MySQL 到 ClickHouse 的高速公路
本篇文章向大家介绍《MySQL 到 ClickHouse 的高速公路》,主要包括MySQL、数据库、clickhouse,具有一定的参考价值,需要的朋友可以参考一下。
2000 年至今,MySQL[1] 一直是全球最受欢迎的 OLTP(联机事务处理)数据库,ClickHouse[2] 则是近年来受到高度关注的 OLAP(联机分析处理)数据库。那么二者之间是否会碰撞出什么火花呢?
本文将带领大家打破异构数据库壁垒,将 MySQL 数据同步至 ClickHouse。对QingCloud MySQL Plus[3] 平台与 MaterializeMySQL[4] 引擎进行了详细介绍,并进一步简述了 HTAP 应用场景。
背景
1、MySQL 复制的发展历程

图 1-1 MySQL 复制的发展历程
图1-1详细罗列了 MySQL 复制的发展历程。
2001 年的 MySQL 3.23 版本就已经支持了同构数据库异步复制;由于是异步复制,根本无法在实际生产中大批量使用。
2013 年 MySQL 5.7.2 版本支持增强半同步复制能力,才勉强算得上是企业级可用的数据同步方案。
2016 年 MySQL 5.7.17 支持了 MGR,并不断地发展成熟,变成了一个金融级别可用的数据同步方案。
而对于同构的 MySQL 数据同步,接下来要做的就是不断地优化体验,提升同步时效性,解决网络异常下的各类问题。
基于此,各大厂商也开始做自己的高可用同步组件。例如 QingCloud MySQL Plus,就具备了真正的强一致性和高可用能力。
2、QingCloud MySQL Plus

图 1-2 MySQL Plus 架构图
图 1-2 中的 Xenon 是由类 Raft 算法来实现的高可用组件,用来管理 MySQL 选举和探活,并订正数据准确性。MySQL 数据同步则依然使用 Semi-Sync Replication 或者 MGR,从而达到数据强一致性、无中心化自动选主且主从秒级切换,以及依托于云的跨区容灾能力。
多副本同步复制,确保金融级强一致性
QingCloud MySQL Plus 采用一主两从的初始节点架构设计,并通过 MySQL 5.7 版本中的 Semi-Sync 特性实现数据的多副本同步复制,确保至少一个从节点与主节点始终保持数据的完全一致,提供金融级数据强一致性。多个从节点的设置将极大地屏蔽掉单点故障带来的影响,确保集群内始终有从节点保有全量数据。
无中心化自动选主且主从秒级切换
节点之间使用 Raft 协议进行管理,当主节点出现故障不可用时,集群会秒级响应并选出新的主节点(与主节点数据完全同步的从节点),立即接管读写请求,确保业务的连续高可用。这一过程,用户完全无需关心后端集群中各节点的角色如何设置,一切由系统自动管理。
跨区容灾能力
可实现多可用区主从部署,具有跨可用区容灾能力,提升数据安全性及容灾能力。
MySQL 有了高可用能力之后,可以通过增加只读实例的方式来增强 AP 能力。但是 MySQL 数据结构和分布方式决定了其 AP 能力相对较弱,那么如何加速 OLAP 查询呢?
