golanggoqueryselector选择器使用示例大全
本篇文章向大家介绍《golanggoqueryselector选择器使用示例大全》,主要包括goquery、selector、选择器,具有一定的参考价值,需要的朋友可以参考一下。
引言
最近研究Go爬虫相关的知识,使用到goquery这个库比较多,尤其是对爬取到的HTML进行选择和查找匹配的内容时,goquery的选择器使用尤其多,而且还有很多不常用但又很有用的选择器,这里总结下,以供参考。
如果大家以前做过前端开发,对jquery不会陌生,goquery类似jquery,它是jquery的go版本实现。使用它,可以很方便的对HTML进行处理。
基于HTML Element 元素的选择器
这个比较简单,就是基于a,p等这些HTML的基本元素进行选择,这种直接使用Element名称作为选择器即可。
比如dom.Find("div")。
func main() {
html := `
DIV1
DIV2
SPAN
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
以上示例,可以把div元素筛选出来,而body,span并不会被筛选。
ID 选择器
这个是使用频次最多的,类似于上面的例子,有两个div元素,其实我们只需要其中的一个,那么我们只需要给这个标记一个唯一的id即可,这样我们就可以使用id选择器,精确定位了。
func main() {
html := `
DIV1
DIV2
SPAN
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("#div1").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
Element ID 选择器
id选择器以#开头,紧跟着元素id的值,使用语法为dom.Find(#id),后面的例子我会简写为Find(#id),大家知道这是代表goquery选择器的即可。
如果有相同的ID,但是它们又分别属于不同的HTML元素怎么办?有好办法,和Element结合起来。比如我们筛选元素为div,并且id是div1的元素,就可以使用Find(div#div1)这样的筛选器进行筛选。
所以这类筛选器的语法为Find(element#id),这是常用的组合方法,比如后面讲的过滤器也可以采用这种方式组合使用。
Class选择器
class也是HTML中常用的属性,我们可以通过class选择器来快速的筛选需要的HTML元素,它的用法和ID选择器类似,为Find(".class")。
func main() {
html := `
DIV1
DIV2
SPAN
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find(".name").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
以上示例中,就筛选出来class为name的这个div元素。
Element Class 选择器
class选择器和id选择器一样,也可以结合着HTML元素使用,他们的语法也类似Find(element.class),这样就可以筛选特定element、并且指定class的元素。
属性选择器
一个HTML元素都有自己的属性以及属性值,所以我们也可以通过属性和值筛选元素。
func main() {
html := `
DIV1
DIV2
SPAN
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div[class]").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
示例中我们通过div[class]这个选择器,筛选出Element为div并且有class这个属性的,所以第一个div没有被筛选到。
刚刚上面这个示例是采用是否存在某个属性为筛选器,同理,我们可以筛选出属性为某个值的元素。
dom.Find("div[class=name]").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
这样我们就可以筛选出class这个属性值为name的div元素。
当然我们这里以class属性为例,还可以用其他属性,比如href等很多,自定义属性也是可以的。
除了完全相等,还有其他匹配方式,使用方式类似,这里统一列举下,不再举例
| 选择器 | 说明 |
|---|---|
| Find(“div[lang]”) | 筛选含有lang属性的div元素 |
| Find(“div[lang=zh]”) | 筛选lang属性为zh的div元素 |
| Find(“div[lang!=zh]”) | 筛选lang属性不等于zh的div元素 |
| Find(“div[lang¦=zh]”) | 筛选lang属性为zh或者zh-开头的div元素 |
| Find(“div[lang*=zh]”) | 筛选lang属性包含zh这个字符串的div元素 |
| Find(“div[lang~=zh]”) | 筛选lang属性包含zh这个单词的div元素,单词以空格分开的 |
| Find(“div[lang$=zh]”) | 筛选lang属性以zh结尾的div元素,区分大小写 |
