这才是真・开源模型!公开「后训练」一切,性能超越Llama 3.1 Instruct
在IT行业这个发展更新速度很快的行业,只有不停止的学习,才不会被行业所淘汰。如果你是科技周边学习者,那么本文《这才是真・开源模型!公开「后训练」一切,性能超越Llama 3.1 Instruct》就很适合你!本篇内容主要包括##content_title##,希望对大家的知识积累有所帮助,助力实战开发!
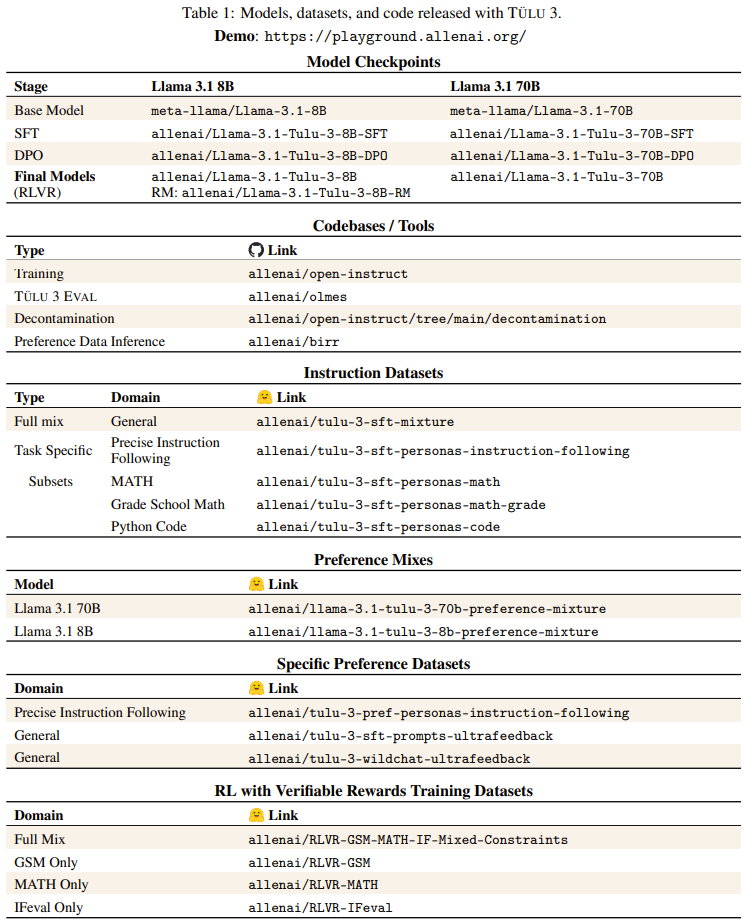
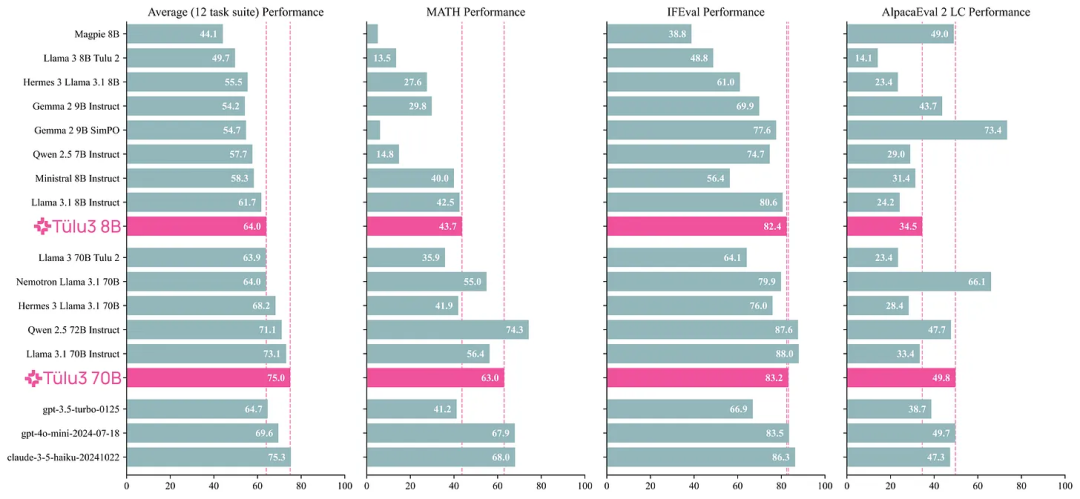
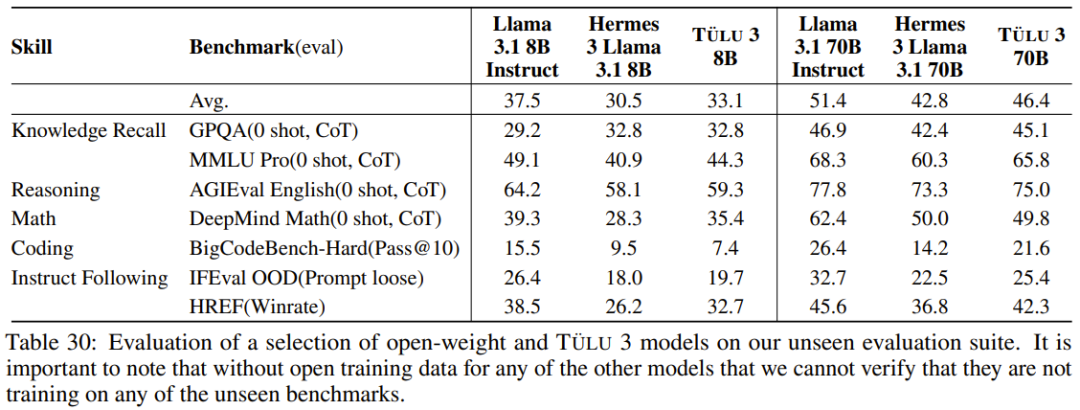
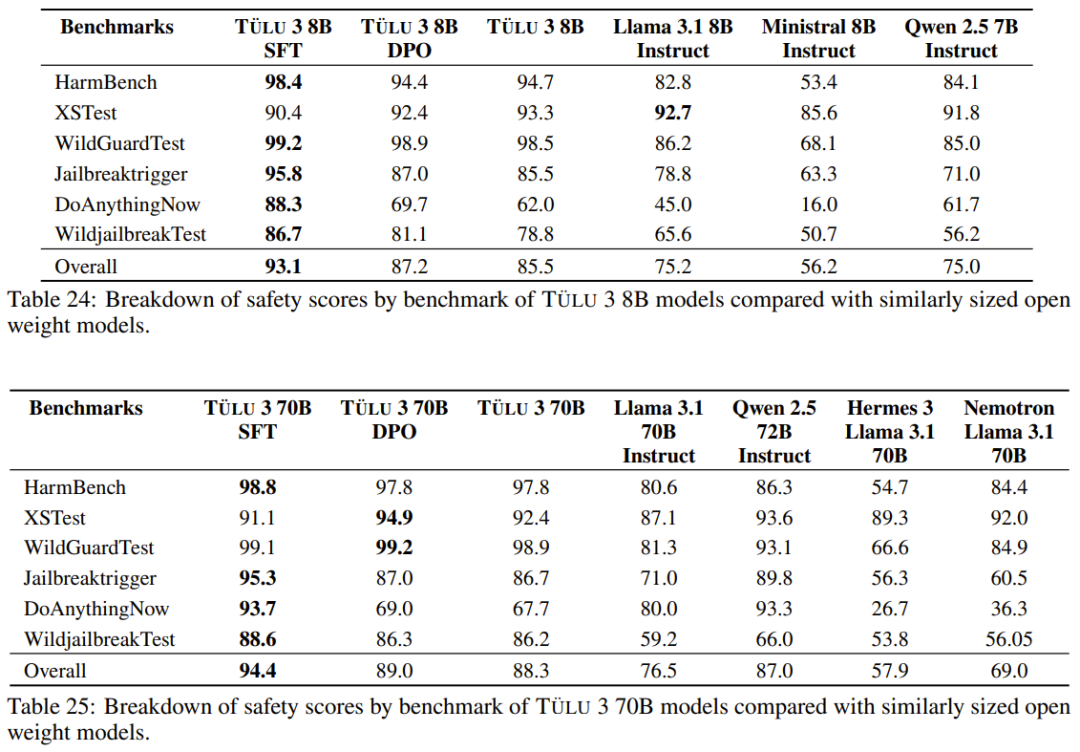
开源模型阵营又迎来一员猛将:Tülu 3。它来自艾伦人工智能研究所(Ai2),目前包含 8B 和 70B 两个版本(未来还会有 405B 版本),并且其性能超过了 Llama 3.1 Instruct 的相应版本!长达 73 的技术报告详细介绍了后训练的细节。
