使用GaLore在本地GPU进行高效的LLM调优
golang学习网今天将给大家带来《使用GaLore在本地GPU进行高效的LLM调优》,感兴趣的朋友请继续看下去吧!以下内容将会涉及到等等知识点,如果你是正在学习科技周边或者已经是大佬级别了,都非常欢迎也希望大家都能给我建议评论哈~希望能帮助到大家!
训练大型语言模型(llm)是一项计算密集型的任务,即使是那些“只有”70亿个参数的模型也是如此。这种级别的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(LoRA)等参数高效方法,使得在消费级gpu上可以对大量模型进行微调。
GaLore是一种创新方法,它采用优化参数训练方式来减少VRAM需求,而非简单减少参数数量。这意味着GaLore是一种新的模型训练策略,允许模型充分利用全部参数进行学习,并比LoRA更有效地节省内存。
GaLore通过将这些梯度映射到低维空间,有效减轻了计算负担,同时保留了关键的训练信息。与传统优化器在反向传播时一次性更新所有层不同,GaLore采用逐层更新的方式进行反向传播。这种策略显著减少了训练过程中的内存占用,进一步优化了性能。
就像LoRA一样,GaLore使我们能够在消费级GPU上微调7B模型,该GPU配备了高达24 GB的VRAM。结果显示,模型的性能与全参数微调相当,甚至似乎优于LoRA。
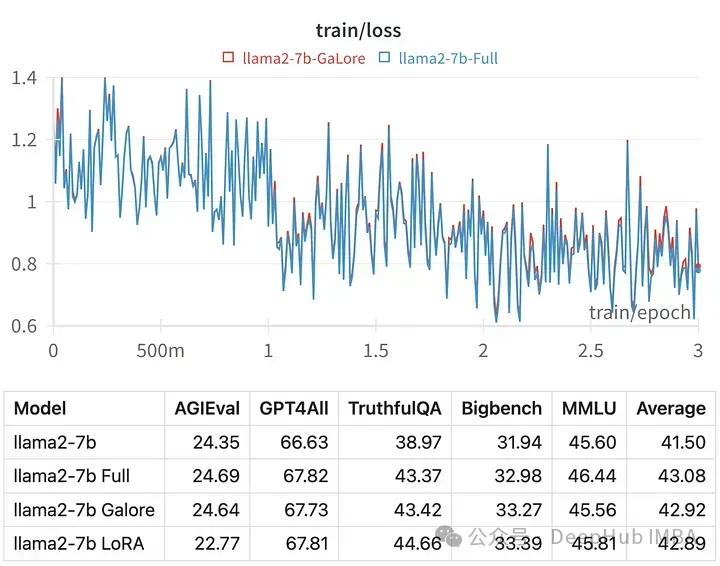
优于目前Hugging Face还没有官方代码,我们就来手动使用论文的代码进行训练,并与LoRA进行对比
安装依赖
首先就要安装GaLore
pip install galore-torch
然后我们还要一下这些库,并且请注意版本
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
调度器和优化器的类
Galore分层优化器是通过模型权重挂钩激活的。由于我们使用Hugging Face Trainer,还需要自己实现一个优化器和调度器的抽象类。这些类的结构不执行任何操作。
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrs加载GaLore优化器
GaLore优化器的目标是特定的参数,主要是那些在线性层中以attn或mlp命名的参数。通过系统地将函数与这些目标参数挂钩,GaLore 8位优化器就会开始工作。
from transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()HF Trainer
准备好优化器后,我们开始使用Trainer进行训练。下面是一个简单的例子,使用TRL的SFTTrainer (Trainer的子类)在Open Assistant数据集上微调llama2-7b,并在RTX 3090/4090等24 GB VRAM GPU上运行。