| Find(“div[lang^=zh]”) | 筛选lang属性以zh开头的div元素,区分大小写 |
以上是属性筛选器的用法,都是以一个属性筛选器为例,当然你也可以使用多个属性筛选器组合使用,比如: Find("div[id][lang=zh]"),用多个中括号连起来即可。当有多个属性筛选器的时候,要同时满足这些筛选器的元素才能被筛选出来。
parent>child选择器
如果我们想筛选出某个元素下符合条件的子元素,我们就可以使用子元素筛选器,它的语法为Find("parent>child"),表示筛选parent这个父元素下,符合child这个条件的最直接(一级)的子元素。
func main() {
html := `
DIV1
DIV2
DIV3
DIV4
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("body>div").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
以上示例,筛选出body这个父元素下,符合条件的最直接的子元素div,结果是DIV1、DIV2、DIV3,虽然DIV4也是body的子元素,但不是一级的,所以不会被筛选到。
那么问题来了,我就是想把DIV4也筛选出来怎么办?就是要筛选body下所有的div元素,不管是一级、二级还是N级。有办法的,goquery考虑到了,只需要把大于号(>)改为空格就好了。比如上面的例子,改为如下选择器即可。
dom.Find("body div").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
prev+next相邻选择器
假设我们要筛选的元素没有规律,但是该元素的上一个元素有规律,我们就可以使用这种下一个相邻选择器来进行选择。
func main() {
html := `
DIV1
P1
DIV2
DIV3
DIV4
P2
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div[lang=zh]+p").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
这个示例演示了这种用法,我们想选择 P1Find("div[lang=zh]+p")达到选择P元素的目的。
这种选择器的语法是("prev+next"),中间是一个加号(+),+号前后也是选择器。
prev~next选择器
有相邻就有兄弟,兄弟选择器就不一定要求相邻了,只要他们共有一个父元素就可以。
dom.Find("div[lang=zh]~p").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
刚刚的例子,只需要把+号换成~号,就可以把P2也筛选出来,因为P2、P1和DIV1都是兄弟。
兄弟选择器的语法是("prev~next"),也就是相邻选择器的+换成了~。
内容过滤器
有时候我们使用选择器选择出来后后,希望再过滤一下,这时候就用到过滤器了,过滤器有很多,我们先讲内容过滤器这一种。
dom.Find("div:contains(DIV2)").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
Find(":contains(text)")表示筛选出的元素要包含指定的文本,我们例子中要求选择出的div元素要包含DIV2文本,那么只有一个DIV2元素满足要求。
此外还有Find(":empty")表示筛选出的元素都不能有子元素(包括文本元素),只筛选那些不包含任何子元素的元素。
Find(":has(selector)")和contains差不多,只不过这个是包含的是元素节点。
dom.Find("span:has(div)").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
以上示例表示筛选出包含div元素的span节点。
:first-child过滤器
:first-child过滤器,语法为Find(":first-child"),表示筛选出的元素要是他们的父元素的第一个子元素,如果不是,则不会被筛选出来。
func main() {
html := `
DIV1
P1
DIV2
DIV3
DIV5
P2
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div:first-child").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Html())
})
}
以上例子中,我们使用Find("div")会筛选出所有的div元素,但是我们加了:first-child后,就只有DIV1和DIV4了,因为只有这两个是他们父元素的第一个子元素,其他的DIV都不满足。
:first-of-type过滤器
:first-child选择器限制的比较死,必须得是第一个子元素,如果该元素前有其他在前面,就不能用:first-child了,这时候:first-of-type就派上用场了,它要求只要是这个类型的第一个就可以,我们把上面的例子微调下。
func main() {
html := `
DIV1
P1
DIV2
DIV3
P2
DIV5
