ReFT(表征微调):比PeFT效果更好的新的大语言模型微调技术
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《ReFT(表征微调):比PeFT效果更好的新的大语言模型微调技术》,聊聊,我们一起来看看吧!
ReFT(Representation Finetuning)是一种突破性的方法,有望重新定义我们对大型语言模型进行微调的方式。
斯坦福大学的研究人员最近(4月)在arxiv上发布的论文,ReFT与传统的基于权重的微调方法大有不同,它提供了一种更高效和有效的方法来适应这些大规模的模型,以适应新的任务和领域!

在介绍这篇论文之前,我们先看看PeFT。
参数高效微调 PeFT
Parameter Efficient Fine-Tuning(PEFT)是一种微调少量或额外的模型参数的高效微调方法。与传统的预测网络微调方法相比,使用PEFT进行微调可以大幅降低计算和存储成本,同时保证了与全量微调相当的性能。此技术的应用范围非常广泛,并且能够实现与全量微调相当的性能。
在PeFT的思想之上就产生了我们非常熟悉的LoRA,还有各种LoRA的变体,除了有名的LoRA之外常用的PeFT方法还有:
Prefix Tuning:通过virtual token构造连续型隐式prompt ,这是21年斯坦福发布的方法。
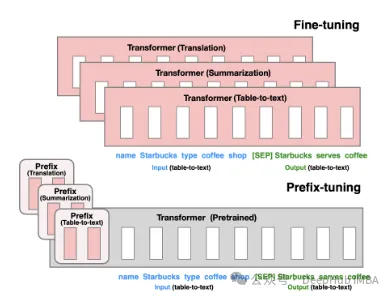
P-Tuning V1/V2 是由清华大学在2021年提出的技术,旨在将自然语言的离散模型转换为可训练的隐式prompt(连续参数优化问题)。V2版本通过在输入前的每层添加可微调的参数,进一步增强了V1版本的性能。这种方法有效地扩展了模型的应用范围和灵活性。
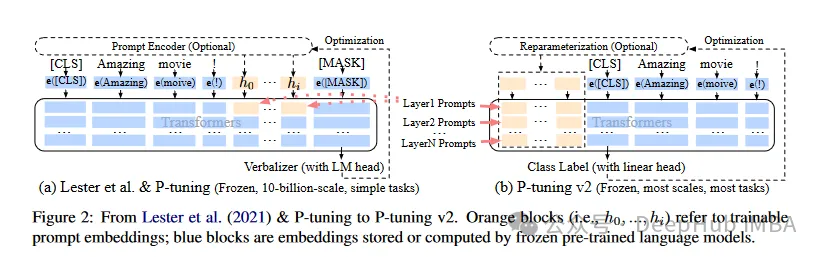
然后就是我们熟悉的也是最长用的LoRA,这里就不多介绍了,我们可以狭义理解为LoRA是目前最好的PeFT方法,这样可以对我们下面介绍的ReFT更好的对比。
表征微调 ReFT
ReFT (Representation Finetuning)是一组专注于在推理过程中对语言模型的隐藏表示学习干预的方法,而不是直接修改其权重。
与更新模型整个参数集的传统微调方法不同,ReFT通过策略性地操纵模型表示的一小部分来操作,指导其行为以更有效地解决下游任务。
ReFT背后的核心思想受到最近语言模型可解释性研究的启发:在这些模型学习的表示中编码了丰富的语义信息。通过干预这些表示,ReFT旨在解锁和利用这些编码知识,实现更高效和有效的模型适应。
ReFT的一个关键优点是它的参数效率:传统的微调方法需要更新模型参数的很大一部分,这可能是计算昂贵和资源密集的,特别是对于具有数十亿参数的大型语言模型。ReFT方法通常需要训练数量级更少的参数,从而获得更快的训练时间和更少的内存需求。
ReFT与PeFT有何不同
ReFT与传统PEFT方法在几个关键方面有所不同:
1、干预目标
PEFT方法,例如,LoRA、DoRA和prefix-tuning,侧重于修改模型的权重或引入额外的权重矩阵。而ReFT方法不直接修改模型的权重;它们会干预模型在向前传递期间计算的隐藏表示。
2、适应机制