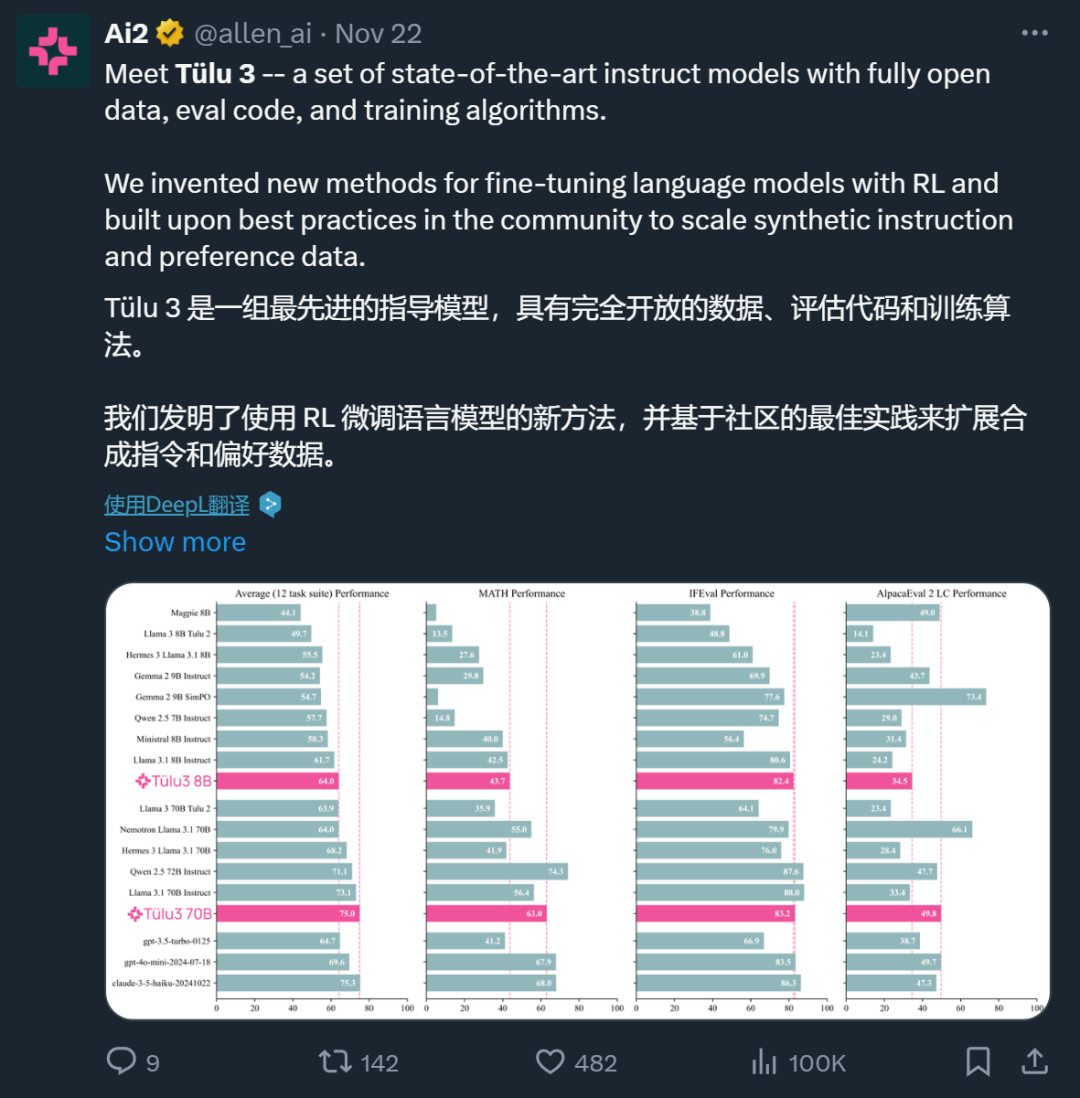
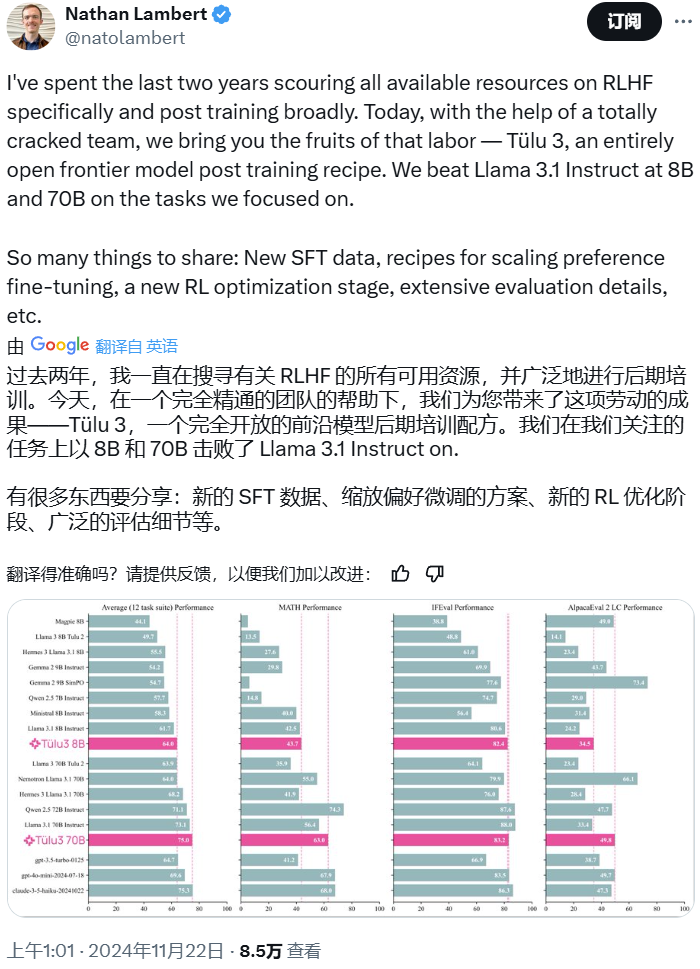


模型:https://huggingface.co/allenai
技术报告:https://allenai.org/papers/tulu-3-report.pdf
数据集:https://huggingface.co/collections/allenai/tulu-3-datasets-673b8df14442393f7213f372
GitHub:https://github.com/allenai/open-instruct
Demo:https://playground.allenai.org/
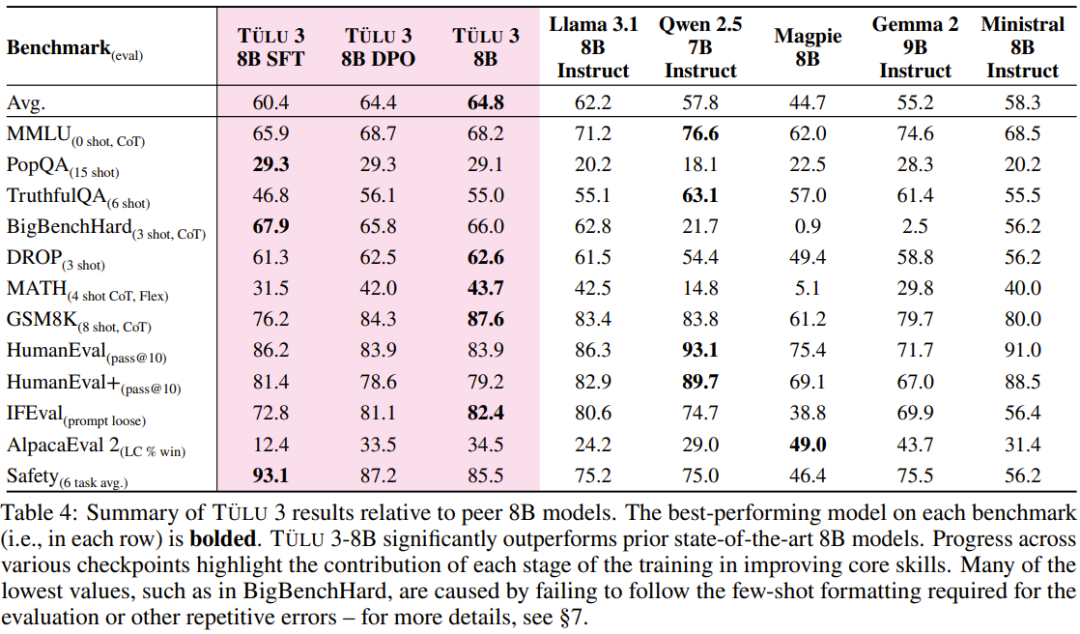
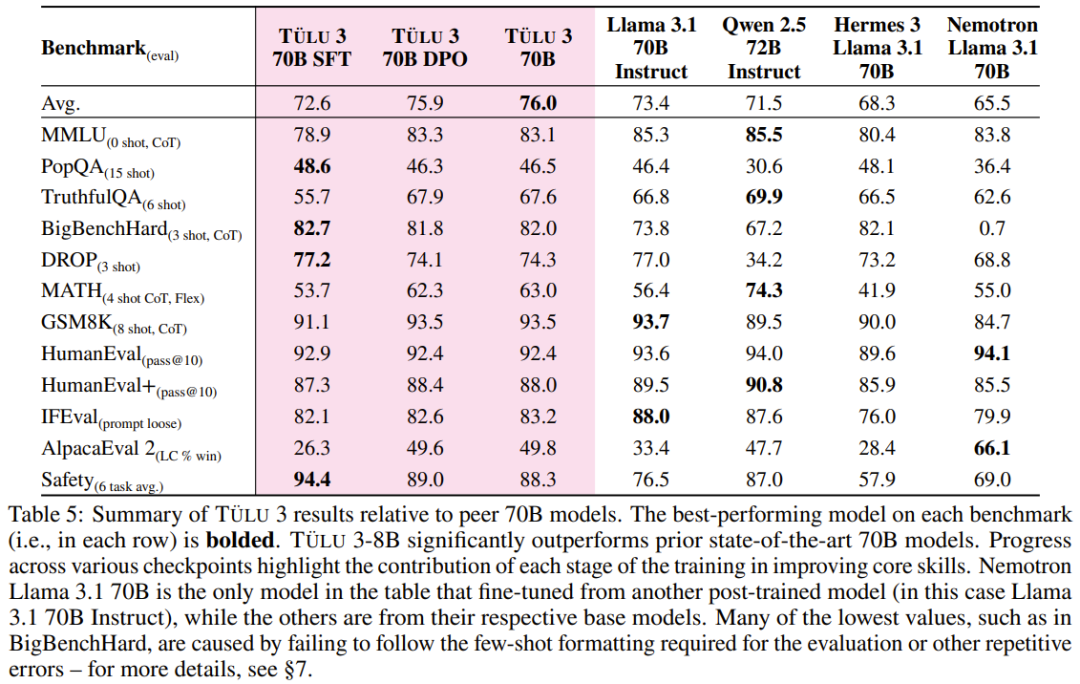
