详细介绍
原子回声AtomGPT大模型:专注中文的智能语言处理工具
原子回声AtomGPT大模型是一个专注于中文大模型训练的项目,旨在开发一个在中文处理能力上能够与ChatGPT相媲美的智能系统。该项目通过展示模型在训练过程中的能力提升,让用户能够直观地感受到模型学习和发展的每一个阶段。
主要特点:
- 专注中文处理:项目致力于提升模型在中文语境下的表现,确保其在中文环境中的高效性和准确性。
- 学习过程可视化:通过展示模型的学习过程,用户可以观察到模型能力的逐步提升,增强用户体验。
- 持续进步:模型会通过不断的训练持续进步,以期达到更高的智能水平,提供更优质的服务。
主要功能:
- 中文语言理解:AtomGPT能够理解用户输入的中文内容,提供精准的语义分析。
- 中文语言生成:根据用户输入,模型能够生成自然流畅的中文回答或内容,满足用户需求。
- 能力展示:项目提供了展示模型在不同训练阶段能力的功能,用户可以直观感受模型的成长。
使用示例:
用户可以轻松体验AtomGPT的强大功能:
- 访问AtomGPT项目网站:进入项目官网,了解更多关于模型的信息。
- 输入问题或请求:在交互界面中输入中文问题或请求,例如“今天的天气怎么样?”。
- 观察模型生成回答:查看AtomGPT根据其训练数据生成的中文回答,感受其智能水平。
总结:
