Go语言纯文本文件的读写操作
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个Golang开发实战,手把手教大家学习《Go语言纯文本文件的读写操作》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
对于纯文本文件,我们必须创建自定义的格式,理想的格式应该易于解析和扩展。下面是某单个发票以自定义纯文本格式存储的数据。
INVOICE ID=5441 CUSTOMER=960 RAISED=2012-09-06 DUE=2012-10-06 PAID=true
ITEM ID=BE9066 PRICE=400.89 QUANTITY=7: Keep out of
ITEM ID=AM7240 PRICE=183.69 QUANTITY=2
ITEM ID=PT9110 PRICE=105.40 QUANTITY=3: Flammable
写纯文本文件
由于 Go语言的 fmt 包中打印函数强大而灵活,写纯文本数据非常简单直接。type TxtMarshaler struct{}func (TxtMarshaler) Marshallnvoices(writer io.Writer, invoices []*Invoice) error { bufferedWriter := bufio.NewWriter(writer) defer bufferedWriter.Flush() var write writerFunc = func (format string, args...interface{}) error { _, err := fmt.Fprintf(bufferedWriter, format, args ...) return err } if err := write("%s %d", fileType, fileVersion); err != nil { return err } for invoice := range invoices { if err := write.Writeinvoice(invoice); err != nil { return err } } return nil}该方法在开始处创建了一个带缓冲区的 writer,用于操作所传入的文件。延迟执行刷新缓冲区的操作是必要的,这可以保证我们缩写的数据确实能够写入文件(除非发生错误)。
与以 if _,err := fmt.Fprintf(bufferedWriter,...); err != nil {return err} 的形式来检查每次写操作不同的是,我们创建了一个函数字面量来做两方面的简化。第该 writer() 函数会忽略 fmt.Fprintf() 函数报告的所写字节数。其次,该函数处理了 bufferedWriter,因此我们不必在自己的代码中显式地提到。
我们本可以将 write() 函数传给辅助函数的,例如,writeinvoice(write, invoice)。但不同于此做法的是,我们往前更进了一步,将该方法添加到 writerFunc 类型中。
这是通过声明接受一个 writerFunc 值作为其接收器的方法(即函数)来达到,跟定义任何其他类型一样。这样就允许我们以 write.writeinvoice(invoice) 这样的形式调用,也就是说,在 write() 函数自身上调用方法。并且,由于这些方法接受 write() 函数作为它们的接收器,我们就可以使用 write() 函数。
需注意的是,我们必须显式地声明 write() 函数的类型 (writerFunc)。如果不这样做,Go语言就会将其类型定义为 func(string, . . . interface{}) error(当然,它本来就是这种类型),并且不允许我们在其上调用 writerFunc 方法(除非我们使用类型转换的方法将其转换成 writerFunc 类型)。
有了方便的 write() 函数(及其方法),我们就可以开始写入文件类型和文件版本(后者使得容易适应数据的改变)。然后,我们迭代每一个发票项,针对每一次迭代,我们调用 write() 函数的 writeinvoice() 方法。
const noteSep = ":"type writerFunc func(string, ..interface{}) errorfunc (write writerFunc) writeinvoice(invoice *Invoice) error { note := "" if invoice.Note != "" { note = noteSep + "" + invoice.Note } if err := write("INVOICE ID=%d CUSTOMER=%d RAISED=%s DUE=%s" + "PAID=%t%s", invoice.Id, invoice.Customerld, invoice.Raised.Format(dateFormat), invoice.Due.Format(dateFormat), invoice.Paid, note); err != nil { return err } if err := write.writeitems(invoice.Items); err != nil { return err } return write ("f")}该方法用于写每一个发票项。它接受一个要写的发票项,同时使用作为接收器传入的 write() 函数来写数据。
发票数据一次性就可以写入,如果给出了注释文本,我们就在其前面加入冒号以及空格来将其写入。对于日期/时间(即 time.Time值),我们使用 time.Time.Format() 方法,跟我们以 JSON 和 XML 格式写入数据时一样。而对于布尔值,我们使用 %t 格式指令,也可以使用 %v 格式指令或 strconv.FormatBol() 函数。
一旦发票行写好了,就开始写发票项。最后,我们写入分页符和一个换行符,表示发票数 据的结束。