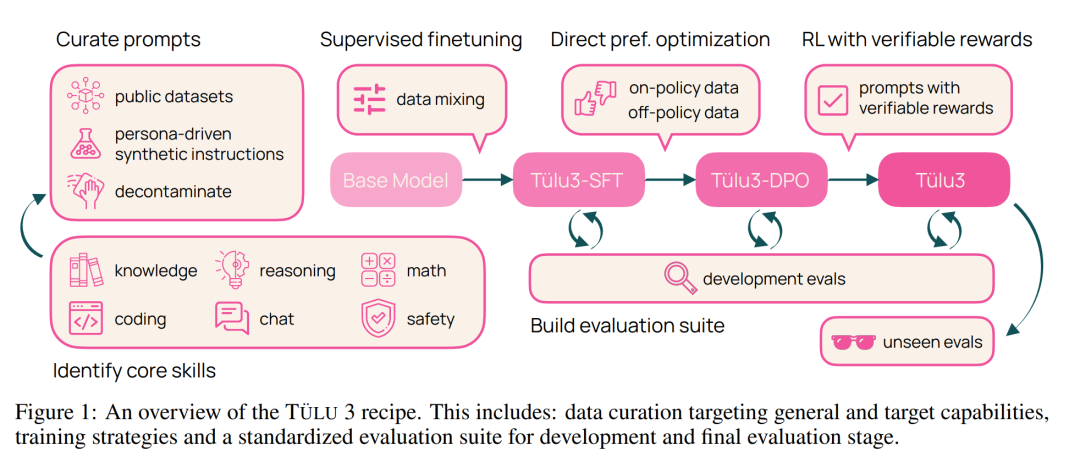
阶段一:数据整理。Ai2 整理了各种提示(prompt)信息,并将其分配到多个优化阶段。他们创建了新的合成提示,或在可用的情况下,从现有数据集中获取提示,以针对特定能力。他们确保了提示不受评估套件 Tülu 3 EVAL 的污染。
阶段二:监督微调。Ai2 利用精心挑选的提示和回答结果进行监督微调(SFT)。在评估框架指导下,他们通过全面的实验,确定最终的 SFT 数据和训练超参数,以增强目标核心技能,同时不对其他技能的性能产生重大影响。
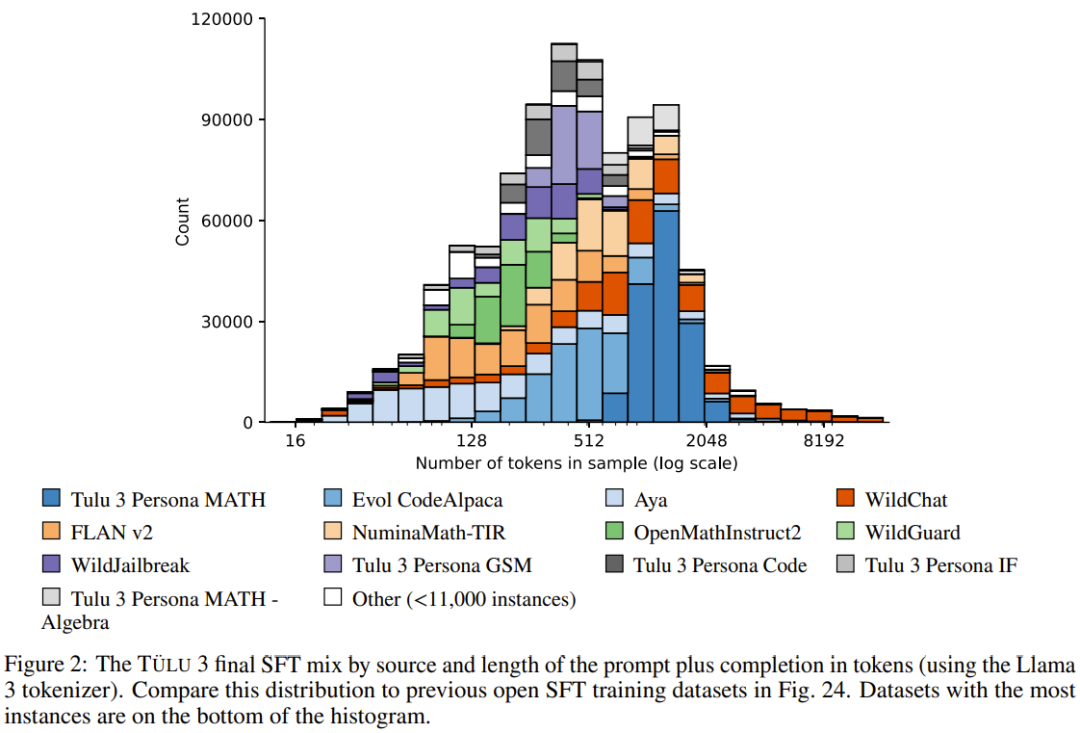
阶段三:偏好微调。Ai2 将偏好微调 —— 特别是 DPO(直接偏好优化)—— 应用于根据选定的提示和 off-policy 数据构建的新 on-policy 合成偏好数据。与 SFT 阶段一样,他们通过全面的实验来确定最佳偏好数据组合,从而发现哪些数据格式、方法或超参数可带来改进。