原子回声AtomGPT大模型是一个专注于中文大模型训练的项目,通过展示模型的学习过程,为用户提供了一个参与和观察模型成长的平台。随着训练的深入,AtomGPT有潜力成为一个强大的中文语言处理工具,为用户提供高质量的智能服务。
查看更多
最新文章
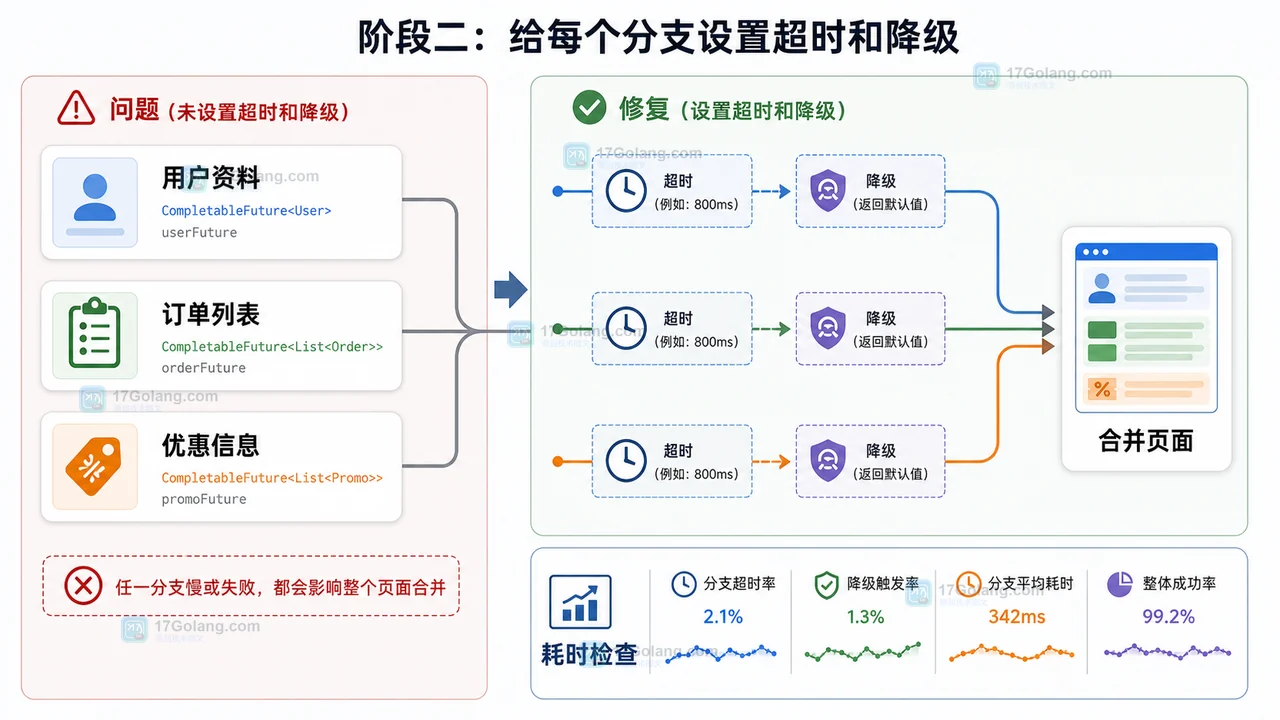
Java CompletableFuture 接口聚合工作流:从超时边界到降级返回
本文用一个用户首页聚合场景,梳理 Java CompletableFuture 的并发拉取、超时边界、异
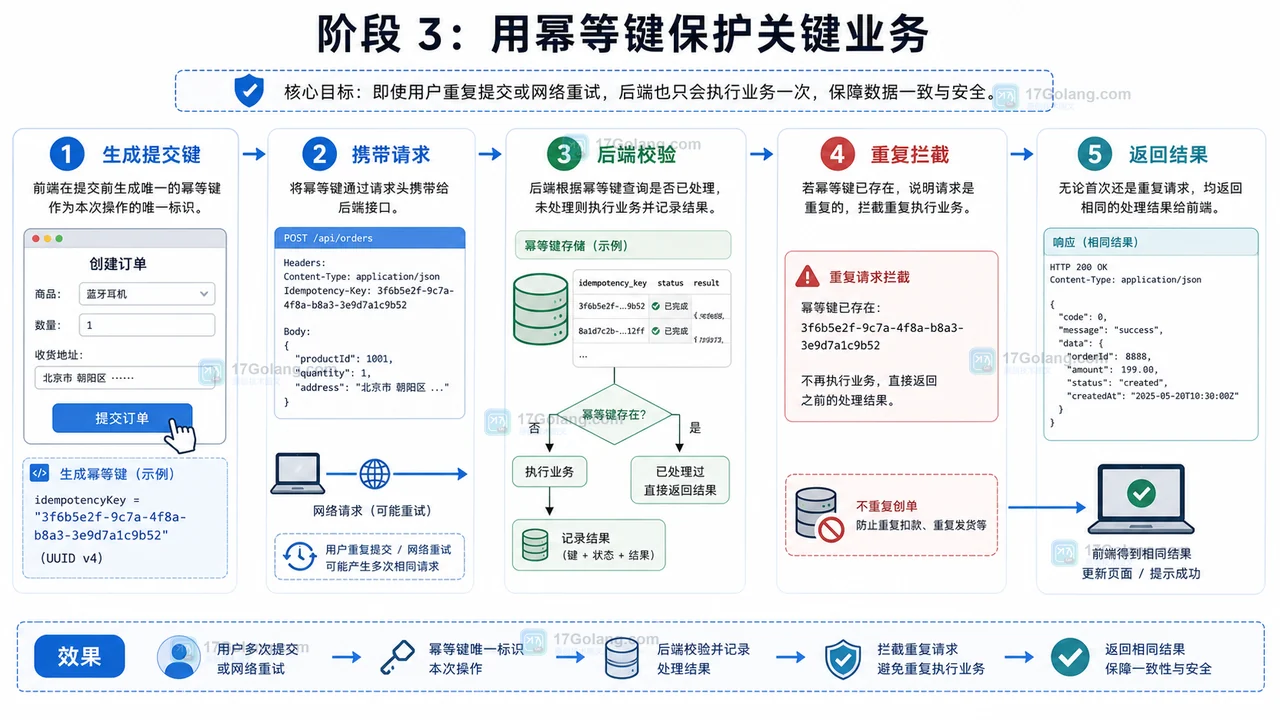
前端表单重复提交防护工作流:从按钮状态到请求取消和幂等键
