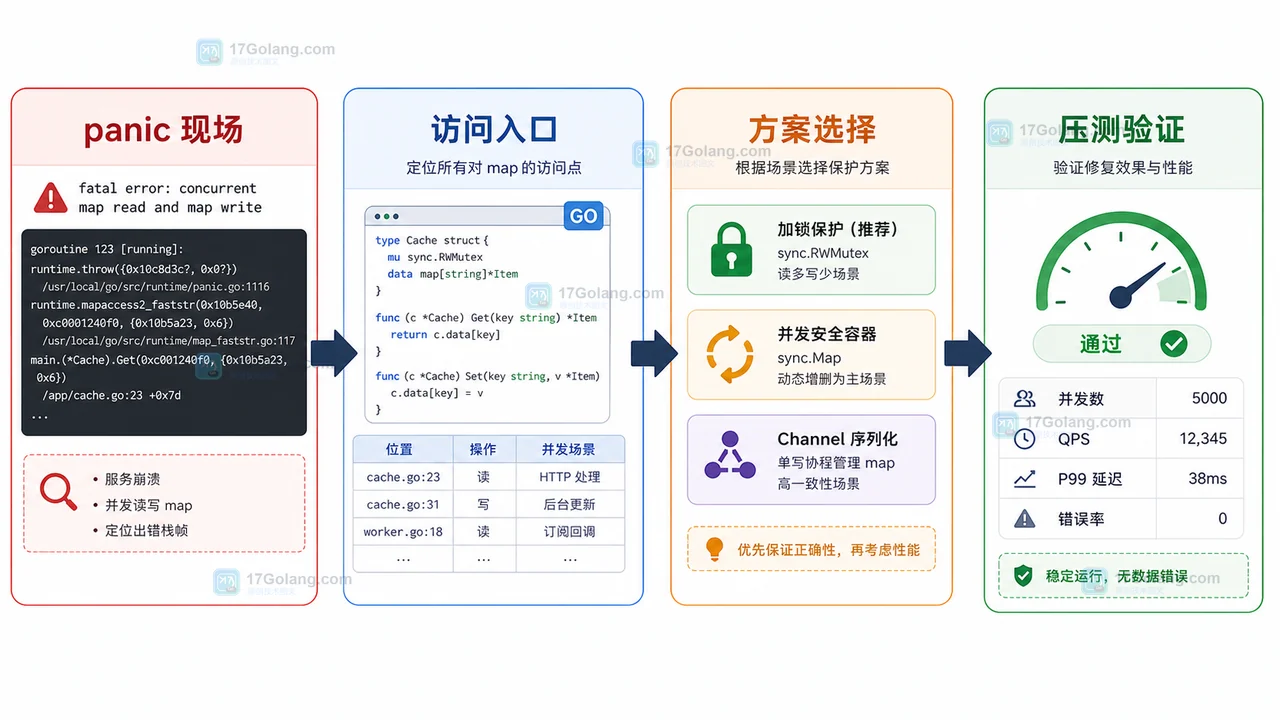
使用 ANTLR4 来匹配可输出的类字母字符,以便实现在 Go 语言中的目标
使用 ANTLR4 解析器和词法分析器,可以通过引入词法模式来匹配可打印的字母字符。在进入词法模式后,可以匹配括号、空格或非特殊字符,直到出现模式外的字符。通过使用词法模式,可以在自己的文件中定义词法分析器和解析器规则,其中词法分析器语法使用 "lexer grammar ...",而解析器语法使用 "parser grammar ..."。
这让我很害怕,我只是找不到解决方案。我有一个用于搜索查询的语法,并且希望匹配由可打印字母组成的查询中的任何搜索项,但特殊字符“(”、“)”除外。引号括起来的字符串是单独处理的并且可以工作。
这是一个有点有效的语法:
/* antlr grammar for minidb query language */
grammar mdb;
start
: searchclause eof
;
searchclause
: table expr
;
expr
: fieldsearch
| searchop fieldsearch
| unop expr
| expr relop expr
| lparen expr relop expr rparen
;
lparen
: '('
;
rparen
: ')'
;
unop
: not
;
relop
: and
| or
;
searchop
: no
| every
;
fieldsearch
: field eq searchterm
;
field
: id
;
table
: id
;
searchterm
:
| string
| id+
| digit+
| digit+ id+
;
string
: '"' ~('\n'|'"')* ('"' )
;
and
: 'and'
;
or
: 'or'
;
not
: 'not'
;
no
: 'no'
;
every
: 'every'
;
eq
: '='
;
fragment valid_id_start
: ('a' .. 'z') | ('a' .. 'z') | '_'
;
fragment valid_id_char
: valid_id_start | ('0' .. '9')
;
id
: valid_id_start valid_id_char*
;
digit
: ('0' .. '9')
;
/*
not_special
: ~(' ' | '\t' | '\n' | '\r' | '\'' | '"' | ';' | '.' | '=' | '(' | ')' )
; */
ws
: [ \r\n\t] + -> skip
;
问题是搜索词太受限制。它应该匹配注释掉的 not_special 中的任何字符,即有效的查询将是:
Person Name=% Person Address=^%Street%%%$^&*@^
但是每当我尝试以任何方式将 not_special 放入搜索词的定义中时,它都不起作用。我也尝试过将其字面意义放入规则中(注释掉 not_special)和许多其他内容,但它就是行不通。在我的大多数尝试中,语法只是抱怨“=”后的无关输入,并表示它期待 eof。但我也不能将 eof 放入 not_special。
有什么方法可以简单地解析规则字段搜索中“=”之后的每个文本,直到出现空格或“)”、“(”?