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,save_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "<|im_start|>user", response_template = "<|im_start|>assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()GaLore优化器带有一些需要设置的超参数如下:
target_modules_list:指定GaLore针对的层
rank:投影矩阵的秩。与LoRA类似,秩越高,微调就越接近全参数微调。GaLore的作者建议7B使用1024
update_proj_gap:更新投影的步骤数。这是一个昂贵的步骤,对于7B来说大约需要15分钟。定义更新投影的间隔,建议范围在50到1000步之间。
scale:类似于LoRA的alpha的比例因子,用于调整更新强度。在尝试了几个值之后,我发现scale=2最接近于经典的全参数微调。
微调效果对比
给定超参数的训练损失与全参数调优的轨迹非常相似,表明GaLore分层方法确实是等效的。
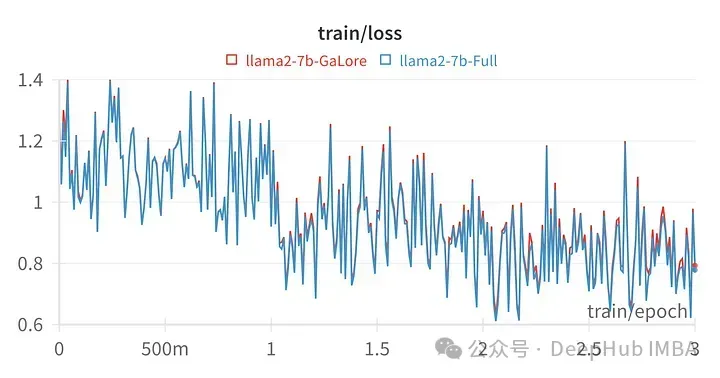
用GaLore训练的模型得分与全参数微调非常相似。
GaLore可以节省大约15 GB的VRAM,但由于定期投影更新,它需要更长的训练时间。
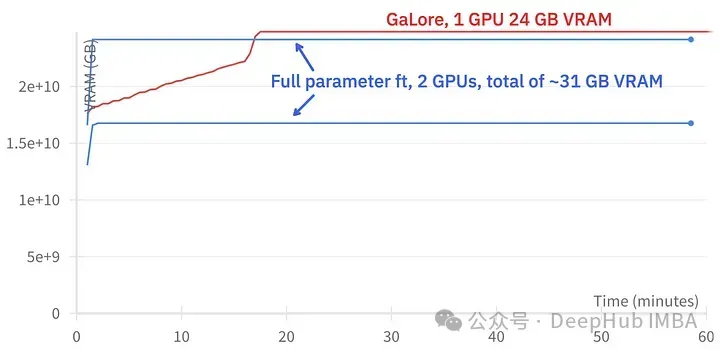
上图为2个3090的内存占用对比
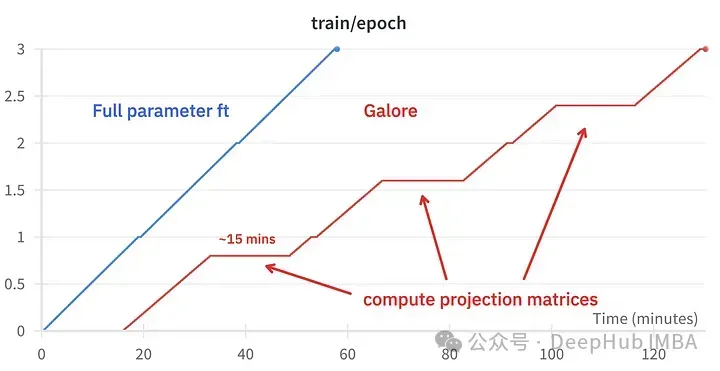
训练事件对比,微调:~58分钟。GaLore:约130分钟
最后我们再看看GaLore和LoRA的对比
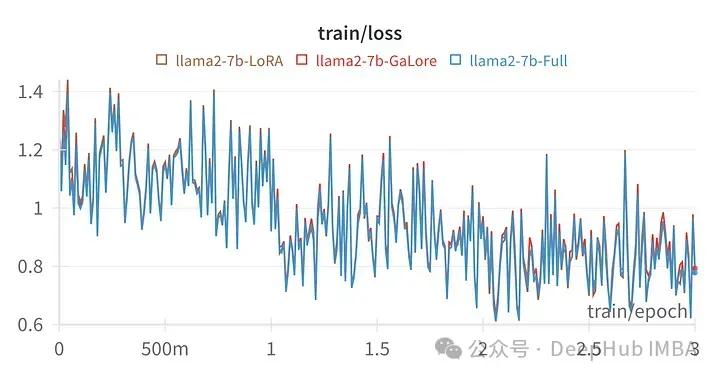
上图为LoRA微调所有线性层,rank64,alpha 16的损失图
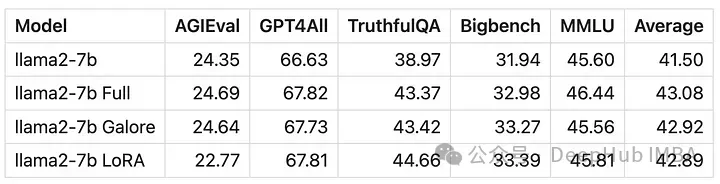
从数值上可以看到GaLore是一种近似全参数训练的新方法,性能与微调相当,比LoRA要好得多。
总结
GaLore可以节省VRAM,允许在消费级GPU上训练7B模型,但是速度较慢,比微调和LoRA的时间要长差不多两倍的时间。
今天关于《使用GaLore在本地GPU进行高效的LLM调优》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于大型语言模型,GaLore的内容请关注golang学习网公众号!