ClickHouse 同步 MySQL 数据
为了加速 OLAP 查询,QingCloud MySQL Plus 借用 ClickHouse 来同步 MySQL 数据。
1、ClickHouse 概述
图2-1 ClickHouse 产品图
ClickHouse 是一个用于联机分析 (OLAP) 的列式数据库管理系统 (DBMS)。ClickHouse 构思于 2008 年,最初是为 YandexMetrica(世界第二大Web分析平台)而开发的。多年来一直作为该系统的核心组件被该系统持续使用着,并于 2016 年宣布开源。
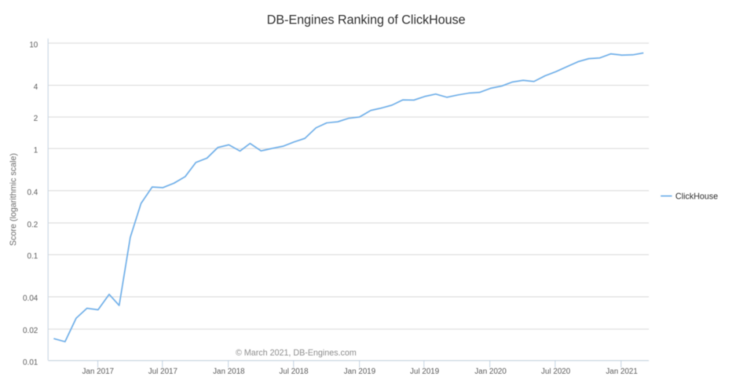
图 2-2 ClickHouse 热度趋势图
从目前最新的 DB-Engines 中可以看到其排名曲线一路高涨,并且各大厂在重要业务上已经大量部署,这是一个很明显的趋势。因此,我们似乎可以认定 ClickHouse 的火热并不只是一时现象,它将长久地存活下去。而且,ClickHouse 灵活的外部表引擎,可轻松实现与 MySQL 的数据同步,接下来让我们了解一下。
2、MySQL Table Engine
MySQL Table Engine 的特性
- Mapping to MySQL table
- Fetch table struct from MySQL
- Fetch data from MySQL when executing query
ClickHouse 最开始支持表级别同步 MySQL 数据,通过外部表引擎 MySQL Table Engine 来实现同 MySQL 表的映射。从 MySQL 的 information_schema 中获取对应表的结构,将其转换为 ClickHouse 支持的数据结构,此时在 ClickHouse 端,表结构建立成功。但是此时,并没有真正去同步数据。只有向 ClickHouse 中的该表发起请求时,才会主动的拉取要同步的 MySQL 表的数据。
MySQL Table Engine 使用起来非常简陋,但它是非常有意义的。因为这是第一次打通 ClickHouse 和 MySQL 的数据通道。但是,缺点异常明显:
- 仅仅是对 MySQL 表关系的映射;
- 查询时传输 MySQL 数据到 ClickHouse,会给 MySQL 可能造成未知的网络压力和读压力,可能影响 MySQL 在生产中正常使用。
基于 MySQL Table Engine 只能映射 MySQL 表关系的缺点,QingCloud ClickHouse 团队实现了MySQL Database Engine。
3、MySQL Database Engine
MySQL Database Engine 的特性
- Mapping to MySQL Database
- Fetch table list from MySQL
- Fetch table struct from MySQL
- Fetch data from MySQL when executing query
MySQL Database Engine 是库级别的映射,依然要从 information_schema 中拉取待同步库中包含的所有 MySQL 表的结构,解决了需要建立多表的问题。但仍然还有和 MySQL Table Engine 一样的缺点:查询时传输 MySQL 数据到 ClickHouse,给 MySQL 可能造成未知的网络压力和读压力,可能影响 MySQL 在生产中正常使用。
4、借用第三方软件同步
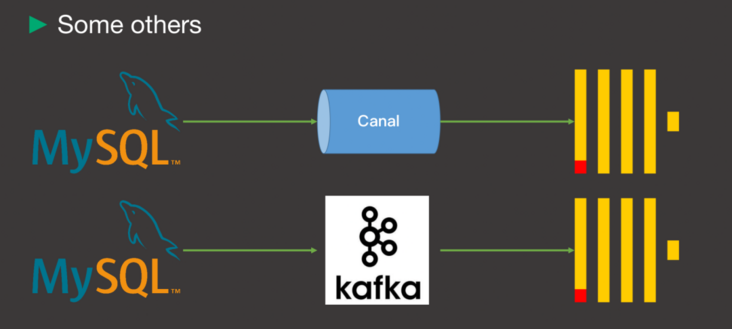
图 2-3 借用第三方软件同步数据
除去上面提到的 MySQL Table Engine 、MySQL Database Engine 两种方式,还有可以采用第三方软件来同步数据,比如 Canal 或者 Kafka,通过解析 MySQL binlog,然后编写程序控制向 ClickHouse 写入。这样做有很大的优势,即同步流程自主可控。但是也带来了额外的问题:
- 增加了数据同步的复杂度。
- 增加了第三方软件,使得运维难度指数级增加。
基于此,我们又可以思考一个问题,ClickHouse 能否主动同步并订阅 MySQL 数据呢?
