如何利用GORM实现MySQL事务
- 2023-01-07 184浏览
-
- Go语言实现操作MySQL的基础知识总结
- 2023-01-23 265浏览