注意string 规则工作正常,但不应要求用户每次都使用引号,因为这是一个命令行工具,需要对它们进行转义。
目标语言是 go。
解决方案
您可以通过引入 lexical mode 来解决这个问题,只要您匹配 eq 令牌,您就需要输入该值。进入该词法模式后,您可以匹配 (, ) 或空格(在这种情况下,您会弹出词法模式),或者继续匹配 not_special 字符。
通过使用词法模式,您必须在自己的文件中定义词法分析器和解析器规则。请务必使用 lexer 语法 ... 和 parser 语法 ...,而不是在组合 .g4 文件中使用的 grammar ...。
快速演示:
lexer grammar mdblexer;
string
: '"' ~[\r\n"]* '"'
;
opar
: '('
;
cpar
: ')'
;
and
: 'and'
;
or
: 'or'
;
not
: 'not'
;
no
: 'no'
;
every
: 'every'
;
eq
: '=' -> pushmode(not_special_mode)
;
id
: valid_id_start valid_id_char*
;
digit
: [0-9]
;
ws
: [ \r\n\t]+ -> skip
;
fragment valid_id_start
: [a-za-z_]
;
fragment valid_id_char
: [a-za-z_0-9]
;
mode not_special_mode;
opar2
: '(' -> type(opar), popmode
;
cpar2
: ')' -> type(cpar), popmode
;
ws2
: [ \t\r\n] -> skip, popmode
;
not_special
: ~[ \t\r\n()]+
;
你的解析器语法将像这样开始:
parser grammar mdbparser;
options {
tokenvocab=mdblexer;
}
start
: searchclause eof
;
// your other parser rules
我的go有点生疏,但是一个小的java测试:
string source = "person address=^%street%%%$^&*@^()";
mdblexer lexer = new mdblexer(charstreams.fromstring(source));
commontokenstream tokens = new commontokenstream(lexer);
tokens.fill();
for (token t : tokens.gettokens()) {
system.out.printf("%-15s %s\n", mdblexer.vocabulary.getsymbolicname(t.gettype()), t.gettext());
}
打印以下内容:
ID Person ID Address EQ = NOT_SPECIAL ^%Street%%%$^&*@^ OPAR ( CPAR ) EOF
到这里,我们也就讲完了《使用 ANTLR4 来匹配可输出的类字母字符,以便实现在 Go 语言中的目标》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于的知识点!