 通过 HTML 从 Excel 获取数据:全面指南
通过 HTML 从 Excel 获取数据:全面指南
- 上一篇
- 通过 HTML 从 Excel 获取数据:全面指南

- 下一篇
- PHP中标签的用法:了解列和行
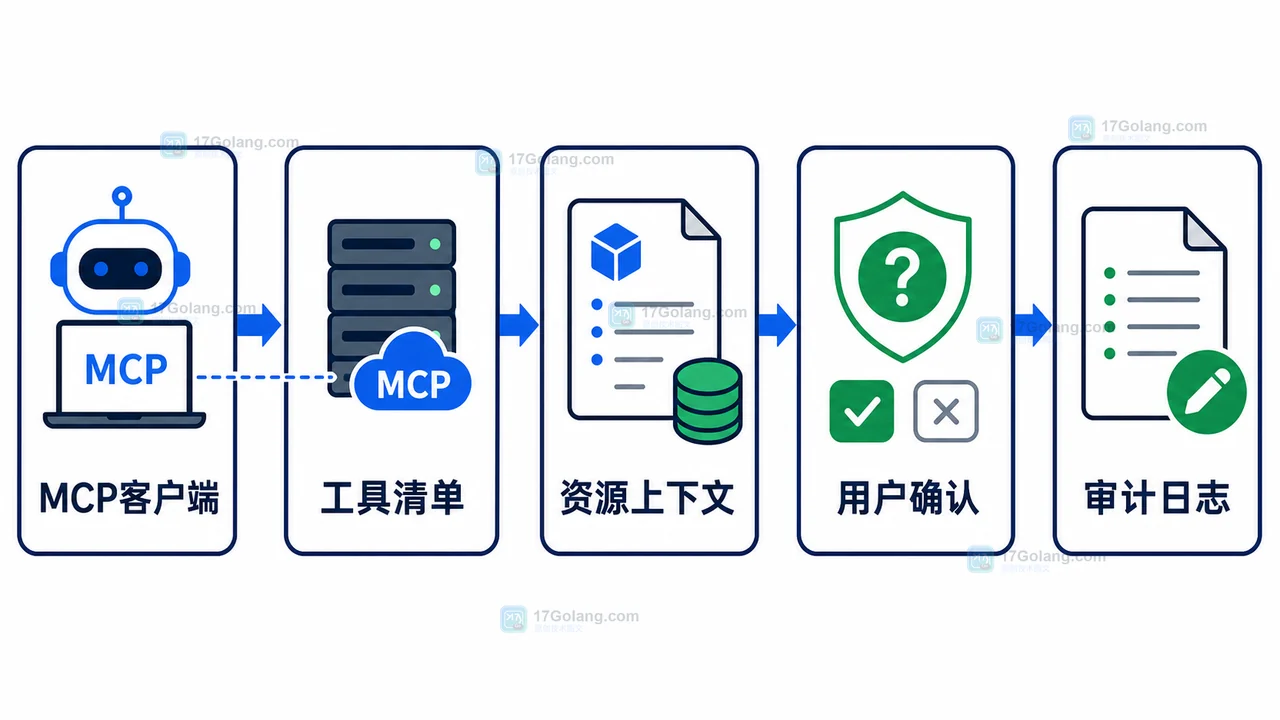
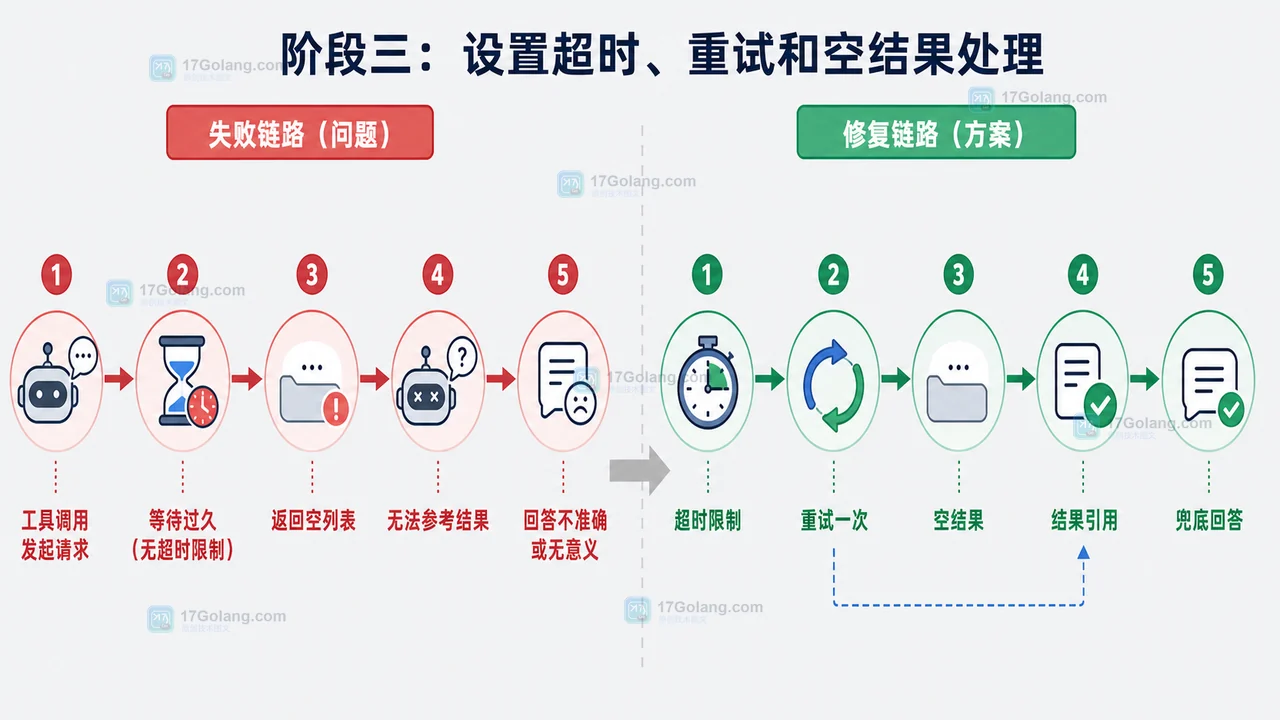