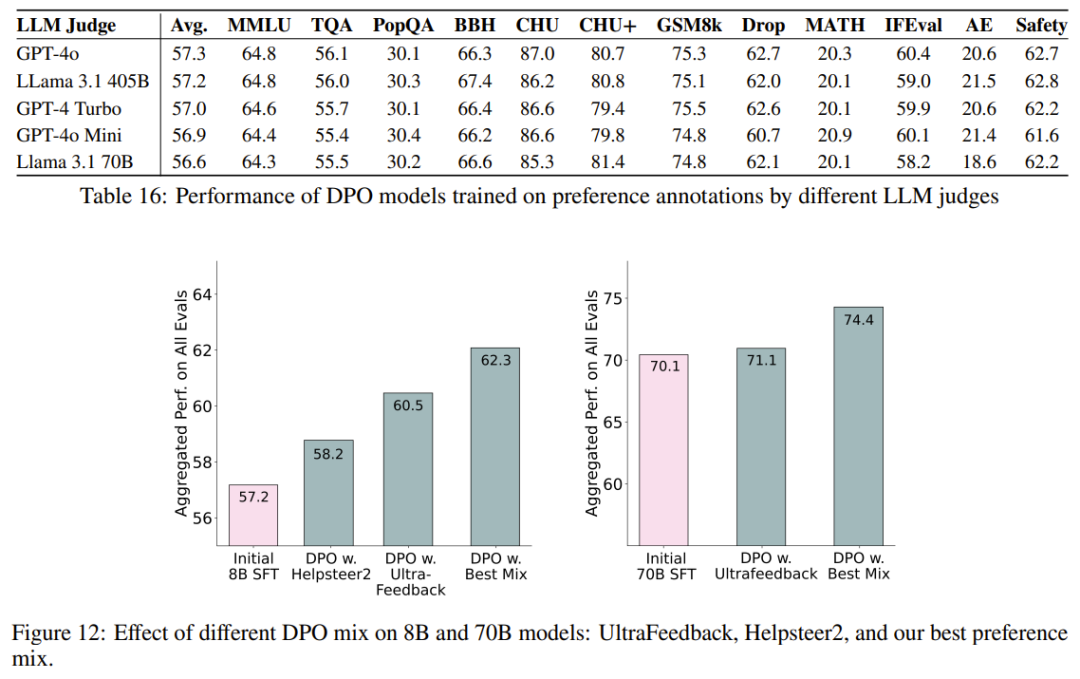
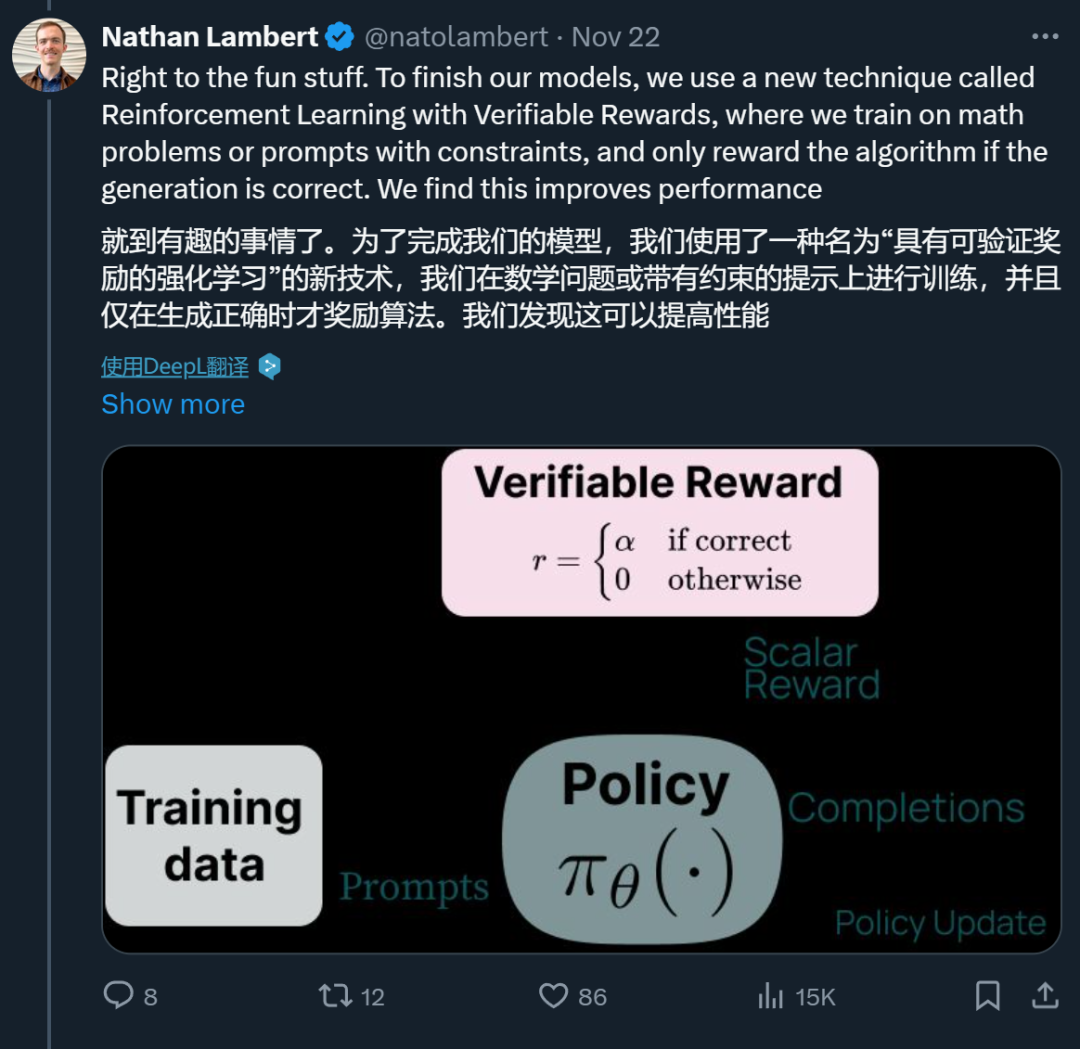
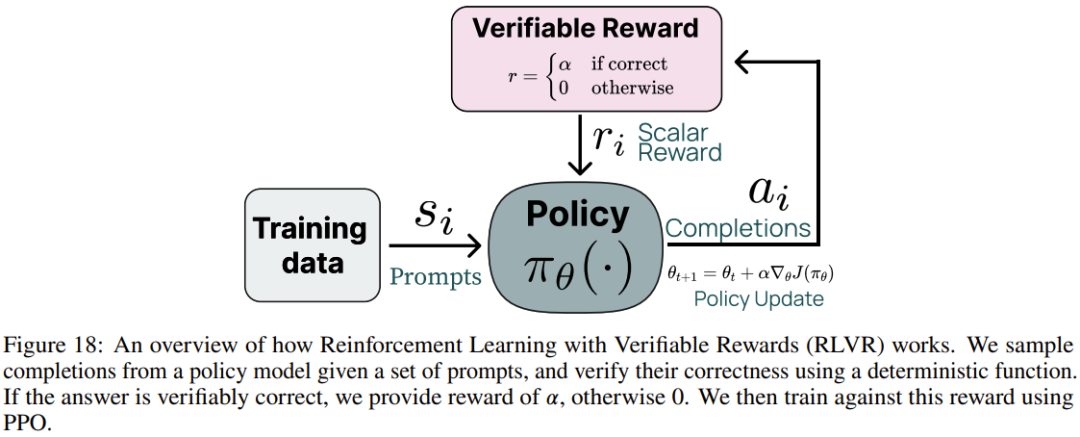
阶段四:具有可验证奖励的强化学习。Ai2 引入了一个新的基于强化学习的后训练阶段,该阶段通过可验证奖励(而不是传统 RLHF PPO 训练中常见的奖励模型)来训练模型。他们选择了结果可验证的任务,例如数学问题,并且只有当模型的生成被验证为正确时才提供奖励。然后,他们基于这些奖励进行强化学习训练。
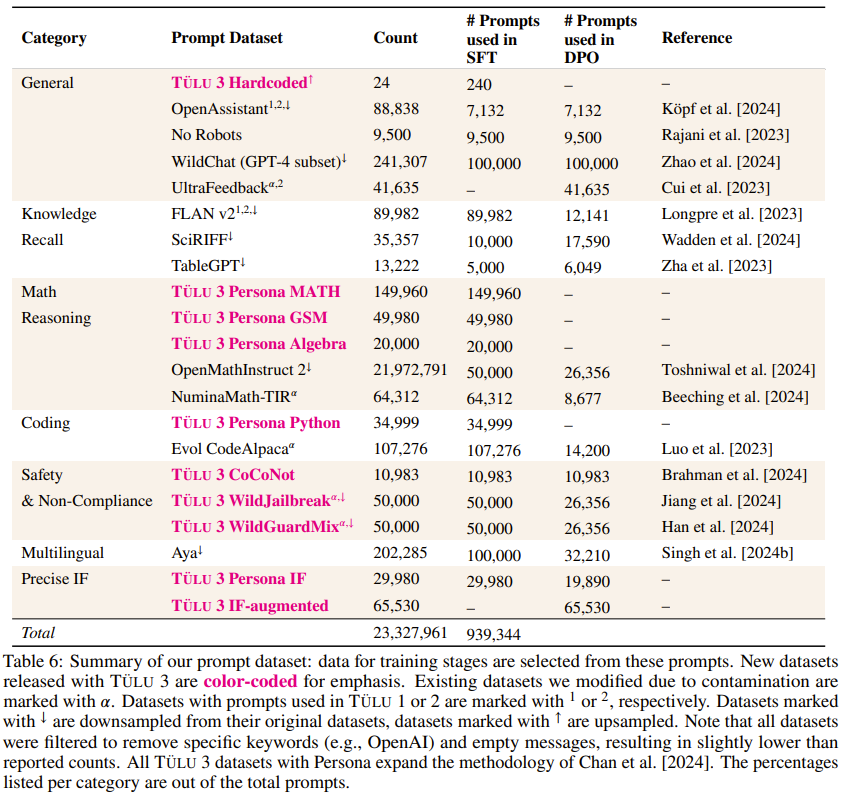
数据质量、出处和规模:Ai2 通过仔细调查可用的开源数据集、分析其出处、净化来获取提示,并针对核心技能策划合成提示。为确保有效性,他们进行了全面的实验,研究它们对评估套件的影响。他们发现有针对性的提示对提高核心技能很有影响,而真实世界的查询(如 WildChat)对提高通用聊天能力很重要。利用 Tülu 3 EVAL 净化工具,他们可以确保提示不会污染评估套件。