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div:first-of-type").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Html())
})
}
改动很简单,把原来的DIV4换成了P2,如果我们还使用:first-child,DIV5是不能被筛选出来的,因为它不是第一个子元素,它前面还有一个P2。这时候我们使用:first-of-type就可以达到目的,因为它要求是同类型第一个就可以。DIV5就是这个div类型的第一个元素,P2不是div类型,被忽略。
:last-child 和 :last-of-type过滤器
这两个正好和上面的:first-child、:first-of-type相反,表示最后一个,这里不再举例,大家可以自己试试。
:nth-child(n) 过滤器
这个表示筛选出的元素是其父元素的第n个元素,n以1开始。所以我们可以知道:first-child和:nth-child(1)是相等的。通过指定n,我们就很灵活的筛选出我们需要的元素。
func main() {
html := `
DIV1
P1
DIV2
DIV3
P2
DIV5
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div:nth-child(3)").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Html())
})
}
这个示例会筛选出DIV2,因为DIV2是其父元素body的第三个子元素。
:nth-of-type(n) 过滤器
:nth-of-type(n)和 :nth-child(n) 类似,只不过它表示的是同类型元素的第n个,所以:nth-of-type(1) 和 :first-of-type是相等的,大家可以自己试试,这里不再举例。
nth-last-child(n) 和:nth-last-of-type(n) 过滤器
这两个和上面的类似,只不过是倒序开始计算的,最后一个元素被当成了第一个。大家自己测试下看看效果,很明显。
:only-child 过滤器
Find(":only-child") 过滤器,从字面上看,可以猜测出来,它表示筛选的元素,在其父元素中,只有它自己,它的父元素没有其他子元素,才会被匹配筛选出来。
func main() {
html := `
DIV1
DIV5
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div:only-child").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Html())
})
}
示例中DIV5就可以被筛选出来,因为它是它的父元素span达到唯一子元素,但DIV1就不是,所以不能呗筛选出来。
:only-of-type 过滤器
上面的例子,如果想筛选出DIV1怎么办?可以使用Find(":only-of-type"),因为它是它的父元素中,唯一的div元素,这就是:only-of-type过滤器所要做的,同类型元素只要只有一个,就可以被筛选出来。大家把上面的例子改成:only-of-type试试,看看是否有DIV1。
选择器或(|)运算
如果我们想同时筛选出div,span等元素怎么办?这时候可以采用多个选择器进行组合使用,并且以逗号(,)分割,Find("selector1, selector2, selectorN")表示,只要满足其中一个选择器就可以被筛选出来,也就是选择器的或(|)运算操作。
func main() {
html := `
DIV1
DIV5
`
dom,err:=goquery.NewDocumentFromReader(strings.NewReader(html))
if err!=nil{
log.Fatalln(err)
}
dom.Find("div,span").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Html())
})
}
小结
goquery 是解析HTML网页必备的利器,在爬虫抓取网页的过程中,灵活的使用goquery不同的选择器,可以让我们的抓取工作事半功倍,大大提升爬虫的效率。
本篇关于《golanggoqueryselector选择器使用示例大全》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于Golang的相关知识,请关注golang学习网公众号!
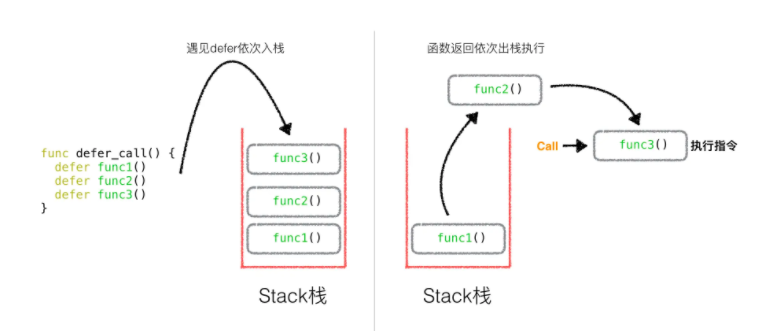 一文搞懂Go语言中defer关键字的使用
一文搞懂Go语言中defer关键字的使用
- 上一篇
- 一文搞懂Go语言中defer关键字的使用

- 下一篇
- Go time包AddDate使用解惑实例详解
-

- 复杂的项链
- 这篇技术文章出现的刚刚好,太细致了,很有用,已加入收藏夹了,关注作者大大了!希望作者大大能多写Golang相关的文章。
- 2023-01-18 00:01:48
-
- 俊秀的灯泡
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢up主分享技术文章!
- 2023-01-16 19:10:38
-
- 能干的西牛
- 太全面了,已收藏,感谢老哥的这篇文章内容,我会继续支持!