func (write writerFunc) writelterns(items []*Item) error { for _, item := range items { note :="" if item.Note != "" { note = noteSep + " " + item.Note } if err := write("ITEM ID=%s PRICE=%.2f QUANTITY=%d%s", item.Id, item.Price, item.Quantity, note); err != nil { return err } } return nil}该 writeltems() 方法接受发票的发票项,并使用作为接收器传入的 write() 函数来写数据。它迭代每一个发票项并将其写入,并且也跟写入发票数据一样,如果其注释文档为空则无需写入。
读纯文本文件
打开并读取一个纯文本格式的数据跟写入纯文本格式数据一样简单。要解析文本来重建原始数据可能稍微复杂,这需根据格式的复杂性而定。有 4 种方法可以使用。前 3 种方法包括将每行切分,然后针对非字符串的字段使用转换函数如 strconv.Atoi() 和 time.Parse()。这些方法是:
第一,手动解析(例如,一个字母一个字母或者一个字一个字地解析),这样做实现起来烦琐,不够健壮并且也慢;第二,使用 fmt.Fields() 或者 fmt.Split() 函数来将每行切分;第三,使用正则表达式。对于该 invoicedata 程序,我们使用第四,无需将每行切分或者使用转换函数,因为我们所 需的功能都能够交由fmt包的扫描函数处理。
func (TxtMarshaler) Unmarshallnvoices(reader io.Reader) ([]*Invoice, error) { bufferedReader := bufio.NewReader(reader) if err := checkTxtVersion(bufferedReader); err != nil { return nxl, err } var invoices []*Invoice eof := false for lino := 2; !eof; lino++ { line, err := bufferedReader.Readstring(') if err == io.EOF{ err = nil // io.EOF不是一个真正的错误 eof = true //下一次迭代的时候会终止循环 } else if err != nil { return nilz err //遇到真正的错误则立即停止 } if invoices, err = parseTxtLine(lino, line, invoices); err != nil { return nil, err } } return invoices, nil}针对所传入的 io.Reader,该方法创建了一个带缓冲的 reader,并将其中的每一行轮流传入解析函数中。通常,对于文本文件,我们会对 io.EOF 进行特殊处理,以便无论它是否以新行结尾其最后一行都能被读取。(当然,对于这种格式,这样做相当自由。)
按照常规,从行号 1 开始,该文件被逐行读取。第一行用于检查文件是否有个合法的类型和版本号,因此处理实际数据时,行号 (lino) 从 2 开始读起。
由于我们逐行工作,并且每一个发票文件都表示成两行甚至多行(一行 INVOICE 行和一行或者多行 ITEM 行),我们需跟踪当前发票,以便每读一行就可以将其添加到当前发票数据中。这很容易做到,因为所有的发票数据都被追加到一个发票切片中,因此当前发票永远是处于位置 invoices[len(invoices)-1] 处的发票。
当 parseTxtLine() 函数解析一个 INVOICE 行时,它会创建一个新的 Invoice 值,并将一个指向该值的指针追加到 invoices 切片中。
如果要在一个函数内部往一个切片中追加数据,有两种技术可以使用。第一种技术是传入一个指向切片的指针,然后在所指向的切片中操作。第二种技术是传入切片值,同时返回(可能被修改过的)切片给调用者,以赋值回原始切片。parseTxtLine() 函数使用第二种技术。
func parseTxtLine(lino int, line string, invoices []*Invoice) ([]*Invoicer error) { var err error if strings.HasPrefix(line, "INVOICE") { var invoice *Invoice invoice, err = parseTxtlnvoice(lino, line) invoices = append(invoices, invoice) } else if strings.HasPrefix(line, "ITEM") { if len(invoices) == 0 { err = fmt.Errorf("item outside of an invoice line %dM, lino) } else { var item *Item item, err = parseTxtItem(lino, line) items := &invoices[len(invoices)-1].Items *items = append(*items, item) } } return invoices, err}该函数接受一个行号(lino,用于错误报告),需被解析的行,以及我们需要填充的发票切片。
如果该行以文本“INVOICE”开头,我们就调用 parseTxtInvoice() 函数来解析该行,并创建一个 Invoice 值,并返回一个指向它的指针。然后,我们将该 *Inovice 值追加到 invoices 切片中,并在最后返回该 invoices 切片和 nil 值或者错误值。
需要注意的是,这里的发票信息是不完整的,我们只有它的 ID、客户 ID、创建和持续时间、是否支付以及注释信息,但是没有任何发票项。
如果该行以“ITEM”开头,我们首先检查当前发票是否存在(即 invoices 切片不为空)。如果存在,我们调用 parseTxtItem() 函数来解析该行并创建一个 Item 值,然后返回一个指向该值的指针。然后我们将该项添加到当前发票的项中。这可以通过取得指向当前发票项的指针以及将指针的值设置为追加新 *Item 后的结果来达到。当然,我们本可以使用 invoices[len(invoices)-1].Items = append(invoices[len(invoices)-1].Items, item) 来直接添加 *Item。