本文整理一套前端表单重复提交防护工作流,从按钮状态、加载提示、请求取消、幂等键、错误恢复到复查指标,帮助
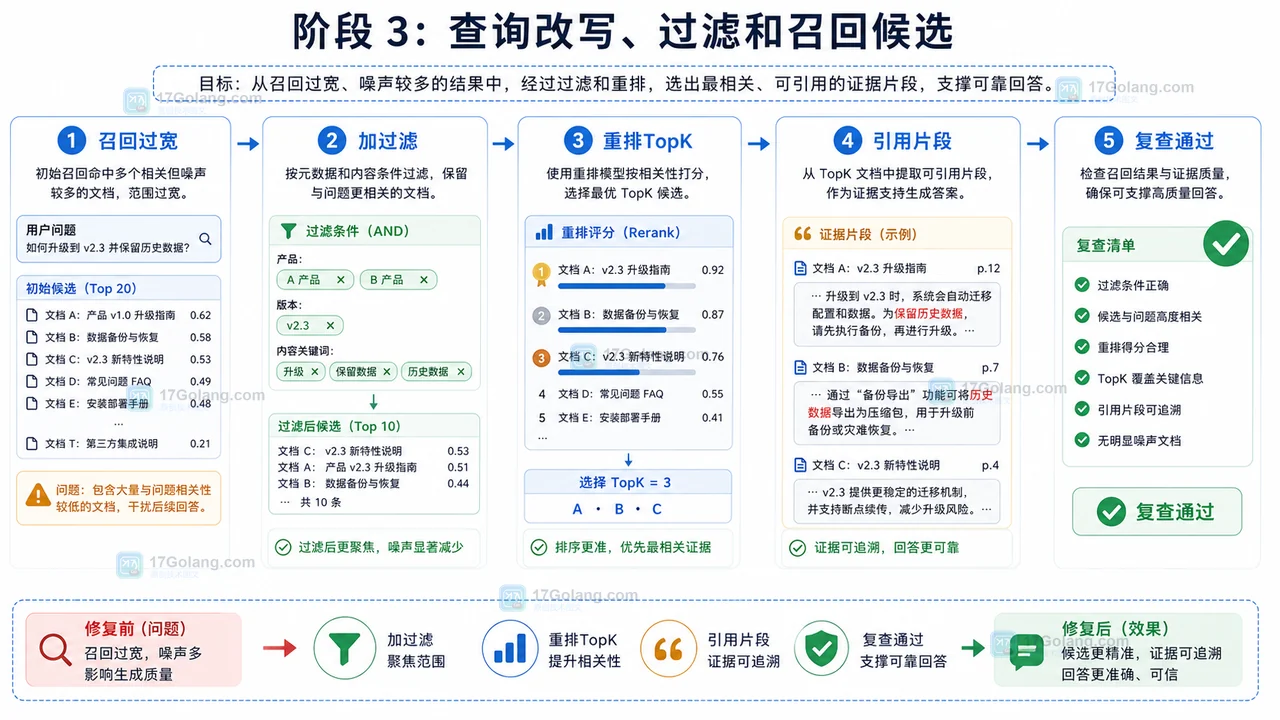
AI 知识库检索召回工作流:从文档切分到重排和证据引用
本文整理一套 AI 知识库检索召回工作流,从文档清洗、切分、向量入库、查询改写、过滤重排到证据引用和复查
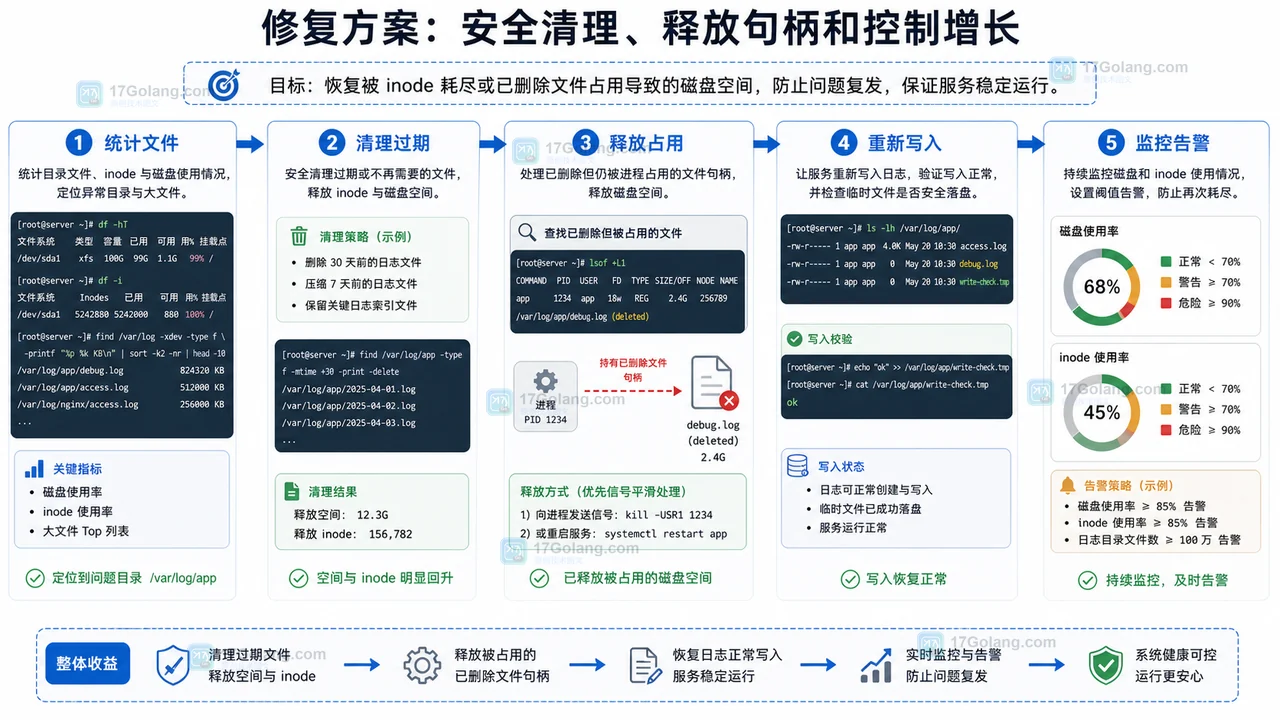
Linux 磁盘还有空间却写入失败排查:从 inode 到已删除文件占用
本文从 Linux 写文件提示 No space left on device 但 df -h 仍有空间