Materialize MySQL
为了解决 MySQL Database Engine 依然存留的问题,支持 ClickHouse 主动同步并订阅 MySQL 数据,QingCloud ClickHouse 团队自主研发了 MaterializeMySQL 引擎。
1、简述 MaterializeMySQL
MaterializeMySQL 引擎是由 QingCloud ClickHouse 团队自主研发的库引擎,目前作为实验特性合并到 ClickHouse 20.8 版本中,是对 MySQL 库级别关系的映射,通过消费 binlog 存储到 MergeTree 的方式来订阅 MySQL 数据。
CREATE DATABASE test ENGINE = MaterializeMySQL( '172.17.0.3:3306', 'demo', 'root', '123' )
具体使用方式就是一条简单的 CREATE DATABASE SQL 示例:
172.17.0.3:3306 - MySQL 地址和端口
demo - MySQL 库的名称
root - MySQL 同步账户
123 - MySQL 同步账户的密码
2、MaterializeMySQL 的设计思路
- Check MySQL Vars
- Select history data
- Consume new data
MaterializeMySQL 的设计思路如下:
a. 首先检验源端 MySQL 参数是否符合规范。
b. 再将数据根据 GTID 分割为历史数据和增量数据。
c. 同步历史数据至 GTID 点。
d. 持续消费增量数据。
3、MaterializeMySQL 的函数流程
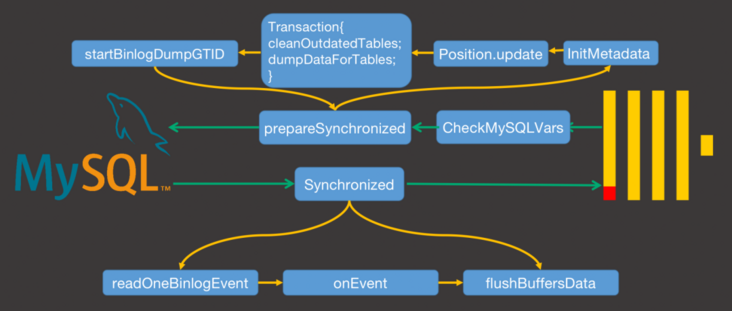
图3-1 MaterializeMySQL 函数流程
如图3-1 所示,MaterializeMySQL 函数的主体流程为:
CheckMySQLVars -> prepareSynchronized -> Synchronized
(1)CheckMySQLVars
检验参数比较简单,就是要查询这些参数是否符合预期。
SHOW VARIABLES WHERE (Variable_name = 'log_bin' AND upper(Value) = 'ON') OR (Variable_name = 'binlog_format' AND upper(Value) = 'ROW') OR (Variable_name = 'binlog_row_image' AND upper(Value) = 'FULL') OR (Variable_name = 'default_authentication_plugin' AND upper(Value) = 'MYSQL_NATIVE_PASSWORD') OR (Variable_name = 'log_bin_use_v1_row_events' AND upper(Value) = 'OFF');
(2)prepareSynchronized
这一步来实现历史数据的拉取。
- 先初始化 gtid 信息。
- 为了保证幂等性每次重新同步时,都要清理 ClickHouse MaterializeMySQL 引擎库下的表。
- 重新拉取历史数据,并将 MySQL 表结构在 ClickHouse 端进行改写。
- 建立与 MySQL 的 Binlog 传输通道。
std::optionalMaterializeMySQLSyncThread::prepareSynchronized() { connection = pool.get(); MaterializeMetadata metadata( connection, DatabaseCatalog::instance().getDatabase(database_name)->getMetadataPath() + "/.metadata", mysql_database_name, opened_transaction); if (!metadata.need_dumping_tables.empty()) { Position position; position.update(metadata.binlog_position, metadata.binlog_file, metadata.executed_gtid_set); metadata.transaction(position, [&]() { cleanOutdatedTables(database_name, global_context); dumpDataForTables(connection, metadata, query_prefix, database_name, mysql_database_name, global_context, [this] { return isCancelled(); }); }); } connection->query("COMMIT").execute(); }
在 MySQL 中,demo 库下有一个表 t ,主键为 ID , 普通列 col_1。
CREATE TABLE demo.t ( id int(11) NOT NULL, col_1 varchar(20) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE = InnoDB;
在 ClickHouse 中,依然是 id 作为主键列,但是,多了隐藏列 _sign 和 _version。
- _sign:值只有 1 和 -1。其中,1 代表这行数据存在,-1 代表这行数据被删除。
- _version:只会读到 version 高的值,会在后台不断合并主键相同的行,最终保留 Version 最高的行。
CREATE TABLE test.t
(
`id` Int32,