- 2023-01-10 01:30:24
-
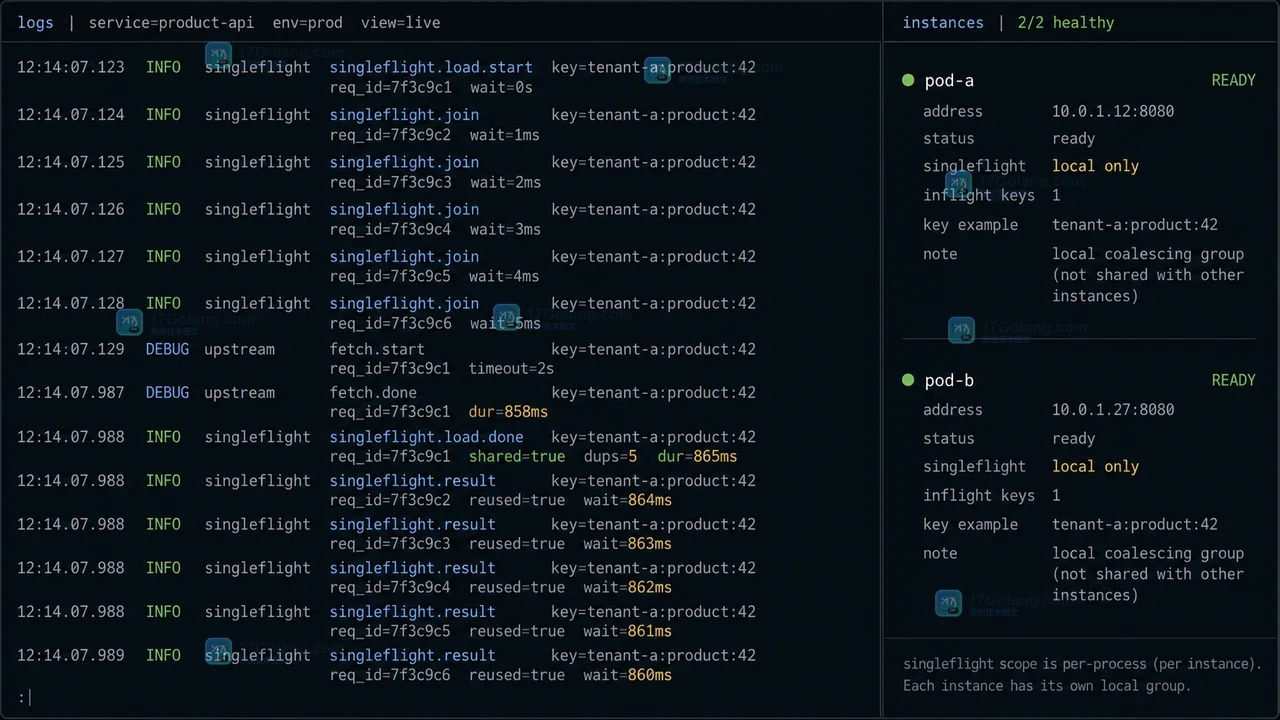
- Golang · Go教程 | 5小时前 | golang · 缓存 · singleflight · go · 高并发 · 后端开发 · Go 并发控制 缓存失效 请求合并 singleflight 回源
- Go singleflight 怎么合并同一请求:缓存失效时别让 500 个请求一起回源
- 109浏览 收藏
-

- Golang · Go教程 | 8小时前 | [] · []
- Go 项目 GitHub Actions 怎么设质量门禁:go vet、go test 与构建分阶段拦截
- 485浏览 收藏
-

- Golang · Go教程 | 9小时前 | [] · []
- Go html/template 怎么安全把后端数据交给前端:别把 JSON 硬塞进 template.JS
- 177浏览 收藏
-

- Golang · Go教程 | 12小时前 | 前端开发 · Go教程 · html/template · 网页模板 · 导航 · Go html/template CurrentPath 导航高亮 template.FuncMap Go网页模板
- Go html/template 怎么高亮当前导航:传入 CurrentPath 的最小写法
- 409浏览 收藏
-
![Go 拼接字符串怎么选:strings.Builder、bytes.Buffer 和 []byte 的边界](/uploads/20260716/1784195965-01-builder-timeline.webp)