像LoRA和DoRA这样的PEFT方法学习权重更新或模型权重矩阵的低秩近似值。然后在推理期间将这些权重更新合并到基本模型的权重中,从而不会产生额外的计算开销。ReFT方法学习干预,在推理过程中在特定层和位置操纵模型的表示。此干预过程会产生一些计算开销,但可以实现更有效的适应。
3、动机
PEFT方法的主要动机是对参数有效适应的需求,减少了调优大型语言模型的计算成本和内存需求。另一方面,ReFT方法受到最近语言模型可解释性研究的启发,该研究表明,在这些模型学习的表示中编码了丰富的语义信息。ReFT的目标是利用和利用这些编码的知识来更有效地适应模型。
4.参数效率
PEFT和ReFT方法都是为了参数效率而设计的,但ReFT方法在实践中证明了更高的参数效率。例如LoReFT(低秩线性子空间ReFT)方法通常需要训练的参数比最先进的PEFT方法(LoRA)少10-50倍,同时在各种NLP基准测试中获得具有竞争力或更好的性能。
5、可解释性
虽然PEFT方法主要侧重于有效的适应,但ReFT方法在可解释性方面提供了额外的优势。通过干预已知编码特定语义信息的表示,ReFT方法可以深入了解语言模型如何处理和理解语言,从而可能导致更透明和值得信赖的人工智能系统。
ReFT架构
ReFT模型体系结构定义了干预的一般概念,这基本上意味着在模型向前传递期间对隐藏表示的修改。我们首先考虑一个基于transformer的语言模型,该模型生成标记序列的上下文化表示。
给定一个n个输入令牌序列x = (x₁,…,xn),模型首先将其嵌入到一个表示列表中,就h₁,…,hn。然后m层连续计算第j个隐藏表示,每一个隐藏的表示都是一个向量h∈λ,其中d是表示的维数。
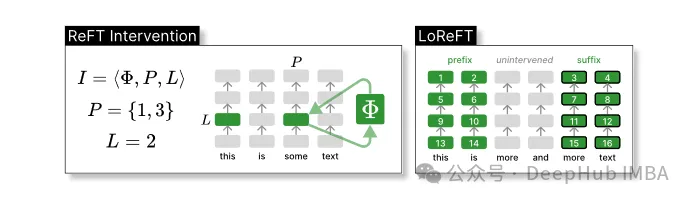
ReFT定义了一个干预的概念,它在模型向前传递期间修改隐藏的表示。
干预I是一个元组⟨Φ, P, L⟩,它封装了由基于transformer的LM计算的表示的单个推理时间的干预动作,这个函数包含了三个参数:
干预函数Φ:用学习到的参数Φ (Φ)来表示。
干预所应用的一组输入位置P≤{1,…,n}。
对层L∈{1,…,m}进行干预。
然后,干预的动作如下:
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}该干预在前向传播计算完后立即进行,所以会影响到后续层中计算的表示。
为了提高计算的效率,也可以将干预的权重进行低秩分解,也就是得到了低秩线性子空间ReFT (LoReFT)。
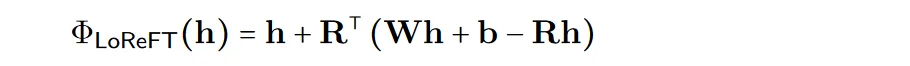
在上面的公式中使用学习到的投影源Rs = Wh +b。LoReFT编辑R列的R维子空间中的表示,来或取从我们的线性投影Wh +b中获得的值。
对于生成任务,ReFT论文使用语言建模的训练目标,重点是在所有输出位置上使用最小化交叉熵损失。
pyreft库代码示例
斯坦福大学的研究人员在发布论文的同时还发布了pyreft库,这是一个建立在pyvene之上用于在任意PyTorch模型上执行和训练激活干预的库。
pyreft可以兼容HuggingFace上可用的任何预训练语言模型,并且可以使用ReFT方法进行微调。以下是如何将lama- 27b模型的第19层输出进行单一干预的代码示例:
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()剩下的代码就和HuggingFace训练模型没有任何的区别了,我们来做一个完整的演示:
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
一旦完成训练,就可以检查模型信息:
prompt = tokenizer("GO->", return_tensors="pt").to("cuda") base_unit_location = prompt["input_ids"].shape[-1] - 1# last position _, reft_response = reft_model.generate( prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True))LoReFT的性能测试
最后我们来看看它在各种NLP基准测试中的卓越表现,以下是斯坦福大学的研究人员展示的数据。
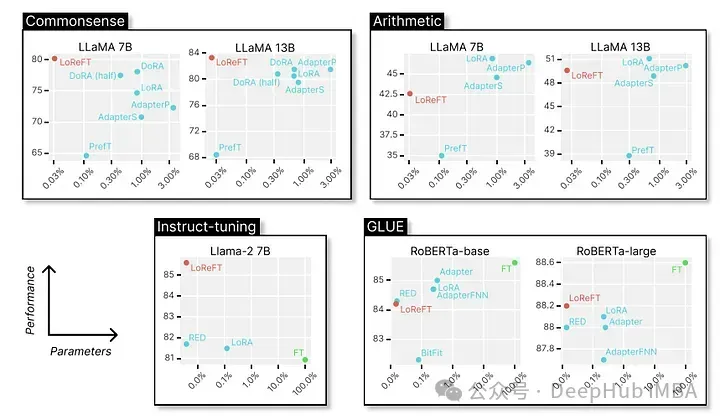
LoReFT在8个具有挑战性的数据集上获得了最先进的性能,包括BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-e、ARC-c和OBQA。尽管使用的参数比现有的PEFT方法少得多(少10-50倍),但LoReFT的性能还是大大超过了所有其他方法,展示了它有效捕获和利用大型语言模型中编码的常识性知识的能力。
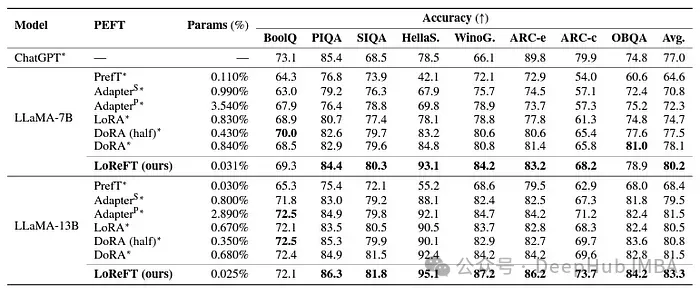
虽然LoReFT在数学推理任务上没有超过现有的PEFT方法,但它在AQuA、GSM8K、MAWPS和SVAMP等数据集上展示了具有竞争力的性能。研究人员指出LoReFT的性能随着模型尺寸的增大而提高,这表明它的能力随着语言模型的不断增长而扩大。
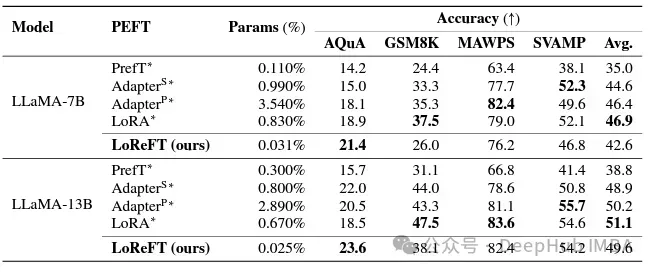
在指令遵循领域,LoReFT取得了显著的结果,在Alpaca-Eval v1.0基准测试上优于所有的微调方法,包括完全微调(这个要注重说明)。当在llama - 27b模型上训练时,LoReFT的比GPT-3.5 Turbo模型的还要好1%,同时使用的参数比其他PEFT方法少得多。
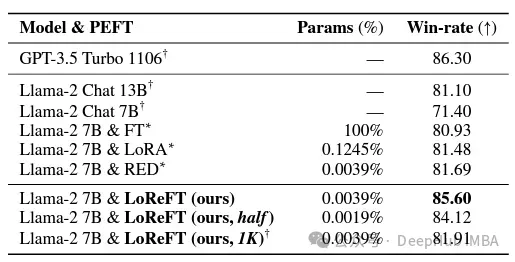
LoReFT还展示了其在自然语言理解任务中的能力,当应用于RoBERTa-base和RoBERTa-large模型时,在GLUE基准测试中实现了与现有PEFT方法相当的性能。
当在参数数量上与之前最有效的PEFT方法相匹配时,LoReFT在各种任务中获得了相似的分数,包括情感分析和自然语言推理。
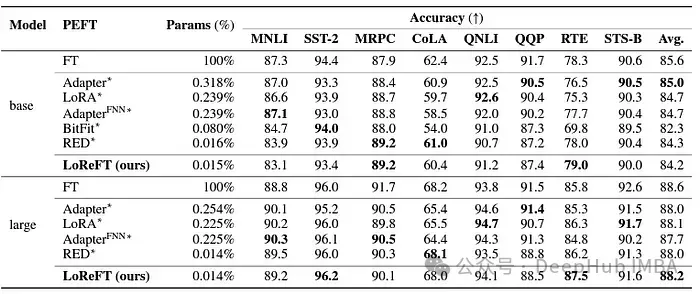
总结
ReFT特别是LoReFT的成功,对自然语言处理的未来和大型语言模型的实际应用具有重要意义。ReFT的参数效率使其成为一种使大型语言模型适应特定的任务或领域,同时最大限度地减少计算资源和训练时间的有效的解决方案。
并且ReFT还提供了一个独特的视角来增强大型语言模型的可解释性。在常识推理、算术推理和指令遵循等任务中的成功表明该方法的有效性。目前来看ReFT有望开启新的可能性,克服传统调优方法的局限性。
以上就是《ReFT(表征微调):比PeFT效果更好的新的大语言模型微调技术》的详细内容,更多关于大型语言模型,ReFT的资料请关注golang学习网公众号!
