MySQL-Seconds_behind_master 的精度误差
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《MySQL-Seconds_behind_master 的精度误差》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下MySQL,希望所有认真读完的童鞋们,都有实质性的提高。
前言
Seconds_behind_master 是我们观察主从延迟的一个重要指标。但任何指标所能表示的精度都是有限的。例如用精度只能到秒的指标去衡量毫秒级的表现就会产生非常大的误差。如果再以此误差去分析问题,就会让思维走上弯路。例如用 Seconds_behind_master 去评估 1s 内的主从延迟就是一个典型的例子。
问题现场
在一些问题的排查中,我们注意到一个很奇怪的现象。那就是相同配置的从库表现出来的主从延迟差距有将近 500ms。而这两个从库之间的差别就是所在的机房不一样 (和主库都不在同一个机房)。如下图所示:
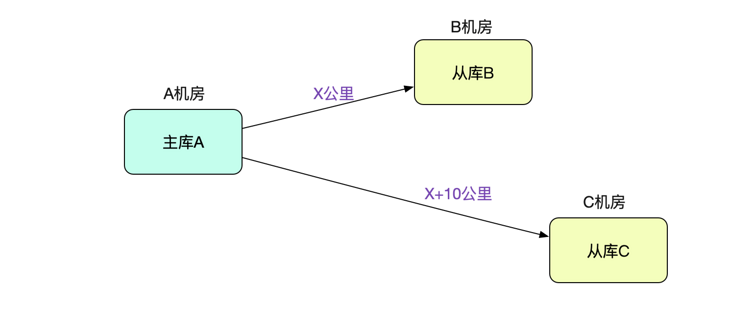
网络问题
难道是网络问题?那我们 ping 一下吧,最多也就相差 1ms。那么还有 499ms 去哪里了呢,看来还得继续挖掘。
Seconds_behind_master 的取点数据
直觉上来说网络问题不可能导致 500ms 这么大的误差,而机器配置和 MySQL 版本又是一样的。这就让笔者不得不怀疑这个兼容数据的准确性。所以就先看看这个 500ms 是怎么计算出来的。
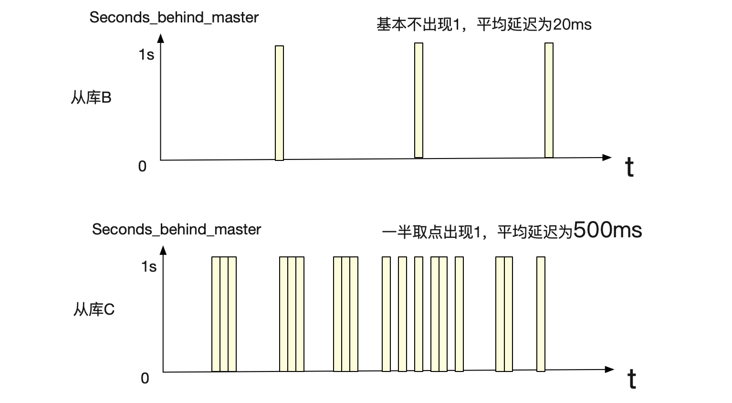
从监控取点数据来看从库 C 确实有主从延迟,不然为什么有那么多取点为 0 呢。
Seconds_behind_master 什么时候计算出来为 1
这时候笔者突然想到一个点,如果主从延迟一个是 501ms 一个是 499ms,那么 Seconds_behind_master 计算的时候会不会采用四舍五入法。501ms (>=500ms) 的就是 1,499 (
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp)
- mi->clock_diff_with_master);前面 time (0) - mi->rli->last_master_timestamp 明显就是指时间差。但是,我们要考虑到一个很容易被忽略的常识,也就是不同机器的时间戳是不一样的!
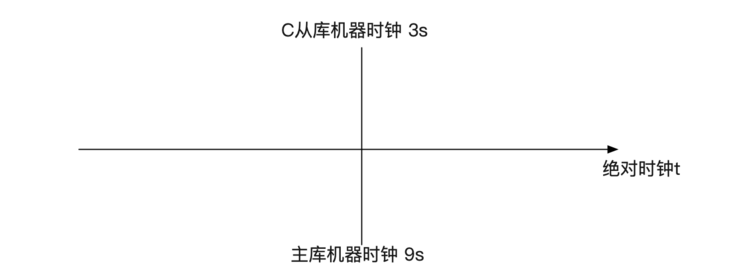
那么很明显的,如果主从实际延迟是 0,但是计算的时候没有剔除掉机器时钟的差异。那么主从延迟就是 6s。源码中的 mi->clock_diff_with_master 就是去修正这个差距!而计算这个 clock_diff_with_master 就会引起不小的误差。
什么时候计算 clock_diff_with_master
笔者在源码中翻阅时候注意到 clock_diff_with_master 不是每次都去计算的,而是在主从连接上或者重连 (reconnect) 的那一刻去计算一次。
handle_slave_io
/* 建立主从连接 */
|->safe_connect(thd, mysql, mi))
/* connected: 主从连接成功后,计算一下主从clock_diff_with_master */
|->get_master_version_and_clock 这就自然会导致下面的现象,假设一旦 clock_diff_with_master 计算有了误差。那么这个误差就会一直存在,直到下次重连为止!
clock_diff_with_master 跨秒误差
接着笔者又注意到 clock_diff_with_master 精度只能到秒。那么自然就会出现下面这几种现象。为了简单起见,我们假设绝对时钟是从 0 开始,而且我们假设主从延迟是 0。只看精度误差所能造成的影响。
在实际主从延迟为 0 的情况下 clock_diff_with_master 计算出来是 - 1,Seconds_behind_master 计算为 1
尽管有 NTP,我们也不可能做到两台机器的时间戳在完全一致 (除非两台机器有铯原子钟,那基本就没有毫秒级的误差了)。两台机器之间出现几百毫秒甚至数秒的延迟非常正常。例如假设我当前从库的 clock 是 0.5s,主库的 clock 是 1s。那么由于计算精度 (只能到秒) 的原因,实际实际只有 0.5s 的时间差会放大到 1s。