`col_1` Nullable(String),
`_sign` Int8 MATERIALIZED 1,
`_version` UInt64 MATERIALIZED 1
)
ENGINE = ReplacingMergeTree(_version)
PARTITION BY intDiv(id, 4294967)
ORDER BY tuple(id)(3)Synchronized
在 prepareSynchronized 中,我们得到了历史数据以及历史数据位点信息,并且获得了与 MySQL 的 Binlog 传输通道。接下来就是从该位点同步增量数据。通过 readOneBinlogEvent 函数读取每一条 binlog 内容,然后使用 onEvent 转换成 ClickHouse 的语句格式即可。最终为了数据安全性,调用 flushBuffersData 函数将数据落盘。
client.connect();
client.startBinlogDumpGTID(randomNumber(), mysql_database_name, metadata.executed_gtid_set, metadata.binlog_checksum);
Buffers buffers(database_name);
while (!isCancelled())
{
BinlogEventPtr binlog_event = client.readOneBinlogEvent(std::max(UInt64(1), max_flush_time - watch.elapsedMilliseconds()));
if (binlog_event)
onEvent(buffers, binlog_event, *metadata);
if (!buffers.data.empty())
flushBuffersData(buffers, *metadata);
}HTAP 应用场景
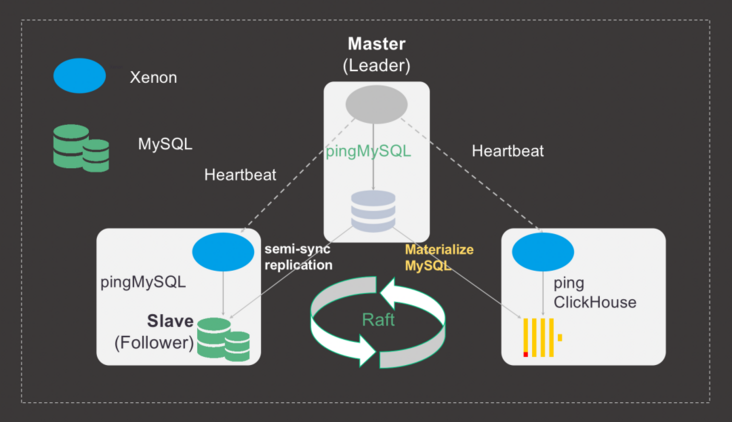
图 4-1 Materialize 实现 HTAP 架构图
当我们打通了 ClickHouse 和 MySQL 的复制通道,而 ClickHouse 的分析能力又是如此让人惊喜,那么我们是不是可以用 MySQL Plus + ClickHouse 实现 HTAP 呢?
在图 4-1 中的架构,依然使用高可用组件 Xenon 来管理 MySQL 复制,同时 Xenon 增加了对 ClickHouse 的监管,通过 MaterializeMySQL 来同步 MySQL 数据。
在之前的 MySQL Plus 架构图中,使用 MySQL 只读实例来进行商务分析、用户画像等分析业务。而现在可以直接将 ClickHouse 作为一个分析实例加入到 MySQL 复制中,替代一部分只读实例进行分析计算。同时 ClickHouse 本身支持了海量函数来支持分析能力的同时还支持标准 SQL,相信可以让使用者享受到很好的体验。
目前的 ClickHouse 可以支持同步 MySQL 5.7 和 8.0 的数据,不支持同步 MySQL 5.6 的数据。不过,作为一个实验特性, MaterializeMySQL 的时间线相当于是 2001 年刚刚支持复制的 MySQL。欢迎大家一起来贡献和维护 MaterializeMySQL。
[1]. MySQL : https://www.mysql.com/
[2]. ClickHouse : https://clickhouse.tech/docs/en/
[3]. MySQL Plus:https://www.qingcloud.com/pro...
[4]. MaterializeMySQL:https://clickhouse.tech/docs/...
以上就是《MySQL 到 ClickHouse 的高速公路》的详细内容,更多关于mysql的资料请关注golang学习网公众号!
 Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
- 上一篇
- Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB

- 下一篇
- 使用Mybatis的TypeHandler加解密数据
-

- 凶狠的鸭子
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享技术文章!
- 2023-06-03 02:49:44
-
- 甜蜜的手链
- 这篇技术文章出现的刚刚好,好细啊,太给力了,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-02-02 02:49:37







-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 5948次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6371次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6181次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8157次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 6760次使用
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- 搞一个自娱自乐的博客(二) 架构搭建
- 2023-02-16 244浏览
-
- B-Tree、B+Tree以及B-link Tree
- 2023-01-19 235浏览
-
- mysql面试题
- 2023-01-17 157浏览
-
- MySQL数据表简单查询
- 2023-01-10 101浏览


