linux模拟资源占用 你会吗
你在学习文章相关的知识吗?本文《linux模拟资源占用 你会吗》,主要介绍的内容就涉及到,如果你想提升自己的开发能力,就不要错过这篇文章,大家要知道编程理论基础和实战操作都是不可或缺的哦!
公司拥有一批云服务器,这些服务器托管在华为云上,然而,很多云服务器的资源利用率并不高,处于空闲状态。我开始担心领导会察觉到这些空闲资源,要求我们降低配置,并可能削减云服务器的采购预算。因此,我计划编写一个 shell 脚本,用于模拟资源占用的情况。
实施思路
- 使用 stress 工具对内存进行压力测试,占用剩余内存的80%,以模拟CPU和内存的消耗情况。
- 使用 dd 命令生成大文件,占用第二块硬盘剩余空间的80%,以模拟硬盘空间的消耗和IO操作。
- 让脚本运行持续20分钟,一旦检测到内存占用超过80%,则停止压力测试。
- 避免对CPU进行压力测试,因为过高的CPU占用率可能导致应用异常或服务器重启的风险。
相关工具
stress
stress 命令主要用来模拟系统负载较高时的场景,本文介绍其基本用法。文中 demo 的演示环境为 ubuntu 18.04。
可选参数
-c, –cpu N 产生 N 个进程,每个进程都反复不停的计算随机数的平方根
-i, –io N 产生 N 个进程,每个进程反复调用 sync() 将内存上的内容写到硬盘上
-m, –vm N 产生 N 个进程,每个进程不断分配和释放内存 –vm-bytes B 指定分配内存的大小
–vm-stride B 不断的给部分内存赋值,让 COW(Copy On Write)发生 –vm-hang N 指示每个消耗内存的进程在分配到内存后转入睡眠状态 N 秒,然后释放内存,一直重复执行这个过程
–vm-keep 一直占用内存,区别于不断的释放和重新分配(默认是不断释放并重新分配内存)
-d, –hadd N 产生 N 个不断执行 write 和 unlink 函数的进程(创建文件,写入内容,删除文件)
–hadd-bytes B 指定文件大小
-t, –timeout N 在 N 秒后结束程序 –backoff N 等待N微妙后开始运行
-q, –quiet 程序在运行的过程中不输出信息
-n, –dry-run 输出程序会做什么而并不实际执行相关的操作
–version 显示版本号
-v, –verbose 显示详细的信息
消耗 CPU 资源
stress 消耗 CPU 资源是通过调用 sqrt 函数计算由 rand 函数产生的随机数的平方根实现。下面的命令会产生 4 个这样的进程不断计算:
$ stress -c
使用 top 命令查看 CPU 的状态如下(CPU 在用户态满负荷运转):
消耗内存资源
下面的命令产生两个子进程,每个进程分配 300M 内存:
$ stress --vm 2 --vm-bytes 300M --vm-keep
父进程处于睡眠状态,两个子进程负责资源消耗。
–vm-keep 一直占用内存,区别于不断的释放和重新分配(默认是不断释放并重新分配内存)。 –vm-hang N 指示每个消耗内存的进程在分配到内存后转入睡眠状态 N 秒,然后释放内存,一直重复执行这个过程。
–vm-keep 和 –vm-hang 都可以用来模拟只有少量内存的机器,但是指定它们时 CPU 的使用情况是不一样的。
$stress --vm 2 --vm-bytes 500M --vm-keep
一直在进行默认的 stride 操作,user 非常高(cpu 在用户态忙碌)。
$ stress --vm 2 --vm-bytes 500M --vm-hang 5
上面这两种状态不断切换,但整体上看 CPU 的负载并不高。
–vm-stride B 不断的给部分内存赋值,让 COW(Copy On Write)发生。只要指定了内存相关的选项,这个操作就会执行,只是大小为默认的 4096。赋值内存的比例由参数决定:
for (i = 0; i
$ stress --vm 2 --vm-bytes 500M --vm-stride 64 $ stress --vm 2 --vm-bytes 500M --vm-stride 1M
为什么会产生这样的结果?原因是单独的赋值和对比操作可以让 CPU 在用户态的负载占到 99% 以上。–vm-stride 值增大就意味着减少赋值和对比操作,这样就增加了内存的释放和分配次数(cpu在内核空间的负载)。 不指定 –vm-stride 选项就使用默认值是 4096,CPU 负载情况居于前两者之间:
$ stress --vm 2 --vm-bytes 500M
消耗 IO 资源 下面的命令产生 4 个进程,每个进程都反复调用 sync 函数将内存上的内容写到硬盘上:
$ stress -i 4