创建多技能 SFT 数据集。通过利用不同数据混合结果进行几轮有监督微调,Ai2 优化了「通用」和「特定技能」类别中提示的分布。例如,为了提高数学推理能力,Ai2 首先通过创建数学专业模型在评估套件中建立一个上限,然后混合数据,使通用模型更接近这个上限。
编排一个 On-Policy 偏好数据集。Ai2 开发了一个 on-policy 数据编排 pipeline,以扩展偏好数据集生成。具体来说,他们根据给定的提示从 Tülu 3-SFT 和其他模型中生成完成结果,并通过成对比较获得偏好标签。他们的方法扩展并改进了 Cui et al. [2023] 提出的 off-policy 偏好数据生成方法。通过对偏好数据进行精心的多技能选择,他们获得了 354192 个用于偏好调整的实例,展示了一系列任务的显着改进。
偏好调整算法设计。Ai2 对几种偏好调整算法进行了实验,观察到使用长度归一化( length-normalized)直接偏好优化的性能有所提高。他们在实验中优先考虑了简单性和效率,并在整个开发过程和最终模型训练中使用了长度归一化直接偏好优化算法,而不是对基于 PPO 的方法进行成本更高的研究。
具有可验证奖励的特定技能强化学习。Ai2 采用了一种新方法,利用标准强化学习范式,针对可以对照真实结果(如数学)进行评估的技能进行强化学习。他们将这种算法称为「可验证奖励强化学习」(RLVR)。结果表明,RLVR 可以提高模型在 GSM8K、MATH 和 IFEval 上的性能。
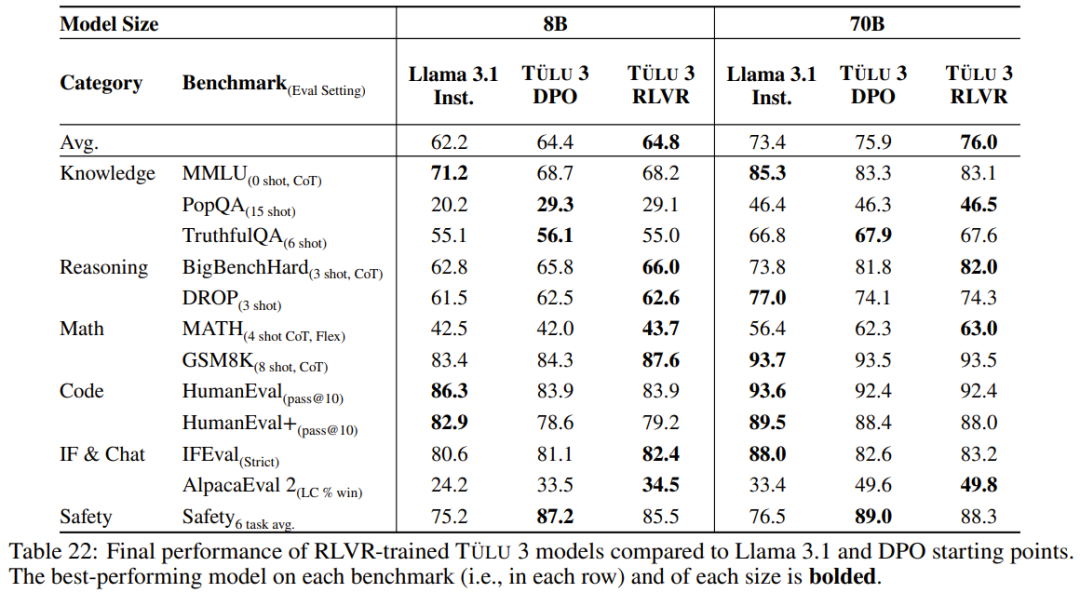
用于强化学习的训练基础设施。Ai2 实现了一种异步式强化学习设置:通过 vLLM 高效地运行 LLM 推理,而学习器还会同时执行梯度更新。并且 Ai2 还表示他们的强化学习代码库的扩展性能非常好,可用于训练 70B RLVR 策略模型。
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 Vue中van-calendar组件重绘问题:如何避免第三方组件因Vue重绘而重新渲染?
Vue中van-calendar组件重绘问题:如何避免第三方组件因Vue重绘而重新渲染?
- 上一篇
- Vue中van-calendar组件重绘问题:如何避免第三方组件因Vue重绘而重新渲染?

- 下一篇
- 深入解析亚马逊平板电脑:功能、优势与购买指南
-

- 科技周边 · 人工智能 | 2星期前 | AI绘画
- AI绘画工具安装与配置教程
- 339浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- 海螺AI语音功能测评与体验分享
- 260浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- ChatGPT读不了加密PDF?先解密再上传
- 438浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- 千问AI测试规范与覆盖率提升技巧
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- MiniMaxMusic2.0专业模式上线:音乐创作新神器
- 232浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 25次使用
-

- MeloLab
- MeloLab 是一款 AI 音乐生成工具,可根据文本创意生成歌曲、人声、混音、分轨和背景音乐,适合创作者快速制作音乐素材。
- 23次使用
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8670次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9083次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8912次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