任何其他的行(例如空和换页行)都被忽略。顺便提一下,理论上而言,如果我们优先处理“ITEM”的情况该函数会更快,因为数据中发票项的行数远比发票和空行的行数多。
func parseTxtHnvoice(lino int, line string) (invoice *Invoice, err error) { invoice = &Invoice{} var raised, due string if _, err = fmt.Sscanf (line, "INVOICE ID=%d CUSTOMER=%d" + "RAISED=%s DUE=%s PAID=%t", &invoice.Id, &invoice.CustomerTd, &raised, &due, &invoice.Paid); err != nil { return nil, fmt.Errorf("invalid invoice %v line %d", err, lino) } if invoice.Raised, err = time.Parse(dateFormat, raised); err != nil { return nil, fmt.Errorf("invalid raised %v line %d", err, lino) } if invoice.Due, err = time.Parse(dateFormat, due); err != nil { return nil, fmt.Errorf ("invalid due %v line %d", err, lino) } if i := strings.Index(line, noteSep); i > -1 { invoice.Note = strings.TrimSpace(line[i+len(noteSep):]) } return invoice, nil}函数开始处,我们创建了一个 0 值的 Invoice 值,并将指向它的指针赋值给 invoice 变量(类型为 *Invoice)。扫描函数可以处理字符串、数字以及布尔值,但不能处理 time.Time 值,因此我们将创建以及持续时间以字符串的形式输入,并单独解析它们。下表中列岀了 fmt 中的扫描函数。
表:fmt 中的扫描函数
如果 fmt.Sscanf() 函数不能读入与我们所提供的值相同数量的项,或者如果发生了错误(例如,读取错误),函数就会返回一个非空的错误值。其中:参数 r 是一个从其中读数据的 io.Reader,s 是一个从其中读数据的字符串,fs 是一个用于 fmt 包中打印函数的格式化字符串,args 表示一个或者多个需填充的值的指针。所有这些扫描函数返回成功解析(即填充)项的数量,以及另一个空或者非空的错误值。
日期使用 time.Parse() 函数来解析,这在之前的节中已有阐述。如果发票行有冒号,则意味着该行末尾处有注释,那么我们就删除其空白符,并将其返回。我们使用了表达式 line[i+1:] 而非 line[i+len(noteSep):],因为我们知道 noteSep 的冒号字符占用了一个 UTF-8 字节,但为了更为健壮,我们选择了对任何字符都有效的方法,无论它占用多少字节。
func parseTxtltem(lino int, line string) (item *Item, err error) { item = &Item{} if _, err = £mt.Sscanf(line, "ITEM ID=%s PRICE=%f QUANTITY=%d", &itern. Id, &item. Price, &item.Quantity); err ! = nil { return nil, fmt.Errorf("invalid item %v line %d", err, lino) } i£ i := strings.Index(line, noteSep); i > -1 { item.Note = strings.TrimSpace(line[i+len(noteSep):]) } return item, nil}该函数的功能如我们所见过的 parseTxtInvoice() 函数一样,区别在于除了注释文本之外,所有的发票项值都可以直接扫描。
func checkTxtversion(bufferReader *buffio.Reader) error{ var version int if _, err := fmt.Fscanf(bufferedReader,"INVOICES %d",&version); err != nil{ retrun errors.New("cannot read non-invoices text file") } else if version > fileVersion { return fmt.Erroff("version %d is too new to read", version) } return nil}该函数用于读取发票文本文件的第一行数据。它使用 fmt.Fscanf() 函数来直接读取 bufio.Reader。如果该文件不是一个发票文件或者其版本太新而不能处理,就会报告错误。否则,返回 nil 值。
使用 fmt 包的打印函数来写文本文件比较容易。解析文本文件却挑战不小,但是 Go语言的 regexp 包中提供了 strings.Fields() 和 strings.Split() 函数,fmt 包中提供了扫描函数,使得我们可以很好的解决该问题。
今天关于《Go语言纯文本文件的读写操作》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于golang的内容请关注golang学习网公众号!
 Go语言二进制文件的读写操作
Go语言二进制文件的读写操作
- 上一篇
- Go语言二进制文件的读写操作

- 下一篇
- Go语言使用Gob传输数据
-

- 魁梧的酒窝
- 这篇文章真是及时雨啊,太详细了,受益颇多,码住,关注楼主了!希望楼主能多写Golang相关的文章。
- 2023-03-21 00:46:17
-
- 生动的钢笔
- 很好,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢老哥分享文章内容!
- 2023-02-09 19:05:31
-
- 英俊的帽子
- 太细致了,码住,感谢师傅的这篇技术文章,我会继续支持!