使用 top 命令查看 CPU 的状态如下:
sy 升高,wa(iowait) 非常高。
压测磁盘及 IO 下面的命令创建一个进程不断的在磁盘上创建 10M 大小的文件并写入内容:
$ stress -d 1 --hdd-bytes 10M
使用 top 命令查看 CPU 的状态如下(此时的 CPU 主要消耗在内核态):
下面是 iostat 2 的输出(同样是高 iowait,瓶颈是写磁盘):
其它选项
–verbose 显示 stress 程序运行过程中的详细信息:
–timeout N 在 N 秒后结束程序。
–quiet stress 程序运行的过程中不输出信息。
-n, –dry-run 输出程序会做什么而并不实际执行相关的操作:
–backoff N 让新 fork 出来的进程 sleep N 微秒再开始运行。
除了单独指定某一类的选项,还可以同时执行多个类型的任务,比如产生 3 个 CPU 进程、3 个 IO 进程、2 个10M 的 vm 进程,并且每个 vm 进程中不循环分配释放内存:
$ stress --cpu 3 --io 3 --vm 2 --vm-bytes 10M --vm-keep
dd
dd 命令 用于复制文件并对原文件的内容进行转换和格式化处理。dd 命令功能很强大的,对于一些比较底层的问题,使用 dd 命令往往可以得到出人意料的效果。用的比较多的还是用 dd 来备份裸设备。但是不推荐,如果需要备份 oracle 裸设备,可以使用 rman 备份,或使用第三方软件备份,使用 dd 的话,管理起来不太方便。需要的时候使用 dd 对物理磁盘操作,如果是文件系统的话还是使用 tar backup cpio 等其他命令更加方便。另外,使用 dd 对磁盘操作时,最好使用块设备文件。
语法
dd (选项)
命令选项
bs=:将ibs(输入)与obs(输出)设成指定的字节数; cbs=:转换时,每次只转换指定的字节数; conv=:指定文件转换的方式; count=:仅读取指定的区块数; ibs=:每次读取的字节数; obs=:每次输出的字节数; of=:输出到文件; seek=:一开始输出时,跳过指定的区块数; skip=:一开始读取时,跳过指定的区块数; --help:帮助; --version:显示版本信息。
实例
> dd if=/dev/zero of=sun.txt bs=1M count=1 1+0 records in 1+0 records out 1048576 bytes (1.0 MB) copied, 0.006107 seconds, 172 MB/s [root@localhost text] 1.1M sun.txt
该命令创建了一个 1M 大小的文件 sun.txt,其中参数解释:
- if 代表输入文件。如果不指定 if,默认就会从 stdin 中读取输入。
- of 代表输出文件。如果不指定 of,默认就会将 stdout 作为默认输出。
- bs 代表字节为单位的块大小。
- count 代表被复制的块数。
- /dev/zero 是一个字符设备,会不断返回 0 值字节(\0)。
块大小可以使用的计量单位表
| 单元大小 | 代码 |
|---|---|
| 字节(1B) | c |
| 字节(2B) | w |
| 块(512B) | b |
| 千字节(1024B) | k |
| 兆字节(1024KB) | M |
| 吉字节(1024MB) | G |
以上命令可以看出 dd 命令来测试内存操作速度:
> 1048576 bytes (1.0 MB) copied, 0.006107 seconds, 172 MB/s
生成随机字符串
我们甚至可以使用 /dev/urandom 设备配合 dd 命令 来获取随机字符串
> dd if=/dev/urandom bs=1 count=15|base64 -w 0 15+0 records in 15+0 records out 15 bytes (15 B) copied, 0.000111993 s, 134 kB/s wFRAnlkXeBXmWs1MyGEs
常用案例汇总