 在使用 Reader 接口执行 select 查询时的规范
在使用 Reader 接口执行 select 查询时的规范
- 上一篇
- 在使用 Reader 接口执行 select 查询时的规范

- 下一篇
- 安全关闭 golang 服务的最佳实践 - 参数接收与实现
-
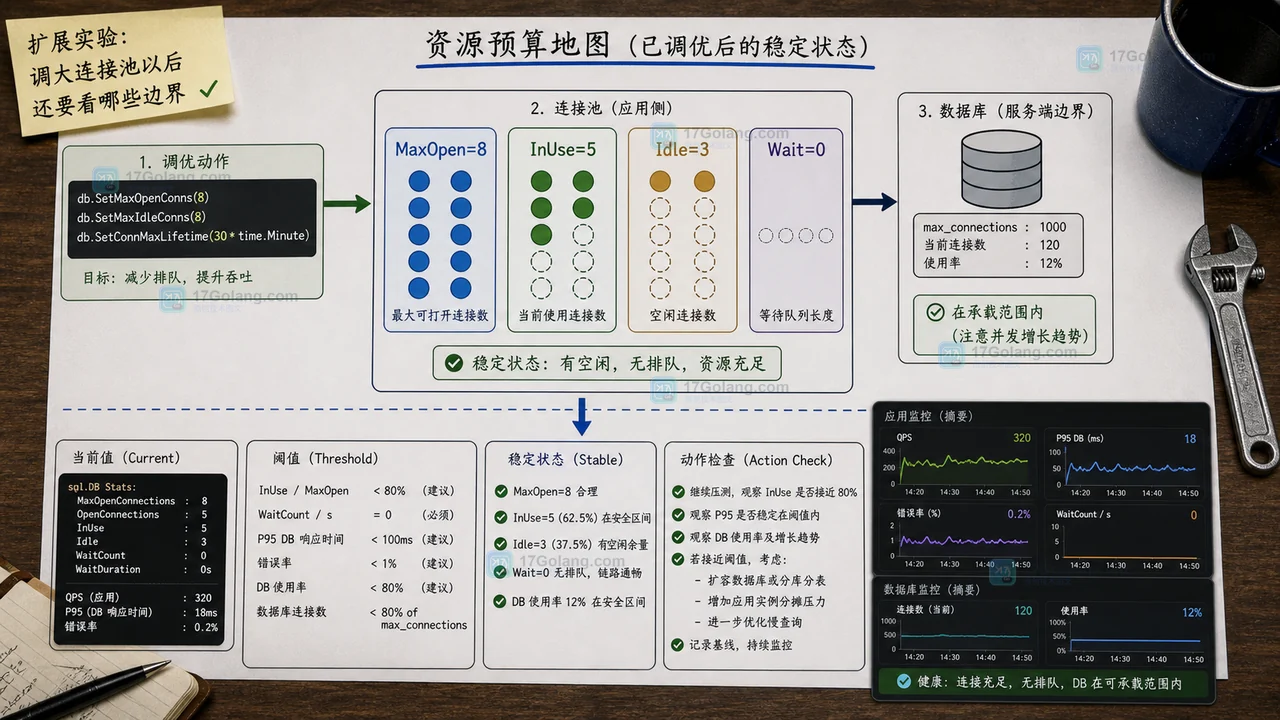
- Golang · Go问答 | 21小时前 | 连接池 · 性能排查 · database/sql · Go问答 · Go 连接池 DBStats sql.DB WaitCount SetMaxOpenConns
- Go sql.DB WaitCount 为什么增长:用小实验看连接池预算怎么调
- 214浏览 收藏
-
![Go nil slice 为什么 JSON 是 null:接口数组字段统一成 [] 的迁移清单](/uploads/20260628/1782577125-go-nil-slice-json-diff.webp)
- Golang · Go问答 | 3天前 | JSON · 接口设计 · Go问答 · nil slice · Go 接口兼容 json.Marshal nil slice empty slice 数组字段
- Go nil slice 为什么 JSON 是 null:接口数组字段统一成 [] 的迁移清单
- 305浏览 收藏


![Go 问答:nil slice 和空 slice 有什么区别,JSON 为什么一个是 null 一个是 []](/uploads/20260616/1781589727-go-nil-empty-slice-struct.webp)
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3120次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2882次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2835次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3054次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3001次使用
-
- 用Nginx反向代理部署go写的网站。
- 2023-01-17 502浏览
-
- GoLand调式动态执行代码
- 2023-01-13 502浏览
-
- 从不同的 go 例程将数据写入同一通道无需等待组即可正常工作
- 2024-04-29 501浏览
-
- Golang rsa-oaep解密失败,前端使用webcrypto
- 2024-04-26 501浏览
-
- 如何从用户输入以惰性方式初始化包的全局变量?
- 2024-04-24 501浏览


