使用 Python 抓取佐治亚州亚特兰大律师数据的技术指南
亲爱的编程学习爱好者,如果你点开了这篇文章,说明你对《使用 Python 抓取佐治亚州亚特兰大律师数据的技术指南》很感兴趣。本篇文章就来给大家详细解析一下,主要介绍一下,希望所有认真读完的童鞋们,都有实质性的提高。

在本指南中,我们将探讨如何使用 python 从法律网站上抓取律师数据,重点关注佐治亚州亚特兰大的律师。这些信息对于那些想要寻找律师、研究律师事务所或收集附近律师数据的人来说非常有价值。我们将使用流行的 python 库创建一个强大的抓取工具,可以帮助您收集亚特兰大地区律师的信息。
先决条件
在我们开始之前,请确保您已安装以下软件:
- python 3.x
- pip(python 包安装程序)
您需要安装这些库:
pip install requests lxml csv
设置刮刀
首先,让我们导入必要的库并设置标头和 cookie:
from lxml import html
import os
import csv
import requests
cookies = {
‘optanonalertboxclosed’: ‘2024–08–29t14:38:29.268z’,
‘_ga’: ‘ga1.2.1382693123.1724942310’,
‘_gid’: ‘ga1.2.373246331.1724942310’,
‘_gat’: ‘1’,
‘optanonconsent’: ‘isiabglobal=false&datestamp=fri+aug+30+2024+00%3a17%3a14+gmt%2b0600+(bangladesh+standard+time)&version=5.9.0&landingpath=notlandingpage&groups=0_106263%3a1%2c0_116595%3a1%2c0_104533%3a1%2c101%3a1%2c1%3a1%2c0_116597%3a1%2c103%3a1%2c104%3a1%2c102%3a1%2c3%3a1%2c0_104532%3a1%2c2%3a1%2c4%3a1&awaitingreconsent=false’,
‘_ga_jhnlz3fy7v’: ‘gs1.2.1724954588.3.1.1724955436.0.0.0’,
}
headers = {
‘accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7’,
‘accept-language’: ‘en-us,en;q=0.9,bn;q=0.8’,
‘cache-control’: ‘no-cache’,
‘dnt’: ‘1’,
‘pragma’: ‘no-cache’,
‘sec-ch-ua’: ‘“chromium”;v=”128", “not;a=brand”;v=”24", “google chrome”;v=”128"’,
‘sec-ch-ua-mobile’: ‘?0’,
‘sec-ch-ua-platform’: ‘“windows”’,
‘sec-fetch-dest’: ‘document’,
‘sec-fetch-mode’: ‘navigate’,
‘sec-fetch-site’: ‘cross-site’,
‘sec-fetch-user’: ‘?1’,
‘upgrade-insecure-requests’: ‘1’,
‘user-agent’: ‘mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/128.0.0.0 safari/537.36’,
}
提出请求
现在,让我们向网站发出请求以获取律师数据:
response = requests.get( ‘https://www.kslaw.com/people?capability_id=&locale=en&office_id=1&page=1&per_page=400&q=&school_id=&starts_with=&title_id', cookies=cookies, headers=headers, )
解析 html
我们将使用 lxml 来解析 html 内容:
webp = html.fromstring(response.content) all_people_elems = webp.xpath(“//*[@id=’people_grid’]/div[@class=’person’]”)
将数据保存到 csv
让我们创建一个函数来将抓取的数据保存到 csv 文件中:
def save_csv(filename, data_list, isfirst=false, removeatstarting=true):
“””save data to csv file”””
if isfirst:
if os.path.isfile(filename):
if removeatstarting:
os.remove(filename)
else:
pass
with open(f’{filename}’, “a”, newline=’’, encoding=’utf-8-sig’) as fp:
wr = csv.writer(fp, dialect=’excel’)
wr.writerow(data_list)
# initialize the csv file
people_file = f”kslaw_people.csv”
save_csv(people_file, [‘url’, ‘name’, ‘status’, ‘fax’, ‘telephone’, ‘email’, ‘address’], isfirst=true)
提取律师数据
现在,让我们循环遍历律师元素并提取相关信息:
for each_people in all_people_elems:
name = each_people.xpath(“.//h2/a/text()”)[0]
href = each_people.xpath(“.//h2/a/@href”)[0]
full_url = f”https://www.kslaw.com{href}" if href else “URL not found”
status = each_people.xpath(“.//p/text()”)[0].strip()
fax = ‘ — ‘
address = ‘ — ‘
# Extract the Atlanta telephone number
phone_numbers = each_people.xpath(“.//p[@class=’contacts’]/a[starts-with(@href, ‘tel:’)]/text()”)
phone_numbers = [phone.strip() for phone in phone_numbers]
phone_numbers_str = ‘, ‘.join(phone_numbers) if phone_numbers else “Phone numbers not found”
# Extract the email address
email = each_people.xpath(“.//p[@class=’contacts’]/a[contains(@href, ‘mailto:’)]/text()”)
email = email[0].strip() if email else “Email not found”
data_list = [full_url, name, status, fax, phone_numbers_str, email, address]
save_csv(people_file, data_list)
print(data_list)
结论
此 python 脚本允许您从特定法律网站抓取律师数据,重点关注佐治亚州亚特兰大的律师。通过运行此脚本,您可以快速编制律师事务所列表并找到附近的律师。对于那些希望与律师联系或对亚特兰大法律环境进行研究的人来说,这些数据非常宝贵。
请记住负责任地使用这些数据,并遵守网站的服务条款和相关法律。始终尊重您所收集数据的个人的隐私。
对于那些寻求寻找律师或研究律师事务所的人来说,这些抓取的数据可以提供一个起点。然而,重要的是通过额外的研究来补充这些信息,例如阅读评论、检查律师协会记录以及亲自联系律师以确保他们适合您的法律需求。
通过利用python和网络抓取技术,您可以有效地收集佐治亚州亚特兰大律师的信息,简化在法律领域寻找法律代表或进行市场研究的过程。
准备好提升您的网络形象了吗?
我专注于构建适合您独特需求的响应式 react.js web 应用程序。让我们将您的愿景变为现实!
在 fiverr 上雇用我 →
文中关于的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《使用 Python 抓取佐治亚州亚特兰大律师数据的技术指南》文章吧,也可关注golang学习网公众号了解相关技术文章。
 Golang 反射:创建具有指针字段的对象
Golang 反射:创建具有指针字段的对象
- 上一篇
- Golang 反射:创建具有指针字段的对象