1.将本地的/dev/hdb整盘备份到/dev/hdd #dd if=/dev/hdb of=/dev/hdd 2.将/dev/hdb全盘数据备份到指定路径的image文件 #dd if=/dev/hdb of=/root/image 3.将备份文件恢复到指定盘 #dd if=/root/image of=/dev/hdb 4.备份/dev/hdb全盘数据,并利用gzip工具进行压缩,保存到指定路径 #dd if=/dev/hdb | gzip > /root/image.gz 5.将压缩的备份文件恢复到指定盘 #gzip -dc /root/image.gz | dd of=/dev/hdb 6.备份与恢复MBR 备份磁盘开始的512个字节大小的MBR信息到指定文件: #dd if=/dev/hda of=/root/image count=1 bs=512 count=1指仅拷贝一个块;bs=512指块大小为512个字节。 恢复: #dd if=/root/image of=/dev/had 将备份的MBR信息写到磁盘开始部分 7.备份软盘 #dd if=/dev/fd0 of=disk.img count=1 bs=1440k (即块大小为1.44M) 8.拷贝内存内容到硬盘 #dd if=/dev/mem of=/root/mem.bin bs=1024 (指定块大小为1k) 9.拷贝光盘内容到指定文件夹,并保存为cd.iso文件 #dd if=/dev/cdrom(hdc) of=/root/cd.iso 10.增加swap分区文件大小 第一步:创建一个大小为256M的文件: #dd if=/dev/zero of=/swapfile bs=1024 count=262144 第二步:把这个文件变成swap文件: #mkswap /swapfile 第三步:启用这个swap文件: #swapon /swapfile 第四步:编辑/etc/fstab文件,使在每次开机时自动加载swap文件: /swapfile swap swap default 0 0 11.销毁磁盘数据 #dd if=/dev/urandom of=/dev/hda1 注意:利用随机的数据填充硬盘,在某些必要的场合可以用来销毁数据。 12.测试硬盘的读写速度 #dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file #dd if=/root/1Gb.file bs=64k | dd of=/dev/null 通过以上两个命令输出的命令执行时间,可以计算出硬盘的读、写速度。 13.确定硬盘的最佳块大小: #dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file #dd if=/dev/zero bs=2048 count=500000 of=/root/1Gb.file #dd if=/dev/zero bs=4096 count=250000 of=/root/1Gb.file #dd if=/dev/zero bs=8192 count=125000 of=/root/1Gb.file 通过比较以上命令输出中所显示的命令执行时间,即可确定系统最佳的块大小。 14.修复硬盘: #dd if=/dev/sda of=/dev/sda 或dd if=/dev/hda of=/dev/hda 当硬盘较长时间(一年以上)放置不使用后,磁盘上会产生magnetic flux point,当磁头读到这些区域时会遇到困难,并可能导致I/O错误。当这种情况影响到硬盘的第一个扇区时,可能导致硬盘报废。上边的命令有可能使这些数 据起死回生。并且这个过程是安全、高效的。 15.利用netcat远程备份 #dd if=/dev/hda bs=16065b | netcat 1234 在源主机上执行此命令备份/dev/hda #netcat -l -p 1234 | dd of=/dev/hdc bs=16065b 在目的主机上执行此命令来接收数据并写入/dev/hdc #netcat -l -p 1234 | bzip2 > partition.img #netcat -l -p 1234 | gzip > partition.img 以上两条指令是目的主机指令的变化分别采用bzip2、gzip对数据进行压缩,并将备份文件保存在当前目录。 将一个很大的视频文件中的第i个字节的值改成0x41(也就是大写字母A的ASCII值) echo A | dd of=bigfile seek=$i bs=1 count=1 conv=notrunc
脚本
编写的shell脚本如下:
#!/bin/bash
#模拟cpu,IO,内存使用
#ver 1.0
#每天凌晨1:00执行
#持续20分钟
#记录执行日志
script_log="script_log.log"
mem_info=$(free -m | grep Mem)
used_mem=$(echo $mem_info | awk '{print $3}')
total_mem=$(echo $mem_info | awk '{print $2}')
# 计算内存利用率
mem_util=$(echo "scale=2; $used_mem / $total_mem * 100" | bc)
#内存利用率取整数