那么我们现在可以计算出来在这种情况下 Seconds_behind_master 的平均值,在这里有一个预先假设就是我们取监控点的时间是随机的。
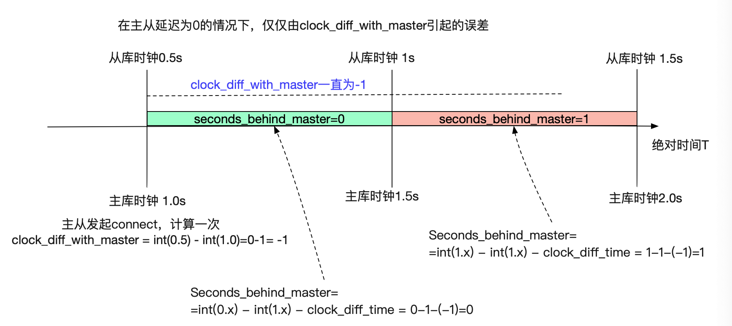
在上图中我们可以看到,在我们取从库时钟 [0.5,1.5) 这个 1s 的时间段范围内。在前 0.5s,也就是 [0.5,1) 这个区间中我们计算出来的 Seconds_behind_master 是 0,而在 [1,1.5) 区间计算的确是 1 。那我们的平均值就可以计算出来为 (0.50+0.51)/(1.5-0.5)=0.5=500ms!
也就是说,在没有任何实际主从延迟的情况下,仅仅跨秒这一个因素就能造成好几百毫秒的误差。
实际主从延迟为 0 的情况下 clock_diff_with_master 计算为 0,Seconds_behind_master 计算为 - 1 并被校正为 0
另外一个有意思的点是,既然误差能加 1,自然也能减 1。也就是 Seconds_behind_master 计算为 - 1。这就会给观察人员造成一个错觉,从库比主库快!当然了 MySQL 源码考虑到了这一点,强制校正为 0。
在这里,笔者将主从连接的那一刻稍微往前偏移 0.1s,就可以构造出刚才说的现象,如下图所示:

MySQL 中的源码注释和强行校正逻辑如下所示:
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp) - mi->clock_diff_with_master); /* Apparently on some systems time_diff can be last_master_timestamp is 0 (i.e. they are in the same second), then we get 0-(2-1)=-1 as a result. This confuses users, so we don't go below 0: hence the max(). last_master_timestamp == 0 (an "impossible" timestamp 1970) is a special marker to say "consider we have caught up". */ protocol->store((longlong)(mi->rli->last_master_timestamp ? max(0L, time_diff) : 0));
如何获得精确的毫秒级的主从延迟
由于 Seconds_behind_master 精度的原因,完全无法衡量毫秒级的主从延迟,所以出现了 pt-heartbeat 这样的工具去精确的计算主从间毫秒级的延迟。在后续采用 pt-heartbeat 对两个库进行监控后,这两个看上去平均延迟相差 500ms 的从库实际主从延迟差距在 10ms 之内。
总结
任何指标都有其表示的精度,而在其精度表示范围之外就会产生相当大的误差,以至于能够误导我们的判断。当对某一项的指标感到很反常识的时候,可以考虑是不是本身指标并不能描述当前我们想要观察的现象。例如本文中的阐述就表明 Seconds_behind_master 对 1s 的主从延迟的刻画没有太大的意义。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于数据库的相关知识,也可关注golang学习网公众号。
 超强讲师阵容!7天0元带你学完MySQL基础架构、SQL性能调优、MGR!
超强讲师阵容!7天0元带你学完MySQL基础架构、SQL性能调优、MGR!
- 上一篇
- 超强讲师阵容!7天0元带你学完MySQL基础架构、SQL性能调优、MGR!

- 下一篇
- yum安装MySQL
-

- 欢喜的钢铁侠
- 这篇文章内容真及时,太全面了,很有用,码起来,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-07-02 17:25:56
-
- 开放的铃铛
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢师傅分享文章!
- 2023-06-01 07:42:26







-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 6078次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 6496次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6304次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8271次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 6906次使用
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- 搞一个自娱自乐的博客(二) 架构搭建
- 2023-02-16 244浏览
-
- B-Tree、B+Tree以及B-link Tree
- 2023-01-19 235浏览
-
- mysql面试题
- 2023-01-17 157浏览
-
- MySQL数据表简单查询
- 2023-01-10 101浏览