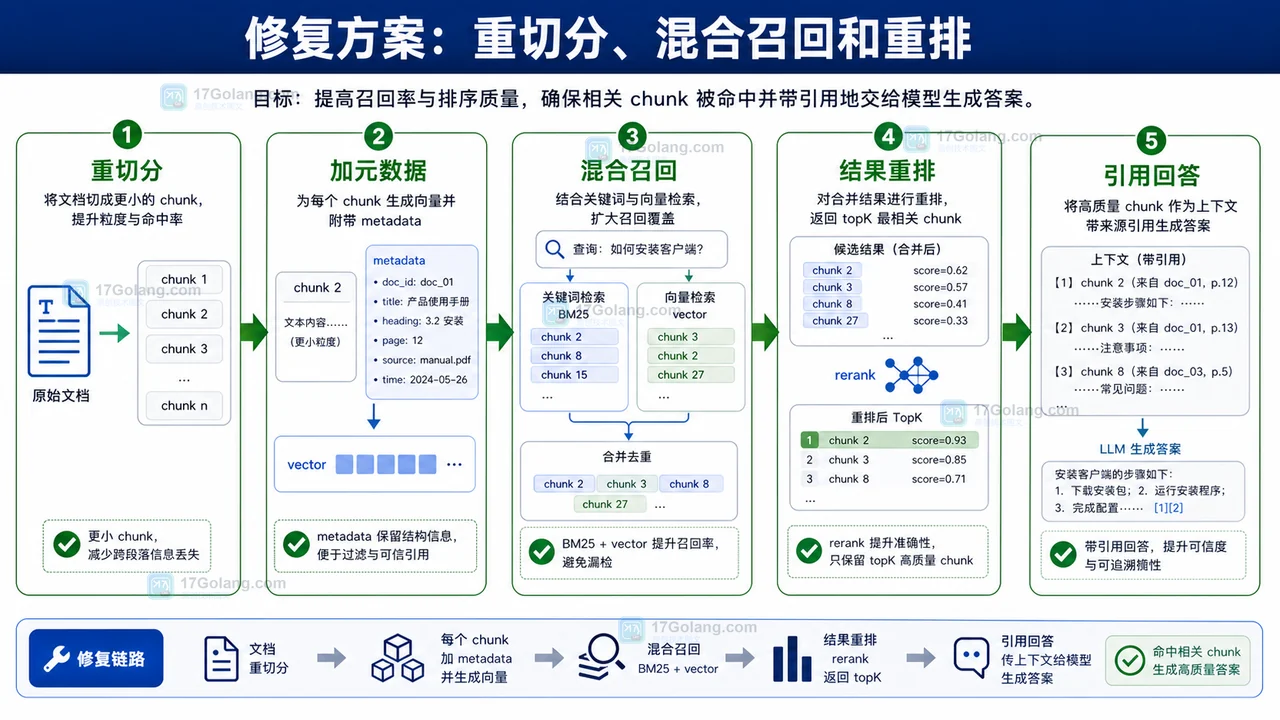

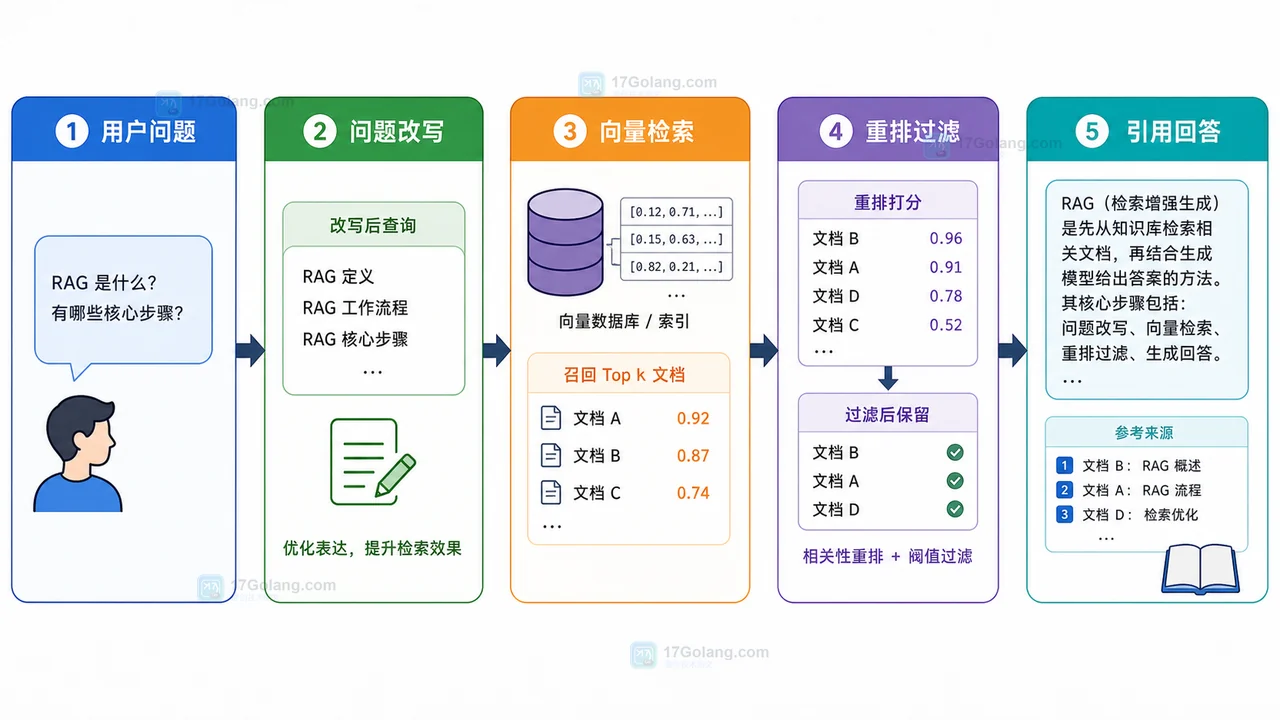
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1001次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 958次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 895次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1083次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1066次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