- 下一篇
- PHP 函数版本更新指南:安全考虑因素
-
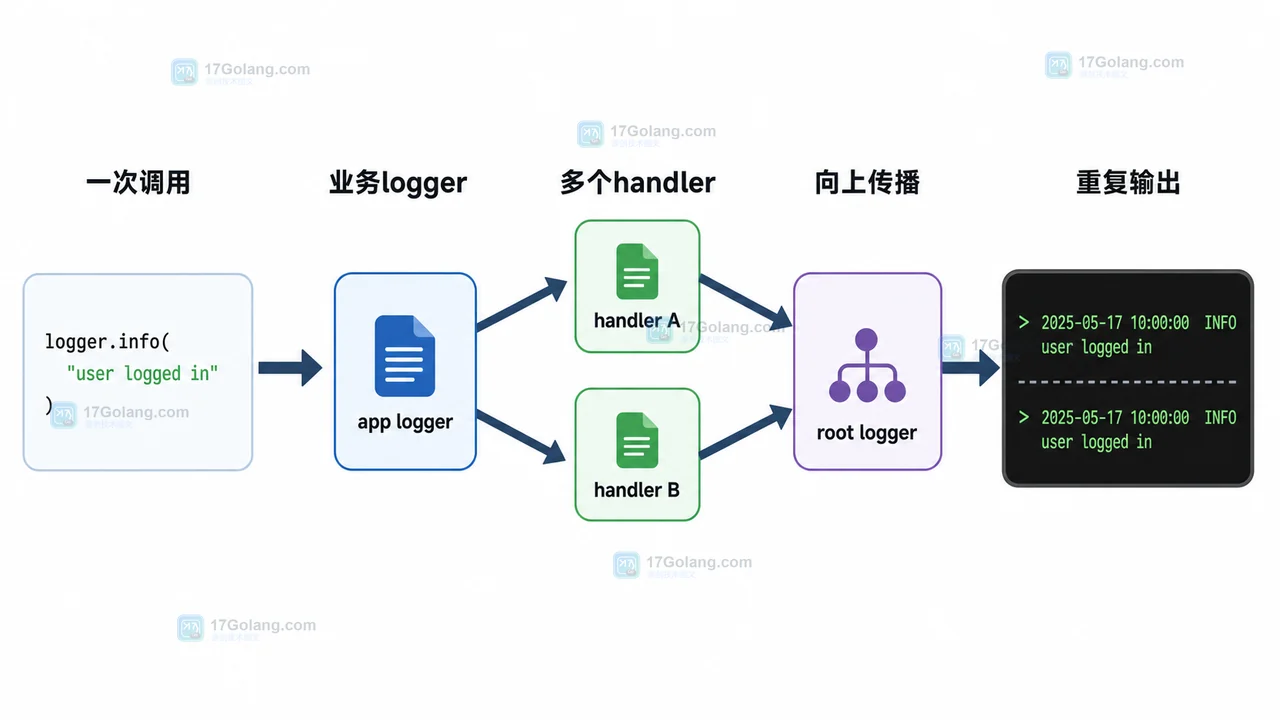
- 文章 · python教程 | 2天前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig
- Python logging 日志重复打印排查:为什么一条记录输出了两遍
- 324浏览 收藏
-

- 文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory
- Python dataclass 默认值完整工作流:从可变默认值到 default_factory
- 228浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2958次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2731次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2668次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2897次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2847次使用
-
- Python监控网页状态:requests异常处理实战
- 2026-05-29 501浏览
-
- TensorFlow模型部署为API的TF Serving方法
- 2026-05-26 501浏览
-
- Python字符串编码转换:encode与decode详解
- 2026-05-16 501浏览
-
- TensorFlow裁剪无用算子方法详解
- 2026-05-15 501浏览
-
- httpx 如何设置代理认证(Proxy-Authorization)
- 2026-05-05 501浏览