- 2023-01-21 18:58:13
-
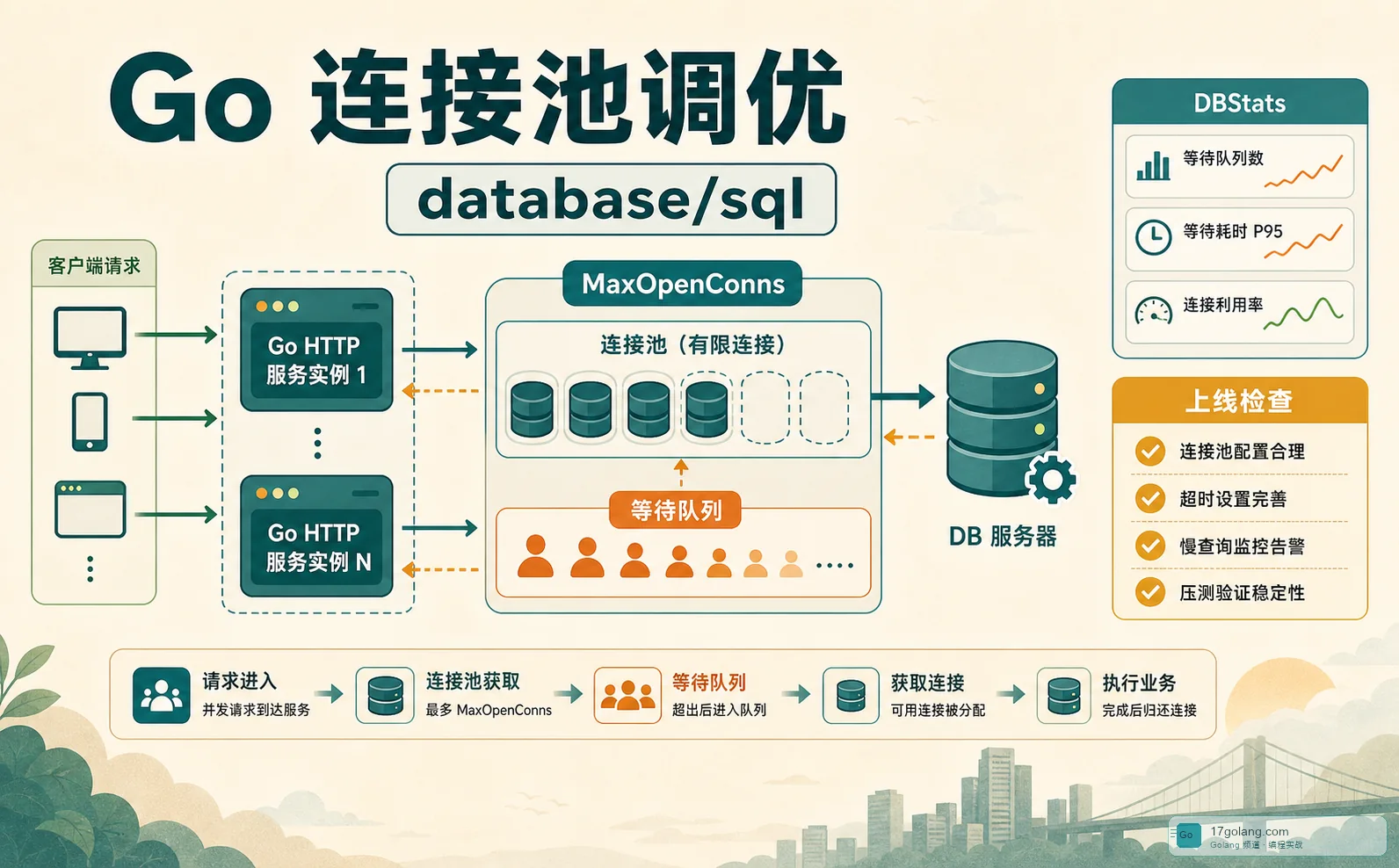
- Golang · Go教程 | 3天前 | 性能优化 · Go教程 · 后端工程 · Golang实战 · database/sql · 连接池调优 · golang Go 性能优化 连接池 MaxOpenConns database/sql 后端工程 DBStats
- Go database/sql 连接池实战:别让 MaxOpenConns 把接口拖成排队机
- 242浏览 收藏
-

- Golang · Go教程 | 4天前 | 并发编程 · 数据竞争 · Go教程 · 生产实践 · race detector · golang Go 数据竞争 并发 sync atomic race detector go test -race
- Go race detector 实战:别让数据竞争混进线上服务
- 147浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 6597次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 7003次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 6811次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 8763次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 7454次使用
-
- Go语言文件锁操作
- 2023-01-07 225浏览
-
- Go语言文件的写入、追加、读取、复制操作
- 2022-12-30 389浏览
-
- Go语言从INI配置文件中读取需要的值
- 2022-12-23 250浏览
-
- Go语言并发目录遍历
- 2023-01-07 137浏览
-
- Go语言使用切片读写文件
- 2023-02-25 190浏览