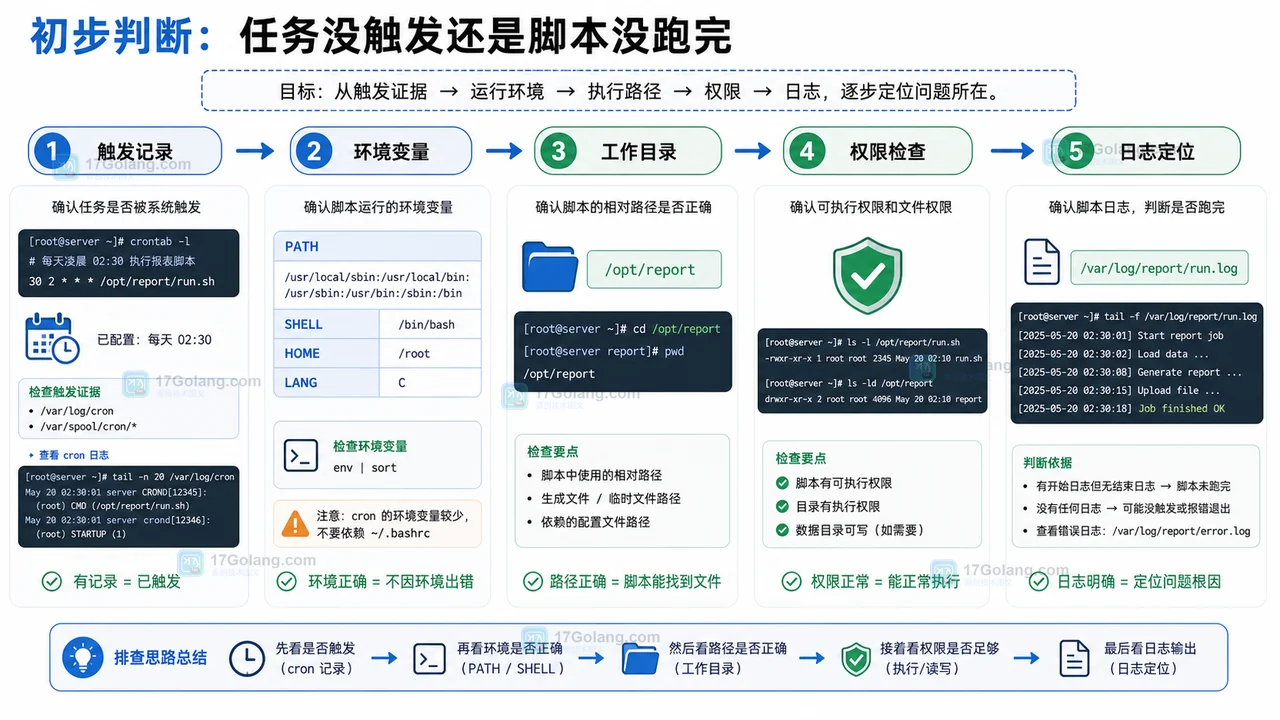
Linux crontab 定时任务不运行排查:从 PATH 到工作目录和日志
本文从 crontab 定时任务没有按时运行的现象出发,按触发记录、PATH、工作目录、权限、日志和并发
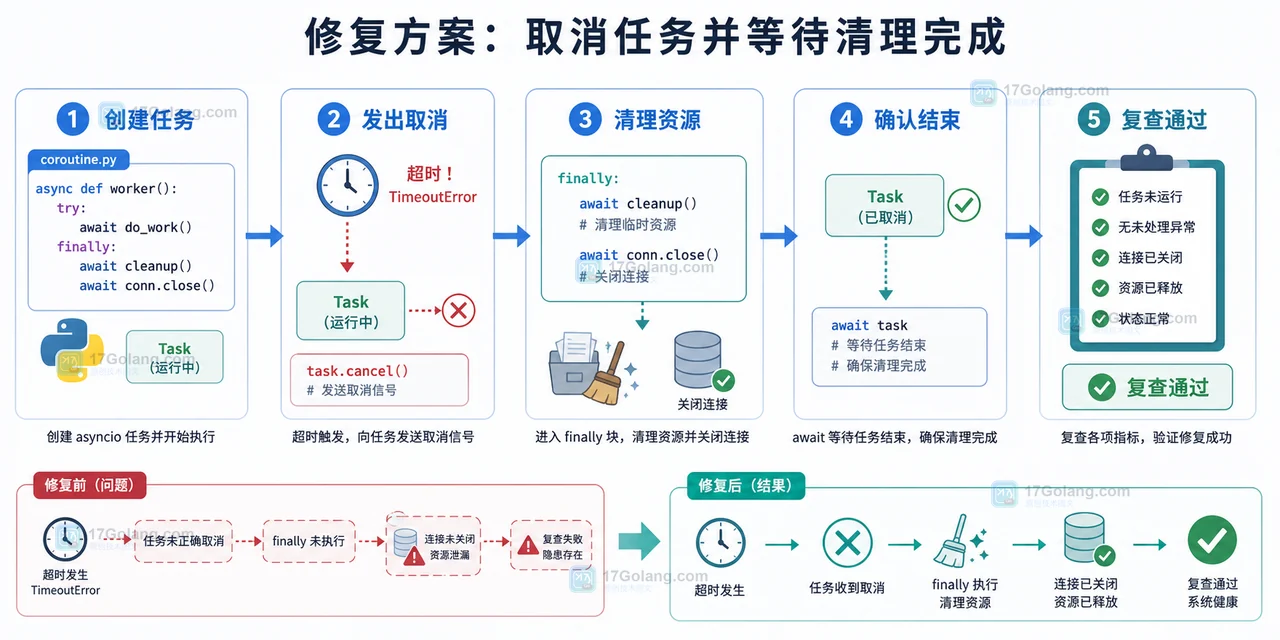
Python asyncio 超时后任务还在跑排查:从 wait_for 到取消清理
本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消