mem_utilization=$(printf "%.0f" "$mem_util")
if [ ! -f "$script_log" ]; then
touch "$script_log"
fi
# 模拟内存占用
function simulate_memory() {
#安装stress压测工具
INSTALLED=$(rpm -qa | grep stress)
if [ $? -eq 0 ];then
echo "$(date +%Y-%m-%d-%H:%M) 已经安装了stress" >> $script_log
else
yum install stress -y
sleep 5
fi
#执行内存
if [ $mem_utilization -lt 80 ];then
stress --io 1 --vm 1 --vm-bytes "$(awk '/MemFree/{printf "%d\n", 0.7*$2}' /proc/meminfo)k" --vm-keep &
echo "$(date +%Y-%m-%d-%H:%M) 执行内存压测命令 " >> $script_log
fi
}
#模拟file占用
function simulate_file() {
#判断第二硬盘是否存在
second_disk=$(lsblk | grep -w "vd[b-z]")
if [ $? -eq 0 ];then
echo "$(date +%Y-%m-%d-%H:%M) 第二块硬盘存在" >> $script_log
if [ -d "/data" ];then
if [ -d "/data/second_disk_data_tmp" ];then
echo "$(date +%Y-%m-%d-%H:%M) 临时目录/data/second_disk_data_tmp已存在" >> $script_log
else
mkdir -p /data/second_disk_data_tmp
echo "$(date +%Y-%m-%d-%H:%M) 临时目录/data/second_disk_data_tmp不存在,已创建" >> $script_log
fi
fi
else
echo "$(date +%Y-%m-%d-%H:%M) 第二块硬盘不存在" >> $script_log
fi
#执行前先删除临时文件
if [ -f "/data/second_disk_data_tmp/data_tmp.txt" ];then
rm -f /data/second_disk_data_tmp/data_tmp.txt
echo "$(date +%Y-%m-%d-%H:%M) /data/second_disk_data_tmp/data_tmp.txt 文件存在,已删除"
else
touch /data/second_disk_data_tmp/data_tmp.txt
fi
#第二块盘磁盘利用率
second_disk_usage=$(df -h | egrep "vd[b-z]" | awk '{ print $5 }' | tr -d "%")
#需要占用的磁盘空间大小
file_size=$(df -h | egrep "vd[b-z]" | awk '{ print $4*0.8 }' | tr -d "G"|bc)
#去整数
size_file=$(printf "%.0f" "$file_size")
#计算需要生成的文件大小
#如果第二盘的空间小于80
if [ $second_disk_usage -lt 80 ];then
#dd命令生成文件
time1=$(date +%s)
echo "$(date +%Y-%m-%d-%H:%M) 开始执行生成临时文件" >> $script_log
dd if=/dev/zero of=/data/second_disk_data_tmp/data_tmp.txt bs=1G count=$size_file
time2=$(date +%s)
time3=$((time2-time1))
echo "$(date +%Y-%m-%d-%H:%M) 生成了临时文件,路径为/data/second_disk_data_tmp/data_tmp.txt,花费时间$time3 秒" >> $script_log
if [ $second_disk_usage -ge 80 ];then
if [ -f "/data/second_disk_data_tmp/data_tmp.txt" ];then
rm -rf /data/second_disk_data_tmp/data_tmp.txt
echo "$(date +%Y-%m-%d-%H:%M) 第二盘硬盘利用率大于80%,已删除临时文件" >> $script_log