 总投资 630 亿元,京东方国内首条 8.6 代 AMOLED 生产线奠基
总投资 630 亿元,京东方国内首条 8.6 代 AMOLED 生产线奠基
- 上一篇
- 总投资 630 亿元,京东方国内首条 8.6 代 AMOLED 生产线奠基

- 下一篇
- 如何解决vs code - gopls命令不可用
-

- 科技周边 · 人工智能 | 1星期前 | AI绘画
- AI绘画工具安装与配置教程
- 339浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 海螺AI语音功能测评与体验分享
- 260浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- ChatGPT读不了加密PDF?先解密再上传
- 438浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 千问AI测试规范与覆盖率提升技巧
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- MiniMaxMusic2.0专业模式上线:音乐创作新神器
- 232浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 即梦AI音乐可视化效果评测
- 280浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | 豆包AI 豆包AI助手
- 豆包AI写诗技巧与教程分享
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | openclaw
- OpenClawAI摘要生成技巧全解析
- 102浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 百度发布DuMate智能体,李彦宏解读DAA新定义
- 247浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 智谱清影制作鸟瞰街景镜头教程
- 306浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | openclaw
- OpenClaw框架解析与技术亮点揭秘
- 357浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 即梦AI美妆详情页提示词技巧
- 334浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7787次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8217次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8025次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 9952次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8791次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