- Golang · Go教程 | 1天前 | 标准库 · 基准测试 · Go教程 · 字符串拼接 · Go 字符串拼接 strings.Builder bytes.Buffer []byte
- Go 拼接字符串怎么选:strings.Builder、bytes.Buffer 和 []byte 的边界
- 188浏览 收藏
-

- Golang · Go教程 | 1天前 | golang · Timer · 并发编程 · time.After · 性能排查 · time.After go timer Go 1.23 NewTimer Timer.Reset Timer.Stop
- Go 1.23 以后还要手动 Stop Timer 吗:一次超时循环改造实战
- 403浏览 收藏
-
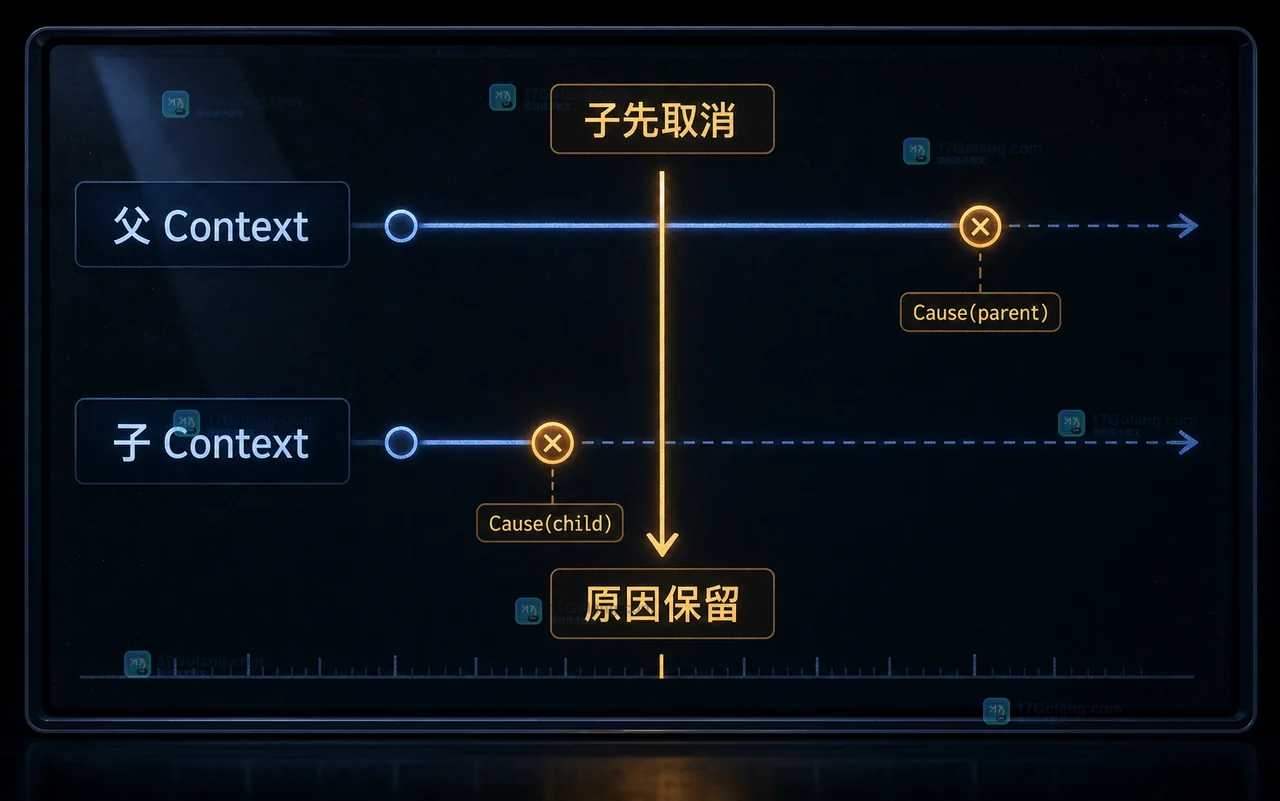
- Golang · Go教程 | 1天前 | 并发 · 错误处理 · go · Context · 排错 · Go 错误链 context.WithCancelCause context.Cause 取消原因
- Go context.WithCancelCause 怎么用:让中断原因能被日志和调用方看见
- 366浏览 收藏
-

- Golang · Go教程 | 1天前 | 并发 · WaitGroup · go · worker pool · 服务停机 · Go channel WaitGroup 优雅停机 worker pool 任务排空
- Go worker pool 停机时任务为什么会丢?关闭顺序、WaitGroup 和排空策略
- 207浏览 收藏
-
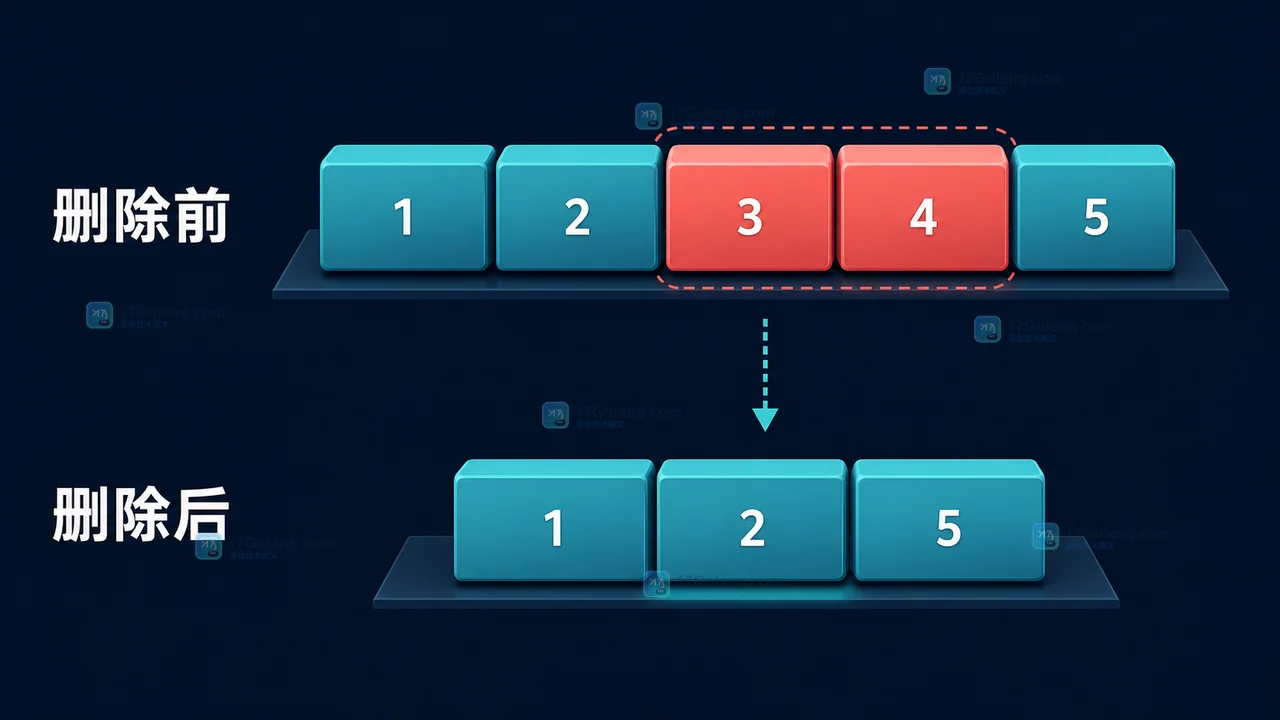
- Golang · Go教程 | 1天前 | 切片 · Slices · Go教程 · Go 1.21 · 切片删除 Go教程 Go slices.Delete slices.DeleteFunc Go 1.21
- Go slices.Delete 怎么用?删除元素后为什么一定要接收返回切片
- 463浏览 收藏
-
- Golang · Go教程 | 1天前 | HTTP · Go教程 · 服务治理 · Shutdown · SIGTERM · SIGTERM Go 优雅关闭 http.Server Shutdown Go HTTP 服务 连接收尾 服务下线
- Go HTTP 服务优雅关闭怎么做?Shutdown、超时和连接收尾的取舍
- 316浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4533次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4207次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4164次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4392次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4338次使用
-
- Go爬虫(http、goquery和colly)详解
- 2022-12-31 353浏览
-
- Go 语言选择器实例教程
- 2023-01-26 336浏览
-
- golang解析网页利器goquery的使用方法
- 2023-01-21 112浏览
-
- go如何将两个切片转化为一段json?
- 2023-02-24 274浏览