fi
fi
fi
}
start_time=$(date +%s)
simulate_memory
simulate_file
start_time=$(date +%s)
#此刻的内存利用率
while true;do
#计算此时内存利用率
mem_info_now=$(free -m | grep Mem)
used_mem_now=$(echo $mem_info_now | awk '{print $3}')
total_mem_now=$(echo $mem_info_now | awk '{print $2}')
# 计算内存利用率
mem_util_now=$(echo "scale=2; $used_mem_now / $total_mem_now * 100" | bc)
mem_utilization_now=$(printf "%.0f" "$mem_util_now")
current_time=$(date +%s)
elapsed_time=$((current_time - start_time))
if [ $mem_utilization_now -ge 80 ];then
for i in $(ps aux | grep "stress --io" | awk '{ print $2}');do kill -9 $i;done
echo "$(date +%Y-%m-%d-%H:%M) 内存利用率大于80%停止stress命令 " >> $script_log
sleep 10
simulate_memory
sleep 10
fi
if [ $elapsed_time -ge 1200 ]; then
break
fi
sleep 10
done
for i in $(ps aux | grep "stress --io" | awk '{ print $2}');do kill -9 $i;done
echo "$(date +%Y-%m-%d-%H:%M) 结束内存压测" >> $script_log
end_time=$(date +%s)
cost_time=$((end_time - start_time))
echo "$(date +%Y-%m-%d-%H:%M) 程序已经运行:$cost_time 秒 并结束" >> $script_log
exit 0
执行效果
cpu
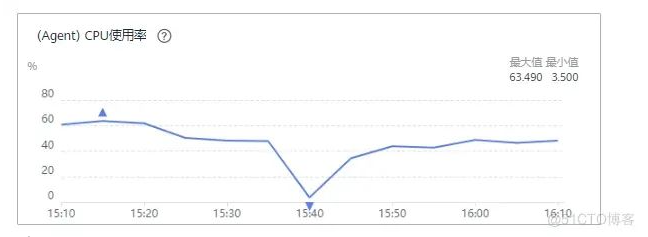
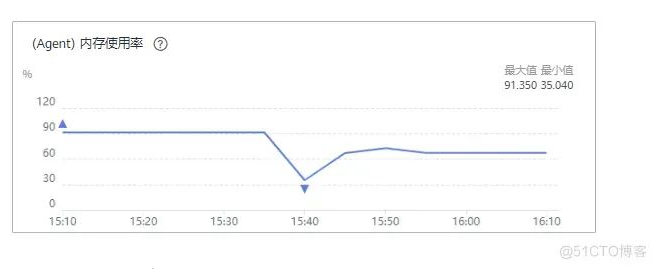
内存
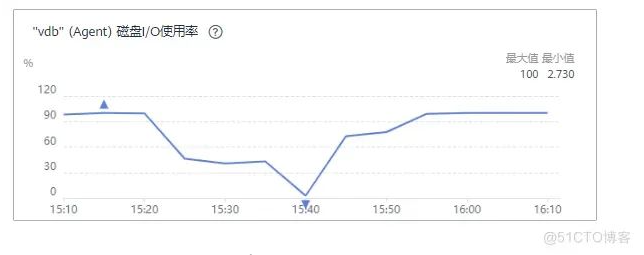
IO
相关问题
1 dd命令执行时间过长,持续将近十几分钟
2 dd执行过程中磁盘IO基本上被占满
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
 阅读进度条
阅读进度条 
-
- 文章 · linux | 2天前 | Linux · 运维排查 · 文件句柄 · ulimit · 服务限制 · Linux 文件句柄 lsof ulimit too many open files LimitNOFILE 服务限制
- Linux 文件句柄耗尽排查工作流:从 ulimit 到服务限制放大
- 482浏览 收藏
-

- 文章 · linux | 2星期前 |
- Linux下禁用su切换用户设置方法
- 187浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 944次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 913次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 845次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1043次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1014次使用
-
- 命令行工具:应对Linux服务器安全挑战的利器
- 2023-10-04 501浏览
-
- 如何使用Docker进行容器的水平伸缩和负载均衡
- 2023-11-07 501浏览
-
- linux .profile的作用是什么
- 2024-04-07 501浏览
-
- 如何解决s权限位引发postfix及crontab异常
- 2024-11-21 501浏览
-
- 如何通过脚本自动化Linux上的K8S安装
- 2025-02-17 501浏览


